Получение рекомендаций Azure для миграции базы данных SQL Server
Расширение миграции SQL Azure для Azure Data Studio помогает оценить требования к базе данных, получить рекомендации по SKU правильного размера для ресурсов Azure и перенести базу данных SQL Server в Azure.
Узнайте, как использовать этот унифицированный интерфейс, собирая данные о производительности из исходного экземпляра SQL Server, чтобы получить правильные рекомендации Azure для целевых объектов SQL Azure.
Обзор
Перед миграцией в Azure SQL можно использовать расширение миграции SQL в Azure Data Studio, чтобы создать рекомендации по правильному размеру для База данных SQL Azure, Управляемый экземпляр SQL Azure и SQL Server в целевых объектах Azure Виртуальные машины. Это средство помогает собирать данные о производительности из исходного экземпляра SQL (на локальном или другом облаке), а также рекомендовать конфигурацию вычислений и хранилища для удовлетворения потребностей рабочей нагрузки.
На схеме представлен рабочий процесс рекомендаций Azure в расширении миграции SQL Azure для Azure Data Studio:

Примечание.
Оценка и функция рекомендаций Azure в расширении миграции SQL Azure для Azure Data Studio поддерживает исходные экземпляры SQL Server, работающие в Windows или Linux.
Необходимые компоненты
Чтобы приступить к работе с рекомендациями Azure для миграции базы данных SQL Server, необходимо выполнить следующие предварительные требования:
Установите расширение миграции SQL Azure из Azure Data Studio Marketplace.
Убедитесь, что имя входа, используемое для подключения исходного экземпляра SQL Server, имеет минимальные разрешения.
Поддерживаемые источники и целевые объекты
Рекомендации Azure можно создать для следующих версий SQL Server:
- Поддерживаются SQL Server 2008 и более поздних версий в Windows или Linux.
- SQL Server, работающий в других облаках, может поддерживаться, но точность результатов может отличаться.
Рекомендации Azure можно создать для следующих целевых объектов SQL Azure:
- База данных SQL Azure
- Семейства оборудования: серия "Стандартный" (5-го поколения)
- Уровни служб: общего назначения, критически важный для бизнеса, гипермасштабирование
- Управляемый экземпляр SQL Azure
- Семейства оборудования: серия "Стандартный" (5-го поколения), серия "Премиум", оптимизированная для памяти серии "Премиум"
- Уровни служб: общего назначения, критически важный для бизнеса
- SQL Server на виртуальной машине Azure
- Семейства виртуальных машин: общее назначение, оптимизированное для памяти
- Семейства хранилищ: SSD уровня "Премиум"
Сбор данных производительности
Прежде чем создавать рекомендации, необходимо собрать данные о производительности из исходного экземпляра SQL Server. На этом этапе сбора данных запрашиваются несколько динамических системных представлений из экземпляра SQL Server, чтобы получить характеристики производительности рабочей нагрузки. Средство записывает метрики, включая ЦП, память, хранилище и использование операций ввода-вывода каждые 30 секунд и сохраняет счетчики производительности локально на компьютере в виде набора CSV-файлов.
Уровень экземпляра
Эти данные о производительности собираются один раз на экземпляр SQL Server:
| Измерение производительности | Description | Динамическое управление (DMV) |
|---|---|---|
SqlInstanceCpuPercent |
Объем ЦП, используемого процессом SQL Server, в процентах | sys.dm_os_ring_buffers |
PhysicalMemoryInUse |
Общий объем памяти процесса SQL Server | sys.dm_os_process_memory |
MemoryUtilizationPercentage |
Использование памяти SQL Server | sys.dm_os_process_memory |
На уровне базы данных
| Измерение производительности | Description | Динамическое управление (DMV) |
|---|---|---|
DatabaseCpuPercent |
Общий процент ЦП, используемый базой данных | sys.dm_exec_query_stats |
CachedSizeInMb |
Общий размер в мегабайтах кэша, используемого базой данных | sys.dm_os_buffer_descriptors |
Уровень файла
| Измерение производительности | Description | Динамическое управление (DMV) |
|---|---|---|
ReadIOInMb |
Общее количество мегабайт, считываемых из этого файла | sys.dm_io_virtual_file_stats |
WriteIOInMb |
Общее количество мегабайт, записанных в этот файл | sys.dm_io_virtual_file_stats |
NumOfReads |
Общее количество операций чтения, выданных в этом файле | sys.dm_io_virtual_file_stats |
NumOfWrites |
Общее количество записей, выданных в этом файле | sys.dm_io_virtual_file_stats |
ReadLatency |
Задержка чтения операций ввода-вывода в этом файле | sys.dm_io_virtual_file_stats |
WriteLatency |
Задержка записи ввода-вывода в этом файле | sys.dm_io_virtual_file_stats |
Перед созданием рекомендации требуется не менее 10 минут сбора данных, но для точной оценки рабочей нагрузки рекомендуется выполнить сбор данных в течение достаточно длительного времени, чтобы записать как пиковое, так и вне пиковое использование.
