Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Это важно
Автомасштабирование Lakebase находится в бета-версии в следующих регионах: eastus2, , westeuropewestus.
Автомасштабирование Lakebase — это последняя версия Lakebase с автомасштабированием вычислений, масштабированием до нуля, ветвлением и мгновенным восстановлением. Сравнение функций с Lakebase Provisioned см. в разделе выбора между версиями.
Панель мониторинга метрик в пользовательском интерфейсе Lakebase предоставляет графы для систем мониторинга и метрик базы данных. Панель мониторинга метрик можно получить на боковой панели в приложении Lakebase. Наблюдаемые метрики включают использование ОЗУ, использование ЦП, количество подключений, размер базы данных, взаимоблокировки, операции строк, задержки репликации, производительность кэша и размер рабочего набора.
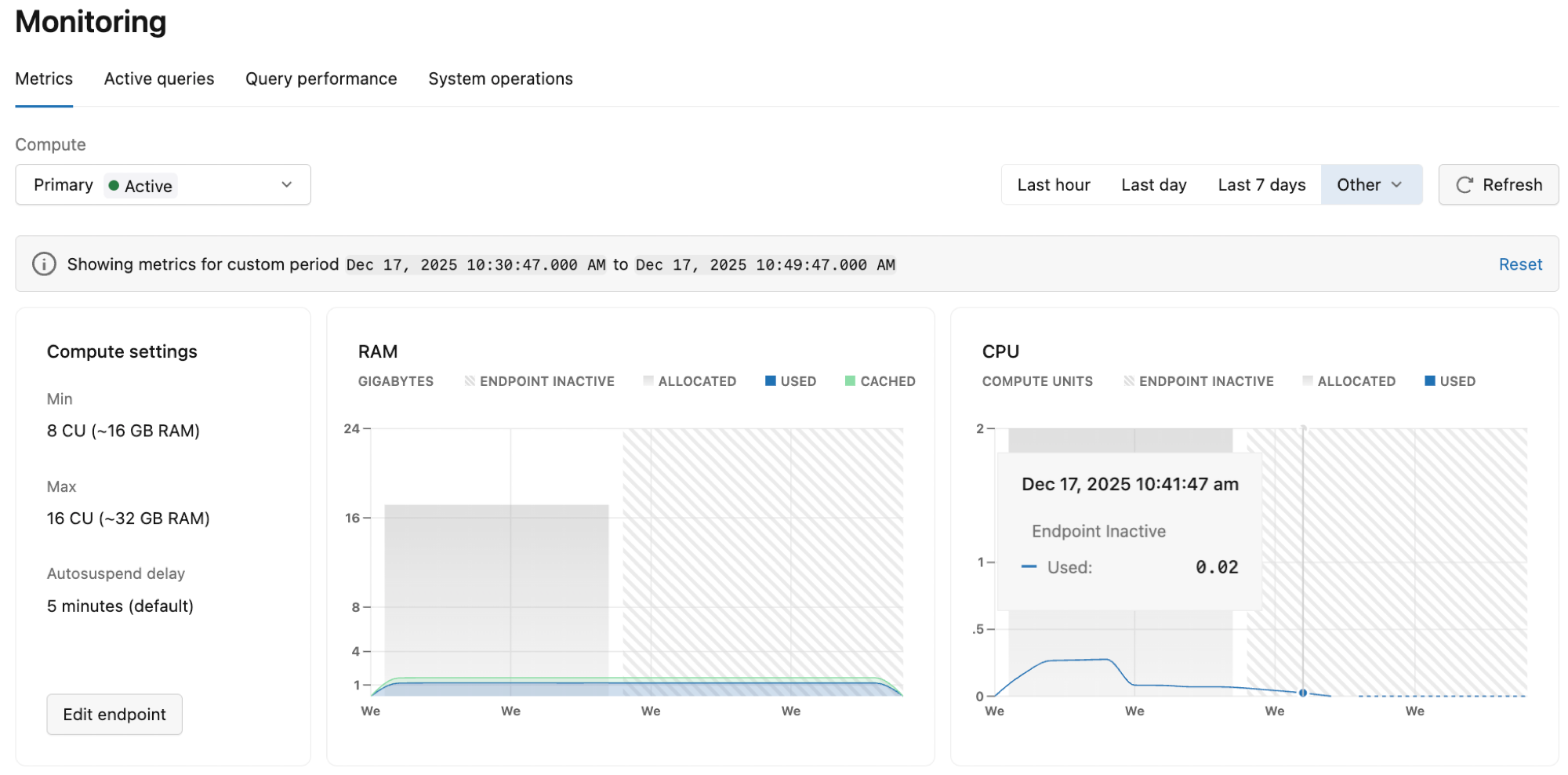
На панели мониторинга отображаются метрики для выбранной ветви и вычислений. Используйте раскрывающееся меню для просмотра метрик для другой ветви или вычислений. Можно выбрать один из стандартных периодов времени (последний час, последний день, последние 7 дней) или выбрать другие варианты (последние 3 часа, последние 6 часов, последние 12 часов, последние 2 дня или настраиваемые). Нажмите кнопку "Обновить" , чтобы обновить отображаемые метрики.
Общие сведения о неактивных вычислениях
Если графы не отображают никаких данных, вычисление может быть неактивным из-за масштабирования до нуля.
Если вычисление неактивно, значения метрик снижаются до 0, так как для отправки данных требуется активное вычисление. Неактивные периоды отображаются как диагональный узор на графиках.
Если графы не отображают данные, попробуйте выбрать другой период времени или вернуться позже после сбора дополнительных данных об использовании.
RAM
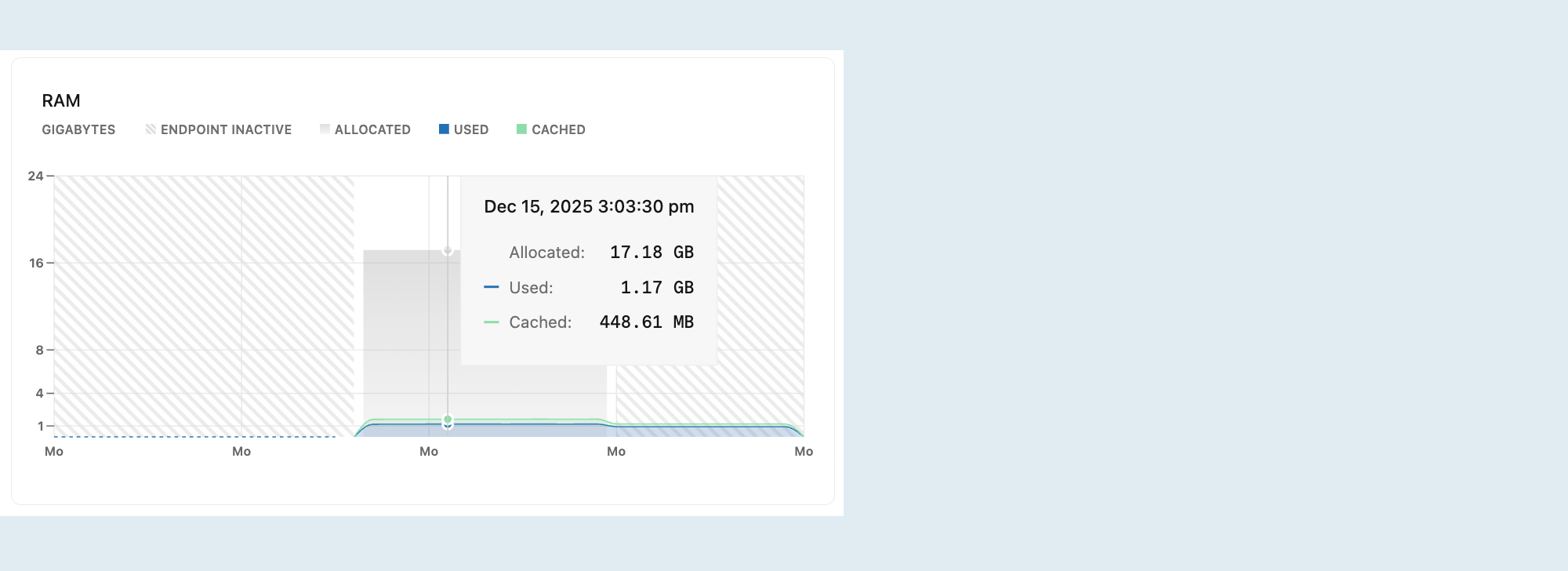
На этом графике показаны выделенные ОЗУ и использование с течением времени для выбранного вычисления.
Он включает следующие метрики:
Выделено: объем выделенной ОЗУ.
ОЗУ выделяется в соответствии с размером вычислительных ресурсов или конфигурацией автомасштабирования . При автомасштабировании выделенная память увеличивается и уменьшается по мере увеличения и уменьшения масштаба вычислительных ресурсов в ответ на нагрузку. Если масштаб до нуля включен и вычислительные ресурсы переходят в состояние простоя после бездействия, выделенная ОЗУ снижается до 0.
Используется: объем используемой ОЗУ.
График отображает строку, показывающую использование ОЗУ. Если процесс регулярно достигает максимального выделенного объема ОЗУ, рассмотрите возможность увеличения вычислительных мощностей. Параметры размера вычислений см. в разделе "Размеры вычислений".
Кэширован: объем данных, кэшированных в памяти предыдущими запросами и операциями.
ЦП
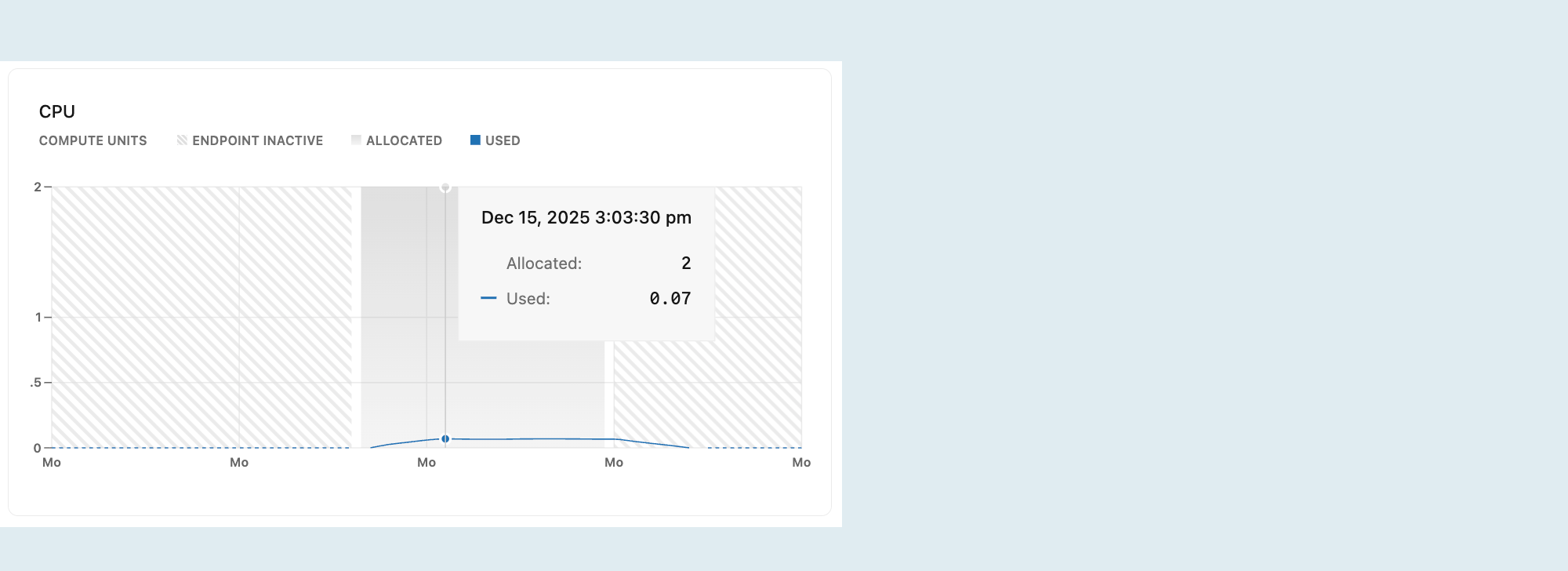
На этом графике показано выделение ЦП и использование с течением времени для выбранного вычисления.
Выделено: объем выделенного ЦП.
ЦП выделяется в соответствии с размером вычислительных ресурсов или конфигурацией автомасштабирования . При автоматическом масштабировании выделенный ЦП увеличивается и уменьшается по мере увеличения и уменьшения масштаба вычислительных ресурсов в ответ на загрузку. Если масштабирование до нуля включено и вычислительные ресурсы переходят в состояние простоя после периода неактивности, выделенный процессор сокращается до 0.
Используется: объем используемого ЦП в единицах вычислений (CU).
Если построенная линия регулярно достигает максимального выделенного ЦП, подумайте об увеличении размера вычислительных мощностей. Параметры размера вычислений см. в разделе "Размеры вычислений".
Число подключений
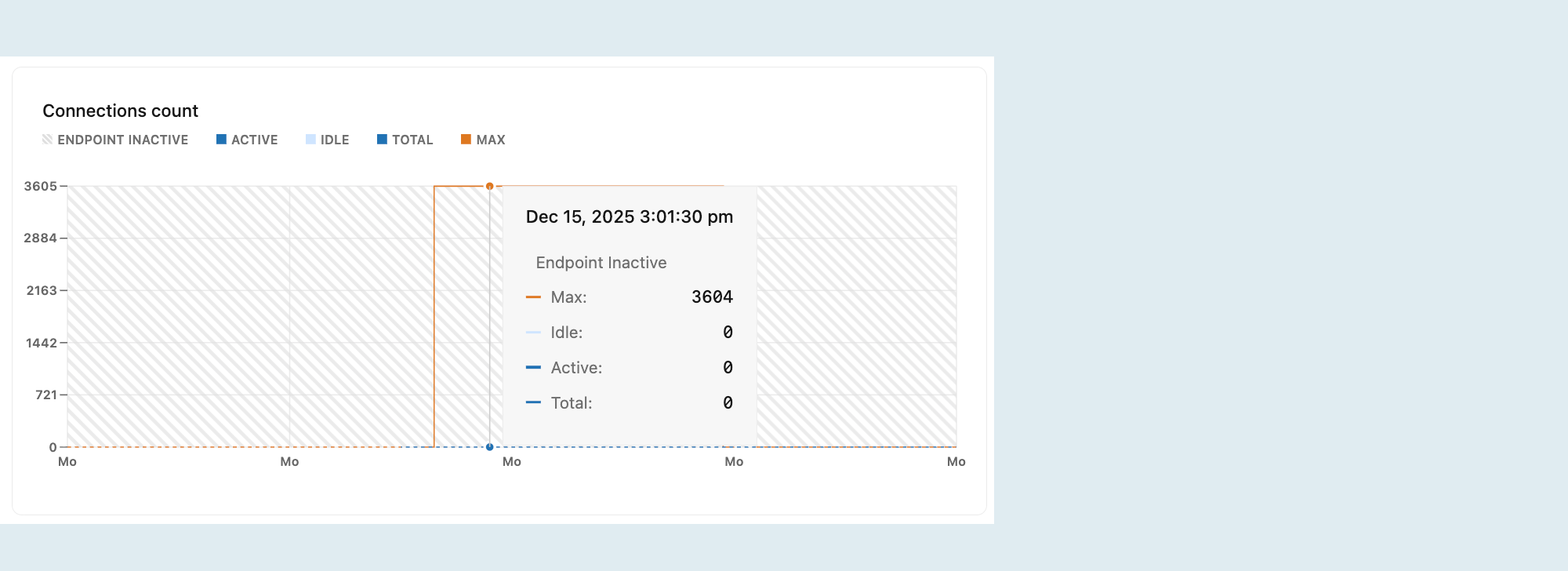
Граф счетчика подключений показывает максимальное количество подключений, количество неактивных подключений, количество активных подключений и общее количество подключений с течением времени для выбранного вычисления.
Активный: количество активных подключений для выбранного вычисления.
Мониторинг активных подключений помогает понять рабочую нагрузку базы данных. Если количество активных подключений постоянно высоко, база данных может находиться под большой нагрузкой, что может привести к проблемам производительности, таким как время отклика медленных запросов.
Простой: количество бездействуемых подключений для выбранного вычисления.
Неактивные подключения открыты, но в настоящее время не используются. Хотя несколько бездействующих подключений обычно безвредны, большое число может потреблять ненужные ресурсы, оставляя меньше места для активных подключений и потенциально влияя на производительность. Определение и закрытие ненужных неактивных подключений может помочь освободить ресурсы.
Всего: сумма активных и неактивных подключений для выбранного вычисления.
Макс. Максимальное число одновременных подключений, разрешенных для размера вычислительных ресурсов.
Линия Max помогает визуализировать, насколько близки вы к достижению лимита подключений. Когда общее число подключений приближается к строке Max, рассмотрите следующие возможности:
- Увеличение размера вычислительных ресурсов, чтобы обеспечить больше подключений
- Оптимизация управления подключениями приложения (использование пула подключений, быстрое закрытие неиспользуемых подключений и предотвращение длительного простоя подключений)
Ограничение подключения определяется параметром Postgres max_connections и определяется конфигурацией размера вычислительных ресурсов. Полный список максимальных подключений по размеру вычислительных ресурсов см. в спецификациях вычислений.
Размер базы данных
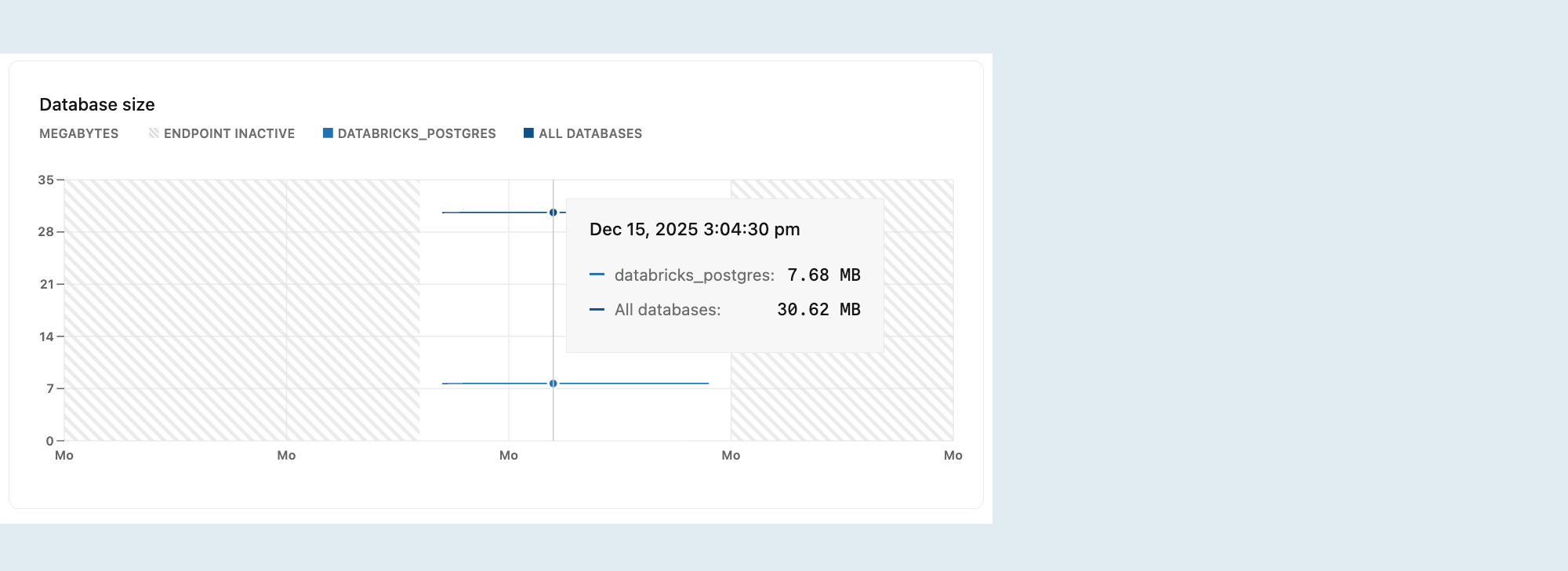
Диаграмма размера базы данных показывает логический размер данных (размер фактических данных) для выбранной базы данных или всех баз данных в выбранной ветви.
Замечание
Логический размер данных означает их объем, как сообщает Postgres, включая таблицы и индексы.
Замечание
Метрики размера базы данных отображаются только во время активности вычислений. Если вычисление неактивно, значения размера базы данных не сообщаются, и граф показывает ноль, несмотря на то, что данные могут присутствовать.
