Запуск проектов MLflow в Azure Databricks
MLflow Project — это формат для упаковки кода обработки и анализа данных для повторного использования и воспроизведения. Компонент MLflow Projects включает API и средства командной строки для запуска проектов, которые также интегрируются с компонентом Отслеживания для автоматической записи параметров и фиксации Git исходного кода в целях воспроизведения.
В этой статье описывается формат MLflow Project и способ удаленного запуска проекта MLflow на кластерах Azure Databricks с помощью CLI MLflow, что упрощает вертикальное масштабирование кода обработки и анализа данных.
Формат проекта MLflow
Любой локальный каталог или репозиторий Git можно рассматривать как проект MLflow. В следующих соглашениях приводится описание проекта:
- Имя проекта — это имя каталога.
- Среда программного обеспечения указана в
python_env.yaml, если она присутствует. Если файл отсутствуетpython_env.yaml, MLflow использует среду virtualenv, содержащую только Python (в частности, последнюю версию Python, доступную для virtualenv) при запуске проекта. - Любой файл
.pyили.shв проекте может быть точкой входа, без прямо объявленных параметров. При выполнении такой команды с набором параметров MLflow передает каждый параметр в командной строке с помощью синтаксиса--key <value>.
Указываются дополнительные параметры при помощи добавления файла MLproject, который является текстовым файлом в синтаксисе YAML. Пример файла MLproject выглядит следующим образом:
name: My Project
python_env: python_env.yaml
entry_points:
main:
parameters:
data_file: path
regularization: {type: float, default: 0.1}
command: "python train.py -r {regularization} {data_file}"
validate:
parameters:
data_file: path
command: "python validate.py {data_file}"
Для Databricks Runtime 13.0 ML и более поздних версий проекты MLflow не могут успешно выполняться в кластере типов заданий Databricks. Чтобы перенести существующие проекты MLflow в Databricks Runtime 13.0 ML и более поздних версий, см . в формате проекта задания MLflow Databricks Spark.
Формат проекта задания MLflow Databricks Spark
Проект задания MLflow Databricks Spark — это тип проекта MLflow, представленный в MLflow 2.14. Этот тип проекта поддерживает запуск MLflow Projects из кластера заданий Spark и может выполняться только с помощью серверной databricks части.
Проекты заданий Databricks Spark должны задавать databricks_spark_job.python_file либо entry_points. Не указывая ни один или не указывая оба параметра, вызывает исключение.
Ниже приведен пример MLproject файла, использующего databricks_spark_job.python_file параметр. Этот параметр включает использование жестко закодированного пути для файла выполнения Python и его аргументов.
name: My Databricks Spark job project 1
databricks_spark_job:
python_file: "train.py" # the file which is the entry point file to execute
parameters: ["param1", "param2"] # a list of parameter strings
python_libraries: # dependencies required by this project
- mlflow==2.4.1 # MLflow dependency is required
- scikit-learn
Ниже приведен пример MLproject файла, использующего entry_points параметр:
name: My Databricks Spark job project 2
databricks_spark_job:
python_libraries: # dependencies to be installed as databricks cluster libraries
- mlflow==2.4.1
- scikit-learn
entry_points:
main:
parameters:
model_name: {type: string, default: model}
script_name: {type: string, default: train.py}
command: "python {script_name} {model_name}"
Этот entry_points параметр позволяет передавать параметры, использующие параметр командной строки, например:
mlflow run . -b databricks --backend-config cluster-spec.json \
-P script_name=train.py -P model_name=model123 \
--experiment-id <experiment-id>
Следующие ограничения применяются к проектам заданий Databricks Spark:
- Этот тип проекта не поддерживает указание следующих разделов в
MLprojectфайле:docker_env,python_envилиconda_env. - Зависимости для проекта должны быть указаны в
python_librariesполеdatabricks_spark_jobраздела. Версии Python нельзя настроить с помощью этого типа проекта. - Запущенная среда должна использовать основную среду выполнения драйвера Spark для запуска в кластерах заданий, использующих Databricks Runtime 13.0 или более поздней версии.
- Аналогичным образом, все зависимости Python, определенные как необходимые для проекта, должны быть установлены в качестве зависимостей кластера Databricks. Это поведение отличается от предыдущего поведения запуска проекта, в котором библиотеки должны быть установлены в отдельной среде.
Запуск проекта MLflow
Чтобы запустить проект MLflow в кластере Azure Databricks в рабочей области по умолчанию, используйте команду:
mlflow run <uri> -b databricks --backend-config <json-new-cluster-spec>
где <uri> — это URI репозитория Git или папка, содержащая проект MLflow, а <json-new-cluster-spec> — документ JSON, содержащий new_cluster structure. URI Git должен иметь вид: https://github.com/<repo>#<project-folder>.
