Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
В этом учебнике описано, как создавать кластеры Apache HBase в HDInsight, создавать таблицы HBase и запрашивать таблицы с помощью Apache Hive. Общие сведения об HBase см. в обзоре Обзор HBase в HDInsight.
В этом руководстве описано следующее:
- Создание кластера Apache HBase
- Создание таблиц HBase и вставка данных
- Использование Apache Hive для создания запросов к Apache HBase
- Использование REST API HBase с помощью Curl
- Проверка состояния кластера
Предварительные условия
Клиент SSH. Дополнительные сведения см. в руководстве по подключению к HDInsight (Apache Hadoop) с помощью SSH.
Bash. В примерах, приведенных в этой статье, для команд curl используется оболочка Bash в Windows 10. Шаги установки см. в статье Windows Subsystem for Linux Installation Guide for Windows 10 (Подсистема Windows для Linux в Windows 10). Другие оболочки Unix также работают. Примеры curl с некоторыми небольшими изменениями могут работать в командной строке Windows. Либо можете использовать командлет Windows PowerShell Invoke-RestMethod.
Создание кластера Apache HBase
Следующая процедура использует шаблон Azure Resource Manager для создания кластера HBase. Шаблон также позволяет создать зависимую учетную запись службы хранилища Azure по умолчанию. Описание параметров, используемых в процедуре, и других методов создания кластеров см. в статье Создание кластеров Hadoop под управлением Linux в HDInsight.
Выберите следующее изображение, чтобы открыть шаблон на портале Azure. Шаблон расположен в шаблонах быстрого запуска Azure.

В диалоговом окне Настраиваемое развертывание укажите следующие значения:
Свойство / Имущество Описание Подписка Выберите подписку Azure, которая используется для создания этого кластера. Группа ресурсов Создайте группу управления ресурсами Azure или выберите существующую. Расположение Укажите расположение группы ресурсов. ИмяКластера Укажите имя кластера HBase. Имя для входа и пароль для кластера Имя входа по умолчанию — admin.Имя пользователя SSH и пароль Имя пользователя по умолчанию — sshuser.Остальные параметры являются необязательными.
У каждого кластера есть зависимость от учетной записи Azure Storage. После удаления кластера данные остаются в учетной записи хранения. Имя хранилища по умолчанию в кластере — это имя кластера с добавлением слова "хранилище". Это прописано в разделе переменных в коде шаблона.
Установите флажок Я принимаю указанные выше условия и выберите Приобрести. Процесс создания кластера занимает около 20 минут.
После удаления кластера HBase можно создать другой кластер HBase с помощью того же контейнера BLOB-объектов по умолчанию. Новый кластер получит таблицы HBase, созданные в исходном кластере. Перед удалением кластера рекомендуется отключить таблицы HBase, чтобы избежать несогласованности.
Создание таблиц и вставка данных
Для подключения к кластерам HBase можно использовать протокол SSH, а для создания таблиц HBase, вставки данных и создания запросов к данным — Apache HBase Shell.
Для большинства пользователей данные отображаются в табличном формате:

В HBase (реализация Cloud BigTable) те же данные выглядят следующим образом:

Использование оболочки HBase
С помощью команды
sshподключитесь к кластеру HBase. Измените следующую команду, заменивCLUSTERNAMEимя кластера, а затем введите команду:ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.netС помощью команды
hbase shellзапустите интерактивную оболочку HBase. В строку SSH-подключения введите следующую команду:hbase shellИспользуйте
createкоманду для создания таблицы HBase с двумя семействами столбцов. В именах таблиц и столбцов учитывается регистр. Введите следующую команду:create 'Contacts', 'Personal', 'Office'С помощью команды
listвыведите список всех таблиц HBase. Введите следующую команду:listС помощью команды
putвставьте значения в указанный столбец строки в определенной таблице. Введите следующие команды:put 'Contacts', '1000', 'Personal:Name', 'John Dole' put 'Contacts', '1000', 'Personal:Phone', '1-425-000-0001' put 'Contacts', '1000', 'Office:Phone', '1-425-000-0002' put 'Contacts', '1000', 'Office:Address', '1111 San Gabriel Dr.'С помощью команды
scanвыполните сканирование данных таблицыContactsи верните их. Введите следующую команду:scan 'Contacts'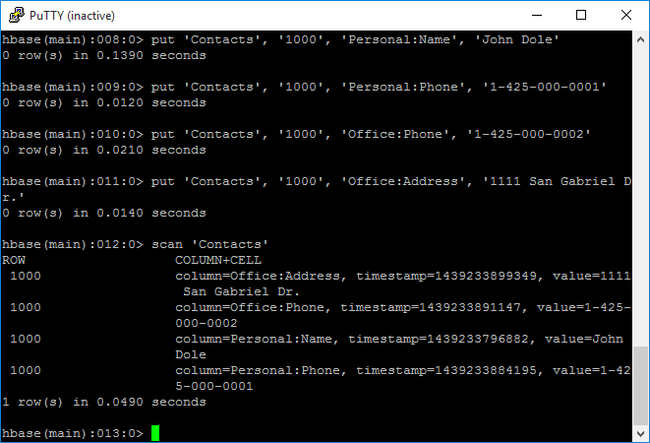
С помощью команды
getполучите содержимое строки. Введите следующую команду:get 'Contacts', '1000'Вы увидите похожие результаты, что и при использовании команды
scan, поскольку есть только одна строка.Дополнительные сведения о схеме таблицы HBase см. в этой статье. Дополнительные команды HBase см. в справочнике по Apache HBase.