Чтобы инициировать процесс сбора данных, начните с подключения к исходному экземпляру SQL в Azure Data Studio, а затем запустите мастер миграции SQL. На шаге 2 выберите "Получить рекомендацию Azure". Выберите "Собрать данные о производительности сейчас" и выберите папку на компьютере, где будут сохранены собранные данные.
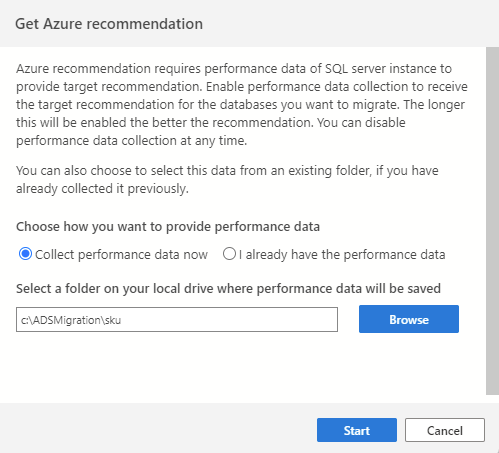
Процесс сбора данных выполняется в течение 10 минут, чтобы создать первую рекомендацию. Важно начать процесс сбора данных, когда активная рабочая нагрузка базы данных отражает использование, аналогичное рабочим сценариям рабочей среды.
После создания первой рекомендации можно продолжить выполнение процесса сбора данных для уточнения рекомендаций. Этот параметр особенно полезен, если шаблоны использования зависят от времени.
Процесс сбора данных начинается после нажатия кнопки "Пуск". Каждые 10 минут собранные точки данных агрегируются, а максимальное значение и дисперсию каждого счетчика записываются на диск в набор из трех CSV-файлов.
Обычно в выбранной папке отображается набор CSV-файлов со следующими суффиксами:
SQLServerInstance_CommonDbLevel_Counters.csv. Содержит статические данные конфигурации о макете файла базы данных и метаданных.SQLServerInstance_CommonInstanceLevel_Counters.csv. Содержит статические данные о конфигурации оборудования экземпляра сервера.SQLServerInstance_PerformanceAggregated_Counters.csv. Содержит агрегированные данные о производительности, которые часто обновляются.
В это время оставьте Azure Data Studio открытым, хотя вы можете продолжить другие операции. В любое время можно остановить процесс сбора данных, вернувшись на эту страницу и выбрав "Остановить сбор данных".
Создание рекомендаций по правильному размеру
Если вы уже собрали данные о производительности из предыдущего сеанса или с помощью другого средства (например, базы данных Помощник по миграции), вы можете импортировать все существующие данные о производительности, выбрав параметр, который у меня уже есть данные о производительности. Перейдите к папке, в которой сохраняются данные о производительности (три .csv файлы) и нажмите кнопку "Пуск ", чтобы инициировать процесс рекомендаций.
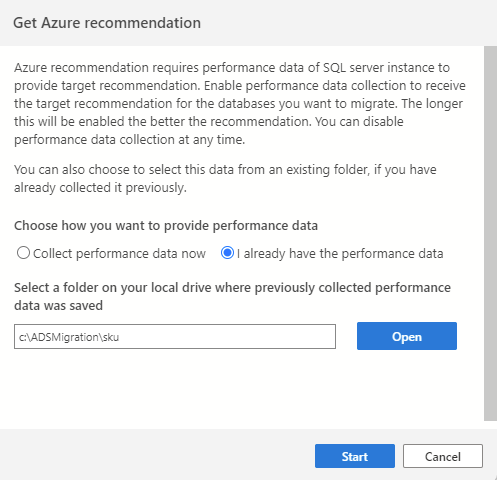
Шаг одного из мастера миграции SQL запрашивает выбор набора баз данных для оценки, и это единственные базы данных, которые будут учитываться во время процесса рекомендаций.
Однако процесс сбора данных о производительности собирает счетчики производительности для всех баз данных из исходного экземпляра SQL Server, а не только тех, которые были выбраны.
Это означает, что ранее собранные данные о производительности можно использовать для повторного создания рекомендаций для другого подмножества баз данных, указав другой список на шаге один.