Пример спецификации кластера:
{
"spark_version": "7.3.x-scala2.12",
"num_workers": 1,
"node_type_id": "Standard_DS3_v2"
}
Если необходимо установить библиотеки в рабочей роли, используйте формат "Спецификация кластера". Обратите внимание, что файлы колес Python должны быть отправлены в DBFS и указаны в качестве pypi зависимостей. Например:
{
"new_cluster": {
"spark_version": "7.3.x-scala2.12",
"num_workers": 1,
"node_type_id": "Standard_DS3_v2"
},
"libraries": [
{
"pypi": {
"package": "tensorflow"
}
},
{
"pypi": {
"package": "/dbfs/path_to_my_lib.whl"
}
}
]
}
Внимание
- зависимости
.eggи.jarне поддерживаются для проектов MLflow. - Выполнение проектов MLflow с помощью сред Docker не поддерживается.
- Требуется использовать новую спецификацию кластера при выполнении MLflow Project на Databricks. Запуск проектов для существующих кластеров не поддерживается.
Использование SparkR
Чтобы использовать SparkR в MLflow Project, код проекта должен сначала установить и импортировать SparkR следующим образом:
if (file.exists("/databricks/spark/R/pkg")) {
install.packages("/databricks/spark/R/pkg", repos = NULL)
} else {
install.packages("SparkR")
}
library(SparkR)
Затем проект может инициализировать сеанс SparkR и использовать его в качестве обычного:
sparkR.session()
...
Пример
В этом примере показано, как создать эксперимент, запустить обучающий проект MLflow в кластере Azure Databricks, просмотреть выходные данные выполнения задания и выполнение в эксперименте.
Требования
- Установите MLflow с помощью
pip install mlflow. - Установите и настройте CLI Databricks. Для выполнения заданий в кластере Azure Databricks требуется механизм аутентификации CLI Databricks.
Шаг 1. Создание эксперимента
В рабочей области выберите Создать >эксперимент MLflow.
В поле "Имя" введите
Tutorial.Нажмите кнопку Создать. Запишите идентификатор эксперимента. В нашем примере поисковый запрос будет выглядеть так:
14622565.
Шаг 2. Запуск обучающего проекта MLflow
Следующие шаги служат для настройки переменной среды MLFLOW_TRACKING_URI и запускают проект, записывая параметры, метрики обучения и обучающую модель в эксперименте, указанном на предыдущем шаге:
Задайте переменную среды
MLFLOW_TRACKING_URIв рабочей области Azure Databricks.export MLFLOW_TRACKING_URI=databricksЗапустите проект обучения MLflow, обучение модели WINE. Замените
<experiment-id>идентификатором эксперимента, который вы записали на предыдущем шаге.mlflow run https://github.com/mlflow/mlflow#examples/sklearn_elasticnet_wine -b databricks --backend-config cluster-spec.json --experiment-id <experiment-id>=== Fetching project from https://github.com/mlflow/mlflow#examples/sklearn_elasticnet_wine into /var/folders/kc/l20y4txd5w3_xrdhw6cnz1080000gp/T/tmpbct_5g8u === === Uploading project to DBFS path /dbfs/mlflow-experiments/<experiment-id>/projects-code/16e66ccbff0a4e22278e4d73ec733e2c9a33efbd1e6f70e3c7b47b8b5f1e4fa3.tar.gz === === Finished uploading project to /dbfs/mlflow-experiments/<experiment-id>/projects-code/16e66ccbff0a4e22278e4d73ec733e2c9a33efbd1e6f70e3c7b47b8b5f1e4fa3.tar.gz === === Running entry point main of project https://github.com/mlflow/mlflow#examples/sklearn_elasticnet_wine on Databricks === === Launched MLflow run as Databricks job run with ID 8651121. Getting run status page URL... === === Check the run's status at https://<databricks-instance>#job/<job-id>/run/1 ===Скопируйте URL-адрес
https://<databricks-instance>#job/<job-id>/run/1в последней строке выходных данных выполнения MLflow.
