API таблиц и SQL в кластерах Apache Flink® в HDInsight в AKS
Внимание
Эта функция в настоящее время доступна для предварительного ознакомления. Дополнительные условия использования для предварительных версий Microsoft Azure включают более юридические термины, применимые к функциям Azure, которые находятся в бета-версии, в предварительной версии или в противном случае еще не выпущены в общую доступность. Сведения об этой конкретной предварительной версии см. в статье Azure HDInsight в предварительной версии AKS. Для вопросов или предложений функций отправьте запрос на AskHDInsight с подробными сведениями и следуйте за нами для получения дополнительных обновлений в сообществе Azure HDInsight.
Apache Flink предоставляет два реляционных API - API таблиц и SQL для единого потока и пакетной обработки. API таблиц — это API запросов, интегрированный с языком, который позволяет составить запросы от реляционных операторов, таких как выбор, фильтрация и присоединение интуитивно. Поддержка SQL Flink основана на Apache Calcite, которая реализует стандарт SQL.
Интерфейсы API таблиц и SQL легко интегрируются друг с другом и API DataStream Flink. Вы можете легко переключаться между всеми API и библиотеками, которые опираются на них.
Apache Flink SQL
Как и другие подсистемы SQL, запросы Flink работают в верхней части таблиц. Она отличается от традиционной базы данных, так как Flink не управляет неактивных данных локально; вместо этого запросы работают непрерывно над внешними таблицами.
Конвейеры обработки данных Flink начинаются с исходных таблиц и заканчиваются таблицами приемников. Исходные таблицы создают строки, управляемые во время выполнения запроса; они ссылаются на таблицы в предложении FROM запроса. Подключение могут быть типа HDInsight Kafka, HDInsight HBase, Центры событий Azure, баз данных, файловых систем или любой другой системы, соединитель которой находится в пути к классам.
Использование Flink SQL Client в HDInsight в кластерах AKS
См. эту статью о том, как использовать CLI из Secure Shell на портал Azure. Ниже приведены некоторые краткие примеры начала работы.
Запуск клиента SQL
./bin/sql-client.shПередача sql-файла инициализации для запуска вместе с sql-client
./sql-client.sh -i /path/to/init_file.sqlНастройка конфигурации в sql-client
SET execution.runtime-mode = streaming; SET sql-client.execution.result-mode = table; SET sql-client.execution.max-table-result.rows = 10000;
SQL DDL
Flink SQL поддерживает следующие инструкции CREATE
- СОЗДАТЬ ТАБЛИЦУ
- СОЗДАТЬ БАЗУ ДАННЫХ
- CREATE CATALOG
Ниже приведен пример синтаксиса для определения исходной таблицы с помощью соединителя jdbc для подключения к MSSQL с идентификатором, именем в качестве столбцов в инструкции CREATE TABLE
CREATE TABLE student_information (
id BIGINT,
name STRING,
address STRING,
grade STRING,
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:sqlserver://servername.database.windows.net;database=dbname;encrypt=true;trustServerCertificate=true;create=false;loginTimeout=30',
'table-name' = 'students',
'username' = 'username',
'password' = 'password'
);
CREATE DATABASE :
CREATE DATABASE students;
CREATE CATALOG:
CREATE CATALOG myhive WITH ('type'='hive');
Непрерывные запросы можно запускать в верхней части этих таблиц
SELECT id,
COUNT(*) as student_count
FROM student_information
GROUP BY grade;
Запись в таблицу приемника из исходной таблицы:
INSERT INTO grade_counts
SELECT id,
COUNT(*) as student_count
FROM student_information
GROUP BY grade;
Добавление зависимостей
Инструкции JAR используются для добавления jar-адресов пользователей в классpath или удаления jar-адресов пользователей из classpath или отображения добавленных jar-объектов в пути класса во время выполнения.
Flink SQL поддерживает следующие инструкции JAR:
- ADD JAR
- ПОКАЗАТЬ JARS
- УДАЛЕНИЕ JAR-ФАЙЛА
Flink SQL> ADD JAR '/path/hello.jar';
[INFO] Execute statement succeed.
Flink SQL> ADD JAR 'hdfs:///udf/common-udf.jar';
[INFO] Execute statement succeed.
Flink SQL> SHOW JARS;
+----------------------------+
| jars |
+----------------------------+
| /path/hello.jar |
| hdfs:///udf/common-udf.jar |
+----------------------------+
Flink SQL> REMOVE JAR '/path/hello.jar';
[INFO] The specified jar is removed from session classloader.
Хранилище метаданных Hive в кластерах Apache Flink® в HDInsight в AKS
Каталоги предоставляют метаданные, такие как базы данных, таблицы, секции, представления и функции и сведения, необходимые для доступа к данным, хранящимся в базе данных или других внешних системах.
В HDInsight в AKS Flink мы поддерживаем два варианта каталога:
GenericInMemoryCatalog
GenericInMemoryCatalog — это реализация каталога в памяти. Все объекты доступны только для времени существования сеанса SQL.
