Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
На этой странице описывается, как использовать таблицы Delta в качестве источников и выходных точек для структурированной потоковой обработки Spark с readStream и writeStream. Delta Lake решает распространенные проблемы производительности и надежности для систем потоковой передачи и файлов. К преимуществам относятся:
- Объедините небольшие файлы, полученные с низкой задержкой, и улучшите производительность.
- Поддерживайте обработку "exactly-once" с несколькими потоками (или параллельными пакетными заданиями).
- Эффективное обнаружение новых файлов при использовании файлов в качестве источника потока.
Сведения о загрузке данных с помощью потоковых таблиц в Databricks SQL см. в статье "Использование потоковых таблиц в Databricks SQL".
Сведения о статических соединениях потока с Delta Lake см. в разделе "Поток-статические соединения".
Использование разностных таблиц в качестве приемника
Данные можно записывать в таблицу Delta с помощью структурированной потоковой передачи. Журнал транзакций Delta Lake гарантирует обработку ровно один раз, даже если одновременно выполняются другие потоки или пакетные запросы, обращающиеся к таблице.
При записи в таблицу Delta с использованием приемника Structured Streaming можно увидеть пустые коммиты epochId = -1. Это ожидается и обычно происходит:
- В первом пакете каждого запуска потокового запроса (это происходит для каждого пакета
Trigger.AvailableNow). - При изменении схемы (например, при добавлении столбца).
Эти пустые коммиты являются преднамеренными и не указывают на ошибку. Они не влияют на правильность или производительность запроса каким-либо значительным образом.
Note
Функция Delta Lake VACUUM удаляет все файлы, не управляемые Delta Lake, но пропускает все каталоги, имена которых начинаются с _. Вы можете безопасно хранить контрольные точки вместе с другими данными и метаданными для таблицы Delta, используя структуру каталогов, например <table-name>/_checkpoints.
Мониторинг невыполненной работы с помощью метрик
Используйте следующие метрики для мониторинга невыполненной работы процесса потокового запроса:
-
numBytesOutstanding: количество байтов, которые еще подлежат обработке в невыполненной работе. -
numFilesOutstanding: количество файлов, которые еще не обработаны в списке отложенных задач. -
numNewListedFiles: количество файлов Delta Lake, перечисленных для вычисления невыполненной работы для этого пакета. -
backlogEndOffset: версия таблицы Delta, используемая для вычисления невыполненной работы.
В записной книжке просмотрите эти метрики на вкладке "Необработанные данные " на панели мониторинга хода выполнения потокового запроса:
{
"sources": [
{
"description": "DeltaSource[file:/path/to/source]",
"metrics": {
"numBytesOutstanding": "3456",
"numFilesOutstanding": "8"
}
}
]
}
Режим добавления
По умолчанию потоки выполняются в режиме добавления и добавляют в таблицу только новые записи.
Используйте метод toTable, когда осуществляете потоковую передачу в таблицы.
Python
(events.writeStream
.outputMode("append")
.option("checkpointLocation", "/tmp/delta/events/_checkpoints/")
.toTable("events")
)
Scala
events.writeStream
.outputMode("append")
.option("checkpointLocation", "/tmp/delta/events/_checkpoints/")
.toTable("events")
Полный режим
Используйте структурированный стриминг в полном режиме, чтобы после каждого пакета заменять всю таблицу. Например, можно непрерывно обновлять сводную таблицу событий по клиенту:
Python
(spark.readStream
.table("events")
.groupBy("customerId")
.count()
.writeStream
.outputMode("complete")
.option("checkpointLocation", "/tmp/delta/eventsByCustomer/_checkpoints/")
.toTable("events_by_customer")
)
Scala
spark.readStream
.table("events")
.groupBy("customerId")
.count()
.writeStream
.outputMode("complete")
.option("checkpointLocation", "/tmp/delta/eventsByCustomer/_checkpoints/")
.toTable("events_by_customer")
Для приложений без строгих требований к задержке можно сэкономить вычислительные ресурсы и затраты с помощью однократных триггеров, таких как AvailableNow. Например, используйте этот триггер для обновления сводных таблиц агрегирования по заданному расписанию, обрабатывая только новые данные, поступающие с момента последнего обновления. См.: AvailableNow инкрементную пакетную обработку.
