Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
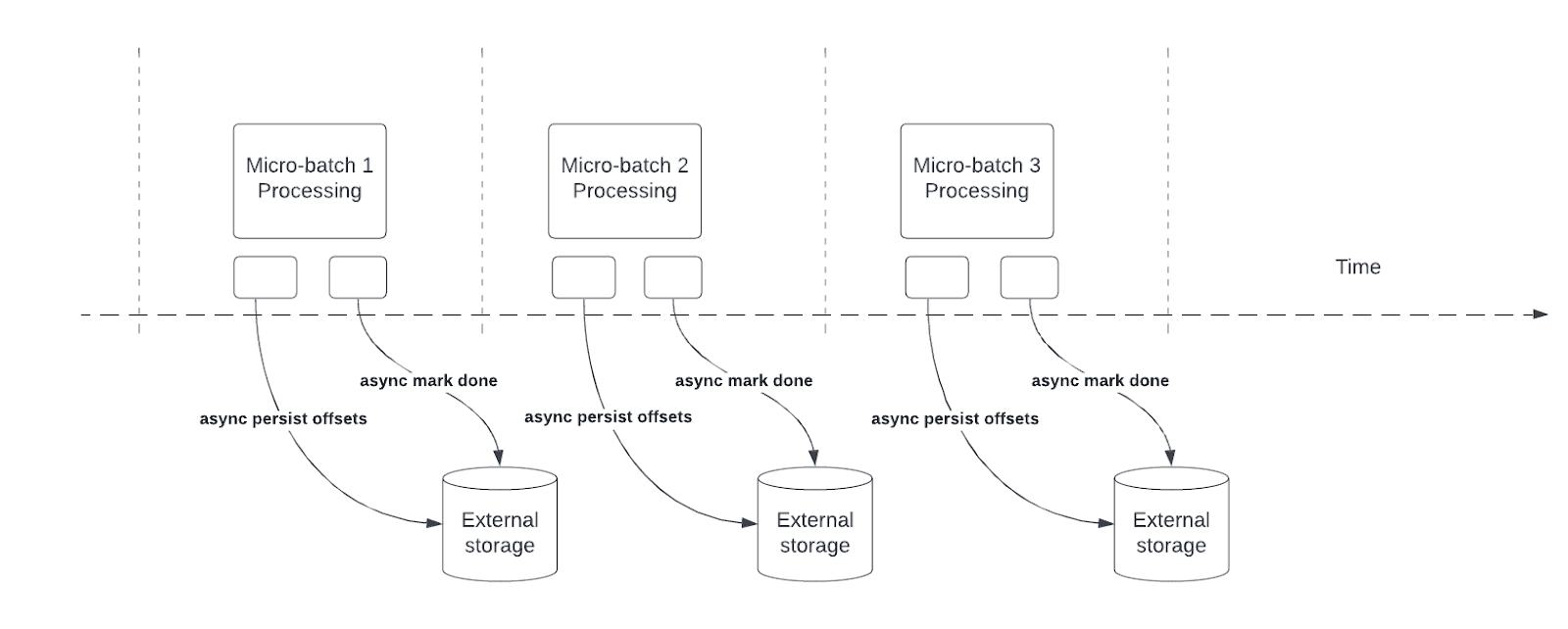
Асинхронное отслеживание хода выполнения сокращает задержку для конвейеров структурированной потоковой передачи, позволяя запросам асинхронно обновлять ход выполнения контрольной точки и обрабатывать данные в каждом микропакете.
Во время обработки запросов структурированная потоковая передача сохраняет и управляет смещениями для измерения хода выполнения запроса в offsetLogcommitLog каждом микропакете. Без асинхронного отслеживания хода выполнения операции по управлению смещениями напрямую влияют на задержку обработки, поскольку обработка данных не может продолжаться до их завершения.
Заметка
Асинхронное отслеживание хода выполнения несовместимо с триггерами Trigger.once или Trigger.availableNow. Если этот параметр включен, структурированные запросы потоковой передачи с Trigger.once или Trigger.availableNow завершаются сбоем.
