Примечание
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Папки Databricks Git можно использовать в потоках CI/CD. Настроив папки Databricks Git в рабочей области, вы можете использовать управление версиями для работы в репозиториях Git и интегрировать их в рабочие процессы проектирования данных. Для более полного обзора CI/CD с Azure Databricks см. в статье CI/CD в Azure Databricks.
Потоки использования
Большая часть работы в разработке автоматизации для папок Git находится в начальной конфигурации папок и в понимании REST API Azure Databricks Repos , используемого для автоматизации операций Git из заданий Azure Databricks. Прежде чем приступить к созданию папок автоматизации и настройки, просмотрите удаленные репозитории Git, которые вы будете внедрять в потоки автоматизации и выбрать подходящие для различных этапов автоматизации, включая разработку, интеграцию, промежуточное размещение и рабочую среду.
- Поток администратора. Для рабочих потоков администратор рабочей области Azure Databricks настраивает папки верхнего уровня в рабочей области для размещения рабочих папок Git. Администратор клонирует репозиторий и ветвь Git при их создании и может предоставить эти папки значимым именам, таким как Production, Test или Staging, которые соответствуют назначению удаленных репозиториев Git в потоках разработки. Дополнительные сведения см. в папке Git Production.
-
Поток пользователя: пользователь может создать папку Git под
/Workspace/Users/<email>/, на основе удаленного репозитория Git. Пользователь создает локальную ветку, специфичную для пользователя, в которую он будет вносить изменения и отправлять их в удаленный репозиторий. Сведения о совместной работе в папках Git для конкретных пользователей см. в статье "Совместная работа с помощью папок Git". - Поток слияния: пользователи могут создавать запросы на слияние (PR) после выполнения push из папки Git. При слиянии pr автоматизация может извлекать изменения в рабочие папки Git с помощью API Azure Databricks Repos.
Совместная работа с помощью папок Git
Вы можете легко сотрудничать с другими пользователями с помощью папок Git, извлечения обновлений и отправки изменений непосредственно из пользовательского интерфейса Azure Databricks. Например, используйте функцию или ветвь разработки для агрегирования изменений, внесенных в несколько ветвей.
В следующем потоке описывается совместная работа с помощью ветви функций:
- Скопируйте существующий репозиторий Git в рабочую область Databricks.
- Используйте пользовательский интерфейс папок Git для создания ветви компонентов из основной ветви. Для выполнения работы можно создать и использовать несколько ветвей функций.
- Внесите изменения в записные книжки Azure Databricks и другие файлы в репозитории.
- Зафиксируйте и отправьте изменения в удаленный репозиторий Git.
- Участники теперь могут клонировать репозиторий Git в собственную папку пользователя.
- Работая с новой ветвью, коллега вносит изменения в блокноты и другие файлы в репозитории Git.
- Участник фиксирует и отправляет изменения в удаленный репозиторий Git.
- Когда вы или другие участники готовы объединить код, создайте PR на веб-сайте поставщика Git. Просмотрите ваш код вместе с вашей командой, прежде чем объединить изменения в ветку развертывания.
Замечание
Databricks рекомендует каждому из разработчиков работать в своей собственной ветке. Дополнительные сведения об устранении конфликтов слияния см. в статье Разрешение конфликтов слияния.
Выберите подход CI/CD
Databricks рекомендует использовать пакеты ресурсов Databricks для упаковки и развертывания рабочих процессов CI/CD. Если вы предпочитаете развертывать только управляемый источником код в рабочей области, можно настроить рабочую папку Git. Для более полного обзора CI/CD с Azure Databricks см. в статье CI/CD в Azure Databricks.
Подсказка
Определите такие ресурсы, как задания и конвейеры в исходных файлах с помощью пакетов, а затем создайте, разверните и управляйте пакетами в папках рабочей области Git. См. Совместная работа над пакетами в рабочей области.