Обработка изменений в исходных таблицах Delta
Структурированная потоковая передача постепенно считывает таблицы Delta. При чтении потокового запроса из таблицы Delta новые записи обрабатываются идемпотентно, так как новые версии таблиц фиксируются в исходной таблице. Структурированная потоковая передача принимает только данные типа "добавление" и выдает исключение, если в исходной таблице Delta происходят какие-либо изменения. Например, если операция UPDATE, DELETE, MERGE INTO или OVERWRITE изменяет исходную таблицу Delta, которую читает потоковый запрос, поток завершается с ошибкой.
Существует четыре типичных подхода для обработки вышестоящих изменений в исходных разностных таблицах в зависимости от варианта использования. Справочная таблица и сведения о каждом из них приведены ниже.
| Подход | Плюсы | Минусы |
|---|---|---|
skipChangeCommits |
Легко, не требуется писать сложную логику. Полезно для обработки только добавления, где изменения в вышестоящем процессе обработаны отдельно или для временной обработки плохой записи. | Не распространяет изменения и обрабатывает только добавления. |
| Полное обновление | Также простое решение, которое не требует писать сложную логику. Полезно для небольших наборов данных с редкими вышестоящими изменениями. | Дорого для больших наборов данных. Требует повторной обработки всех подчиненных таблиц. |
| Изменение потока данных | Обработка всех типов изменений (вставка, обновление и удаление). Databricks рекомендует потоковую передачу из веб-канала CDC таблицы Delta, а не непосредственно из таблицы по возможности. | Требуется создать более сложную логику для обработки каждого типа изменений. |
| Материализованные представления | Простая альтернатива структурированной потоковой передаче с автоматическим распространением изменений. | Более высокая задержка. Доступно только в декларативных конвейерах Lakeflow Spark и Databricks SQL. |
Пропуск коммитов изменений из upstream с помощью skipChangeCommits
Установите skipChangeCommits, чтобы пропускать транзакции, которые удаляют или изменяют существующие записи, и обрабатывать только добавления. Это полезно, если изменения существующих данных не нужно распространять через поток или если вы предпочитаете отдельную логику для обработки этих изменений. Вы можете включить и отключить skipChangeCommits , если необходимо временно игнорировать однократные изменения.
Databricks рекомендует использовать skipChangeCommits для большинства рабочих нагрузок, которые не используют каналы передачи изменений данных.
Python
(spark.readStream
.option("skipChangeCommits", "true")
.table("source_table")
)
Scala
spark.readStream
.option("skipChangeCommits", "true")
.table("source_table")
Important
Если схема таблицы Delta изменится после начала потокового чтения над таблицей, запрос терпит неудачу. Для большинства изменений схемы можно перезапустить поток, чтобы устранить несоответствие схемы и продолжить обработку.
В Databricks Runtime 12.2 LTS и более ранних версиях нельзя осуществлять потоковую передачу данных из таблицы Delta с включенным сопоставлением столбцов, которая подверглась неаддитивной эволюции схемы, например, переименованию или удалению столбцов. Дополнительные сведения см. в разделе "Сопоставление столбцов и потоковая передача".
Note
В версиях Databricks Runtime 12.2 LTS и более поздних skipChangeCommits заменяет ignoreChanges. В Databricks Runtime 11.3 LTS и более низкий ignoreChanges вариант поддерживается. См. Устаревшая опция: ignoreChanges для подробностей.
Устаревшая опция: ignoreDeletes
ignoreDeletes — это устаревший параметр, который обрабатывает только транзакции, удаляющие данные в пределах границ раздела (то есть полное удаление разделов). Если вам нужно обрабатывать удаления не связанных с секциями, обновления или другие изменения, используйте skipChangeCommits вместо этого.
Python
(spark.readStream
.option("ignoreDeletes", "true")
.table("user_events")
)
Scala
spark.readStream
.option("ignoreDeletes", "true")
.table("user_events")
Устаревшая опция: ignoreChanges
ignoreChanges доступен в Databricks Runtime 11.3 LTS и ниже. В Databricks Runtime 12.2 LTS и более поздних версиях он заменяется skipChangeCommits.
При включенном ignoreChanges перезаписанные файлы данных в исходной таблице переиздаются после операций изменения данных, таких как UPDATE, MERGE INTO, DELETE (в разделах) или OVERWRITE. Неизмененные строки часто выдаются наряду с новыми строками, поэтому нижестоящие потребители должны иметь возможность обрабатывать дубликаты. Удаления не распространяются вниз.
ignoreChanges имеет больший приоритет, чем ignoreDeletes.
