Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Адаптивное выполнение запросов (AQE) — это оптимизация запросов, которая возникает во время выполнения запроса.
Мотивация повторной оптимизации среды выполнения заключается в том, что Azure Databricks имеет самую up-toточную статистику в конце перетасовки и широковещательного обмена (называемой этапом запроса в AQE). В результате Azure Databricks может выбрать более подходящую физическую стратегию, определить оптимальный размер и количество секций после перетасовки, либо выполнить оптимизации, которые раньше требовали подсказок, например, обработку соединений со смещением.
Это может быть очень полезно, если сбор статистики не включен или когда статистика устарела. Это также полезно в тех местах, где статически производные статистические данные являются неточными, например в середине сложного запроса, или после возникновения отклонений данных.
Возможности
AQE включен по умолчанию. Он имеет 4 основные функции:
- Динамически изменяет сортировку слиянием на вещательное хеш-соединение.
- Динамически объединяет разделы (объединение небольших разделов в разделы достаточного размера) после обмена при перемешивании. Очень небольшие задачи имеют хуже пропускной способности ввода-вывода и, как правило, страдают больше от планирования затрат и затрат на настройку задач. Объединение небольших задач экономит ресурсы и повышает пропускную способность кластера.
- Динамически обрабатывает перекос при соединении сортировочного слияния и перетасовке при хэш-соединении путем разделения (и репликации при необходимости) перекошенных задач на задачи примерно равного размера.
- Динамически определяет и распространяет пустые связи.
Приложение
AQE применяется ко всем запросам, которые:
- Нетрансляционные
- Содержит по крайней мере одно перемещение данных (обычно при соединении, агрегировании или оконной функции), один подзапрос или оба.
Не все запросы, к которым применен AQE, обязательно оптимизируются повторно. Повторная оптимизация может как создать, так и не создать иной план запроса по сравнению со статически скомпилированным. Сведения о том, был ли изменен план запроса AQE, см. в следующем разделе: планы запросов.
Планы запросов
В этом разделе описывается, как можно изучить планы запросов разными способами.
В этом разделе:
Пользовательский интерфейс Spark
узел AdaptiveSparkPlan
Запросы, примененные к AQE, содержат один или несколько узлов AdaptiveSparkPlan, которые обычно выступают в роли корневого узла каждого основного или вложенного запроса.
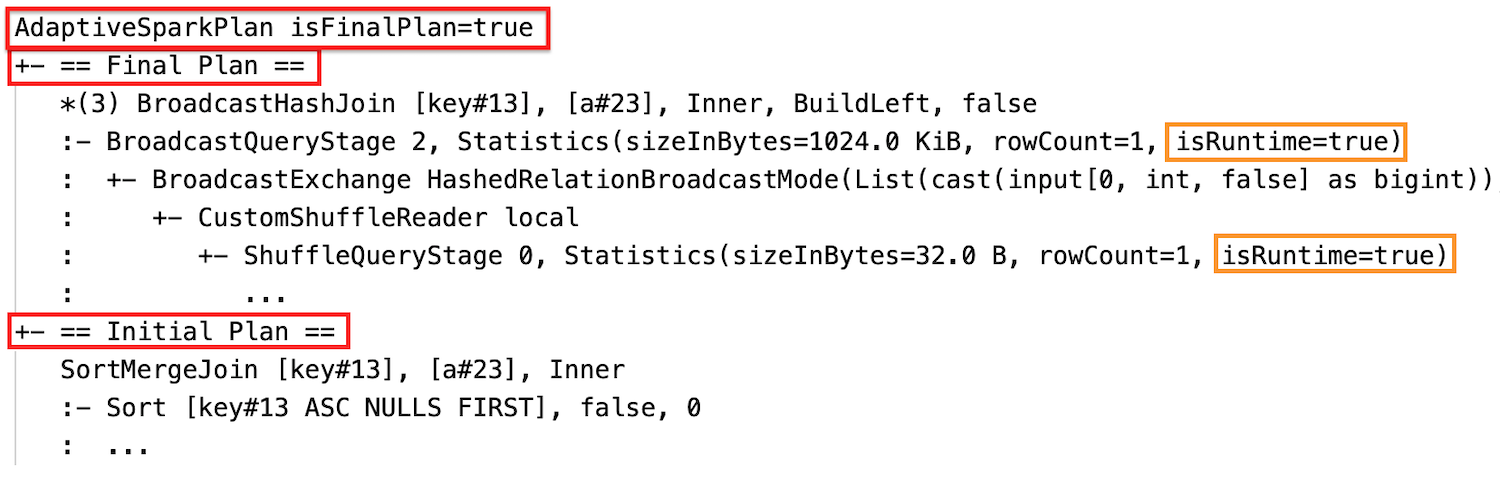
Перед запуском запроса или во время его выполнения флаг isFinalPlan соответствующего узла AdaptiveSparkPlan отображается как false; после завершения выполнения запроса флаг isFinalPlan отображается как true.
