Примечание
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Общий регламент по защите данных (GDPR) и Закон о конфиденциальности потребителей Калифорнии (CCPA) являются правилами конфиденциальности и безопасности данных, которые требуют от компаний окончательного и полностью удаления всех личных сведений (PII), собранных о клиенте по их явному запросу. Также известное как "право быть забытым" (RTBF) или "право на удаление данных", запросы на удаление должны выполняться в течение указанного периода (например, в течение одного календарного месяца).
В этой статье описано, как реализовать RTBF для данных, хранящихся в Databricks. Пример, включенный в эту статью, моделирует наборы данных для компании электронной коммерции и показывает, как удалять данные в исходных таблицах и распространять эти изменения в подчиненные таблицы.
Схема реализации "права на забытое"
На следующей схеме показано, как реализовать "право быть забытым".
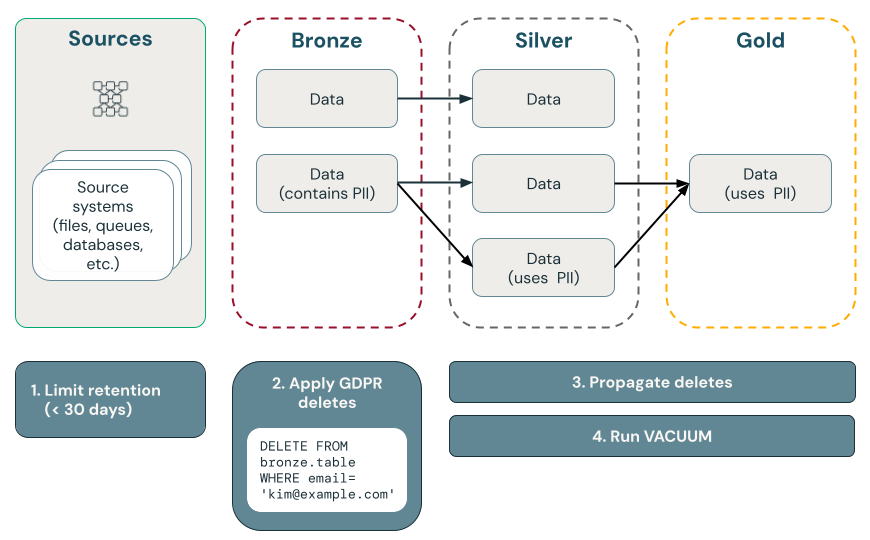
Точка удаляется с помощью Delta Lake
Delta Lake ускоряет точечное удаление в больших озерах данных с транзакциями ACID, что позволяет находить и удалять личные идентифицируемые данные (PII) по запросу в соответствии с требованиями GDPR или CCPA.
Delta Lake сохраняет историю таблиц и делает её доступной для запросов и откатов на конкретные моменты времени. Функция VACUUM удаляет файлы данных, на которые больше не ссылается таблица Delta и которые старше указанного порогового значения хранения, перманентно удаляя данные. Дополнительные сведения о значениях по умолчанию и рекомендациях см. в статье Работа с журналом таблиц Delta Lake.
Убедитесь, что данные удаляются при использовании векторов удаления
Для таблиц с включенными векторами удаления после удаления записей необходимо также запустить REORG TABLE ... APPLY (PURGE) для окончательного удаления базовых записей. Сюда входят таблицы Delta Lake, материализованные представления и потоковые таблицы. См. "Применение изменений к файлам данных Parquet".
Удаление данных в первичных источниках
GDPR и CCPA применяются ко всем данным, включая данные в источниках за пределами Delta Lake, таких как Kafka, файлы и базы данных. Помимо удаления данных в Databricks, необходимо также помнить об удалении данных в вышестоящих источниках, таких как очереди и облачное хранилище.
Полное удаление предпочтительнее, чем запутывание
Необходимо выбрать между удалением данных и их сокрытием. Скрытие можно реализовать с помощью псевдонимизации, маскирования данных и т. д. Тем не менее, самый безопасный вариант является полным стирание, так как, на практике, устранение риска повторного идентификации часто требует полного удаления данных PII.