В отличие от этого, skipChangeCommits полностью игнорирует операции изменения файлов. Перезаписанные файлы данных в исходной таблице из-за операций изменения данных, таких как UPDATE, MERGE INTO, DELETE, и OVERWRITE, полностью игнорируются. Чтобы отразить изменения в исходных таблицах потоков, необходимо реализовать отдельную логику для распространения этих изменений.
Databricks рекомендует использовать skipChangeCommits для всех новых рабочих нагрузок. Чтобы перенести рабочую нагрузку с ignoreChanges на skipChangeCommits, выполните рефакторинг логики потоковой передачи.
Полное обновление подчиненных таблиц
Если изменения вышестоящего потока являются редкими, и данные достаточно малы для повторной обработки, можно удалить контрольную точку потоковой передачи и выходную таблицу, а затем перезапустить поток с самого начала. Это приводит к повторной обработке всех данных из исходной таблицы. Помните, что этот подход также требует повторной обработки всех подчиненных таблиц, которые зависят от выходных данных этого потока.
Этот подход лучше всего подходит для небольших наборов данных или рабочих нагрузок, в которых изменения в исходных данных происходят редко, и стоимость обновления данных допустима.
Использование канала изменений данных
Для рабочих нагрузок, обрабатывающих все типы изменений (вставки, обновления и удаления), используйте канал данных изменений Delta Lake. Поток данных об изменениях записывает изменения на уровне строк в таблицу Delta, позволяя передавать эти изменения по потоковому каналу и определять логику для обработки каждого типа изменений в последующих таблицах. Это самый надежный подход, так как код явно обрабатывает каждое событие изменения. См. использование канала данных изменений Delta Lake в Azure Databricks.
Если вы используете декларативные конвейеры Lakeflow Spark, ознакомьтесь с API AUTO CDC: упрощение отслеживания измененных данных с помощью конвейеров.
Important
В Databricks Runtime 12.2 LTS и ниже вы не можете передавать поток из канала измененных данных для таблицы Delta с включенным сопоставлением столбцов, которые прошли недитивную эволюцию схемы, например переименование или удаление столбцов. См. сопоставление столбцов и потоковую передачу.
Использование материализованных представлений
Материализованные представления автоматически обрабатывают изменения вышестоящего потока путем повторной компиляции результатов при изменении исходных данных. Если вам не нужна самая низкая возможная задержка и требуется избежать управления сложностью потоковой передачи, материализованное представление может упростить архитектуру. Материализованные представления доступны в декларативных конвейерах Lakeflow Spark и в Databricks SQL. См. материализованные представления.
Example
Например, предположим, что у вас есть таблица user_events с date, user_emailи столбцами action, секционированных по date. Вы выгружаете данные из таблицы user_events, и данные должны быть удалены из нее в соответствии с GDPR.
skipChangeCommits позволяет удалять данные в нескольких секциях (в этом примере фильтрация включена user_email). Используйте следующий синтаксис:
spark.readStream
.option("skipChangeCommits", "true")
.table("user_events")
При обновлении user_email с помощью инструкции UPDATE перезаписывается файл, содержащий соответствующий user_email. Используйте skipChangeCommits для пропуска измененных файлов данных.
Databricks рекомендует использовать skipChangeCommits вместо ignoreDeletes, если вы не уверены, что удаления всегда являются полными удалениями секций.
Использование foreachBatch для записи идемпотентных таблиц
Note
Databricks рекомендует настроить отдельные потоковые операции записи для каждого приемника, который нужно обновить, вместо использования foreachBatch. Запись в несколько приемников уменьшает foreachBatch параллелизацию и увеличивает общую задержку, так как записи в несколько таблиц сериализуются в foreachBatch.
Таблицы Delta поддерживают следующие параметры DataFrameWriter, чтобы сделать запись в несколько таблиц в foreachBatch идемпотентной.
-
txnAppId: уникальная строка, которую можно передавать при записи каждого DataFrame. Например, идентификатор StreamingQuery можно использовать какtxnAppId.txnAppIdможет быть любой созданной пользователем уникальной строкой и не должен быть связан с идентификатором потока. -
txnVersion: Монотонно возрастающее количество, действующее как версия транзакции.