Параметры рекомендаций
Существует несколько настраиваемых параметров, которые могут повлиять на рекомендации.

Выберите параметр "Изменить параметры", чтобы настроить эти параметры в соответствии с вашими потребностями.
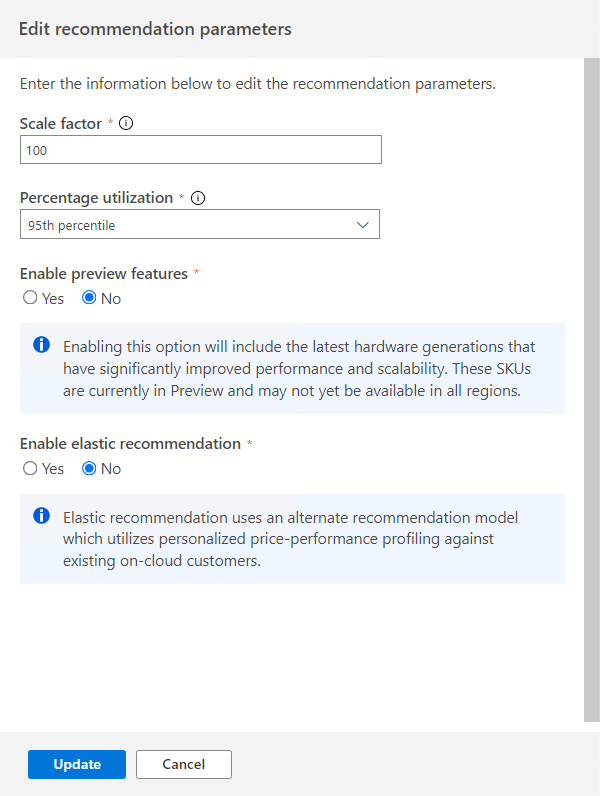
Коэффициент масштабирования:
Этот параметр позволяет предоставить буфер для применения к каждому измерению производительности. Этот параметр учитывает такие проблемы, как сезонное использование, короткий журнал производительности и, скорее всего, увеличивается в будущем. Например, если определить, что требование К ЦП с четырьмя виртуальными ядрами имеет коэффициент масштабирования 150%, истинное требование ЦП составляет шесть виртуальных ядер.
Коэффициент масштабирования по умолчанию — 100 %.
Процент использования:
Процентиль точек данных, используемых в качестве данных производительности, агрегируется.
Значение по умолчанию — 95-й процентиль.
Включение предварительных версий функций:
Этот параметр позволяет использовать конфигурации, которые могут быть недоступны для всех пользователей во всех регионах.
По умолчанию этот параметр выключен.
Включите эластичную рекомендацию:
Этот параметр использует альтернативную модель рекомендаций, которая использует персонализированную профилирование ценовых производительности для существующих клиентов в облаке.
По умолчанию этот параметр выключен.
Процесс сбора данных завершается при закрытии Azure Data Studio. Данные, собранные до этой точки, сохраняются в папке.
При закрытии Azure Data Studio во время сбора данных используйте один из следующих вариантов для перезапуска сбора данных:
Откройте Azure Data Studio и импортируйте файлы данных, сохраненные в локальной папке. Затем создайте рекомендацию из собранных данных.
Откройте Azure Data Studio и снова запустите сбор данных с помощью мастера миграции.