Удаление данных в бронзовом слое, а затем распространение удалений на серебряные и золотые слои
Рекомендуем начать процесс достижения соответствия GDPR и CCPA с удаления данных в бронзовом слое путем выполнения запланированного задания, которое делает запросы к таблице управления, содержащей запросы на удаление. После удаления данных из бронзового слоя изменения можно распространить на серебряные и золотые слои.
Регулярное обслуживание таблиц для удаления данных из исторических файлов
По умолчанию Delta Lake сохраняет журнал таблиц, включая удаленные записи, в течение 30 дней и делает его доступным для перемещения по времени и откатов. Но даже если предыдущие версии данных удаляются, данные по-прежнему сохраняются в облачном хранилище. Поэтому для удаления предыдущих версий данных следует регулярно поддерживать таблицы и представления. Рекомендуемым способом является адаптивная оптимизация управляемых таблиц каталога Unity, которая интеллектуально поддерживает как потоковые таблицы, так и материализованные представления.
- Для таблиц, управляемых прогнозной оптимизацией, Декларативные конвейеры Lakeflow интеллектуально поддерживают как потоковые таблицы, так и материализованные представления на основе шаблонов использования.
- Для таблиц без включенной прогнозной оптимизации декларативные конвейеры Lakeflow автоматически выполняют задачи обслуживания в течение 24 часов после обновления потоковых таблиц и материализованных представлений.
Если вы не используете прогнозную оптимизацию или декларативные конвейеры Lakeflow, выполните VACUUM команду в таблицах Delta, чтобы окончательно удалить предыдущие версии данных. По умолчанию это приведет к сокращению возможностей перемещения по времени до 7 дней, что является настраиваемым параметром, а также удаляет исторические версии данных из облачного хранилища.
Удалите данные PII из бронзового слоя
В зависимости от дизайна вашего хранилища данных, вы можете разорвать связь между PII и другими пользовательскими данными. Например, если вы используете неестественный ключ, такой как user_id, вместо естественного ключа, например, электронной почты, вы можете удалить PII-данные, оставив на месте не-PII данные.
Остальная часть этой статьи обрабатывает RTBF путем полного удаления записей пользователей из всех бронзовых таблиц. Вы можете удалить данные, выполнив команду DELETE, как показано в следующем коде:
spark.sql("DELETE FROM bronze.users WHERE user_id = 5")
При одновременном удалении большого количества записей рекомендуется использовать команду MERGE. В приведенном ниже коде предполагается, что у вас есть таблица управления с именем gdpr_control_table, которая содержит столбец user_id. Вы вставляете запись в эту таблицу для каждого пользователя, запрашивающего "право быть забытым".
Команда MERGE указывает условие сопоставления строк. В этом примере он сопоставляет записи из target_table с записями в gdpr_control_table на основе user_id. Если есть совпадение (например, user_id как в target_table, так и в gdpr_control_table), строка в target_table удаляется. После успешного выполнения этой команды MERGE обновите таблицу управления, чтобы убедиться, что запрос обработан.
spark.sql("""
MERGE INTO target
USING (
SELECT user_id
FROM gdpr_control_table
) AS source
ON target.user_id = source.user_id
WHEN MATCHED THEN DELETE
""")
Распространяйте изменения из бронзового слоя на серебряный и золотой слои.
После удаления данных в бронзовом слое необходимо распространить изменения на таблицы в серебряных и золотых слоях.
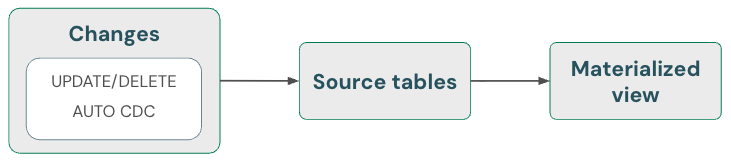
Материализованные представления: автоматическая обработка удалений
Материализованные представления автоматически обрабатывают удаления в источниках. Следовательно, вам не нужно делать ничего особенного, чтобы убедиться, что материализованное представление не содержит данные, которые были удалены из источника. Необходимо обновить материализованное представление и запустить техническое обслуживание, чтобы убедиться, что удаления полностью обработаны.