Delta Lake использует txnAppId и txnVersion, чтобы определять и игнорировать повторяющиеся записи. Например, после сбоя при выполнении пакетной записи можно повторно запустить пакет с теми же txnAppId и txnVersion, чтобы правильно определить и игнорировать дубликаты. См. раздел Использование foreachBatch для записи в произвольные приемники данных.
Warning
Если удалить контрольную точку потоковой передачи и перезапустить запрос, используя новую контрольную точку, необходимо указать другой txnAppId. Новые контрольные точки начинаются с пакетного идентификатора 0. Delta Lake использует идентификатор пакета и txnAppId в качестве уникального ключа и пропускает пакеты с уже видимыми значениями.
В следующем примере кода показан этот шаблон:
Python
app_id = ... # A unique string that is used as an application ID.
def writeToDeltaLakeTableIdempotent(batch_df, batch_id):
batch_df.write.format(...).option("txnVersion", batch_id).option("txnAppId", app_id).save(...) # location 1
batch_df.write.format(...).option("txnVersion", batch_id).option("txnAppId", app_id).save(...) # location 2
streamingDF.writeStream.foreachBatch(writeToDeltaLakeTableIdempotent).start()
Scala
val appId = ... // A unique string that is used as an application ID.
streamingDF.writeStream.foreachBatch { (batchDF: DataFrame, batchId: Long) =>
batchDF.write.format(...).option("txnVersion", batchId).option("txnAppId", appId).save(...) // location 1
batchDF.write.format(...).option("txnVersion", batchId).option("txnAppId", appId).save(...) // location 2
}
Upsert из потоковых запросов с помощью foreachBatch
Вы можете использовать merge и foreachBatch, чтобы записывать сложные апсерты из потокового запроса в таблицу Delta. См. раздел Использование foreachBatch для записи в произвольные приемники данных.
Этот подход имеет множество приложений:
- Улучшите производительность записи с помощью режима вывода
update, в то время как выходной режимcompleteтребует перезаписи всей таблицы результатов для каждого микробатча. - Непрерывно применяйте поток изменений к таблице Delta, используя запрос на слияние для записи измененных данных в
foreachBatch. Ознакомьтесь с медленно изменяющимися данными (SCD) и записью измененных данных (CDC) с помощью Delta Lake. - Управление дедупликацией во время потоковой обработки. Запрос на слияние, предназначенный только для вставки, можно использовать для непрерывной записи данных в таблицу Delta в
foreachBatchс автоматической дедупликацией. См. дедупликацию данных при записи в таблицы Delta.
Note
Убедитесь, что инструкция
mergeвнутриforeachBatchидемпотентна. В противном случае перезапуск потокового запроса может применять операцию в одном пакете данных несколько раз. См. статью "ИспользованиеforeachBatchдля записи идемпотентной таблицы".При использовании
mergeвforeachBatch, метрика скорости входных данных может возвращать значение, являющееся кратным фактической скорости, с которой данные генерируются на источнике.mergeсчитывает входные данные несколько раз, что умножает метрики. Чтобы предотвратить умножение метрик, кэшируйте пакетный кадр данных доmerge, а затем распакуйте его послеmerge.Данные о скорости ввода доступны через
StreamingQueryProgressи в графике скорости потоковой передачи ноутбука. См. Мониторинг запросов структурированной потоковой передачи на Azure Databricks.
Например, можно использовать инструкции SQL в рамках MERGE в foreachBatch.
Scala
// Function to upsert microBatchOutputDF into Delta table using merge
def upsertToDelta(microBatchOutputDF: DataFrame, batchId: Long) {
// Set the dataframe to view name
microBatchOutputDF.createOrReplaceTempView("updates")
// Use the view name to apply MERGE
// NOTE: You have to use the SparkSession that has been used to define the `updates` dataframe
microBatchOutputDF.sparkSession.sql(s"""
MERGE INTO aggregates t
USING updates s
ON s.key = t.key
WHEN MATCHED THEN UPDATE SET *
WHEN NOT MATCHED THEN INSERT *
""")
}
// Write the output of a streaming aggregation query into Delta table
streamingAggregatesDF.writeStream
.foreachBatch(upsertToDelta _)
.outputMode("update")
.start()
Python
# Function to upsert microBatchOutputDF into Delta table using merge
def upsertToDelta(microBatchOutputDF, batchId):
# Set the dataframe to view name
microBatchOutputDF.createOrReplaceTempView("updates")
# Use the view name to apply MERGE
# NOTE: You have to use the SparkSession that has been used to define the `updates` dataframe
# In Databricks Runtime 10.5 and below, you must use the following:
# microBatchOutputDF._jdf.sparkSession().sql("""
microBatchOutputDF.sparkSession.sql("""
MERGE INTO aggregates t
USING updates s
ON s.key = t.key
WHEN MATCHED THEN UPDATE SET *
WHEN NOT MATCHED THEN INSERT *
""")
# Write the output of a streaming aggregation query into Delta table
(streamingAggregatesDF.writeStream
.foreachBatch(upsertToDelta)
.outputMode("update")
.start()
)
Вы также можете использовать API Delta Lake для внесения обновлений и вставок в потоковом режиме.