Развивающийся план
Схема плана запроса развивается по мере выполнения и отражает самый текущий план, который выполняется. Узлы, которые уже были выполнены (в которых доступны метрики), не изменятся, но те, которые еще не были выполнены, могут изменяться со временем в результате повторной оптимизации.
Ниже приведен пример схемы плана запросов:
схема плана запросов 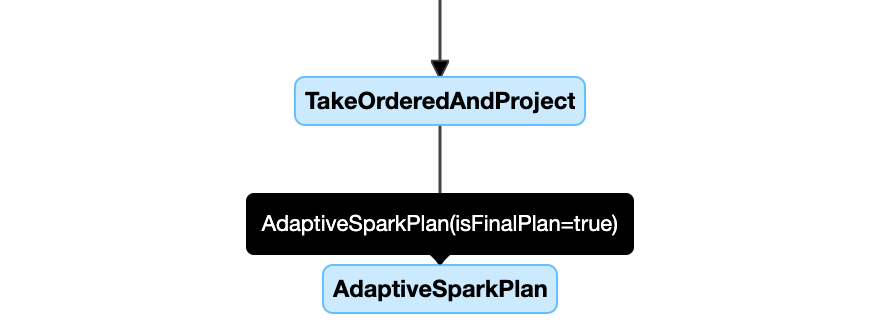
DataFrame.explain()
узел AdaptiveSparkPlan
Запросы, примененные к AQE, содержат один или несколько узлов AdaptiveSparkPlan, которые обычно выступают в роли корневого узла каждого основного или вложенного запроса. Перед выполнением запроса или во время его выполнения флаг isFinalPlan соответствующего узла AdaptiveSparkPlan отображается как false; после завершения выполнения запроса флаг isFinalPlan изменяется на true.
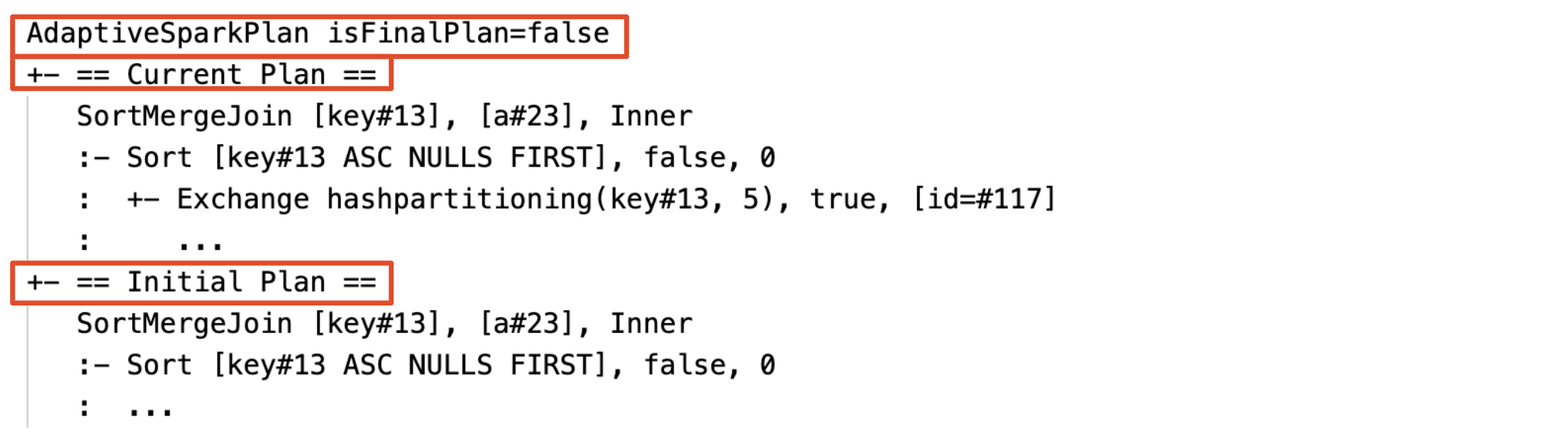
Текущий и начальный план
В каждом узле AdaptiveSparkPlan будет как начальный план (план перед применением любых оптимизаций AQE), так и текущий или окончательный план в зависимости от того, выполнено ли выполнение. Текущий план будет развиваться по мере выполнения.