Материализованное представление всегда возвращает правильный результат, так как использует инкрементные вычисления, если это дешевле, чем полное пересчитывание, но никогда за счёт правильности. Другими словами, удаление данных из источника может привести к полной повторной компиляции материализованного представления.
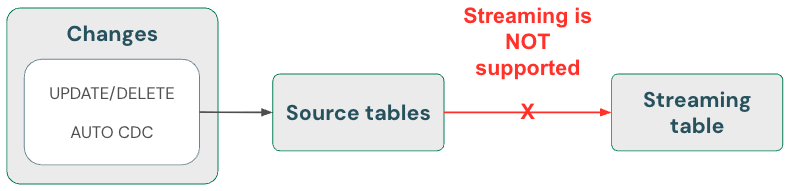
Потоковые таблицы: удаление данных и чтение источника потока с помощью skipChangeCommits
Потоковые таблицы могут обрабатывать только добавляемые данные. То есть потоковые таблицы ожидают, что в источнике потоковой передачи отображаются только новые строки данных. Любая другая операция, например обновление или удаление любой записи из исходной таблицы, используемой для потоковой передачи, не поддерживается и прерывает поток.
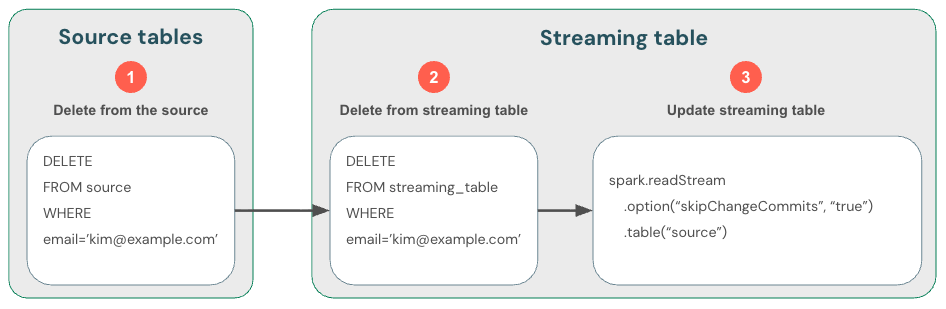
Так как потоковая передача обрабатывает только новые данные, необходимо самостоятельно обрабатывать изменения данных. Рекомендуется: (1) удалить данные в источнике потоковой передачи, (2) удалить данные из таблицы потоковой передачи, а затем (3) обновить потоковое чтение, чтобы использовать skipChangeCommits. Этот флаг сообщает Databricks, что потоковая таблица должна пропускать все, кроме вставок, например обновления или удаления.
Кроме того, можно (1) удалить данные из источника (2) из таблицы потоковой передачи, а затем (3) полностью обновить таблицу потоковой передачи. При полной перезагрузке таблицы потоковой передачи она очищает её стриминговое состояние и перерабатывает все данные заново. Любой вышестоящий источник данных, который выходит за пределы срока хранения (например, раздел Kafka, который удаляет данные через 7 дней), не будет обрабатываться повторно, что может привести к потере данных. Мы рекомендуем использовать этот параметр для потоковых таблиц только в сценарии, когда исторические данные доступны и обработка их снова не будет дорогостоящим.