Scala
import io.delta.tables.*
val deltaTable = DeltaTable.forName(spark, "table_name")
// Function to upsert microBatchOutputDF into Delta table using merge
def upsertToDelta(microBatchOutputDF: DataFrame, batchId: Long) {
deltaTable.as("t")
.merge(
microBatchOutputDF.as("s"),
"s.key = t.key")
.whenMatched().updateAll()
.whenNotMatched().insertAll()
.execute()
}
// Write the output of a streaming aggregation query into Delta table
streamingAggregatesDF.writeStream
.foreachBatch(upsertToDelta _)
.outputMode("update")
.start()
Python
from delta.tables import *
deltaTable = DeltaTable.forName(spark, "table_name")
# Function to upsert microBatchOutputDF into Delta table using merge
def upsertToDelta(microBatchOutputDF, batchId):
(deltaTable.alias("t").merge(
microBatchOutputDF.alias("s"),
"s.key = t.key")
.whenMatchedUpdateAll()
.whenNotMatchedInsertAll()
.execute()
)
# Write the output of a streaming aggregation query into Delta table
(streamingAggregatesDF.writeStream
.foreachBatch(upsertToDelta)
.outputMode("update")
.start()
)
Настройка начальной версии таблицы для обработки изменений
По умолчанию потоки начинаются с последней доступной версии таблицы Delta. Это включает полный снимок таблицы в данный момент и все будущие изменения. Databricks рекомендует использовать исходную версию таблицы по умолчанию для большинства рабочих нагрузок.
При необходимости можно использовать следующие параметры, чтобы указать начальную точку источника потоковой передачи Delta Lake, не обрабатывая всю таблицу.
startingVersion: версия таблицы Delta, с которой начинается чтение. Все изменения таблицы, зафиксированные в указанной версии или после нее, считываются потоком. Если указанная версия недоступна, поток не запускается.Чтобы найти доступные версии коммитов, выполните
DESCRIBE HISTORYи проверьтеversion. Чтобы вернуть только последние изменения, укажитеlatest. Сведения о версиях таблиц Delta см. в статье "Работа с журналом таблиц".startingTimestamp: метка времени, из которой начинается чтение. Все изменения таблицы, зафиксированные в потоке или после указанной метки времени, считываются потоком. Если указанная метка времени предшествует всем коммитам таблицы, потоковое чтение начинается с самой ранней доступной метки времени. Задайте один из следующих вариантов:- Строка метки времени. Например,
"2019-01-01T00:00:00.000Z". - Строка даты. Например,
"2019-01-01".
- Строка метки времени. Например,
Нельзя задать оба startingVersion и startingTimestamp одновременно. Эти параметры применяются только к новым запросам потоковой передачи. Если запрос потоковой передачи запущен и ход выполнения записан в контрольной точке, эти параметры игнорируются.
Important
Хотя вы можете запустить источник потоковой передачи из указанной версии или метки времени, схема источника потоковой передачи всегда является последней схемой таблицы Delta. Необходимо убедиться, что после указанной версии или метки времени в таблице Delta не произошло изменения несовместимой схемы. В противном случае источник потоковой передачи может возвращать неверные результаты при чтении данных с неправильной схемой.
Example
Например, предположим, что у вас есть таблица user_events. Если вы хотите считать изменения начиная с версии 5, используйте:
spark.readStream
.option("startingVersion", "5")
.table("user_events")
Если вы хотите считать изменения начиная с 18 октября 2018 г., используйте:
spark.readStream
.option("startingTimestamp", "2018-10-18")
.table("user_events")
Обработка начального моментального снимка без удаления данных
Эта функция доступна в Databricks Runtime 11.3 LTS и выше.