Минимальные разрешения
Чтобы запросить необходимые системные представления для сбора данных о производительности, для входа SQL Server, используемого для этой задачи, требуются определенные разрешения. Вы можете создать минимально привилегированного пользователя для сбора данных оценки и производительности с помощью следующего сценария:
-- Create a login to run the assessment
USE master;
GO
CREATE LOGIN [assessment]
WITH PASSWORD = '<STRONG PASSWORD>';
-- Create user in every database other than TempDB and model and provide minimal read-only permissions
EXECUTE sp_MSforeachdb '
USE [?];
IF (''?'' NOT IN (''TempDB'',''model''))
BEGIN TRY
CREATE USER [assessment] FOR LOGIN [assessment]
END TRY
BEGIN CATCH
PRINT ERROR_MESSAGE()
END CATCH';
EXECUTE sp_MSforeachdb '
USE [?];
IF (''?'' NOT IN (''tempdb'',''model''))
BEGIN TRY
GRANT SELECT ON sys.sql_expression_dependencies TO [assessment]
END TRY
BEGIN CATCH
PRINT ERROR_MESSAGE()
END CATCH';
EXECUTE sp_MSforeachdb '
USE [?];
IF (''?'' NOT IN (''tempdb'',''model''))
BEGIN TRY
GRANT VIEW DATABASE STATE TO [assessment]
END TRY
BEGIN CATCH
PRINT ERROR_MESSAGE()
END CATCH';
-- Provide server level read-only permissions
GRANT SELECT ON sys.sql_expression_dependencies TO [assessment];
GRANT SELECT ON sys.sql_expression_dependencies TO [assessment];
GRANT EXECUTE ON OBJECT::sys.xp_regenumkeys TO [assessment];
GRANT VIEW DATABASE STATE TO assessment;
GRANT VIEW SERVER STATE TO assessment;
GRANT VIEW ANY DEFINITION TO assessment;
-- Provide msdb specific permissions
USE msdb;
GO
GRANT EXECUTE ON [msdb].[dbo].[agent_datetime] TO [assessment];
GRANT SELECT ON [msdb].[dbo].[sysjobsteps] TO [assessment];
GRANT SELECT ON [msdb].[dbo].[syssubsystems] TO [assessment];
GRANT SELECT ON [msdb].[dbo].[sysjobhistory] TO [assessment];
GRANT SELECT ON [msdb].[dbo].[syscategories] TO [assessment];
GRANT SELECT ON [msdb].[dbo].[sysjobs] TO [assessment];
GRANT SELECT ON [msdb].[dbo].[sysmaintplan_plans] TO [assessment];
GRANT SELECT ON [msdb].[dbo].[syscollector_collection_sets] TO [assessment];
GRANT SELECT ON [msdb].[dbo].[sysmail_profile] TO [assessment];
GRANT SELECT ON [msdb].[dbo].[sysmail_profileaccount] TO [assessment];
GRANT SELECT ON [msdb].[dbo].[sysmail_account] TO [assessment];
-- USE master;
-- GO
-- EXECUTE sp_MSforeachdb 'USE [?]; BEGIN TRY DROP USER [assessment] END TRY BEGIN CATCH SELECT ERROR_MESSAGE() END CATCH';
-- DROP LOGIN [assessment];
Неподдерживаемые сценарии и ограничения
Рекомендации Azure не включают оценки цен, так как эта ситуация может отличаться в зависимости от региона, валюты и скидок, таких как Преимущество гибридного использования Azure. Чтобы получить оценку цен, используйте калькулятор цен Azure или создайте оценку SQL в службе "Миграция Azure".
Рекомендации по База данных SQL Azure с моделью приобретения на основе DTU не поддерживаются.
В настоящее время рекомендации Azure для База данных SQL Azure бессерверного уровня вычислений и эластичных пулов не поддерживаются.
Устранение неполадок
- Рекомендации не созданы
- Если рекомендации не были созданы, эта ситуация может означать, что конфигурации не определены, которые могут полностью удовлетворить требования к производительности исходного экземпляра. Чтобы узнать причины, по которым определенный размер, уровень служб или семейство оборудования было дисквалифицировано:
- Доступ к журналам из Azure Data Studio, перейдя в раздел " > Показать все команды открытых журналов > расширений"
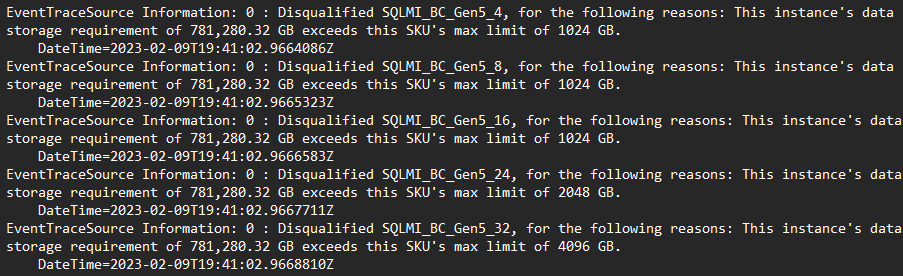
- Перейдите к открытому SkuRecommendationEvent.log Microsoft.mssql > SqlAssessmentLogs >
- Журнал содержит трассировку каждой потенциальной конфигурации, которая была оценена, и причина, по которой она была или не считается подходящей конфигурацией:
- Попробуйте повторно создать рекомендацию с включенной эластичной рекомендацией . Этот параметр использует альтернативную модель рекомендаций, которая использует персонализированную профилирование ценовых показателей для существующих клиентов в облаке.
- Если рекомендации не были созданы, эта ситуация может означать, что конфигурации не определены, которые могут полностью удовлетворить требования к производительности исходного экземпляра. Чтобы узнать причины, по которым определенный размер, уровень служб или семейство оборудования было дисквалифицировано:
