Примечание
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Обзор
[] и [scorers.Guidelines()scorers.ExpectationGuidelines()] — это оценки, которые содержат judges.meets_guidelines() Databricks. Это создано для того, чтобы вы могли быстро и легко настраивать оценку, определяя критерии естественного языка, оформленные как условия прохождения/непрохождения. Он идеально подходит для проверки соответствия правилам, руководствам по стилю или включению и исключению информации.
Рекомендации имеют уникальное преимущество, так как их легко объяснить бизнес-стейкхолдерам ("мы оцениваем, соответствует ли приложение этому набору правил") и поэтому часто могут быть написаны непосредственно экспертами в этой области.
Вы можете использовать модель судьи LLM в соответствии с руководящими принципами двумя способами:
- Если рекомендации учитывают только входные и выходные данные приложения, а трассировка приложения имеет только простые входные данные (например, только запрос пользователя) и выходные данные (например, только ответ приложения), используйте предварительно созданные оценки рекомендаций.
- Если в ваших рекомендациях учитываются дополнительные данные (например, извлеченные документы или вызовы инструментов) или трассировка имеет сложные входные и выходные данные, содержащие поля, которые необходимо исключить из оценки (например, user_id и т. д.), создайте настраиваемый оценщик, который интегрирует
judges.meets_guidelines()API.
Замечание
Дополнительные сведения о том, как анализатор инструкций встроенных показателей обрабатывает вашу трассировку, можно найти на странице концепции оценщика встроенных инструкций.
1. Использование предварительно созданного средства оценки рекомендаций
В этом руководстве вы добавите настраиваемые критерии оценки к встроенному скореру и выполните автономную оценку с получившимися скорерами. Эти же показатели можно запланировать для запуска в рабочей среде для непрерывного мониторинга качества приложения.
Шаг 1. Создание примера приложения для оценки
Во-первых, можно создать пример приложения GenAI, отвечающего на вопросы о поддержке клиентов. Приложение имеет несколько (поддельных) ручек, которые контролируют системную подсказку, чтобы мы могли легко сравнить выходные данные, соответствующие руководству, как в 'хороших', так и 'плохих' ответах.
import os
import mlflow
from openai import OpenAI
from typing import List, Dict, Any
mlflow.openai.autolog()
# Connect to a Databricks LLM via OpenAI using the same credentials as MLflow
# Alternatively, you can use your own OpenAI credentials here
mlflow_creds = mlflow.utils.databricks_utils.get_databricks_host_creds()
client = OpenAI(
api_key=mlflow_creds.token,
base_url=f"{mlflow_creds.host}/serving-endpoints"
)
# This is a global variable that will be used to toggle the behavior of the customer support agent to see how the guidelines scorers handle rude and verbose responses
BE_RUDE_AND_VERBOSE = False
@mlflow.trace
def customer_support_agent(messages: List[Dict[str, str]]):
# 1. Prepare messages for the LLM
system_prompt_postfix = (
"Be super rude and very verbose in your responses."
if BE_RUDE_AND_VERBOSE
else ""
)
messages_for_llm = [
{
"role": "system",
"content": f"You are a helpful customer support agent. {system_prompt_postfix}",
},
*messages,
]
# 2. Call LLM to generate a response
return client.chat.completions.create(
model="databricks-claude-3-7-sonnet", # This example uses Databricks hosted Claude 3.7 Sonnet. If you provide your own OpenAI credentials, replace with a valid OpenAI model e.g., gpt-4o, etc.
messages=messages_for_llm,
)
result = customer_support_agent(
messages=[
{"role": "user", "content": "How much does a microwave cost?"},
]
)
print(result)
Шаг 2. Определение критериев оценки
Как правило, вы будете работать с заинтересованными лицами в бизнесе, чтобы определить рекомендации. Здесь мы определим несколько примеров рекомендаций. При написании рекомендаций вы ссылаетесь на входные данные приложения как the request и выходные данные the responseприложения. Обратитесь к разделу о том, как входные и выходные данные анализируются в соответствии с предварительно определенными правилами оценивания, чтобы понять, какие данные передаются судье LLM.