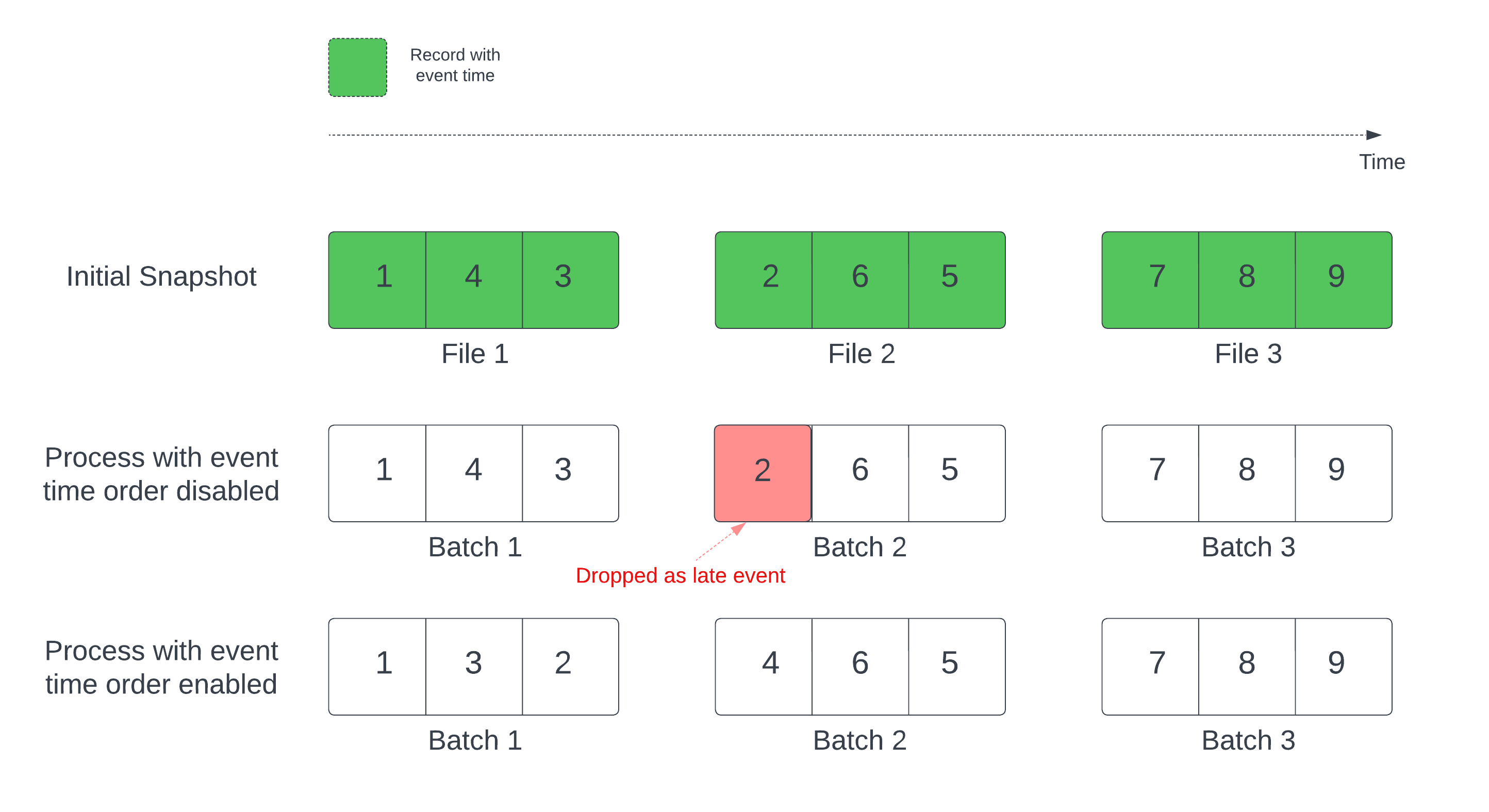
В запросе потоковой передачи с отслеживанием состояния и определённым водяным знаком обработка файлов на основе времени изменения может выполнять записи в неправильном порядке. Это может привести к неправильной пометке записей как запоздалых событий и их удалению. Это может произойти только в том случае, если начальный Delta-снимок обрабатывается по умолчанию.