Шаг 3. Просмотр выполнения задания Azure Databricks
Откройте URL-адрес, скопированный на предыдущем шаге, в браузере, чтобы просмотреть выходные данные выполнения задания Azure Databricks:
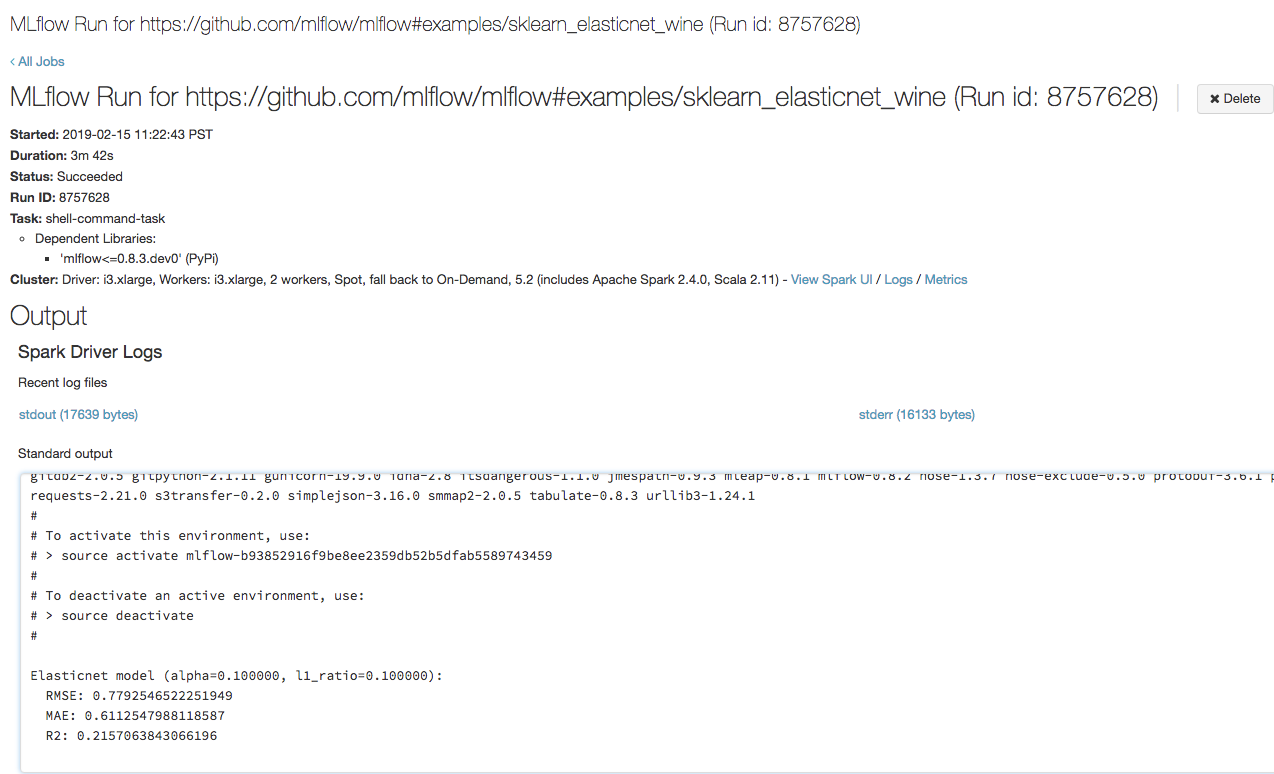
Шаг 4. Просмотр сведений о запуске эксперимента и MLflow
Перейдите к эксперименту в рабочей области Azure Databricks.
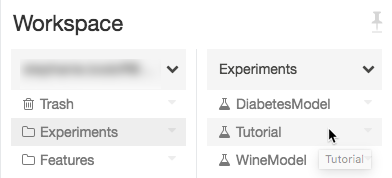
Нажмите на название эксперимента.
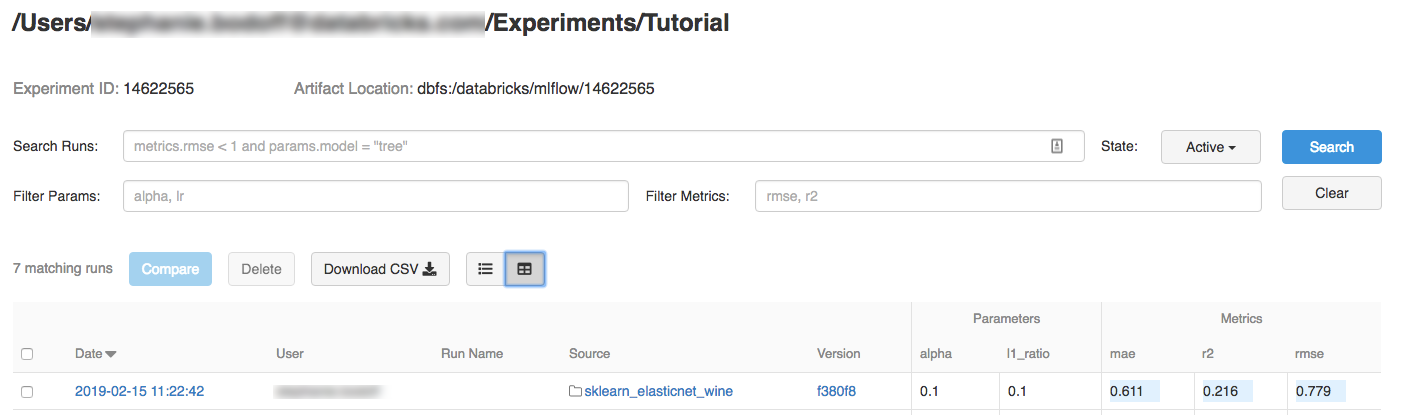
Чтобы отобразить сведения о выполнении, нажмите на ссылку в столбце "Дата".
