Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
На этой странице представлен обзор средств и подходов к экспорту данных и конфигурации из рабочей области Azure Databricks. Ресурсы рабочей области можно экспортировать для требований соответствия требованиям, переносимости данных, резервного копирования или миграции рабочей области.
Обзор
Рабочие области Azure Databricks содержат различные ресурсы, включая конфигурацию рабочей области, управляемые таблицы, объекты ИИ и машинное обучение, а также данные, хранящиеся в облачном хранилище. При экспорте данных рабочей области можно использовать сочетание встроенных средств и API для систематического извлечения этих ресурсов.
Ниже перечислены распространенные причины экспорта данных рабочей области:
- Требования к соответствию требованиям: выполнение обязательств по переносимости данных в соответствии с такими правилами, как GDPR и CCPA.
- Резервное копирование и аварийное восстановление. Создание копий критически важных ресурсов рабочей области для обеспечения непрерывности бизнес-процессов.
- Миграция рабочей области: перемещение ресурсов между рабочими областями или поставщиками облачных служб.
- Аудит и архивация: сохранение исторических записей конфигурации и данных рабочей области.
Планирование экспорта
Прежде чем приступить к экспорту данных рабочей области, создайте инвентаризацию ресурсов, которые необходимо экспортировать и понять зависимости между ними.
Общие сведения о ресурсах рабочей области
Рабочая область Azure Databricks содержит несколько категорий ресурсов, которые можно экспортировать:
- Конфигурация рабочей области: записные книжки, папки, репозитории, секреты, пользователи, группы, списки управления доступом (ACL), конфигурации кластера и определения заданий.
- Ресурсы данных: управляемые таблицы, базы данных, файлы файловой системы Databricks и данные, хранящиеся в облачном хранилище.
- Вычислительные ресурсы: конфигурации кластера, политики и определения пула экземпляров.
- Ресурсы искусственного интеллекта и машинного обучения: эксперименты MLflow, запуски, модели, таблицы Хранилища компонентов, индексы векторного поиска и модели каталога Unity.
- Объекты каталога Unity: конфигурация хранилища метаданных, каталоги, схемы, таблицы, тома и разрешения.
Определите область экспорта
Создайте контрольный список ресурсов для экспорта на основе ваших требований. Обдумайте следующие вопросы:
- Нужно ли экспортировать все ресурсы или только определенные категории?
- Существуют ли требования к соответствию или безопасности, которые определяют, какие ресурсы необходимо экспортировать?
- Необходимо ли сохранять связи между ресурсами (например, задания, ссылающиеся на записные книжки)?
- Необходимо ли повторно создать конфигурацию рабочей области в другой среде?
Планирование области экспорта помогает выбрать правильные инструменты и избежать отсутствия критически важных зависимостей.
Экспорт конфигурации рабочей области
Экспортер Terraform является основным инструментом для экспорта конфигурации рабочей области. Он создает файлы конфигурации Terraform, представляющие ресурсы рабочей области в виде кода.
Использование экспортера Terraform
Экспортер Terraform встроен в поставщик Terraform Azure Databricks и создает файлы конфигурации Terraform для ресурсов рабочей области, включая записные книжки, задания, кластеры, пользователей, группы, секреты и списки управления доступом. Экспортер должен выполняться отдельно для каждой рабочей области. См. сведения о поставщике Databricks Terraform.
Необходимые условия:
- Terraform установлен на вашем компьютере
- Настроена проверка подлинности в Azure Databricks
- Права администратора в рабочей области, которую вы хотите экспортировать
Экспорт ресурсов рабочей области:
Просмотрите видео-пример использования, чтобы получить пошаговый обзор экспортера.
Скачайте и установите поставщика Terraform с помощью средства экспорта:
wget -q -O terraform-provider-databricks.zip $(curl -s https://api.github.com/repos/databricks/terraform-provider-databricks/releases/latest|grep browser_download_url|grep linux_amd64|sed -e 's|.*: "\([^"]*\)".*$|\1|') unzip -d terraform-provider-databricks terraform-provider-databricks.zipНастройте переменные среды проверки подлинности для рабочей области:
export DATABRICKS_HOST=https://your-workspace-url export DATABRICKS_TOKEN=your-tokenЗапустите экспортера, чтобы создать файлы конфигурации Terraform:
terraform-provider-databricks exporter \ -directory ./exported-workspace \ -listing notebooks,jobs,clusters,users,groups,secretsРаспространенные варианты экспорта:
-
-listing: укажите типы ресурсов для экспорта (разделенные запятыми) -
-services: альтернатива перечислению для фильтрации ресурсов -
-directory: выходной каталог для созданных.tfфайлов -
-incremental: запуск добавочного режима для поэтапной миграции
-
Просмотрите созданные
.tfфайлы в выходном каталоге. Экспортер создает один файл для каждого типа ресурса.