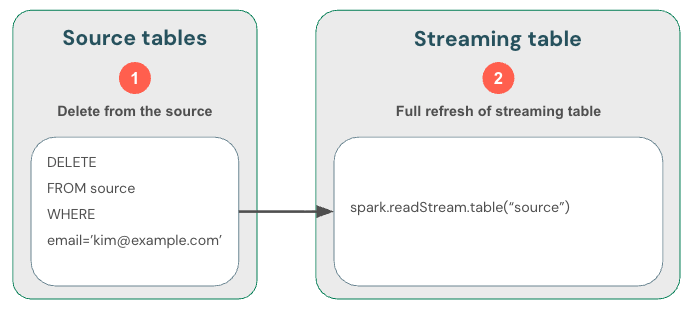
Таблицы Delta: обработка удалений с помощью readChangeFeed
Обычные таблицы Delta не содержат какой-либо специальной обработки для удалений на ранних этапах. Вместо этого необходимо написать собственный код для распространения удалений на них (например, spark.readStream.option("readChangeFeed", true).table("source_table")).
Пример: соответствие GDPR и CCPA для компании электронной коммерции
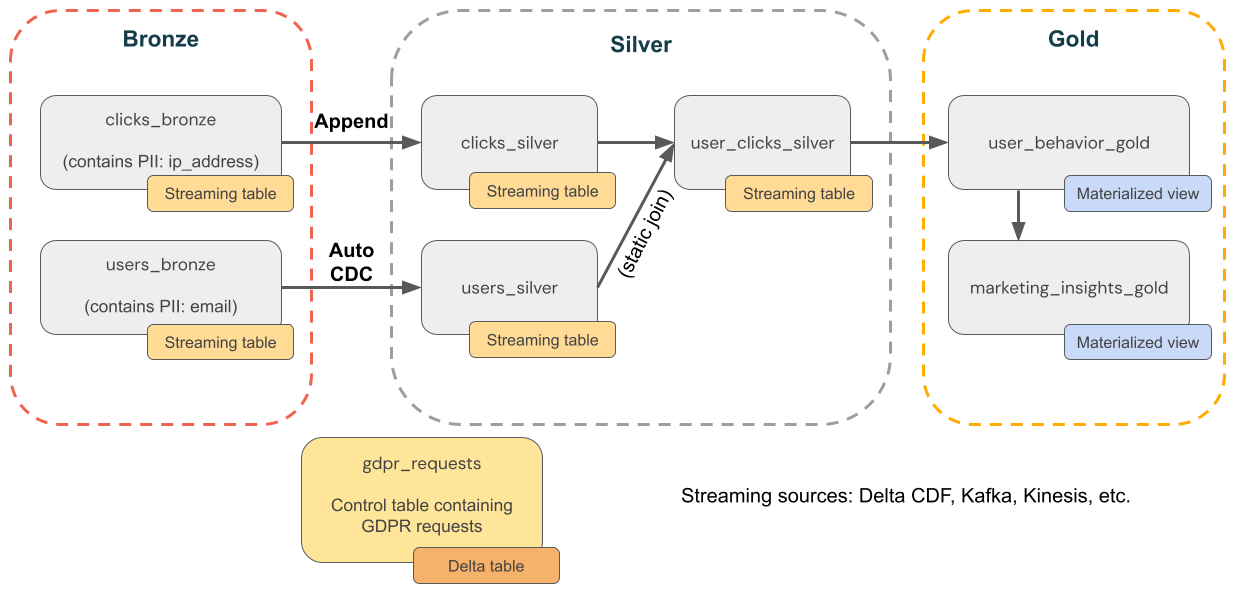
На следующей схеме показана архитектура медальона для компании электронной коммерции, в которой необходимо реализовать соответствие ТРЕБОВАНИЯМ GDPR & CCPA. Несмотря на удаление данных пользователя, может потребоваться подсчитать их действия в подчиненных агрегатах.
-
бронзовый слой
-
users— параметры пользователей. Содержит личные данные (например, адрес электронной почты). -
clickstream— события клика. Содержит личные данные (например, IP-адрес). -
gdpr_requests— контрольная таблица, содержащая идентификаторы пользователей, подлежащих "праву на забвение".
-
-
Серебряный слой
-
clicks_hourly— Всего кликов в час. Если удалить пользователя, вы по-прежнему хотите подсчитать их щелчки. -
clicks_by_user— общее количество щелчков на пользователя. При удалении пользователя вы не хотите подсчитывать их щелчки.