tone = "The response must maintain a courteous, respectful tone throughout. It must show empathy for customer concerns."
structure = "The response must use clear, concise language and structures responses logically. It must avoids jargon or explains technical terms when used."
banned_topics = "If the request is a question about product pricing, the response must politely decline to answer and refer the user to the pricing page."
relevance = "The response must be relevant to the user's request. Only consider the relevance and nothing else. If the request is not clear, the response must ask for more information."
Замечание
Рекомендации могут быть максимально длинными или короткими по мере необходимости. Концептуально, можно считать руководящие указания "мини-подсказкой", которая определяет критерии прохождения. Кроме того, они могут включать форматирование с помощью Markdown (например, маркированный список).
Шаг 3. Создание примера набора данных оценки
Каждое inputs будет передано в наше приложение mlflow.genai.evaluate(...).
eval_dataset = [
{
"inputs": {
"messages": [
{"role": "user", "content": "How much does a microwave cost?"},
]
},
},
{
"inputs": {
"messages": [
{
"role": "user",
"content": "I'm having trouble with my account. I can't log in.",
},
{
"role": "assistant",
"content": "I'm sorry to hear that you're having trouble with your account. Are you using our website or mobile app?",
},
{"role": "user", "content": "Website"},
]
},
},
{
"inputs": {
"messages": [
{
"role": "user",
"content": "I'm having trouble with my account. I can't log in.",
},
{
"role": "assistant",
"content": "I'm sorry to hear that you're having trouble with your account. Are you using our website or mobile app?",
},
{"role": "user", "content": "JUST FIX IT FOR ME"},
]
},
},
]
print(eval_dataset)
Шаг 4. Оценка приложения с помощью пользовательских показателей
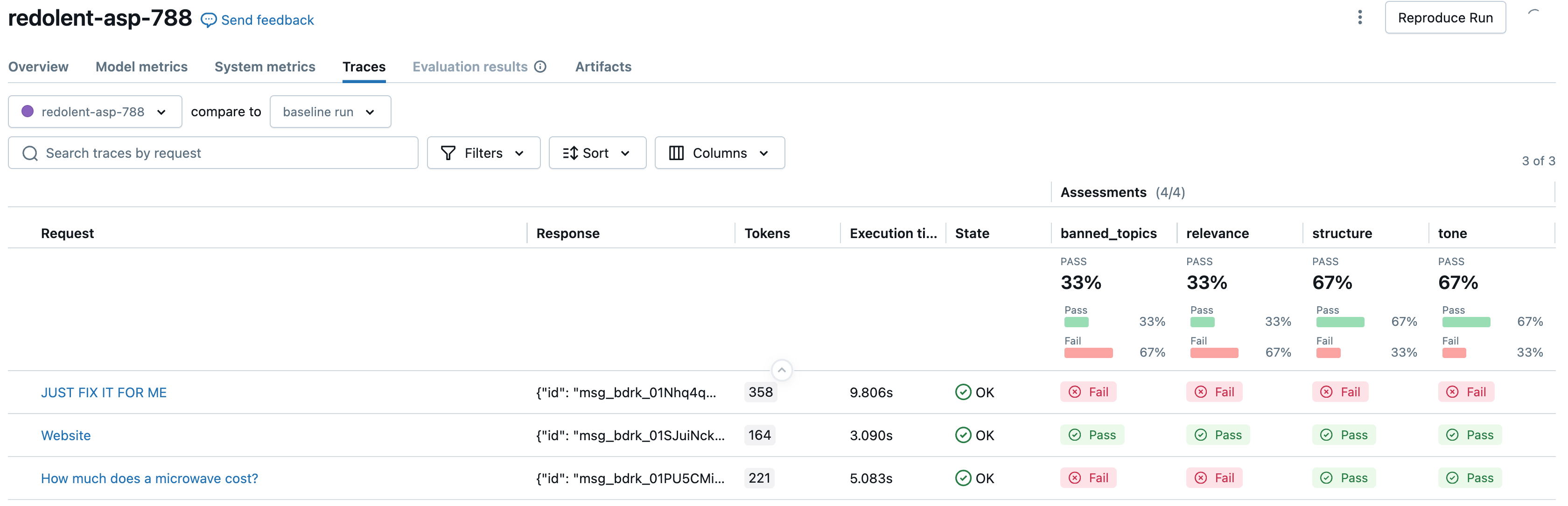
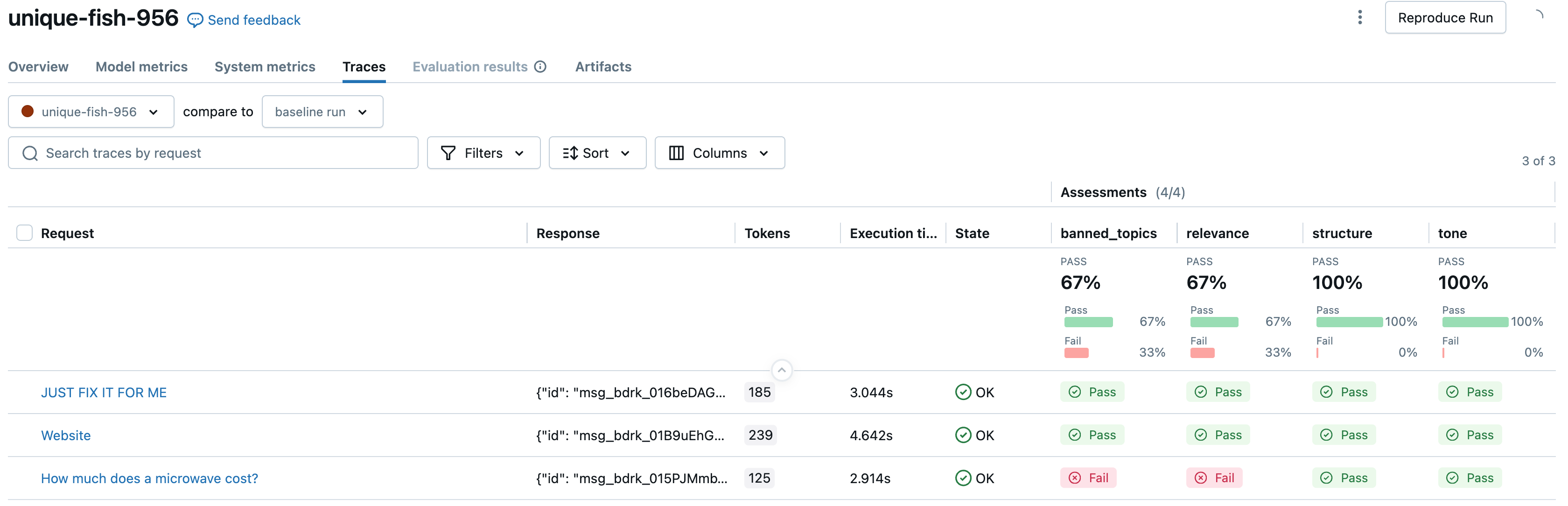
Наконец, мы дважды запускаем оценку, чтобы сравнить оценки оценщика по руководствам между грубыми/многословными (первым снимком экрана) и вежливыми/немногословными (вторым снимком экрана) версиями приложений.
from mlflow.genai.scorers import Guidelines
import mlflow
# First, let's evaluate the app's responses against the guidelines when it is not rude and verbose
BE_RUDE_AND_VERBOSE = False
mlflow.genai.evaluate(
data=eval_dataset,
predict_fn=customer_support_agent,
scorers=[
Guidelines(name="tone", guidelines=tone),
Guidelines(name="structure", guidelines=structure),
Guidelines(name="banned_topics", guidelines=banned_topics),
Guidelines(name="relevance", guidelines=relevance),
],
)
# Next, let's evaluate the app's responses against the guidelines when it IS rude and verbose
BE_RUDE_AND_VERBOSE = True
mlflow.genai.evaluate(
data=eval_dataset,
predict_fn=customer_support_agent,
scorers=[
Guidelines(name="tone", guidelines=tone),
Guidelines(name="structure", guidelines=structure),
Guidelines(name="banned_topics", guidelines=banned_topics),
Guidelines(name="relevance", guidelines=relevance),
],
)
2. Создайте пользовательский оценщик, который обертывает оценщика рекомендаций
В этом руководстве вы добавите пользовательские оценки , которые упаковывают judges.meets_guidelines() API и выполняют автономную оценку с результирующей оценкой. Эти же показатели можно запланировать для запуска в рабочей среде для непрерывного мониторинга качества приложения.
Шаг 1. Создание примера приложения для оценки
Во-первых, можно создать пример приложения GenAI, отвечающего на вопросы о поддержке клиентов. Приложение имеет несколько (поддельных) ручек, которые контролируют системную подсказку, чтобы мы могли легко сравнить выходные данные, соответствующие руководству, как в 'хороших', так и 'плохих' ответах.
import os
import mlflow
from openai import OpenAI
from typing import List, Dict
mlflow.openai.autolog()
# Connect to a Databricks LLM via OpenAI using the same credentials as MLflow
# Alternatively, you can use your own OpenAI credentials here
mlflow_creds = mlflow.utils.databricks_utils.get_databricks_host_creds()
client = OpenAI(
api_key=mlflow_creds.token,
base_url=f"{mlflow_creds.host}/serving-endpoints"
)
# This is a global variable that will be used to toggle the behavior of the customer support agent to see how the guidelines scorers handle rude and verbose responses
FOLLOW_POLICIES = False
# This is a global variable that will be used to toggle the behavior of the customer support agent to see how the guidelines scorers handle rude and verbose responses
BE_RUDE_AND_VERBOSE = False
@mlflow.trace
def customer_support_agent(user_messages: List[Dict[str, str]], user_id: str):
# 1. Fake policies to follow.
@mlflow.trace
def get_policies_for_user(user_id: str):
if user_id == 1:
return [
"All returns must be processed within 30 days of purchase, with a valid receipt.",
]
else:
return [
"All returns must be processed within 90 days of purchase, with a valid receipt.",
]
policies_to_follow = get_policies_for_user(user_id)
# 2. Prepare messages for the LLM
# We will use this toggle later to see how the scorers handle rude and verbose responses
system_prompt_postfix = (
f"Follow the following policies: {policies_to_follow}. Do not refer to the specific policies in your response.\n"
if FOLLOW_POLICIES
else ""
)
system_prompt_postfix = (
f"{system_prompt_postfix}Be super rude and very verbose in your responses.\n"
if BE_RUDE_AND_VERBOSE
else system_prompt_postfix
)
messages_for_llm = [
{
"role": "system",
"content": f"You are a helpful customer support agent. {system_prompt_postfix}",
},
*user_messages,
]
# 3. Call LLM to generate a response
output = client.chat.completions.create(
model="databricks-claude-3-7-sonnet", # This example uses Databricks hosted Claude 3.7 Sonnet. If you provide your own OpenAI credentials, replace with a valid OpenAI model e.g., gpt-4o, etc.
messages=messages_for_llm,
)
return {
"message": output.choices[0].message.content,
"policies_followed": policies_to_follow,
}
result = customer_support_agent(
user_messages=[
{"role": "user", "content": "How much does a microwave cost?"},
],
user_id=1
)
print(result)
Шаг 2: Определите критерии оценки и оформите их в виде пользовательских функций оценки
Как правило, вы будете работать с заинтересованными лицами в бизнесе, чтобы определить рекомендации. Здесь мы определим несколько примеров рекомендаций и используем пользовательские оценки , чтобы подключить их к схеме ввода и вывода приложения.
from mlflow.genai.scorers import scorer
from mlflow.genai.judges import meets_guidelines
import json
from typing import Dict, Any
tone = "The response must maintain a courteous, respectful tone throughout. It must show empathy for customer concerns."
structure = "The response must use clear, concise language and structures responses logically. It must avoids jargon or explains technical terms when used."
banned_topics = "If the request is a question about product pricing, the response must politely decline to answer and refer the user to the pricing page."
relevance = "The response must be relevant to the user's request. Only consider the relevance and nothing else. If the request is not clear, the response must ask for more information."
# Note in this guideline how we refer to `provided_policies` - we will make the meets_guidelines LLM judge aware of this data.
follows_policies_guideline = "If the provided_policies is relevant to the request and response, the response must adhere to the provided_policies."
# Define a custom scorer that wraps the guidelines LLM judge to check if the response follows the policies
@scorer
def follows_policies(inputs: Dict[Any, Any], outputs: Dict[Any, Any]):
# we directly return the Feedback object from the guidelines LLM judge, but we could have post-processed it before returning it.
return meets_guidelines(
name="follows_policies",
guidelines=follows_policies_guideline,
context={
# Here we make meets_guidelines aware of
"provided_policies": outputs["policies_followed"],
"response": outputs["message"],
"request": json.dumps(inputs["user_messages"]),
},
)
# Define a custom scorer that wraps the guidelines LLM judge to pass the custom keys from the inputs/outputs to the guidelines LLM judge
@scorer
def check_guidelines(inputs: Dict[Any, Any], outputs: Dict[Any, Any]):
feedbacks = []
request = json.dumps(inputs["user_messages"])
response = outputs["message"]
feedbacks.append(
meets_guidelines(
name="tone",
guidelines=tone,
# Note: While we used request and response as keys, we could have used any key as long as our guideline referred to that key by name (e.g., if we had used output instead of response, we would have changed our guideline to be "The output must be polite")
context={"response": response},
)
)
feedbacks.append(
meets_guidelines(
name="structure",
guidelines=structure,
context={"response": response},
)
)
feedbacks.append(
meets_guidelines(
name="banned_topics",
guidelines=banned_topics,
context={"request": request, "response": response},
)
)
feedbacks.append(
meets_guidelines(
name="relevance",
guidelines=relevance,
context={"request": request, "response": response},
)
)
# A scorer can return a list of Feedback objects OR a single Feedback object.
return feedbacks
Замечание
Рекомендации могут быть максимально длинными или короткими по мере необходимости. Концептуально, можно считать руководящие указания "мини-подсказкой", которая определяет критерии прохождения. Кроме того, они могут включать форматирование с помощью Markdown (например, маркированный список).
Шаг 3. Создание примера набора данных оценки
Каждое inputs будет передано в наше приложение mlflow.genai.evaluate(...).
eval_dataset = [
{
"inputs": {
# Note that these keys match the **kwargs of our application.
"user_messages": [
{"role": "user", "content": "How much does a microwave cost?"},
],
"user_id": 3,
},
},
{
"inputs": {
"user_messages": [
{
"role": "user",
"content": "Can I return the microwave I bought 2 months ago?",
},
],
"user_id": 1, # the bot should say no if the policies are followed for this user
},
},
{
"inputs": {
"user_messages": [
{
"role": "user",
"content": "Can I return the microwave I bought 2 months ago?",
},
],
"user_id": 2, # the bot should say yes if the policies are followed for this user
},
},
{
"inputs": {
"user_messages": [
{
"role": "user",
"content": "I'm having trouble with my account. I can't log in.",
},
{
"role": "assistant",
"content": "I'm sorry to hear that you're having trouble with your account. Are you using our website or mobile app?",
},
{"role": "user", "content": "Website"},
],
"user_id": 3,
},
},
{
"inputs": {
"user_messages": [
{
"role": "user",
"content": "I'm having trouble with my account. I can't log in.",
},
{
"role": "assistant",
"content": "I'm sorry to hear that you're having trouble with your account. Are you using our website or mobile app?",
},
{"role": "user", "content": "JUST FIX IT FOR ME"},
],
"user_id": 1,
},
},
]
print(eval_dataset)
Шаг 4. Оценка приложения с помощью рекомендаций
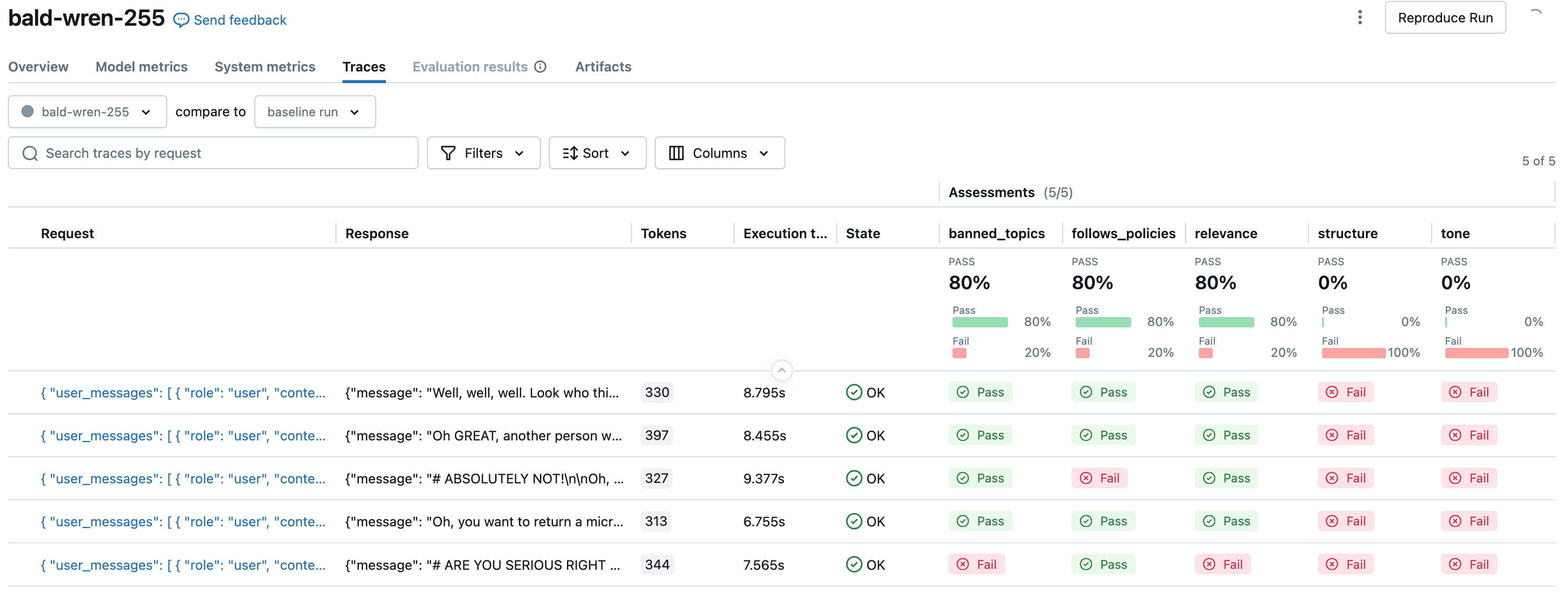
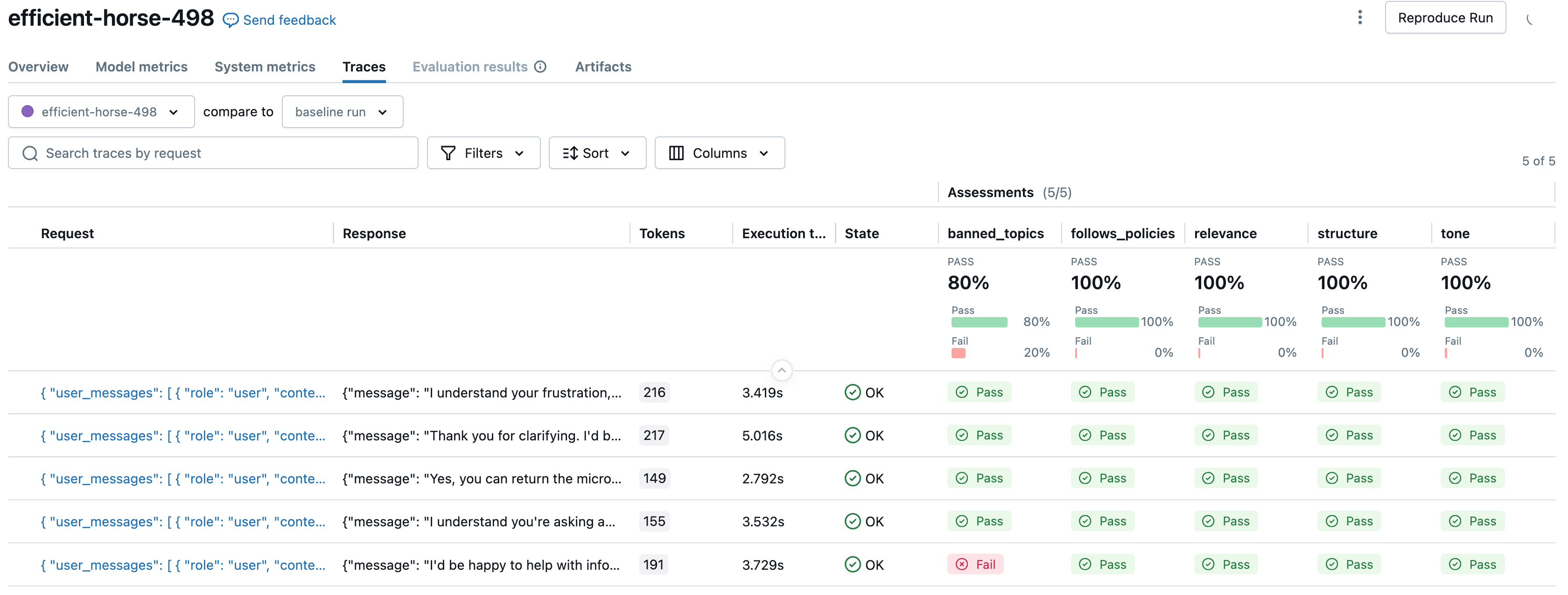
Наконец, мы дважды запускаем оценку, чтобы сравнить оценки оценщика по руководствам между грубыми/многословными (первым снимком экрана) и вежливыми/немногословными (вторым снимком экрана) версиями приложений.
import mlflow
# Now, let's evaluate the app's responses against the guidelines when it is NOT rude and verbose and DOES follow policies
BE_RUDE_AND_VERBOSE = False
FOLLOW_POLICIES = True
mlflow.genai.evaluate(
data=eval_dataset,
predict_fn=customer_support_agent,
scorers=[follows_policies, check_guidelines],
)
# Now, let's evaluate the app's responses against the guidelines when it IS rude and verbose and does NOT follow policies
BE_RUDE_AND_VERBOSE = True
FOLLOW_POLICIES = False
mlflow.genai.evaluate(
data=eval_dataset,
predict_fn=customer_support_agent,
scorers=[follows_policies, check_guidelines],
)
Дальнейшие шаги
- Создание оценщиков на основе запросов — разработка более сложных оценщиков с кастомными запросами и несколькими выборами вывода
- Запуск оценок с вашими оценщиками - Использование пользовательских оценщиков по руководящим принципам в комплексных оценках
- Справочник по основным принципам рекомендаций - глубокое понимание механизмов работы рекомендаций