Замечание
Экспортер Terraform фокусируется на конфигурации рабочей области и метаданных. Он не экспортирует фактические данные, хранящиеся в таблицах или файловой системе Databricks. Необходимо экспортировать данные отдельно с помощью подходов, описанных в следующих разделах.
Экспорт определенных типов активов
Для активов, не охваченных экспортером Terraform, используйте следующие подходы:
- Записные книжки: скачивание записных книжек по отдельности из пользовательского интерфейса рабочей области или использование API рабочей области для программного экспорта записных книжек. См. раздел "Управление объектами рабочей области".
- Секреты: секреты нельзя экспортировать напрямую по соображениям безопасности. Необходимо вручную восстановить секреты в целевой среде. Задокументируйте названия секретов и области их действия для справки.
- Объекты MLflow: используйте инструмент mlflow-export-import для экспорта экспериментов, запусков и моделей. См. раздел "Ресурсы машинного обучения " ниже.
Экспорт данных
Данные клиентов обычно находятся в хранилище облачных учетных записей, а не в Azure Databricks. Вам не нужно экспортировать данные, которые уже есть в облачном хранилище. Однако необходимо экспортировать данные, хранящиеся в управляемых Azure Databricks расположениях.
Экспорт управляемых таблиц
Хотя управляемые таблицы живут в облачном хранилище, они хранятся в иерархии на основе UUID, которая может быть трудно проанализировать. Вы можете использовать DEEP CLONE команду для перезаписи управляемых таблиц в качестве внешних таблиц в указанном расположении, что упрощает работу с ними.
Примеры DEEP CLONE команд:
CREATE TABLE delta.`abfss://container@storage.dfs.core.windows.net/path/to/storage/`
DEEP CLONE my_catalog.my_schema.my_table
Полный скрипт для клонирования всех таблиц в списке каталогов см. в примере скрипта ниже.
Экспорт хранилища Databricks по умолчанию
Для бессерверных рабочих областей Azure Databricks предлагает хранилище по умолчанию, которое является полностью управляемым решением для хранения данных в учетной записи Azure Databricks. Данные в хранилище по умолчанию должны экспортироваться в контейнеры хранилища, принадлежащие клиенту, до удаления рабочей области или вывода из эксплуатации. Дополнительные сведения о бессерверных рабочих областях см. в статье "Создание бессерверной рабочей области".
Для таблиц в хранилище по умолчанию используйте DEEP CLONE для записи данных в контейнер хранилища, принадлежащий клиенту. Для томов и произвольных файлов следуйте тем же шаблонам, которые описаны в разделе корневого экспорта DBFS ниже.
Экспорт корневой папки файловой системы Databricks
Корневая папка файловой системы Databricks — это устаревшее расположение хранилища в учетной записи хранилища вашей рабочей области, которое может содержать принадлежащие клиенту ресурсы, загруженные пользователем данные, скрипты инициализации, библиотеки и таблицы. Хотя корневой каталог файловой системы Databricks является устаревшим шаблоном хранения, устаревшие рабочие области по-прежнему могут хранить данные в этом расположении, которое необходимо экспортировать. Дополнительные сведения об архитектуре хранилища рабочей области см. в разделе "Хранилище рабочей области".
Экспорт корневого каталога файловой системы Databricks:
Так как корневые бакеты в Azure являются частными, вы не можете использовать Azure-родные инструменты, такие как azcopy, для перемещения данных между учетными записями хранения. Вместо этого используйте dbutils fs cp и delta DEEP CLONE в Azure Databricks. Это может занять много времени, в зависимости от объема данных.
# Copy DBFS files to a local path
dbutils.fs.cp("dbfs:/path/to/remote/folder", "/path/to/local/folder", recurse=True)
Для таблиц в корневом хранилище файловой системы Databricks используйте DEEP CLONE:
CREATE TABLE delta.`abfss://container@storage.dfs.core.windows.net/path/to/external/storage/`
DEEP CLONE delta.`dbfs:/path/to/dbfs/location`
Это важно
Экспорт больших объемов данных из облачного хранилища может нести значительные затраты на передачу данных и хранение. Ознакомьтесь с ценами поставщика облачных служб, прежде чем инициировать крупные экспорты.