С помощью команды
exitостановите интерактивную оболочку HBase. Введите следующую команду:exit
Для массовой загрузки данных в таблицу контактов HBase
HBase включает несколько методов загрузки данных в таблицы. Для получения дополнительных сведений обратитесь к разделу Массовая загрузка.
Пример файла данных можно найти в общедоступном файловом контейнере wasb://hbasecontacts@hditutorialdata.blob.core.windows.net/contacts.txt. Файл данных содержит:
8396 Calvin Raji 230-555-0191 230-555-0191 5415 San Gabriel Dr.
16600 Karen Wu 646-555-0113 230-555-0192 9265 La Paz
4324 Karl Xie 508-555-0163 230-555-0193 4912 La Vuelta
16891 Jonn Jackson 674-555-0110 230-555-0194 40 Ellis St.
3273 Miguel Miller 397-555-0155 230-555-0195 6696 Anchor Drive
3588 Osa Agbonile 592-555-0152 230-555-0196 1873 Lion Circle
10272 Julia Lee 870-555-0110 230-555-0197 3148 Rose Street
4868 Jose Hayes 599-555-0171 230-555-0198 793 Crawford Street
4761 Caleb Alexander 670-555-0141 230-555-0199 4775 Kentucky Dr.
16443 Terry Chander 998-555-0171 230-555-0200 771 Northridge Drive
При желании вы можете создать текстовый файл и отправить его в свою учетную запись хранения. Дополнительные сведения см. в статье Upload data for Apache Hadoop jobs in HDInsight (Отправка данных для заданий Apache Hadoop в HDInsight).
Эта процедура использует таблицу Contacts HBase, созданную в последней процедуре.
В открытом сеансе SSH-подключения выполните следующую команду, чтобы преобразовать файл данных в StoreFiles и сохранить по относительному пути, указанному в
Dimporttsv.bulk.output.hbase org.apache.hadoop.hbase.mapreduce.ImportTsv -Dimporttsv.columns="HBASE_ROW_KEY,Personal:Name,Personal:Phone,Office:Phone,Office:Address" -Dimporttsv.bulk.output="/example/data/storeDataFileOutput" Contacts wasb://hbasecontacts@hditutorialdata.blob.core.windows.net/contacts.txtДля передачи данных из
/example/data/storeDataFileOutputв таблицу HBase выполните следующую команду:hbase org.apache.hadoop.hbase.mapreduce.LoadIncrementalHFiles /example/data/storeDataFileOutput ContactsОткройте оболочку HBase и выполните команду
scanдля получения списка содержимого таблицы.
Использование Apache Hive для создания запросов к Apache HBase
Вы можете запрашивать данные в таблицах HBase с помощью Apache Hive. В этом разделе создается таблица Hive, которая соответствует таблице HBase и используется для запросов к данным в вашей таблице HBase.
В открытом сеансе SSH-подключения используйте следующую команду, чтобы запустить Beeline.
beeline -u 'jdbc:hive2://localhost:10001/;transportMode=http' -n adminДополнительные сведения о Beeline см. в статье Использование Hive с Hadoop в HDInsight с применением Beeline.
Выполните приведенный ниже скрипт HiveQL, чтобы создать таблицу Hive, сопоставляемую с таблицей HBase. Перед выполнением этой инструкции убедитесь, что вы создали упомянутый в этой статье пример таблицы с помощью оболочки HBase.
CREATE EXTERNAL TABLE hbasecontacts(rowkey STRING, name STRING, homephone STRING, officephone STRING, officeaddress STRING) STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' WITH SERDEPROPERTIES ('hbase.columns.mapping' = ':key,Personal:Name,Personal:Phone,Office:Phone,Office:Address') TBLPROPERTIES ('hbase.table.name' = 'Contacts');Запустите приведенный ниже скрипт HiveQL, чтобы запросить данные в таблице HBase.
SELECT count(rowkey) AS rk_count FROM hbasecontacts;Чтобы выйти из Beeline, используйте инструкцию
!exit.Чтобы выйти из сеанса SSH-подключения, используйте
exit.