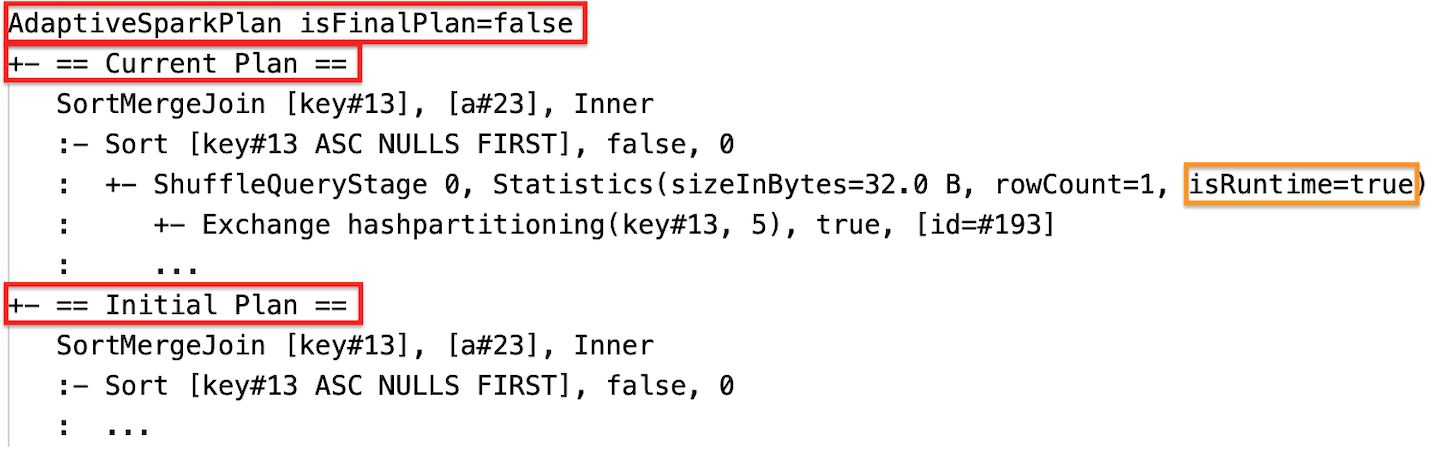
Статистика среды выполнения
Каждый этап перетасовки и трансляции содержит статистику данных.
Перед запуском этапа или при выполнении этапа статистические данные являются оценками времени компиляции, а флаг isRuntime становится false, например: Statistics(sizeInBytes=1024.0 KiB, rowCount=4, isRuntime=false);
После завершения выполнения этапа статистические данные — это те, которые собираются во время выполнения, а флаг isRuntime будет изменен на true, например: Statistics(sizeInBytes=658.1 KiB, rowCount=2.81E+4, isRuntime=true)
Ниже приведен пример DataFrame.explain:
Перед казнью
Во время выполнения
После исполнения
SQL EXPLAIN
узел AdaptiveSparkPlan
Запросы, примененные с использованием AQE, содержат один или несколько узлов AdaptiveSparkPlan, обычно в качестве корневого узла для каждого основного или вложенного запроса.
Нет текущего плана
Так как SQL EXPLAIN не выполняет запрос, текущий план всегда совпадает с начальным планом и не отражает то, что в конечном итоге будет выполнено AQE.
Ниже приведен пример с описанием SQL:

Эффективность
План запроса изменится, если одна или несколько оптимизаций AQE вступили в силу. Влияние этих оптимизаций AQE демонстрируется разницей между текущими и окончательными планами и начальным планом и конкретными узлами плана в текущих и окончательных планах.