Распространенные проблемы экспорта
Секреты:
Секреты нельзя экспортировать напрямую по соображениям безопасности. При использовании экспортера Terraform с -export-secrets параметром экспортер создает переменную vars.tf с тем же именем, что и секрет. Необходимо вручную обновить этот файл с фактическими значениями секретов или запустить экспортер Terraform с параметром -export-secrets (только для секретов, управляемых Azure Databricks).
Azure Databricks рекомендует использовать резервное хранилище секретов Azure Key Vault.
Экспорт ресурсов ИИ и машинного обучения
Для экспорта некоторых ресурсов ИИ и машинного обучения требуются различные инструменты и подходы. Модели из каталога Unity экспортируются в рамках процесса экспорта с использованием экспортёра Terraform.
Объекты MLflow
MLflow не охватывается экспортером Terraform из-за пробелов в API и трудностей с сериализацией. Для экспорта экспериментов MLflow, запусков, моделей и артефактов используйте средство mlflow-export-import . Это средство с открытым исходным кодом обеспечивает частичное покрытие задачи миграции MLflow.
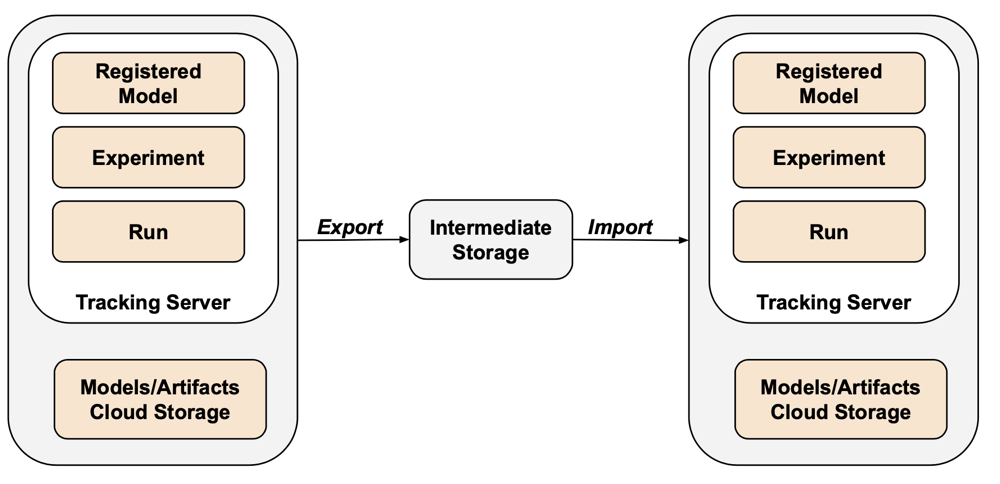
В сценариях, доступных только для экспорта, можно хранить все ресурсы MLflow в контейнере, принадлежашем клиенту, без необходимости выполнить шаг импорта. Дополнительные сведения об управлении MLflow см. в разделе "Управление жизненным циклом модели" в каталоге Unity.
Хранилище компонентов и векторный поиск
Индексы векторного поиска: индексы векторного поиска не находятся в области процедур экспорта данных ЕС. Если вы по-прежнему хотите экспортировать их, они должны быть записаны в стандартную таблицу, а затем экспортированы с помощью DEEP CLONE.
Таблицы Хранилища компонентов: Хранилище компонентов должно обрабатываться аналогично индексам векторного поиска. С помощью SQL выберите соответствующие данные и напишите их в стандартную таблицу, а затем экспортируйте с помощью DEEP CLONE.
Проверка экспортированных данных
После экспорта данных рабочей области убедитесь, что задания, пользователи, записные книжки и другие ресурсы были экспортированы правильно перед удалением старой среды. Используйте контрольный список, созданный на этапе определения объема и планирования, чтобы убедиться, что все ожидаемое для экспорта было успешно экспортировано.
Контрольный список проверки
Используйте этот контрольный список для проверки экспорта:
- Созданные файлы конфигурации: файлы конфигурации Terraform создаются для всех необходимых ресурсов в рабочем пространстве.
- Записные книжки экспортированы: все записные книжки экспортируются с их содержимым и метаданными без изменений.
- Клонированные таблицы: управляемые таблицы успешно клонируются в расположение экспорта.
- Файлы данных, скопированные: данные облачного хранилища копируются полностью без ошибок.
- Экспортированные объекты MLflow: эксперименты, запуски и модели экспортируются вместе с их артефактами.