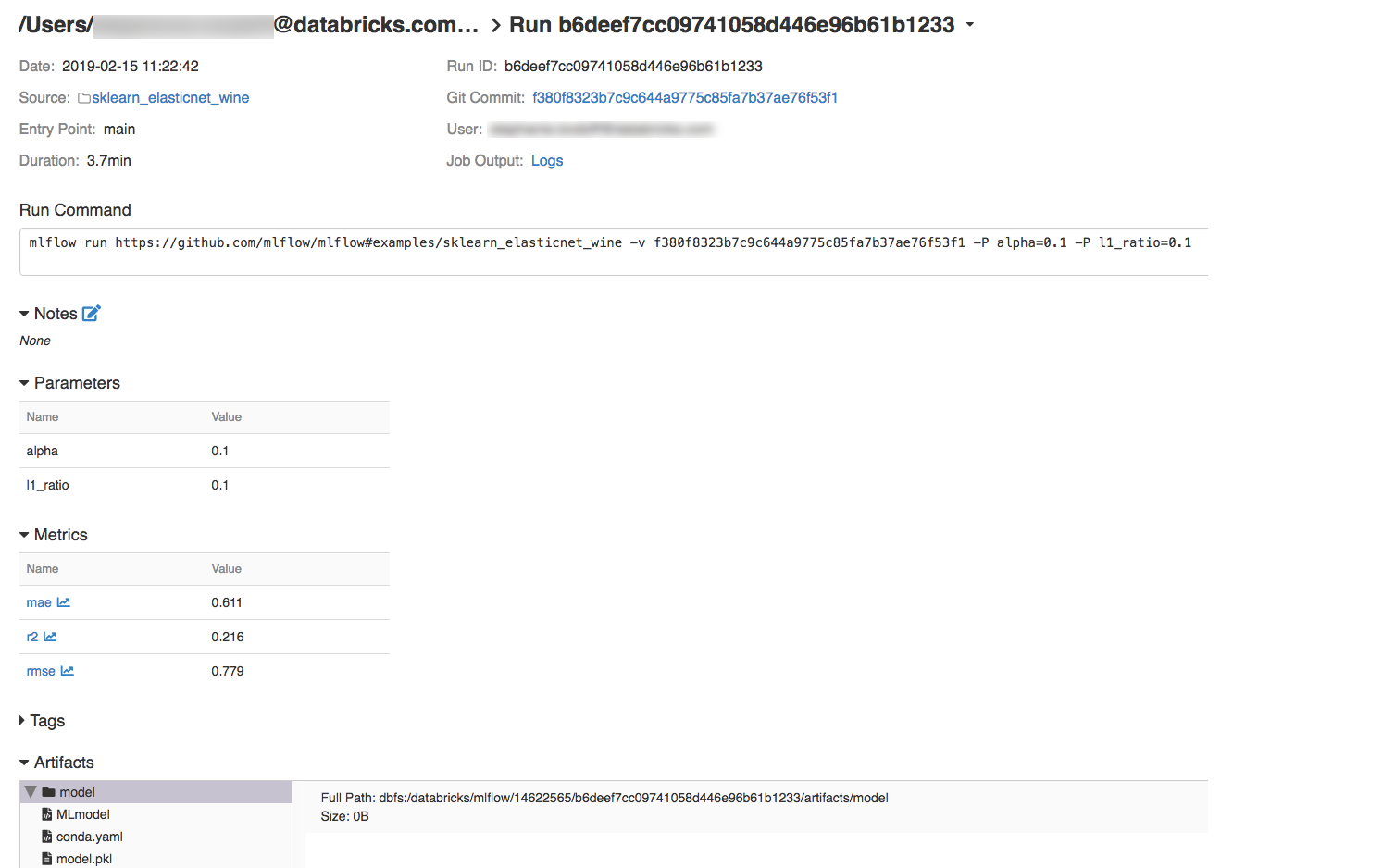
Чтобы просмотреть журналы запуска, нажмите ссылку Журналы в поле "Выходные данные задания".
Ресурсы
Некоторые примеры проектов MLflow см. в библиотеке MLflow App Library, которая содержит репозиторий готовых к выполнению проектов, предназначенных для упрощения включения функциональных возможностей ML в код.