Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
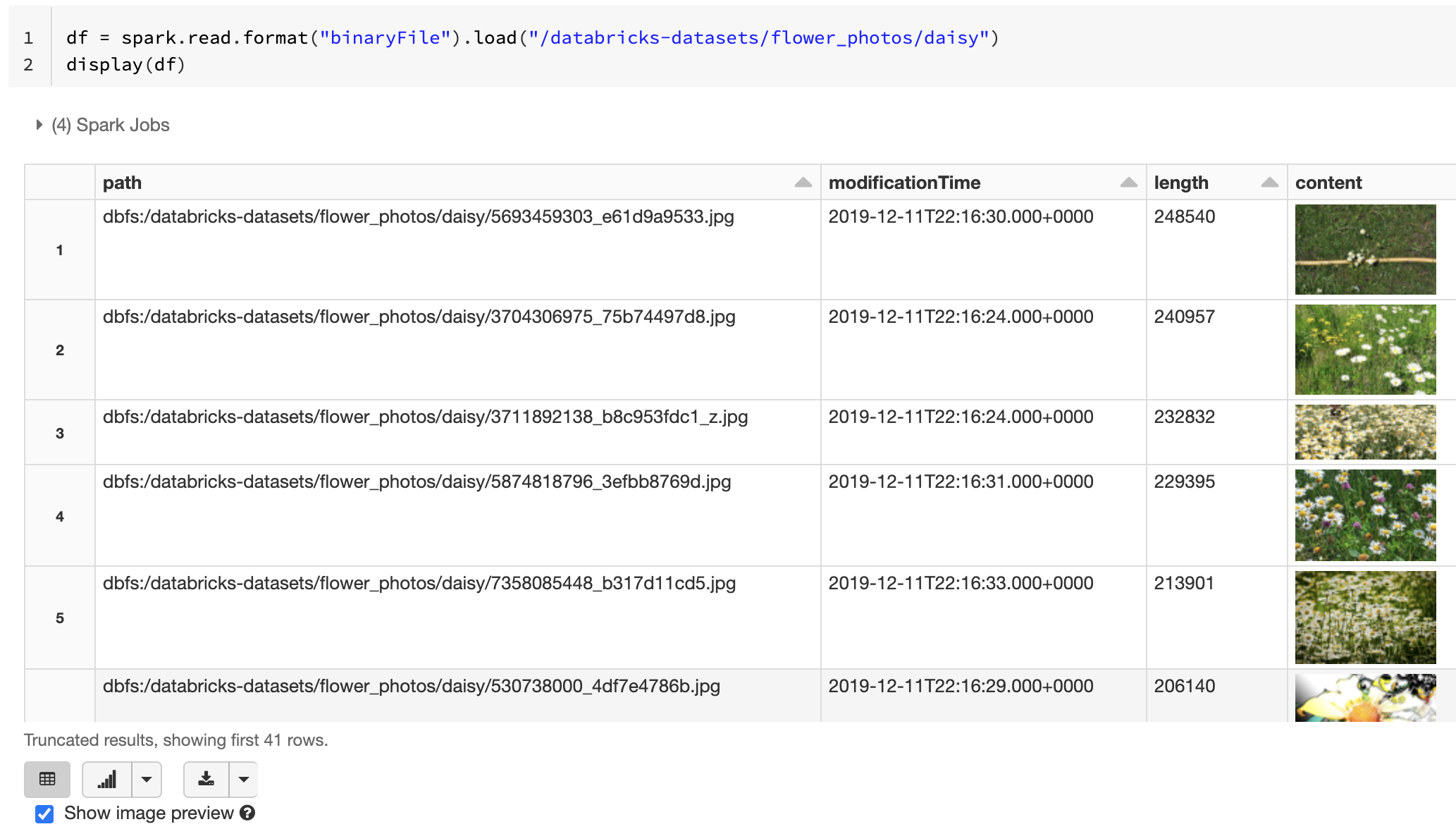
Azure Databricks поддерживает источник данных двоичного файла, который считывает двоичные файлы и преобразует каждый файл в одну запись, содержащую необработанное содержимое и метаданные файла. Обычно используется для загрузки неструктурированных данных, таких как изображения, аудио или PDF-файлы для последующей обработки или вывода машинного обучения. Для чтения двоичных файлов укажите источник данных format как binaryFile.
