Что такое Apache Spark™ в HDInsight в AKS? (Предварительная версия)
Примечание.
Мы отставим Azure HDInsight в AKS 31 января 2025 г. До 31 января 2025 г. необходимо перенести рабочие нагрузки в Microsoft Fabric или эквивалентный продукт Azure, чтобы избежать резкого прекращения рабочих нагрузок. Оставшиеся кластеры в подписке будут остановлены и удалены из узла.
До даты выхода на пенсию будет доступна только базовая поддержка.
Внимание
Эта функция в настоящее время доступна для предварительного ознакомления. Дополнительные условия использования для предварительных версий Microsoft Azure включают более юридические термины, применимые к функциям Azure, которые находятся в бета-версии, в предварительной версии или в противном случае еще не выпущены в общую доступность. Сведения об этой конкретной предварительной версии см. в статье Azure HDInsight в предварительной версии AKS. Для вопросов или предложений функций отправьте запрос на AskHDInsight с подробными сведениями и следуйте за нами для получения дополнительных обновлений в сообществе Azure HDInsight.
Apache Spark™ — это платформа параллельной обработки, которая поддерживает обработку в памяти для повышения производительности приложений аналитики больших данных.
Apache Spark™ предоставляет примитивы для вычислений кластера в памяти. Задание Spark может загрузить данные, поместить их в кэш в памяти и запрашивать их неоднократно. Вычисления в памяти быстрее, чем приложения на основе дисков, такие как Hadoop, которые совместно передают данные через распределенную файловую систему Hadoop (HDFS). Apache Spark позволяет интегрировать с языками программирования Scala и Python, чтобы управлять распределенными наборами данных, такими как локальные коллекции. Нет необходимости структурировать обмен данными как операции сопоставления и редукции.
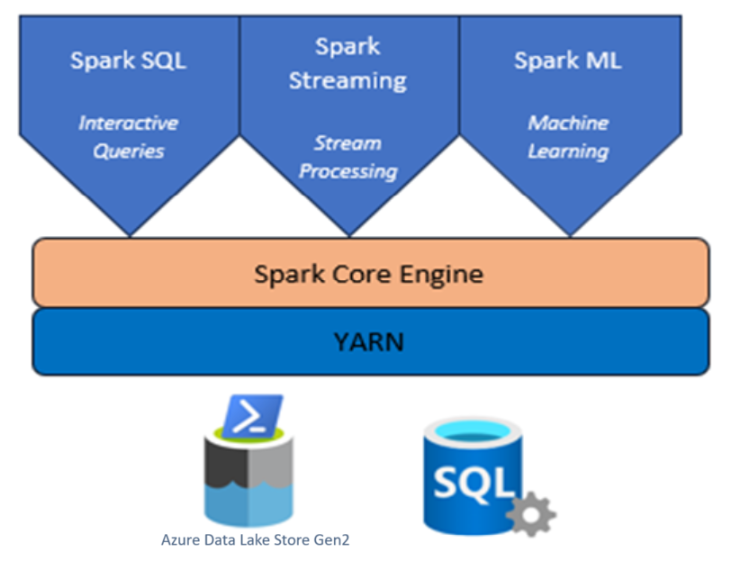
Кластер Apache Spark с HDInsight в AKS
Azure HDInsight — это управляемая комплексная служба аналитики с открытым кодом, предназначенная для предприятий.
Apache Spark™ в Azure HDInsight в AKS — это управляемая служба Spark в Microsoft Azure. С помощью Apache Spark в Azure HDInsight в AKS вы можете хранить и обрабатывать данные в Azure. Кластеры Spark в HDInsight совместимы с или Azure Data Lake Storage 2-го поколения, позволяют применять обработку Spark к существующим хранилищам данных.
Платформа Apache Spark для HDInsight в AKS обеспечивает быструю аналитику данных и кластерные вычисления с помощью обработки в памяти. Jupyter Notebook позволяет работать с данными, объединять код с текстом Markdown и выполнять простые визуализации.
Apache Spark в AKS в HDInsight состоит из нескольких компонентов в виде модулей pod.
Контроллеры кластера
Контроллеры кластера отвечают за установку соответствующей службы и управление ими. Различные контроллеры устанавливаются и управляются в кластере Spark.
Компоненты службы Apache Spark
Служба Zookeeper: трехузловой кластер Zookeeper служит распределенным координатором или хранилищем высокого уровня доступности для других служб.
Служба Yarn: кластер Hadoop Yarn, задания Spark будут запланированы в кластере в качестве приложений Yarn.
Клиентские интерфейсы: кластеры Apache Spark в HDInsight в AKS предоставляют различные клиентские интерфейсы. Livy Server, Jupyter Notebook, Spark History Server предоставляет службы Spark в HDInsight для пользователей AKS.
Справочные материалы
- Apache, Apache Spark, Spark и связанные открытый код имена проектов являются товарными знаками Apache Software Foundation (ASF).