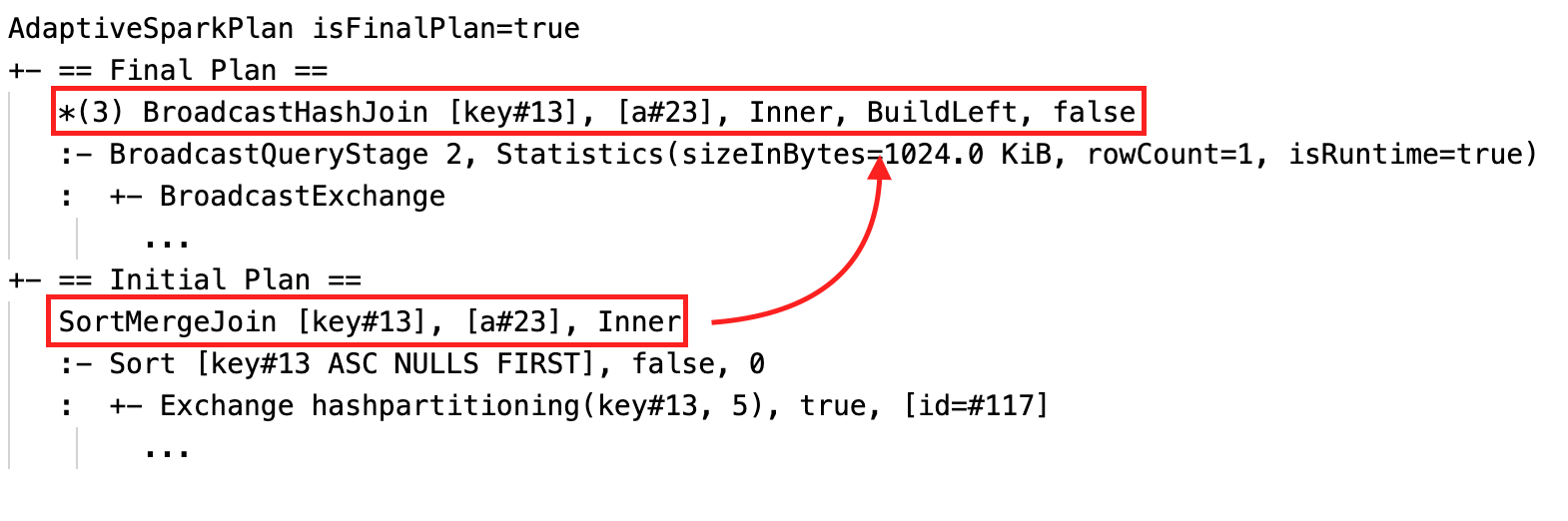
Динамическое изменение объединения сортировки слиянием в широковещательное хэш-соединение: различные узлы физического соединения между текущим и окончательным планом и начальным планом
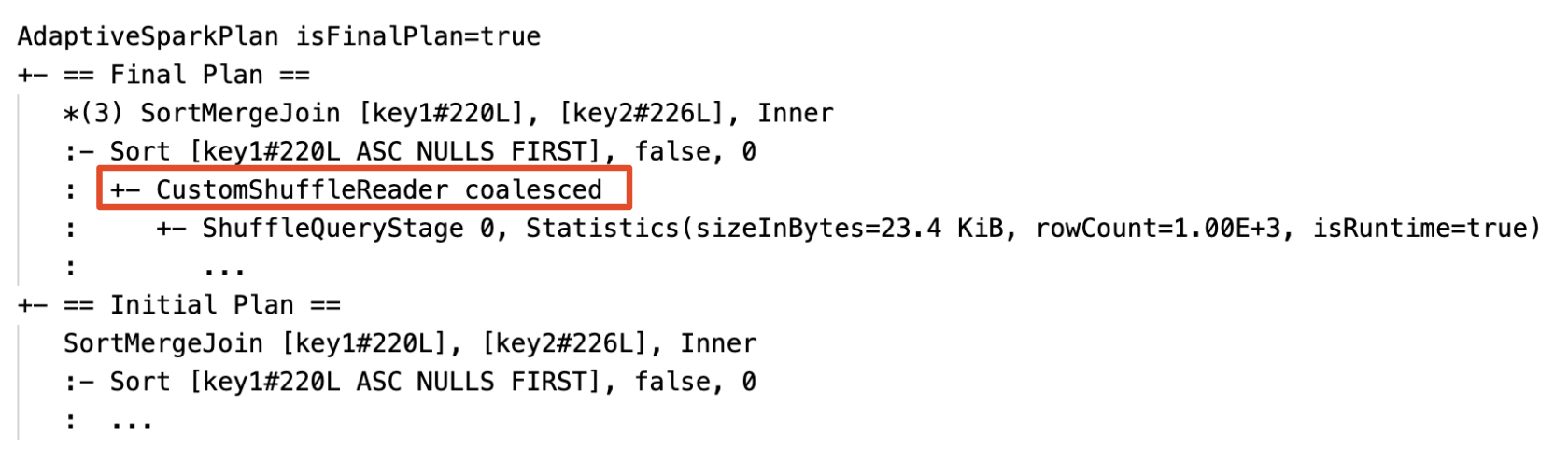
Динамическое объединение секций: узел
CustomShuffleReaderсо свойствамиCoalesced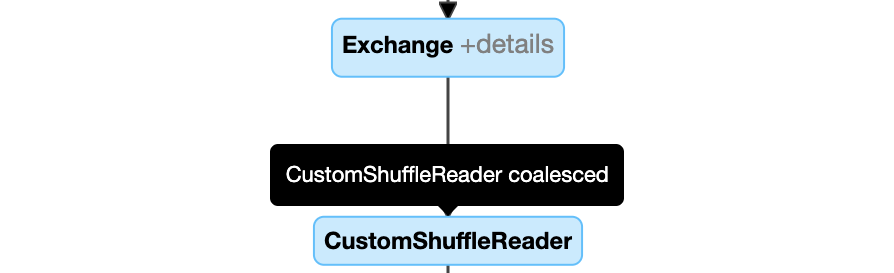
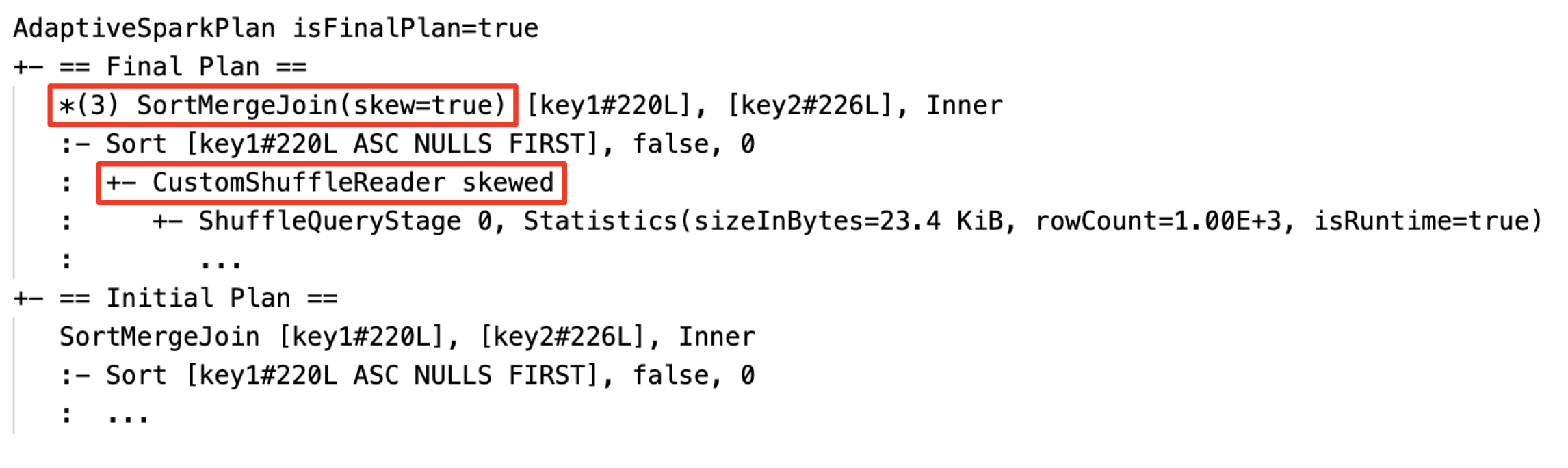
Динамическая обработка соединения с отклонением: узел
SortMergeJoinс полемisSkewв качестве истинного.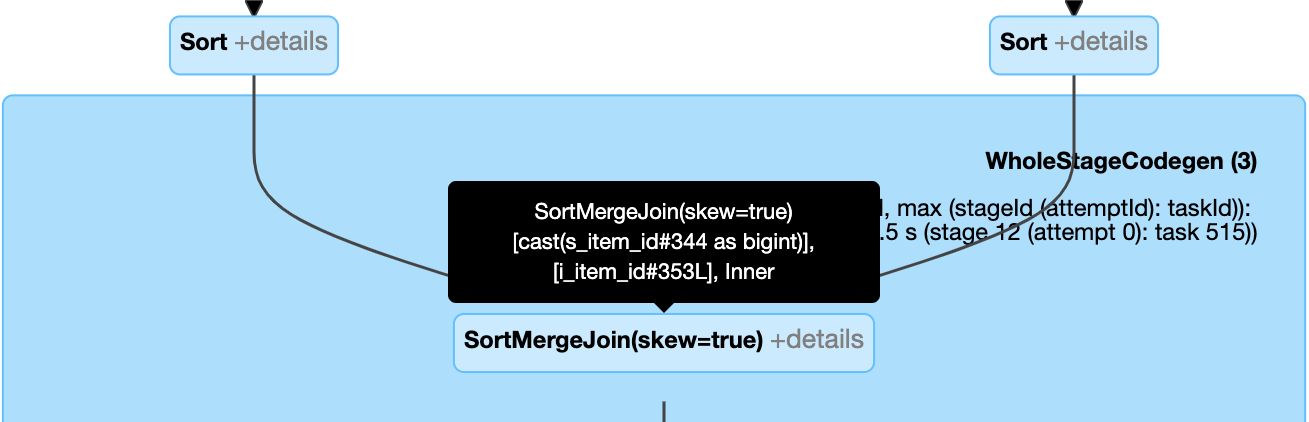
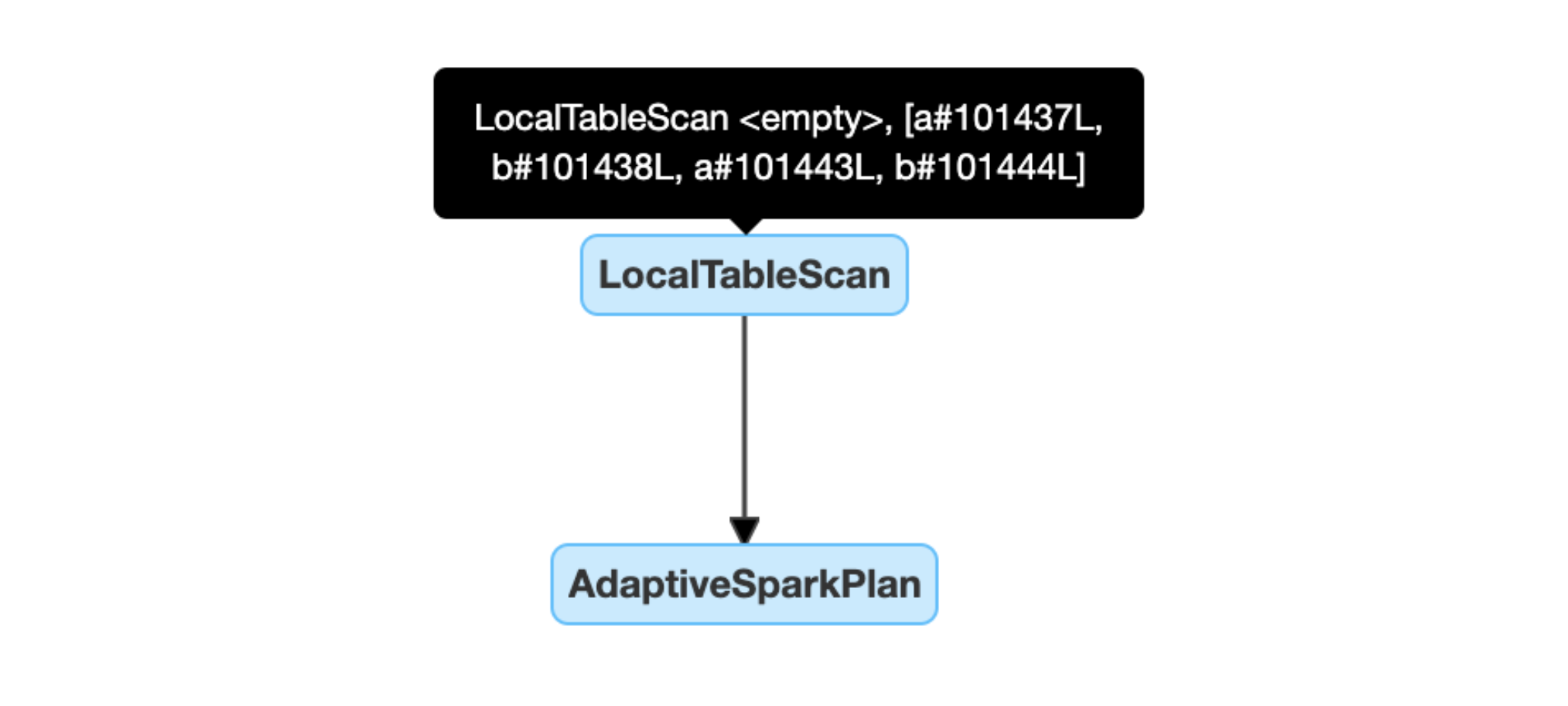
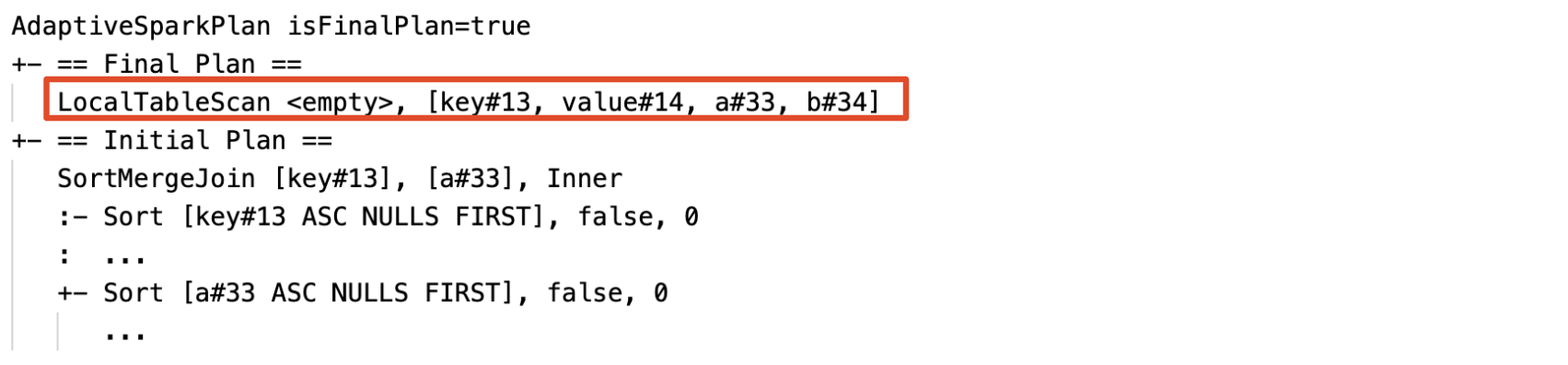
Динамическое обнаружение и распространение пустых отношений: часть (или весь) план заменяется узлом LocalTableScan с полем отношения, установленным как пустое.
Конфигурация
В этом разделе:
- Включить и отключить адаптивное выполнение запросов
- Включить автооптимизированное перетасовывание