Параметры конфигурации
| Выбор | По умолчанию | Описание |
|---|---|---|
asyncProgressTrackingEnabled |
false |
Следует ли включить асинхронное отслеживание хода выполнения. |
asyncProgressTrackingCheckpointIntervalMs |
1000 |
Интервал в миллисекундах между записями смещений и фиксацией завершения. |
Включение асинхронного отслеживания хода выполнения
Чтобы включить асинхронное отслеживание хода выполнения, установите значение asyncProgressTrackingEnabledtrue:
Python
stream = (spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("subscribe", "in")
.load()
)
query = (stream.writeStream
.format("kafka")
.option("topic", "out")
.option("checkpointLocation", "/tmp/checkpoint")
.option("asyncProgressTrackingEnabled", "true")
.start()
)
Scala
val stream = spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("subscribe", "in")
.load()
val query = stream.writeStream
.format("kafka")
.option("topic", "out")
.option("checkpointLocation", "/tmp/checkpoint")
.option("asyncProgressTrackingEnabled", "true")
.start()
Повышение пропускной способности за счёт частоты контрольных точек
Частота контрольных точек 1000 по умолчанию миллисекунда имеет хорошую пропускную способность для большинства запросов. Если операции управления смещением выполняются быстрее, чем их может обработать асинхронное отслеживание выполнения, формируется очередь таких операций. Чтобы предотвратить дальнейшее увеличение невыполненной работы, асинхронное отслеживание хода выполнения может блокировать или замедлять обработку данных, что потенциально приводит к снижению ожидаемых преимуществ задержки.
В этом сценарии Databricks рекомендует увеличить интервал контрольной точки:
Python
query = (stream.writeStream
.format("kafka")
.option("topic", "out")
.option("checkpointLocation", "/tmp/checkpoint")
.option("asyncProgressTrackingEnabled", "true")
.option("asyncProgressTrackingCheckpointIntervalMs", "5000")
.start()
)
Scala
val query = stream.writeStream
.format("kafka")
.option("topic", "out")
.option("checkpointLocation", "/tmp/checkpoint")
.option("asyncProgressTrackingEnabled", "true")
.option("asyncProgressTrackingCheckpointIntervalMs", "5000")
.start()
Заметка
Время восстановления сбоя увеличивается с длительностью интервала контрольной точки. В случае сбоя конвейер должен повторно обрабатывать все данные с момента предыдущей успешной контрольной точки. Прежде чем внести это изменение в рабочую среду, рассмотрите компромисс между низкой задержкой во время регулярной обработки по сравнению с временем восстановления в случае сбоя.
Отключение асинхронного отслеживания хода выполнения
Если включена асинхронное отслеживание прогресса, поток не гарантирует прогресс контрольной точки для каждого пакета. Прежде чем отключить эту функцию, необходимо зафиксировать текущий прогресс.
Чтобы отключить, выполните следующие действия.
обработка как минимум двух микропакетов с
asyncProgressTrackingEnabledустановленным наtrueиasyncProgressTrackingCheckpointIntervalMsустановленным на0Python
query = (stream.writeStream .format("kafka") .option("topic", "out") .option("checkpointLocation", "/tmp/checkpoint") .option("asyncProgressTrackingEnabled", "true") .option("asyncProgressTrackingCheckpointIntervalMs", "0") .start() )Scala
val query = stream.writeStream .format("kafka") .option("topic", "out") .option("checkpointLocation", "/tmp/checkpoint") .option("asyncProgressTrackingEnabled", "true") .option("asyncProgressTrackingCheckpointIntervalMs", "0") .start()Остановите запрос:
Python
query.stop()Scala
query.stop()Отключите асинхронное отслеживание хода выполнения и перезапустите запрос:
Python
query = (stream.writeStream .format("kafka") .option("topic", "out") .option("checkpointLocation", "/tmp/checkpoint") .option("asyncProgressTrackingEnabled", "false") .start() )Scala
val query = stream.writeStream .format("kafka") .option("topic", "out") .option("checkpointLocation", "/tmp/checkpoint") .option("asyncProgressTrackingEnabled", "false") .start()
Если отключить асинхронное отслеживание хода выполнения без выполнения описанных выше действий, может возникнуть следующая ошибка:
java.lang.IllegalStateException: batch x doesn't exist
В журналах драйверов может появиться следующая ошибка:
The offset log for batch x doesn't exist, which is required to restart the query from the latest batch x from the offset log. Please ensure there are two subsequent offset logs available for the latest batch via manually deleting the offset file(s). Please also ensure the latest batch for commit log is equal or one batch earlier than the latest batch for offset log.
Ограничения
- Для приемников Kafka асинхронное отслеживание прогресса поддерживает только статические конвейеры.
- Асинхронное отслеживание хода выполнения не гарантирует сквозную обработку с точностью до одного раза, так как диапазоны смещений для пакета могут изменяться в случае сбоя. Некоторые приемники, такие как Kafka, никогда не предоставляют точно один раз гарантии.