- Разрешения, описанные в документе: списки управления доступом и разрешения записываются в конфигурации Terraform.
- Зависимости определены: связи между активами (например, задания, которые ссылаются на записные книжки) сохраняются в экспорте.
Рекомендации по последующему экспорту
Проверка и приемочное тестирование в значительной степени зависят от ваших требований и может значительно отличаться. Однако эти общие рекомендации применяются:
- Определите тестовую среду: создайте тестовую среду из заданий или записных книжек, которые проверяют правильность работы секретов, данных, соединений, разъёмов и других зависимостей в экспортируемой среде.
- Начните со среды разработки: при переходе в поэтапном режиме начните со среды разработки и переходите к рабочей среде. Это позволяет выявлять основные проблемы на раннем этапе и избегать влияния на производство.
- Используйте Git-директории: По возможности используйте директории Git, так как они хранятся во внешнем репозитории Git. Это позволяет избежать ручного экспорта и гарантирует, что код идентичен в средах.
- Задокументируйте процесс экспорта: запишите используемые средства, команды, выполненные и любые проблемы.
- Защищенные экспортированные данные: убедитесь, что экспортированные данные хранятся безопасно с соответствующими элементами управления доступом, особенно если они содержат конфиденциальные или личные данные.
- Обеспечение соответствия требованиям. Если экспорт выполняется в целях соответствия требованиям, убедитесь, что экспорт соответствует нормативным требованиям и политикам хранения.
Примеры скриптов и автоматизации
Вы можете автоматизировать экспорт рабочей области с помощью скриптов и запланированных заданий.
Скрипт экспорта для глубокого клонирования
Следующий скрипт экспортирует управляемые таблицы каталога Unity с помощью DEEP CLONE. Этот код должен выполняться в исходной рабочей области для экспорта заданного каталога в промежуточный контейнер. Обновите переменные catalogs_to_copy и dest_bucket.
import pandas as pd
# define catalogs and destination bucket
catalogs_to_copy = ["my_catalog_name"]
dest_bucket = "<cloud-storage-path>://my-intermediate-bucket"
manifest_name = "manifest"
# initialize vars
system_info = sql("SELECT * FROM system.information_schema.tables")
copied_table_names = []
copied_table_types = []
copied_table_schemas = []
copied_table_catalogs = []
copied_table_locations = []
# loop through all catalogs to copy, then copy all non-system tables
# note: this would likely be parallelized using thread pooling in prod
for catalog in catalogs_to_copy:
filtered_tables = system_info.filter((system_info.table_catalog == catalog) & (system_info.table_schema != "information_schema"))
for table in filtered_tables.collect():
schema = table['table_schema']
table_name = table['table_name']
table_type = table['table_type']
print(f"Copying table {schema}.{table_name}...")
target_location = f"{dest_bucket}/{catalog}_{schema}_{table_name}"
sqlstring = f"CREATE TABLE delta.`{target_location}` DEEP CLONE {catalog}.{schema}.{table_name}"
sql(sqlstring)
# lists used to create manifest table DF
copied_table_names.append(table_name)
copied_table_types.append(table_type)
copied_table_schemas.append(schema)
copied_table_catalogs.append(catalog)
copied_table_locations.append(target_location)
# create the manifest as a df and write to a table in dr target
# this contains catalog, schema, table and location
manifest_df = pd.DataFrame({"catalog": copied_table_catalogs,
"schema": copied_table_schemas,
"table": copied_table_names,
"location": copied_table_locations,
"type": copied_table_types})
spark.createDataFrame(manifest_df).write.mode("overwrite").format("delta").save(f"{dest_bucket}/{manifest_name}")
display(manifest_df)
Рекомендации по автоматизации
При автоматизации экспорта:
- Используйте запланированные задания: создайте задания Azure Databricks, выполняющие скрипты экспорта в обычном расписании.
- Мониторинг заданий экспорта: настройте оповещения, чтобы уведомить вас о сбое экспорта или занять больше времени, чем ожидалось.
- Управление учетными данными: безопасное хранение учетных данных облачного хранилища и маркеров API с помощью секретов Azure Databricks. Дополнительные сведения см. в разделе Управление секретами.
- Экспорт версий: используйте метки времени или номера версий в путях экспорта для поддержания исторических экспортов.
- Очистка старых экспортов: реализация политик хранения для удаления старых экспортов и управления затратами на хранение.
- Добавочный экспорт. Для больших рабочих областей рекомендуется реализовать добавочный экспорт, который экспортирует только измененные данные с момента последнего экспорта.