Рабочая папка Git
Рабочие папки Git служат другой цели, чем папки Git уровня пользователя, расположенные в папке /Workspace/Users/пользователя. Пользовательские папки Git выполняют роль локальных рабочих копий, где пользователи разрабатывают и отправляют изменения в коде. В отличие от этого, рабочие папки Git создаются администраторами Databricks за пределами пользовательских папок и содержат рабочие ветви развертывания. Папки Git для производства содержат исходный код для автоматизированных рабочих процессов и должны обновляться только программно, когда pull-запросы (PR) объединяются в ветви развертывания. Для рабочих папок Git ограничьте доступ пользователей к только выполнению и разрешайте изменять только администраторам и служебным субъектам Azure Databricks.
Чтобы создать рабочую папку Git, выполните приведенные действия.
Выберите репозиторий Git и ветвь для развертывания.
Получите учетную запись службы и настройте учетные данные Git, чтобы эта учетная запись могла получить доступ к этому репозиторию Git.
Создайте папку Git для Azure Databricks в репозитории Git и разместите её в подпапке
Workspace, предназначенной для проекта, команды и стадии разработки.Выберите общий доступ после выбора папки или общего доступа (разрешения), щелкнув правой кнопкой мыши папку в дереве рабочей области . Настройте папку Git со следующими разрешениями:
- Настройка может выполняться для всех пользователей проекта
- Установите флажок 'Может выполняться' для всех учетных записей субъекта-службы Azure Databricks, которые будут запускать автоматизацию для неё.
- Если это подходит для проекта, задайте для всех пользователей рабочей области возможность просмотра , чтобы поощрять обнаружение и общий доступ.
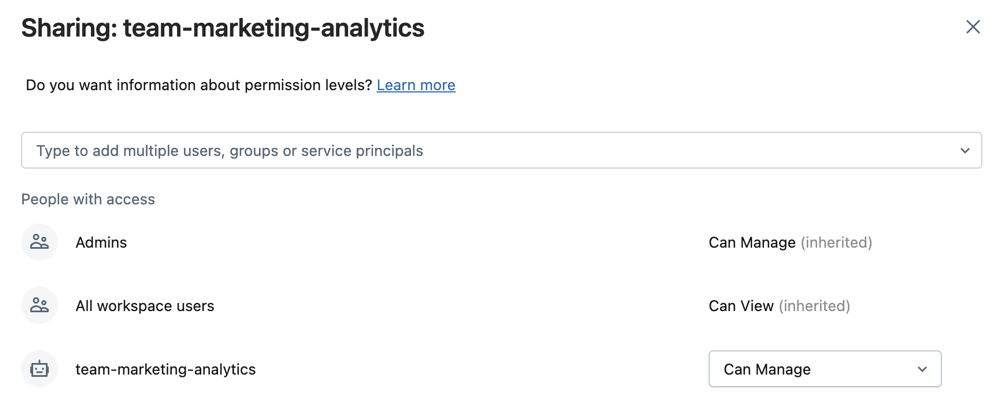
Нажмите кнопку "Добавить".
Настройте автоматические обновления папок Databricks Git. Вы можете использовать автоматизацию для синхронизации рабочей папки Git с удаленной ветвью, выполнив одно из следующих действий.
- Используйте внешние инструменты CI/CD, такие как GitHub Actions, чтобы извлечь последние коммиты в папку Git продакшна, когда pull request сливается в ветвь развертывания. Пример действий Github см. в разделе "Запуск рабочего процесса CI/CD", который обновляет папку Git для рабочей среды.
- Если вы не можете получить доступ к внешним средствам CI/CD, создайте запланированное задание для обновления папки Git в рабочей области с помощью удаленной ветви. Запланируйте выполнение простого блокнота с приведенным ниже кодом, чтобы он выполнялся периодически.
from databricks.sdk import WorkspaceClient w = WorkspaceClient() w.repos.update(w.workspace.get_status(path=”<git-folder-workspace-full-path>”).object_id, branch=”<branch-name>”)
Дополнительные сведения об автоматизации с помощью API Azure Databricks Repos см. в документации по REST API Databricks для Repos.