Prerequisites
Azure Databricks не требует дополнительной конфигурации для использования двоичных файлов.
Параметры
Используйте методы .option() и .options() объекта DataFrameReader для настройки источника данных двоичного файла. Полный список поддерживаемых параметров см. в справочнике по параметрам API Spark.
Выходная схема
Источник двоичных файлов создает DataFrame со следующими столбцами, а также всеми столбцами секционирования:
-
path (StringType): путь к файлу. -
modificationTime (TimestampType): время изменения файла. В некоторых реализациях Файловой системы Hadoop этот параметр может быть недоступен, и значение будет задано значением по умолчанию. -
length (LongType): длина файла в байтах. -
content (BinaryType): содержимое файла.
Usage
В следующих примерах показано загрузку двоичных файлов с помощью API DataFrame Spark и SQL, фильтрации по типу файла, отображению предварительных просмотров изображений и сохранению в разностной таблице для повышения производительности чтения.
Чтение двоичных файлов
Используйте API DataFrame в Apache Spark, чтобы загружать двоичные файлы в DataFrame для преобразования, вывода или последующей обработки.
Python
df = spark.read.format("binaryFile").load("/Volumes/<catalog>/<schema>/<volume>/")
display(df)
Scala
val df = spark.read.format("binaryFile").load("/Volumes/<catalog>/<schema>/<volume>/")
df.show()
SQL
SELECT path, length, modificationTime FROM read_files(
'/Volumes/<catalog>/<schema>/<volume>/images/',
format => 'binaryFile'
)
Настройка параметров чтения
Чтобы загрузить файлы с путями, соответствующими заданному шаблону глобов, при сохранении поведения обнаружения секций можно использовать параметр pathGlobFilter. Следующий код считывает все ФАЙЛЫ JPG из входного каталога с обнаружением секций:
Python
df = spark.read.format("binaryFile").option("pathGlobFilter", "*.jpg").load("/Volumes/<catalog>/<schema>/<volume>/images/")
Scala
val df = spark.read.format("binaryFile").option("pathGlobFilter", "*.jpg").load("/Volumes/<catalog>/<schema>/<volume>/images/")
SQL
SELECT * FROM read_files(
'/Volumes/<catalog>/<schema>/<volume>/images/',
format => 'binaryFile',
pathGlobFilter => '*.jpg'
)
Если вы хотите игнорировать обнаружение секций и рекурсивно искать файлы в входном каталоге, используйте параметр recursiveFileLookup. Этот параметр выполняет поиск по вложенным каталогам, даже если их имена не следуют схеме именования разделов, например date=2019-07-01.
Следующий код считывает все ФАЙЛЫ JPG рекурсивно из входного каталога и игнорирует обнаружение секций:
Python
df = (spark.read.format("binaryFile")
.option("pathGlobFilter", "*.jpg")
.option("recursiveFileLookup", "true")
.load("/Volumes/<catalog>/<schema>/<volume>/images/"))
Scala
val df = spark.read.format("binaryFile")
.option("pathGlobFilter", "*.jpg")
.option("recursiveFileLookup", "true")
.load("/Volumes/<catalog>/<schema>/<volume>/images/")
SQL
SELECT * FROM read_files(
'/Volumes/<catalog>/<schema>/<volume>/images/',
format => 'binaryFile',
pathGlobFilter => '*.jpg',
recursiveFileLookup => true
)
Загрузка и отображение изображений
Databricks рекомендует использовать источник данных двоичных файлов для загрузки данных изображений. Функция Databricks display поддерживает отображение данных изображения, загруженных с помощью двоичного источника данных.
Если все загруженные файлы имеют имя файла с расширением image, то предварительный просмотр изображения включается автоматически.