Взаимоблокировки
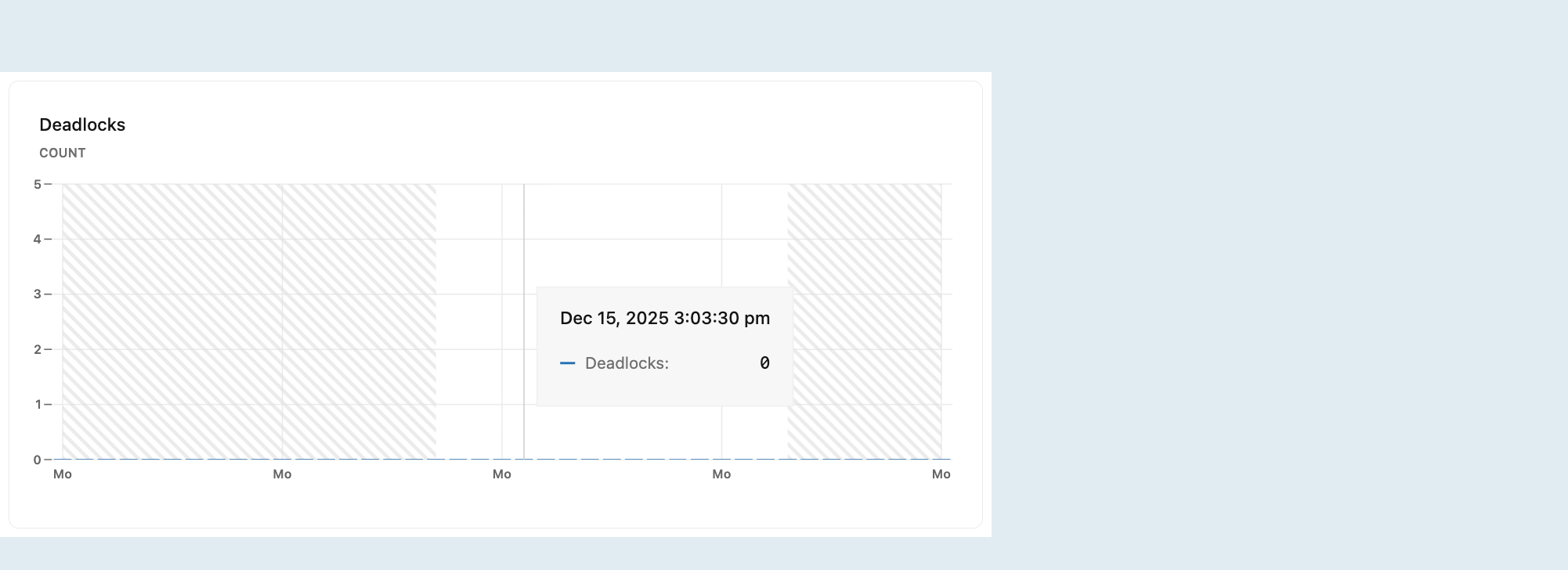
График взаимоблокировок показывает количество взаимоблокировок с течением времени.
Взаимоблокировки возникают, когда две или более транзакций одновременно блокируют друг друга, удерживая ресурсы, необходимые другим транзакциям, создавая цикл зависимостей, которые препятствуют продолжению любой транзакции. Это может привести к проблемам производительности или ошибкам приложения. Дополнительные сведения о взаимоблокировках в Postgres см. в документации PostgreSQL по взаимоблокировкам.
Rows
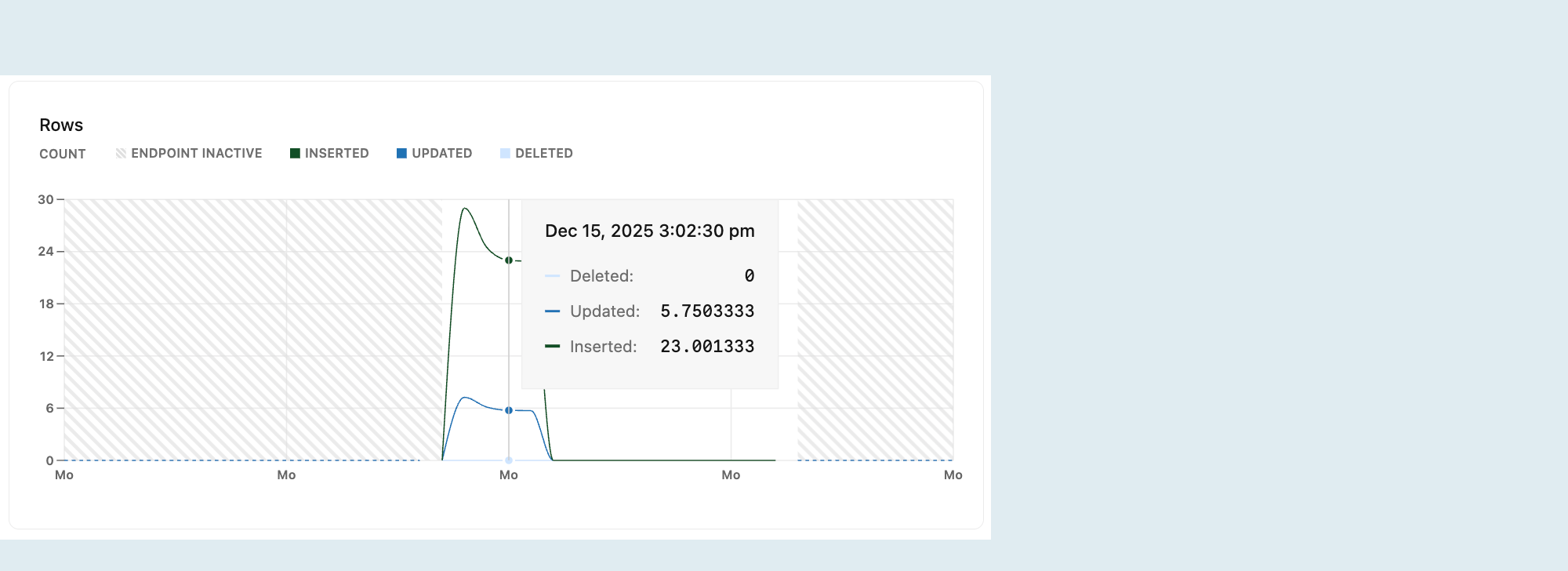
На диаграмме "Строки" отображается количество удаленных, обновленных и вставленных строк с течением времени. Метрики строк сбрасываются до нуля при перезапуске вычислительных ресурсов.
Отслеживание строк, вставленных, обновленных и удаленных с течением времени предоставляет аналитические сведения о шаблонах действий базы данных. Эти данные можно использовать для выявления тенденций или нарушений, таких как пики вставки или необычное количество удалений.
Замечание
Метрики строк фиксируют только изменения на уровне строк (INSERT, UPDATEDELETE) и исключают операции на уровне таблицы, такие как TRUNCATE.
Размер задержки репликации в байтах
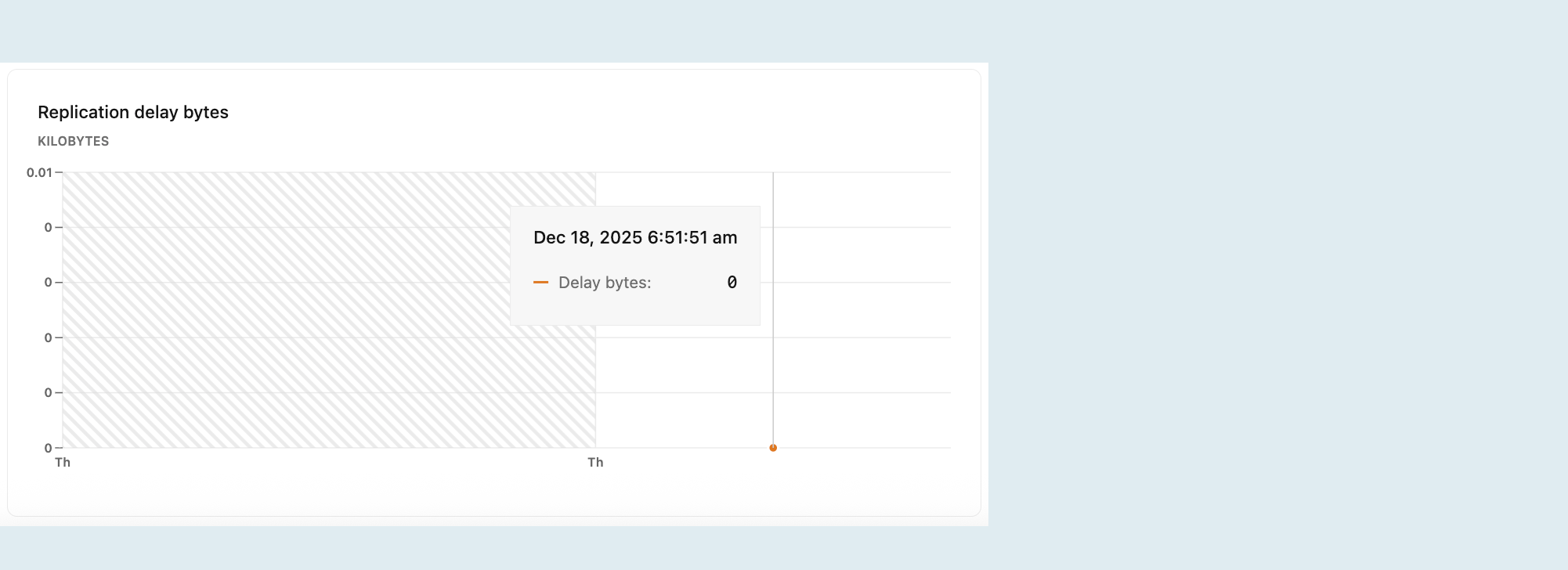
Диаграмма задержки репликации показывает общий размер данных в байтах, отправленных из основного вычисления, но еще не применен к реплике. Большее значение указывает на больший объем данных, ожидающих репликации, что может свидетельствовать о проблемах с пропускной способностью репликации или доступностью ресурсов у реплики.
Замечание
Этот граф виден только при выборе вычислений реплики чтения в раскрывающемся меню вычислений. Дополнительные сведения о репликах для чтения см. в разделе "Реплики для чтения".
Задержка репликации в секундах
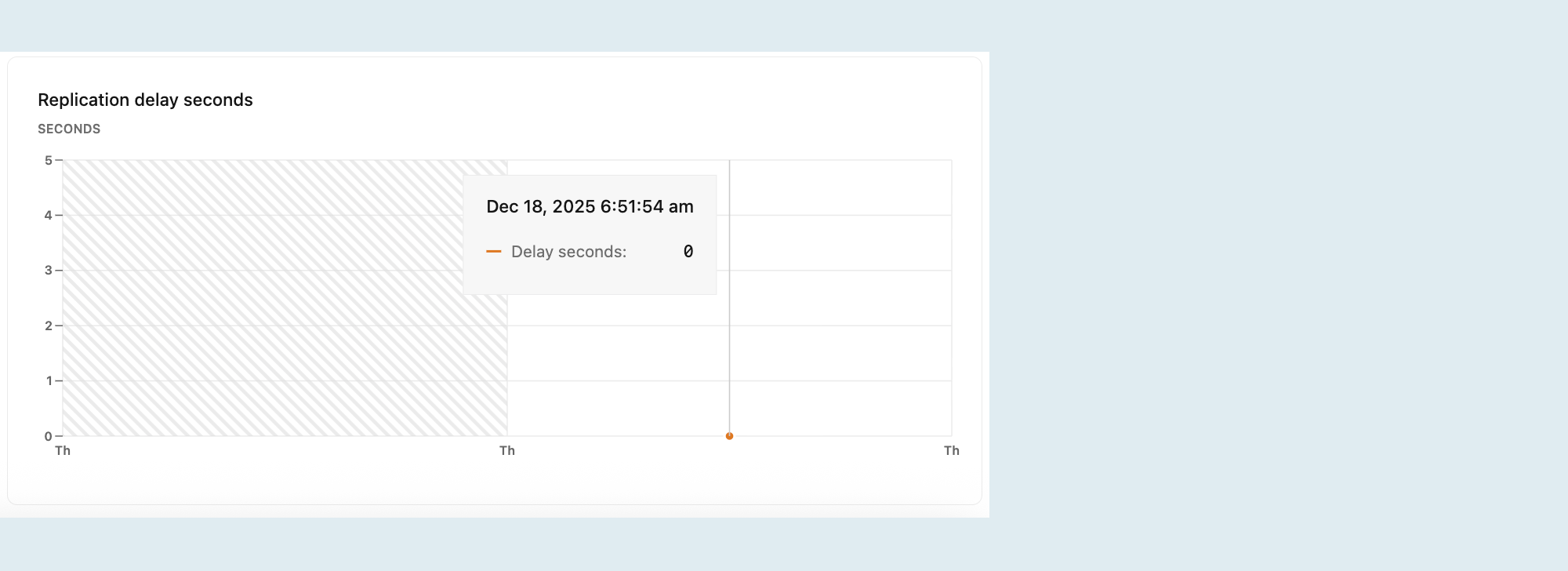
График задержки репликации показывает задержку времени (в секундах) между последней транзакцией, зафиксированной на основном вычислении, и приложением этой транзакции на реплике. Более высокое значение предполагает, что реплика находится за основной, потенциально из-за задержки сети, высокой нагрузки репликации или ограничений ресурсов на реплике.
Замечание
Этот график виден только при выборе вычислительной мощности реплики для чтения в выпадающем меню вычислений. Дополнительные сведения о репликах чтения см. в разделе "Реплики чтения".
Частота попадания в кэш локальных файлов
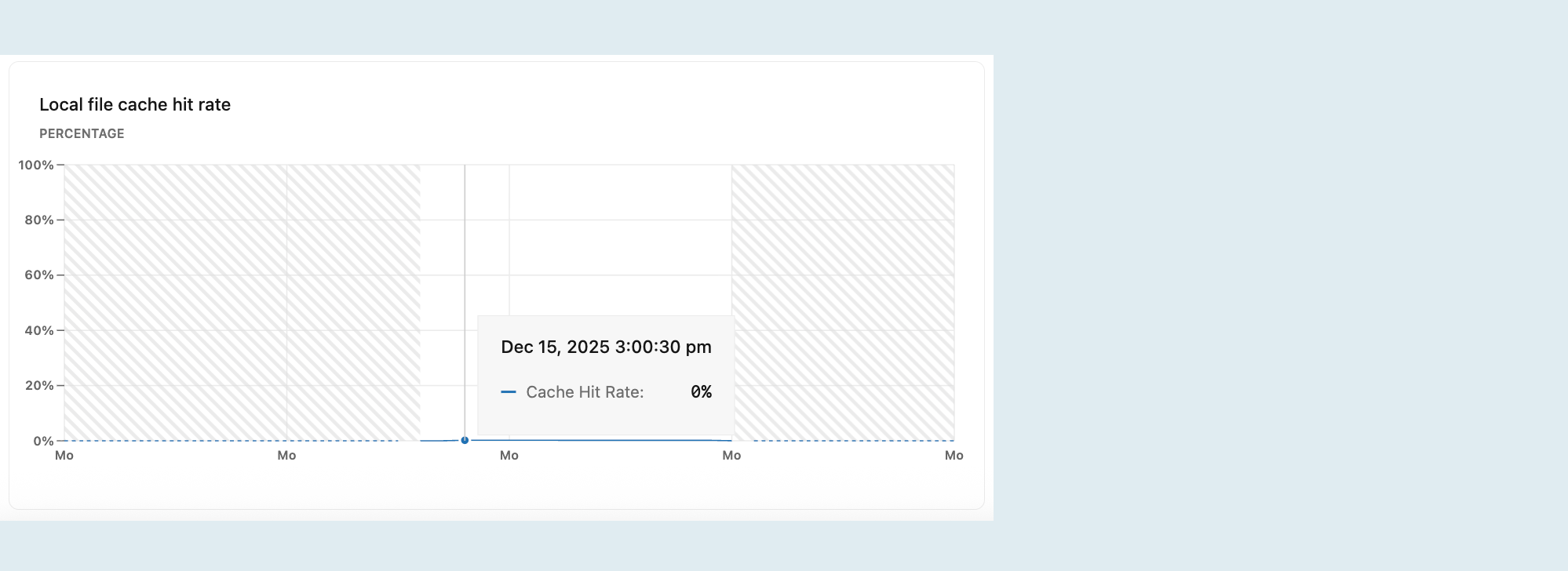
На графике частоты попаданий в кэш локальных файлов отображается процент запросов на чтение, обслуживаемых из локального кэша файлов. Запросы, не обслуживаемые из общих буферов Postgres или локального кэша файлов, извлекают данные из хранилища, что является более дорогостоящим и может привести к снижению производительности запросов.
Для рабочих нагрузок OLTP стремится к скорости попадания кэша в 99% или лучше. Если показатель ниже 99%, рабочий набор может не поместиться в память, что может привести к снижению производительности. Чтобы повысить частоту попадания в кэш, увеличьте размер вычислительных мощностей для увеличения локального кэша файлов. Идеальное соотношение зависит от рабочей нагрузки— рабочие нагрузки с последовательными сканированиями больших таблиц могут выполняться приемлемо с немного меньшим соотношением.
:::info о локальном кэше файлов
Локальный кэш файлов (LFC) — это слой кэширования, который хранит часто используемые данные в локальной памяти вашего вычислительного устройства. При запросе данных Postgres сначала проверяет общие буферы, а затем LFC и, наконец, извлекает из хранилища при необходимости. Размер LFC изменяется в зависимости от вычислительных ресурсов и может использовать до 75% ОЗУ ваших вычислительных мощностей. Например, вычисление с 8 ГБ ОЗУ имеет локальный кэш файлов в 6 ГБ. Для оптимальной производительности определите размер вычислительных ресурсов так, чтобы рабочий набор данных умещался в локальном кэше файлов.
:::
Размер рабочего набора
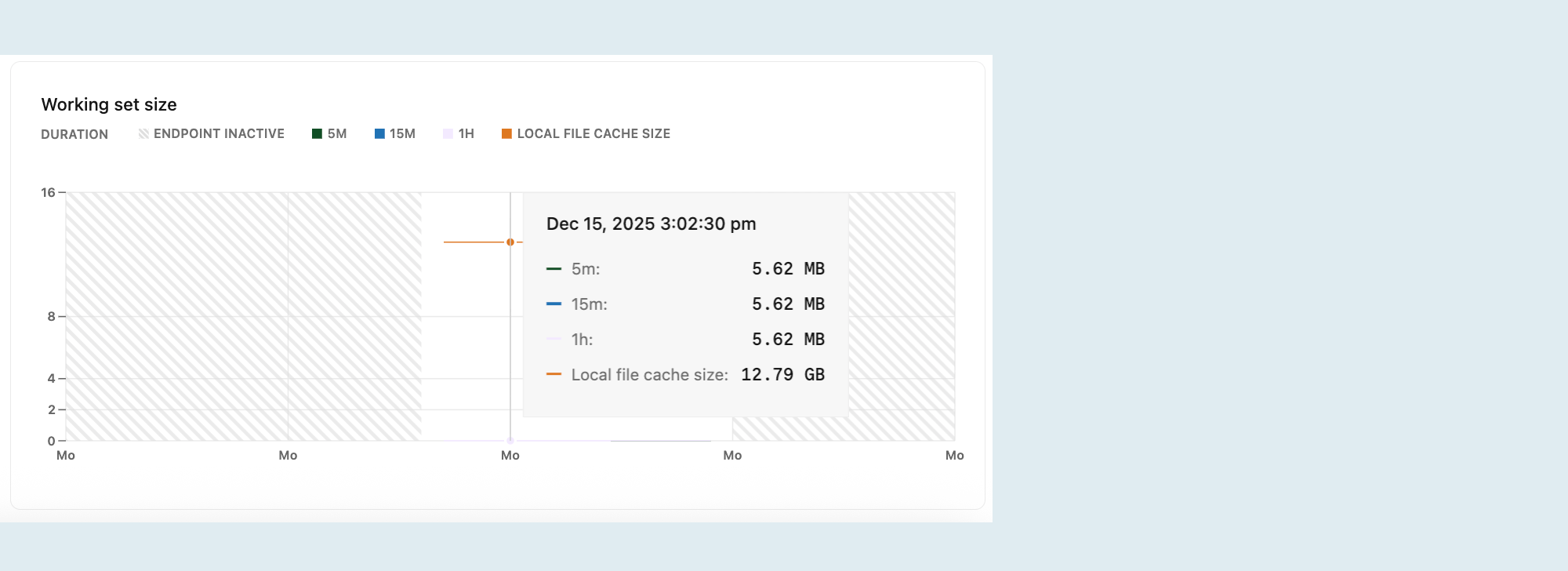
Рабочий набор — это размер отдельного набора страниц Postgres (реляционные данные и индексы), доступ к которым осуществляется в течение заданного интервала времени. Для оптимальной производительности и согласованной задержки размер вычислительных ресурсов, чтобы рабочий набор помещался в локальный кэш файлов для быстрого доступа.
График размера рабочего набора визуализирует объем доступа к данным (вычисляется как уникальные страницы, доступные × размеру страниц) за заданный интервал. На графике отображаются следующие сведения:
5 мин (5 минут): данные, к которым обращались за последние 5 минут.
15 мин (15 минут): данные, к которым обращались за последние 15 минут.
1h (1 час): данные, доступные за последний час.
Размер локального кэша файлов: размер локального кэша файлов, определенный размером вычислительных ресурсов. Большие вычислительные ресурсы имеют большие кэши.
Для оптимальной производительности локальный кэш файлов должен быть больше размера рабочего набора для заданного интервала времени. Если размер рабочего набора превышает размер локального кэша файлов, увеличьте максимальный размер вычислительных ресурсов, чтобы повысить скорость попадания кэша и повысить производительность. Сведения о параметрах и спецификациях размера вычислений см. в спецификациях вычислений.
Если с течением времени шаблон рабочей нагрузки не изменяется, сравните размер рабочего набора в 1 час с размером локального кэша файлов и убедитесь, что размер рабочего набора меньше размера локального кэша файлов.