-
-
золотой слой
-
revenue_by_user— общий объем расходов каждого пользователя.
-
Шаг 1. Заполнение таблиц примерами данных
Следующий код создает две таблицы:
-
source_usersсодержит объемные данные о пользователях. Эта таблица содержит столбец PII с именемemail. -
source_clicksсодержит данные о событиях, связанных с действиями, производимыми пользователями. Он содержит столбец PII с именемip_address.
from pyspark.sql.types import StructType, StructField, StringType, IntegerType, MapType, DateType
catalog = "users"
schema = "name"
# Create table containing sample users
users_schema = StructType([
StructField('user_id', IntegerType(), False),
StructField('username', StringType(), True),
StructField('email', StringType(), True),
StructField('registration_date', StringType(), True),
StructField('user_preferences', MapType(StringType(), StringType()), True)
])
users_data = [
(1, 'alice', 'alice@example.com', '2021-01-01', {'theme': 'dark', 'language': 'en'}),
(2, 'bob', 'bob@example.com', '2021-02-15', {'theme': 'light', 'language': 'fr'}),
(3, 'charlie', 'charlie@example.com', '2021-03-10', {'theme': 'dark', 'language': 'es'}),
(4, 'david', 'david@example.com', '2021-04-20', {'theme': 'light', 'language': 'de'}),
(5, 'eve', 'eve@example.com', '2021-05-25', {'theme': 'dark', 'language': 'it'})
]
users_df = spark.createDataFrame(users_data, schema=users_schema)
users_df.write..mode("overwrite").saveAsTable(f"{catalog}.{schema}.source_users")
# Create table containing clickstream (i.e. user activities)
from pyspark.sql.types import TimestampType
clicks_schema = StructType([
StructField('click_id', IntegerType(), False),
StructField('user_id', IntegerType(), True),
StructField('url_clicked', StringType(), True),
StructField('click_timestamp', StringType(), True),
StructField('device_type', StringType(), True),
StructField('ip_address', StringType(), True)
])
clicks_data = [
(1001, 1, 'https://example.com/home', '2021-06-01T12:00:00', 'mobile', '192.168.1.1'),
(1002, 1, 'https://example.com/about', '2021-06-01T12:05:00', 'desktop', '192.168.1.1'),
(1003, 2, 'https://example.com/contact', '2021-06-02T14:00:00', 'tablet', '192.168.1.2'),
(1004, 3, 'https://example.com/products', '2021-06-03T16:30:00', 'mobile', '192.168.1.3'),
(1005, 4, 'https://example.com/services', '2021-06-04T10:15:00', 'desktop', '192.168.1.4'),
(1006, 5, 'https://example.com/blog', '2021-06-05T09:45:00', 'tablet', '192.168.1.5')
]
clicks_df = spark.createDataFrame(clicks_data, schema=clicks_schema)
clicks_df.write.format("delta").mode("overwrite").saveAsTable(f"{catalog}.{schema}.source_clicks")
Шаг 2. Создание конвейера, обрабатывающего данные PII
Следующий код создает бронзовые, серебряные и золотые слои архитектуры медальона, показанной выше.