- Динамическое изменение сортировочного объединения слиянием на вещательное хеш-объединение
- динамическое объединение разделов
- динамическая обработка смещенного соединения
- динамическое обнаружение и распространение пустых связей
Включение и отключение адаптивного выполнения запросов
| Свойство |
|---|
|
spark.databricks.optimizer.adaptive.enabled Тип: BooleanВключение или отключение адаптивного выполнения запросов. Значение по умолчанию: true |
Включить автооптимизированное перемешивание
| Свойство |
|---|
|
spark.sql.shuffle.partitions Тип: IntegerКоличество секций по умолчанию, используемых при перетасовке данных для соединений или агрегаций. Установка значения auto включает автоматическую оптимизацию преребора, которая автоматически определяет это число на основе плана запроса и размера входных данных запроса.Примечание. Для структурированной потоковой передачи эту конфигурацию нельзя изменить между перезапусками запросов из одного расположения контрольной точки. Значение по умолчанию: 200 |
Динамическое изменение соединения слияния сортировки в вещательное хэш-соединение
| Свойство |
|---|
|
spark.databricks.adaptive.autoBroadcastJoinThreshold Тип: Byte StringПороговое значение для активации переключения на широковещательное соединение во время выполнения. Значение по умолчанию: 30MB |
Динамическое объединение разделов
| Свойство |
|---|
|
spark.sql.adaptive.coalescePartitions.enabled Тип: BooleanВключить или отключить объединение разделов. Значение по умолчанию: true |
|
spark.sql.adaptive.advisoryPartitionSizeInBytes Тип: Byte StringЦелевой размер после объединения. Размеры объединенных разделов будут близки, но не больше указанного размера. Значение по умолчанию: 64MB |
|
spark.sql.adaptive.coalescePartitions.minPartitionSize Тип: Byte StringМинимальный размер разделов после объединения. Размеры объединенных разделов не будут меньше этого значения. Значение по умолчанию: 1MB |
|
spark.sql.adaptive.coalescePartitions.minPartitionNum Тип: IntegerМинимальное количество разделов после слияния. Не рекомендуется, так как параметр явно переопределяет spark.sql.adaptive.coalescePartitions.minPartitionSize.Значение по умолчанию: 2x количество ядер кластера |
Динамическая обработка соединения с дисбалансом
| Свойство |
|---|
|
spark.sql.adaptive.skewJoin.enabled Тип: BooleanВключение или отключение обработки соединения с отклонением. Значение по умолчанию: true |
|
spark.sql.adaptive.skewJoin.skewedPartitionFactor Тип: IntegerФактор, который при умножении на размер медианной секции способствует определению того, является ли секция перекошенной. Значение по умолчанию: 5 |
|
spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes Тип: Byte StringПороговое значение, которое определяет, имеет ли раздел смещение. Значение по умолчанию: 256MB |
Секция считается перекошенной, если и (partition size > skewedPartitionFactor * median partition size), и (partition size > skewedPartitionThresholdInBytes)true.