HiveCatalog
HiveCatalog служит двумя целями: в качестве постоянного хранилища для чистых метаданных Flink, а также в качестве интерфейса для чтения и записи существующих метаданных Hive.
Примечание.
HDInsight в кластерах AKS поставляется с интегрированным вариантом хранилища метаданных Hive для Apache Flink. Хранилище метаданных Hive можно выбрать во время создания кластера
Создание и регистрация баз данных Flink в каталогах
См. эту статью по использованию интерфейса командной строки и началу работы с клиентом Flink SQL из Secure Shell на портал Azure.
Запуск сеанса
sql-client.sh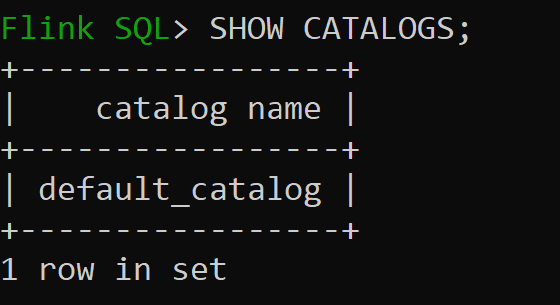
Default_catalog — это каталог по умолчанию в памяти
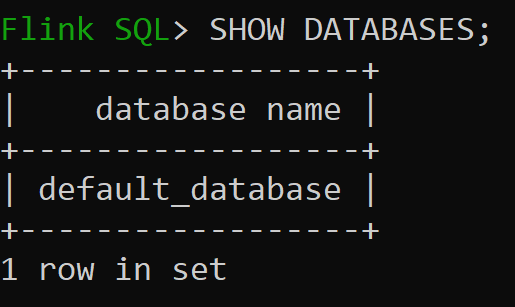
Давайте теперь проверка базу данных по умолчанию каталога в памяти
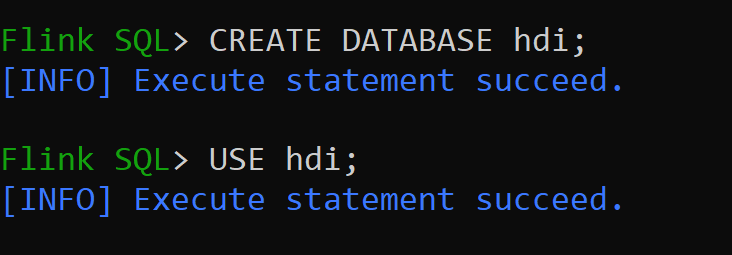
Давайте создадим каталог Hive версии 3.1.2 и используйте его
CREATE CATALOG myhive WITH ('type'='hive'); USE CATALOG myhive;Примечание.
HDInsight в AKS поддерживает Hive 3.1.2 и Hadoop 3.3.2. Задано
hive-conf-dirрасположение/opt/hive-confДавайте создадим базу данных в каталоге hive и создадим ее по умолчанию для сеанса (если не изменено).
Создание и регистрация таблиц Hive в каталоге Hive
Следуйте инструкциям по созданию и регистрации баз данных Flink в каталоге
Давайте создадим таблицу Flink типа соединителя Hive без секции
CREATE TABLE hive_table(x int, days STRING) WITH ( 'connector' = 'hive', 'sink.partition-commit.delay'='1 s', 'sink.partition-commit.policy.kind'='metastore,success-file');Вставка данных в hive_table
INSERT INTO hive_table SELECT 2, '10'; INSERT INTO hive_table SELECT 3, '20';Чтение данных из hive_table
Flink SQL> SELECT * FROM hive_table; 2023-07-24 09:46:22,225 INFO org.apache.hadoop.mapred.FileInputFormat[] - Total input files to process : 3 +----+-------------+--------------------------------+ | op | x | days | +----+-------------+--------------------------------+ | +I | 3 | 20 | | +I | 2 | 10 | | +I | 1 | 5 | +----+-------------+--------------------------------+ Received a total of 3 rowsПримечание.
Каталог хранилища Hive находится в указанном контейнере учетной записи хранения, выбранной во время создания кластера Apache Flink, можно найти в каталоге hive/warehouse/
Позволяет создать таблицу Flink типа соединителя hive с помощью секции
CREATE TABLE partitioned_hive_table(x int, days STRING) PARTITIONED BY (days) WITH ( 'connector' = 'hive', 'sink.partition-commit.delay'='1 s', 'sink.partition-commit.policy.kind'='metastore,success-file');
Внимание
В Apache Flink существует известное ограничение. Для секций выбираются последние столбцы n, независимо от определяемого пользователем столбца секций. FLINK-32596 Ключ секции будет неправильным при использовании диалекта Flink для создания таблицы Hive.
Справочные материалы
- API таблиц Apache Flink и SQL
- Apache, Apache Flink, Flink и связанные открытый код имена проектов являются товарными знакамиApache Software Foundation (ASF).