import dlt
from pyspark.sql.functions import col, concat_ws, count, countDistinct, avg, when, expr
catalog = "users"
schema = "name"
# ----------------------------
# Bronze Layer - Raw Data Ingestion
# ----------------------------
@dlt.table(
name=f"{catalog}.{schema}.users_bronze",
comment='Raw users data loaded from source'
)
def users_bronze():
return (
spark.readStream.table(f"{catalog}.{schema}.source_users")
)
@dlt.table(
name=f"{catalog}.{schema}.clicks_bronze",
comment='Raw clicks data loaded from source'
)
def clicks_bronze():
return (
spark.readStream.table(f"{catalog}.{schema}.source_clicks")
)
# ----------------------------
# Silver Layer - Data Cleaning and Enrichment
# ----------------------------
@dlt.table(
name=f"{catalog}.{schema}.users_silver",
comment='Cleaned and standardized users data'
)
@dlt.expect_or_drop('valid_email', "email IS NOT NULL")
def users_silver():
return (
spark.readStream
.table(f"{catalog}.{schema}.users_bronze")
.withColumn('registration_date', col('registration_date').cast('timestamp'))
.dropDuplicates(['user_id', 'registration_date'])
.select('user_id', 'username', 'email', 'registration_date', 'user_preferences')
)
@dlt.table(
name=f"{catalog}.{schema}.clicks_silver",
comment='Cleaned and standardized clicks data'
)
@dlt.expect_or_drop('valid_click_timestamp', "click_timestamp IS NOT NULL")
def clicks_silver():
return (
spark.readStream
.table(f"{catalog}.{schema}.clicks_bronze")
.withColumn('click_timestamp', col('click_timestamp').cast('timestamp'))
.withWatermark('click_timestamp', '10 minutes')
.dropDuplicates(['click_id'])
.select('click_id', 'user_id', 'url_clicked', 'click_timestamp', 'device_type', 'ip_address')
)
@dlt.table(
name=f"{catalog}.{schema}.user_clicks_silver",
comment='Joined users and clicks data on user_id'
)
def user_clicks_silver():
# Read users_silver as a static DataFrame
users = spark.read.table(f"{catalog}.{schema}.users_silver")
# Read clicks_silver as a streaming DataFrame
clicks = spark.readStream \
.table('clicks_silver')
# Perform the join
joined_df = clicks.join(users, on='user_id', how='inner')
return joined_df
# ----------------------------
# Gold Layer - Aggregated and Business-Level Data
# ----------------------------
@dlt.table(
name=f"{catalog}.{schema}.user_behavior_gold",
comment='Aggregated user behavior metrics'
)
def user_behavior_gold():
df = spark.read.table(f"{catalog}.{schema}.user_clicks_silver")
return (
df.groupBy('user_id')
.agg(
count('click_id').alias('total_clicks'),
countDistinct('url_clicked').alias('unique_urls')
)
)
@dlt.table(
name=f"{catalog}.{schema}.marketing_insights_gold",
comment='User segments for marketing insights'
)
def marketing_insights_gold():
df = spark.read.table(f"{catalog}.{schema}.user_behavior_gold")
return (
df.withColumn(
'engagement_segment',
when(col('total_clicks') >= 100, 'High Engagement')
.when((col('total_clicks') >= 50) & (col('total_clicks') < 100), 'Medium Engagement')
.otherwise('Low Engagement')
)
)
Шаг 3. Удаление данных в исходных таблицах
На этом шаге вы удаляете данные во всех таблицах, где найдена персонально идентифицируемая информация (ПИИ).
catalog = "users"
schema = "name"
def apply_gdpr_delete(user_id):
tables_with_pii = ["clicks_bronze", "users_bronze", "clicks_silver", "users_silver", "user_clicks_silver"]
for table in tables_with_pii:
print(f"Deleting user_id {user_id} from table {table}")
spark.sql(f"""
DELETE FROM {catalog}.{schema}.{table}
WHERE user_id = {user_id}
""")
Шаг 4. Добавление skipChangeCommits в определения затронутых таблиц потоковой передачи
На этом шаге необходимо сообщить Декларативным конвейерам Lakeflow пропустить строки, которые нельзя добавить. Добавьте параметр skipChangeCommits в следующие методы. Вам не нужно обновлять определения материализованных представлений, поскольку они автоматически обрабатывают обновления и удаления.
users_bronzeusers_silverclicks_bronzeclicks_silveruser_clicks_silver
В следующем коде показано, как обновить метод users_bronze:
def users_bronze():
return (
spark.readStream.option('skipChangeCommits', 'true').table(f"{catalog}.{schema}.source_users")
)
При повторном запуске конвейера он успешно обновится.