Динамическое обнаружение и распространение пустых связей
| Свойство |
|---|
|
spark.databricks.adaptive.emptyRelationPropagation.enabled Тип: BooleanВключение или отключение динамического распространения пустой связи. Значение по умолчанию: true |
Часто задаваемые вопросы (ЧАВО)
В этом разделе:
- Почему AQE не транслировал небольшую таблицу соединения?
- Следует ли по-прежнему использовать подсказку стратегии присоединения к трансляции с включенным AQE?
- В чем разница между подсказкой для перекошенного соединения и оптимизацией перекошенного соединения AQE? Какой из них следует использовать?
- Почему AQE не настраивает порядок присоединения автоматически?
- Почему AQE не обнаружила отклонение данных?
Почему AQE не транслировал небольшую таблицу соединения?
Если размер отношения, которое ожидается транслировать, действительно попадает под это пороговое значение, но все равно не транслируется:
- Проверьте тип соединения. Широковещательная трансляция не поддерживается для определенных типов соединений, например, левое отношение
LEFT OUTER JOINневозможно транслировать. - Также может быть так, что отношение содержит много пустых секций, и в этом случае большинство задач может быстро завершиться с сортировочным объединением или может быть оптимизировано с помощью обработки соединения с перекосом. AQE избегает изменения таких соединений слиянием сортировки для широковещательных хэш-соединений, если процент непустых секций ниже, чем
spark.sql.adaptive.nonEmptyPartitionRatioForBroadcastJoin.
Следует ли по-прежнему использовать подсказку стратегии присоединения к широковещательной трансляции с включенной функцией AQE?
Да. Статически запланированное широковещательное соединение обычно более производительное, чем динамически запланированное AQE, поскольку AQE может не переключаться на широковещательное соединение до выполнения перемешивания для обеих сторон соединения, к тому времени, когда будут получены фактические размеры отношений. Таким образом, использование подсказки широковещательной трансляции по-прежнему может быть хорошим выбором, если вы хорошо знаете ваш запрос. AQE будет учитывать указания запросов так же, как и статическая оптимизация, но по-прежнему может применять динамические оптимизации, которые не влияют на подсказки.
В чем разница между подсказкой для перекошенного соединения и оптимизацией перекошенного соединения AQE? Какой из них следует использовать?
Рекомендуется полагаться на автоматическую обработку соединений с перекосом в AQE, а не использовать подсказку для перекосов, так как обработка перекосов в AQE полностью автоматизирована и в целом работает лучше, чем способ с подсказками.
Почему AQE не скорректировал порядок присоединения автоматически?
Переупорядочение динамических соединений не является частью AQE.
Почему AQE не обнаружила отклонение данных?
Существуют два условия размера, которые должны быть выполнены для того, чтобы AQE мог идентифицировать раздел как несбалансированный:
- Размер раздела больше, чем
spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes(по умолчанию 256 МБ) - Размер раздела больше среднего размера всех разделов, умноженного на фактор перекоса раздела
spark.sql.adaptive.skewJoin.skewedPartitionFactor(по умолчанию — 5).
Кроме того, поддержка обработки отклонений ограничена для определенных типов соединений, например в LEFT OUTER JOIN, можно оптимизировать только отклонение на левой стороне.
Наследство
Термин "Адаптивное выполнение" существовал с spark 1.6, но новый AQE в Spark 3.0 принципиально отличается. С точки зрения функциональности Spark 1.6 выполняет только часть, касающуюся «динамически укрупняемых разделов». С точки зрения технической архитектуры новый AQE — это платформа динамического планирования и перепланирования запросов на основе статистики среды выполнения, которая поддерживает различные оптимизации, такие как описанные в этой статье, и может быть расширена, чтобы обеспечить более потенциальную оптимизацию.