Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Узнайте, как организовывать записные книжки и модулировать код в записных книжках. Ознакомьтесь с примерами и поймите, когда следует использовать альтернативные методы для оркестрации ноутбуков.
Методы оркестрации и модульизации кода
В следующей таблице сравниваются методы, доступные для управления записными книжками и модульности кода в записных книжках.
| Метод | Вариант использования | Примечания |
|---|---|---|
| Задания Lakeflow | Оркестрация записной книжки (рекомендуется) | Рекомендуемый метод для оркестрации записных книжек. Поддерживает сложные рабочие процессы с зависимостями задач, планированием и триггерами. Обеспечивает надежный и масштабируемый подход для рабочих нагрузок, но требует установки и настройки. |
| dbutils.notebook.run() | Оркестрация блокнота | Используйте dbutils.notebook.run(), если задания не подходят для вашего сценария использования, например для динамического запуска блокнота на основе файла метаданных (ETL на основе метаданных).Запускает новое эфемерное задание для каждого вызова, что может увеличить накладные расходы и не обладает расширенными функциями планирования. |
| файлы рабочей области | Модульизация кода (рекомендуется) | Рекомендуемый метод для модульного анализа кода. Разбивайте код на модули, чтобы хранить их в многократно используемых файлах в рабочей области. Поддерживает управление версиями с репозиториями и интеграцией с idEs для улучшения отладки и модульного тестирования. Требуется дополнительная настройка для управления путями файлов и зависимостями. |
| %run | Модульизация кода | Используйте, %run если вы не можете получить доступ к файлам рабочей области.Импортируйте функции или переменные из других блокнотов, исполняя их напрямую. Полезно для прототипирования, но может привести к тесно связанному коду, который сложнее поддерживать. Не поддерживает передачу параметров или управление версиями. |
%run и dbutils.notebook.run()
Эта %run команда позволяет встроить одну записную книжку в другую. Вы можете использовать %run для модульизации кода, поставив вспомогательные функции в отдельную записную книжку. Его также можно использовать для объединения записных книжек, которые реализуют шаги анализа. При использовании %run вызванная записная книжка выполняется немедленно, а функции и переменные, определенные в ней, становятся доступными в вызывающей записной книжке.
API dbutils.notebook дополняет %run, так как позволяет передавать параметры и возвращать значения из записной книжки. Это позволяет создавать сложные рабочие процессы и конвейеры с зависимостями. Например, можно получить список файлов в каталоге и передать имена в другую записную книжку, что невозможно с %run. Вы также можете создавать рабочие процессы if-then-else на основе возвращаемых значений.
В отличие от %run метод dbutils.notebook.run() запускает новое задание для запуска записной книжки.
Как и все API dbutils, эти методы доступны только в Python и Scala. Тем не менее, можно использовать dbutils.notebook.run() для вызова ноутбука R.
Использование %run для импорта записной книжки
В этом примере первая записная книжка определяет функцию reverse, которая доступна во второй записной книжке после использования %run магической команды для выполнения shared-code-notebook.
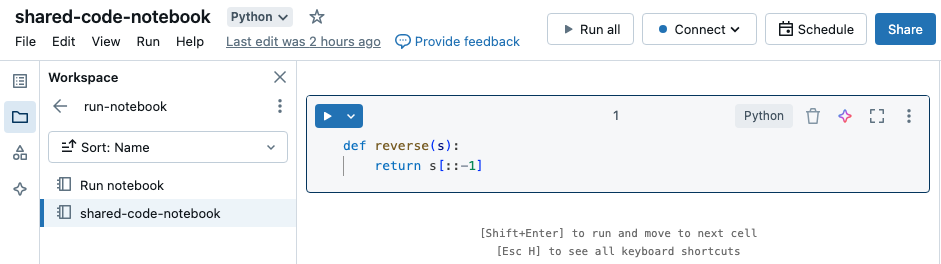
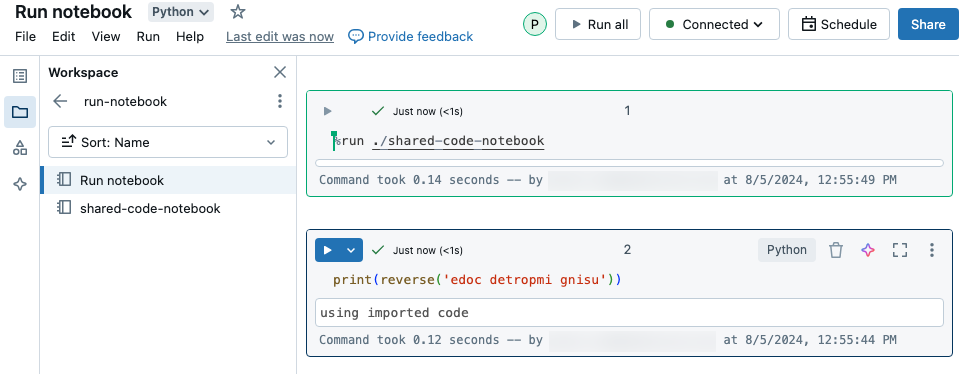
Поскольку оба ноутбука находятся в одном каталоге рабочей области, используйте префикс ./ в ./shared-code-notebook, чтобы указать, что путь должен быть определен относительно текущего запускаемого ноутбука. Записные книжки можно упорядочить в каталоги, например %run ./dir/notebook, или использовать абсолютный путь, например %run /Users/username@organization.com/directory/notebook.
Примечание.
-
%runдолжен находиться в ячейке отдельно, так как он выполняет ноутбук целиком. - Вы не можете использовать
%runдля запуска файла Python и импортированияimportсущностей, определенных в этом файле, в записную книжку. Чтобы импортировать из файла Python, см. в разделе Модульная организация кода с помощью файлов. Или упакуйте файл в библиотеку Python, создайте библиотеку Azure Databricks из этой библиотеки Python и установите библиотеку в кластер, который вы используете для выполнения записной книжки. - При использовании
%runдля запуска записной книжки, содержащей мини-приложения, по умолчанию указанная записная книжка выполняется со значениями по умолчанию мини-приложения. Вы также можете передавать значения в виджеты; см. Использование виджетов Databricks с %run.
использовать dbutils.notebook.run для запуска нового задания
Запустите ноутбук и верните его код завершения. Метод запускает кратковременное задание, которое выполняется немедленно.
Методы, доступные в API dbutils.notebook, это run и exit. Оба параметра и возвращаемые значения должны быть строками.
run(path: String, timeout_seconds: int, arguments: Map): String
Параметр timeout_seconds управляет тайм-аутом выполнения (0 означает отсутствие тайм-аута).
run Вызов вызывает исключение, если оно не завершается в течение указанного времени. Если Azure Databricks работает более 10 минут, выполнение записной книжки завершается сбоем независимо от timeout_seconds.
Параметр arguments задает значения виджетов целевой записной книжки. В частности, если в работающей записной книжке содержится виджет A, и вы передаете ("A": "B") пары "ключ-значение" в составе параметра аргументов в вызове run(), то при извлечении значения виджет A вернет значение "B". Инструкции по созданию и работе с мини-приложениями можно найти на странице мини-приложений Databricks .
Примечание.
- Параметр
argumentsпринимает только латинские символы (набор символов ASCII). Использование символов, отличных от ASCII, возвращает ошибку. - Задания, созданные с помощью API
dbutils.notebook, должны выполняться в течение 30 дней или менее.
run Использование
Python
dbutils.notebook.run("notebook-name", 60, {"argument": "data", "argument2": "data2", ...})
язык программирования Scala
dbutils.notebook.run("notebook-name", 60, Map("argument" -> "data", "argument2" -> "data2", ...))
Передача структурированных данных между записными книжками
В этом разделе показано, как передавать структурированные данные между записными книжками.
Python
# Example 1 - returning data through temporary views.
# You can only return one string using dbutils.notebook.exit(), but since called notebooks reside in the same JVM, you can
# return a name referencing data stored in a temporary view.
## In callee notebook
spark.range(5).toDF("value").createOrReplaceGlobalTempView("my_data")
dbutils.notebook.exit("my_data")
## In caller notebook
returned_table = dbutils.notebook.run("LOCATION_OF_CALLEE_NOTEBOOK", 60)
global_temp_db = spark.conf.get("spark.sql.globalTempDatabase")
display(table(global_temp_db + "." + returned_table))
# Example 2 - returning data through DBFS.
# For larger datasets, you can write the results to DBFS and then return the DBFS path of the stored data.
## In callee notebook
dbutils.fs.rm("/tmp/results/my_data", recurse=True)
spark.range(5).toDF("value").write.format("parquet").save("dbfs:/tmp/results/my_data")
dbutils.notebook.exit("dbfs:/tmp/results/my_data")
## In caller notebook
returned_table = dbutils.notebook.run("LOCATION_OF_CALLEE_NOTEBOOK", 60)
display(spark.read.format("parquet").load(returned_table))
# Example 3 - returning JSON data.
# To return multiple values, you can use standard JSON libraries to serialize and deserialize results.
## In callee notebook
import json
dbutils.notebook.exit(json.dumps({
"status": "OK",
"table": "my_data"
}))
## In caller notebook
import json
result = dbutils.notebook.run("LOCATION_OF_CALLEE_NOTEBOOK", 60)
print(json.loads(result))
язык программирования Scala
// Example 1 - returning data through temporary views.
// You can only return one string using dbutils.notebook.exit(), but since called notebooks reside in the same JVM, you can
// return a name referencing data stored in a temporary view.
/** In callee notebook */
sc.parallelize(1 to 5).toDF().createOrReplaceGlobalTempView("my_data")
dbutils.notebook.exit("my_data")
/** In caller notebook */
val returned_table = dbutils.notebook.run("LOCATION_OF_CALLEE_NOTEBOOK", 60)
val global_temp_db = spark.conf.get("spark.sql.globalTempDatabase")
display(table(global_temp_db + "." + returned_table))
// Example 2 - returning data through DBFS.
// For larger datasets, you can write the results to DBFS and then return the DBFS path of the stored data.
/** In callee notebook */
dbutils.fs.rm("/tmp/results/my_data", recurse=true)
sc.parallelize(1 to 5).toDF().write.format("parquet").save("dbfs:/tmp/results/my_data")
dbutils.notebook.exit("dbfs:/tmp/results/my_data")
/** In caller notebook */
val returned_table = dbutils.notebook.run("LOCATION_OF_CALLEE_NOTEBOOK", 60)
display(sqlContext.read.format("parquet").load(returned_table))
// Example 3 - returning JSON data.
// To return multiple values, use standard JSON libraries to serialize and deserialize results.
/** In callee notebook */
// Import jackson json libraries
import com.fasterxml.jackson.module.scala.DefaultScalaModule
import com.fasterxml.jackson.module.scala.experimental.ScalaObjectMapper
import com.fasterxml.jackson.databind.ObjectMapper
// Create a json serializer
val jsonMapper = new ObjectMapper with ScalaObjectMapper
jsonMapper.registerModule(DefaultScalaModule)
// Exit with json
dbutils.notebook.exit(jsonMapper.writeValueAsString(Map("status" -> "OK", "table" -> "my_data")))
/** In caller notebook */
// Import jackson json libraries
import com.fasterxml.jackson.module.scala.DefaultScalaModule
import com.fasterxml.jackson.module.scala.experimental.ScalaObjectMapper
import com.fasterxml.jackson.databind.ObjectMapper
// Create a json serializer
val jsonMapper = new ObjectMapper with ScalaObjectMapper
jsonMapper.registerModule(DefaultScalaModule)
val result = dbutils.notebook.run("LOCATION_OF_CALLEE_NOTEBOOK", 60)
println(jsonMapper.readValue[Map[String, String]](result))
Обработка ошибок
В этом разделе показано, как обрабатывать ошибки.
Python
# Errors throw a WorkflowException.
def run_with_retry(notebook, timeout, args = {}, max_retries = 3):
num_retries = 0
while True:
try:
return dbutils.notebook.run(notebook, timeout, args)
except Exception as e:
if num_retries > max_retries:
raise e
else:
print("Retrying error", e)
num_retries += 1
run_with_retry("LOCATION_OF_CALLEE_NOTEBOOK", 60, max_retries = 5)
язык программирования Scala
// Errors throw a WorkflowException.
import com.databricks.WorkflowException
// Since dbutils.notebook.run() is just a function call, you can retry failures using standard Scala try-catch
// control flow. Here, we show an example of retrying a notebook a number of times.
def runRetry(notebook: String, timeout: Int, args: Map[String, String] = Map.empty, maxTries: Int = 3): String = {
var numTries = 0
while (true) {
try {
return dbutils.notebook.run(notebook, timeout, args)
} catch {
case e: WorkflowException if numTries < maxTries =>
println("Error, retrying: " + e)
}
numTries += 1
}
"" // not reached
}
runRetry("LOCATION_OF_CALLEE_NOTEBOOK", timeout = 60, maxTries = 5)
Одновременный запуск нескольких блокнотов
Одновременно можно запускать несколько записных книжек с помощью стандартных конструкций Scala и Python, таких как Threads (Scala, Python) и фьючерсы (Scala, Python). В примерах записных книжек показано, как использовать эти конструкции.
- Скачайте следующие четыре записных книжки. Записные книжки написаны в Scala.
- Импортируйте записные книжки в одну папку в рабочей области.
- Запустите записную книжку одновременного выполнения.