Для потоков с исходной таблицей Delta запрос сначала обрабатывает все данные, присутствующие в таблице, и создает версию, называемую начальным моментальным снимком. По умолчанию файлы данных таблицы Delta обрабатываются на основе последнего изменения файла. Однако время последнего изменения необязательно соответствует временной последовательности событий.
Чтобы избежать потери данных во время начальной обработки моментальных снимков withEventTimeOrder, включите эту опцию.
withEventTimeOrder делит диапазон времени события начальных данных моментального снимка на контейнеры времени. Каждый микропакет обрабатывает контейнер путем фильтрации данных в пределах диапазона времени. Параметры maxFilesPerTrigger и maxBytesPerTrigger по-прежнему применяются для управления размером микропакета, но только приблизительно вследствие подхода обработки.
На следующей схеме показан этот процесс:
Constraints
- Невозможно изменить
withEventTimeOrder, если потоковый запрос уже запущен и начальный моментальный снимок активно обрабатывается. Чтобы перезапустить с измененнымwithEventTimeOrder, необходимо удалить контрольную точку. - Если параметр
withEventTimeOrderвключен, вы не можете перейти на версию среды выполнения Databricks, которая не поддерживает эту функцию, до завершения первоначальной обработки снимка. Чтобы понизить уровень, дождитесь завершения начального снимка состояния или удалите контрольную точку и перезапустите запрос. - Эта функция не поддерживается в следующих сценариях:
- Столбец времени события — это сгенерированный столбец, и между источником Delta и водяным знаком существуют преобразования, не связанные с проекцией.
- В запросе потока имеется подложка с несколькими источниками delta.
Производительность
Если withEventTimeOrder включена, производительность начальной обработки моментальных снимков может быть медленнее. Каждый микропакет сканирует начальный моментальный снимок, чтобы отфильтровать данные в соответствующем диапазоне времени события. Чтобы повысить производительность фильтрации, выполните приведенные действия.
- Используйте столбец Delta-источника в качестве времени события, чтобы можно было использовать пропуск данных. См. пропуск данных.
- Разделите таблицу по столбцу времени события.
Используйте Spark UI, чтобы узнать, сколько файлов Delta сканируется для определенного микропакета.
Example
Предположим, что у вас есть таблица user_events с столбцом event_time. Запрос потоковой передачи — это агрегатный запрос. Если вы хотите убедиться, что данные не будут удаляться во время обработки исходных моментальных снимков, можно использовать следующее:
spark.readStream
.option("withEventTimeOrder", "true")
.table("user_events")
.withWatermark("event_time", "10 seconds")
Вы можете задать withEventTimeOrder конфигурацию Spark в кластере, чтобы применить ее ко всем потоковым запросам: spark.databricks.delta.withEventTimeOrder.enabled true
Ограничение скорости ввода для повышения производительности обработки
По умолчанию структурированная потоковая передача обрабатывает как можно больше файлов в каждом микропакете. Чтобы ограничить объем данных, обработанных на пакет и управлять использованием памяти, стабилизацией задержки или сокращением затрат на облачное хранилище, используйте следующие параметры:
-
maxFilesPerTrigger: количество новых файлов, которые следует учитывать в каждом микропакете. Значение по умолчанию — 1000. -
maxBytesPerTrigger: объем данных, обрабатываемых в каждом микропакете. Этот параметр задает "мягкое максимальное значение", то есть пакетная обработка приблизительно этого объема данных может обрабатывать больше, чем лимит, чтобы потоковый запрос продвигался вперед в случаях, когда наименьший входной блок превышает этот лимит. Это значение не задано по умолчанию.
Если вы используете как maxBytesPerTrigger, так и maxFilesPerTrigger, микропакетный процесс обрабатывает данные до достижения лимита maxFilesPerTrigger или maxBytesPerTrigger.
Note
По умолчанию, если logRetentionDuration очищает транзакции в исходной таблице и потоковый запрос пытается обработать эти версии, запрос завершится неудачей для предотвращения потери данных. Параметр failOnDataLoss можно установить в false так, чтобы игнорировать потерянные данные и продолжать обработку. См. Настройка сохранения данных для запросов по временному перемещению.
Управление затратами на облачное хранилище
Потоковые запросы имеют несколько режимов триггеров, которые позволяют сбалансировать затраты и задержки, включая processingTime, availableNow и realTime. См. раздел "Управление затратами на облачное хранилище".