Python
df = spark.read.format("binaryFile").load("/Volumes/<catalog>/<schema>/<volume>/images/")
display(df) # image thumbnails are rendered in the "content" column
Scala
val df = spark.read.format("binaryFile").load("/Volumes/<catalog>/<schema>/<volume>/images/")
df.show()
SQL
SELECT * FROM read_files(
'/Volumes/<catalog>/<schema>/<volume>/images/',
format => 'binaryFile'
)
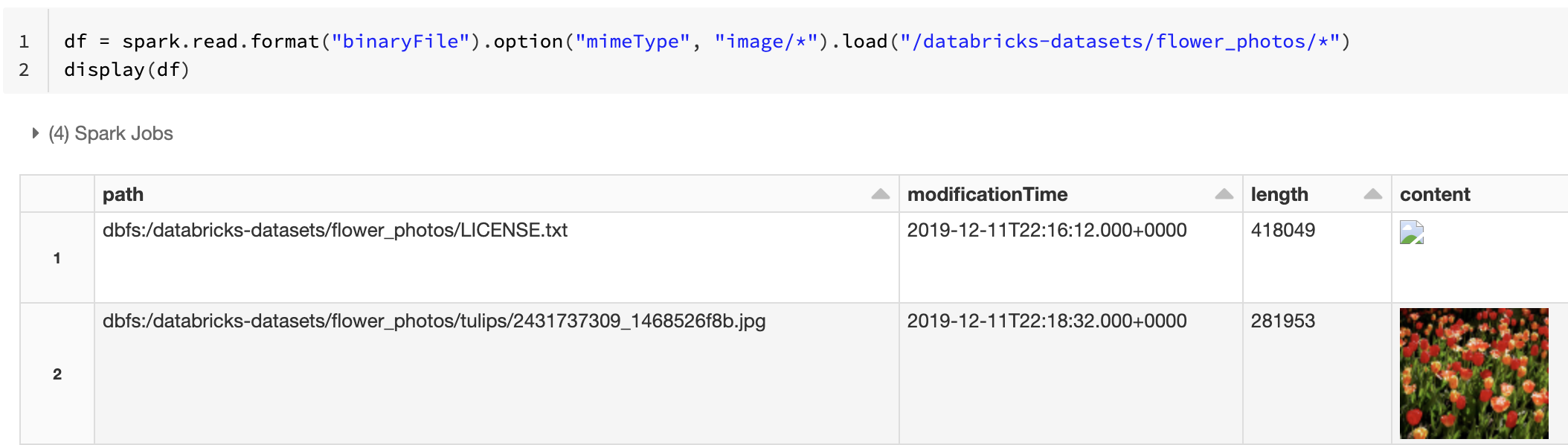
Кроме того, можно принудительно применить функцию предварительного просмотра изображений, используя параметр mimeType со строковым значением "image/*" для аннотации двоичного столбца. Изображения декодируются на основе данных о формате в двоичном содержимом. Поддерживаются следующие типы изображений: bmp, gif, jpeg и png. Неподдерживаемые файлы отображаются в виде значка поврежденного изображения.
Python
df = spark.read.format("binaryFile").option("mimeType", "image/*").load("/Volumes/<catalog>/<schema>/<volume>/images/")
display(df)
Scala
val df = spark.read.format("binaryFile").option("mimeType", "image/*").load("/Volumes/<catalog>/<schema>/<volume>/images/")
df.show()
SQL
SELECT * FROM read_files(
'/Volumes/<catalog>/<schema>/<volume>/images/',
format => 'binaryFile',
mimeType => 'image/*'
)
Рекомендуемый рабочий процесс для обработки данных изображения см. в разделе Эталонное решение для приложений, работающих с изображениями.
Сохранить в таблицу Delta
Чтобы повысить производительность чтения при загрузке данных обратно, Azure Databricks рекомендует сохранять данные, загруженные из двоичных файлов в таблицу Delta.
Python
df.write.format("delta").saveAsTable("<catalog>.<schema>.<table>")
Scala
df.write.format("delta").saveAsTable("<catalog>.<schema>.<table>")
Дополнительные ресурсы
- Чтение файлов изображений. Если для рабочей нагрузки требуются структурированные поля изображения, такие как высота, ширина и данные канала, а не необработанные байты, источник данных изображения предоставляет декодированную схему.