Отдельные кластеры Hive и HBase
Запрос Hive для доступа к данным HBase не следует выполнять из кластера HBase. Для запроса данных HBase можно использовать любой кластер, поставляемый с Hive (включая Spark, Hadoop, HBase или Interactive Query), при условии что выполнены следующие шаги:
- Оба кластера должны быть подключены к одной виртуальной сети и подсети.
- Скопируйте
/usr/hdp/$(hdp-select --version)/hbase/conf/hbase-site.xmlс головных узлов кластера HBase на головные узлы и рабочие узлы кластера Hive.
Безопасные кластеры
Данные HBase можно также запрашивать из Hive с помощью HBase с поддержкой протокола ESP:
- При использовании шаблона с несколькими кластерами оба кластера должны включать протокол ESP.
- Чтобы разрешить Hive запрашивать данные HBase, убедитесь, что пользователю
hiveпредоставлены разрешения на доступ к данным HBase с помощью подключаемого модуля Apache Ranger HBase - При использовании отдельных кластеров с поддержкой ESP содержимое головного
/etc/hostsкластера HBase должно быть добавлено к/etc/hostsголовным узлам кластера Hive и рабочим узлам.
Примечание.
После масштабирования любого из кластеров, необходимо снова добавить /etc/hosts.
Использование REST API HBase с Curl
REST API HBase защищен с помощью базовой аутентификации. Чтобы обеспечить безопасную отправку учетных данных на сервер, все запросы следует отправлять с помощью протокола HTTPS.
Чтобы включить REST API HBase в кластере HDInsight, добавьте следующий пользовательский скрипт запуска в раздел Действие скрипта. Сценарий запуска можно добавить во время или после создания кластера. Для пункта Тип узла задайте значение Серверы региона, чтобы сценарий выполнялся только на серверах регионов HBase. Скрипт запускает прокси-сервер REST HBase на порте 8090 на серверах регионов.
#! /bin/bash THIS_MACHINE=`hostname` if [[ $THIS_MACHINE != wn* ]] then printf 'Script to be executed only on worker nodes' exit 0 fi RESULT=`pgrep -f RESTServer` if [[ -z $RESULT ]] then echo "Applying mitigation; starting REST Server" sudo python /usr/lib/python2.7/dist-packages/hdinsight_hbrest/HbaseRestAgent.py else echo "REST server already running" exit 0 fiЗадайте переменную среды для простоты использования. Измените следующие команды, заменив
MYPASSWORDпароль для входа в кластер. ЗаменитеMYCLUSTERNAMEименем кластера HBase. Затем введите указанные ниже команды.export PASSWORD='MYPASSWORD' export CLUSTER_NAME=MYCLUSTERNAMEДля получения списка имеющихся таблиц HBase используйте следующую команду:
curl -u admin:$PASSWORD \ -G https://$CLUSTER_NAME.azurehdinsight.net/hbaserest/Для создания новой таблицы HBase с двумя семействами столбцов используйте следующую команду:
curl -u admin:$PASSWORD \ -X PUT "https://$CLUSTER_NAME.azurehdinsight.net/hbaserest/Contacts1/schema" \ -H "Accept: application/json" \ -H "Content-Type: application/json" \ -d "{\"@name\":\"Contact1\",\"ColumnSchema\":[{\"name\":\"Personal\"},{\"name\":\"Office\"}]}" \ -vСхема предоставляется в формате JSON.
Чтобы вставить какие-либо данные, используйте следующую команду:
curl -u admin:$PASSWORD \ -X PUT "https://$CLUSTER_NAME.azurehdinsight.net/hbaserest/Contacts1/false-row-key" \ -H "Accept: application/json" \ -H "Content-Type: application/json" \ -d "{\"Row\":[{\"key\":\"MTAwMA==\",\"Cell\": [{\"column\":\"UGVyc29uYWw6TmFtZQ==\", \"$\":\"Sm9obiBEb2xl\"}]}]}" \ -vBase64 кодирует значения, указанные в параметре
-d. В примере:MTAwMA==: 1000;
Личное: Имя
Sm9obiBEb2xl: John Dole.
false-row-key позволяет вставить несколько (пакетированных) значений.
Для получения строки используйте следующую команду:
curl -u admin:$PASSWORD \ GET "https://$CLUSTER_NAME.azurehdinsight.net/hbaserest/Contacts1/1000" \ -H "Accept: application/json" \ -v
Примечание.
Сканирование через конечную точку кластера пока не поддерживается.
Для получения дополнительной информации о HBase Rest см. руководство пользователя Apache HBase.
Примечание.
Thrift не поддерживается HBase в HDInsight.
При использовании Curl или любого другого взаимодействия REST с WebHCat необходимо пройти проверку подлинности запросов, указав имя пользователя и пароль администратора кластера HDInsight. Имя кластера необходимо также использовать в составе универсального кода ресурса (URI), используемого для отправки запросов на сервер.
curl -u <UserName>:<Password> \
-G https://<ClusterName>.azurehdinsight.net/templeton/v1/status
Вы должны получить ответ, аналогичный приведенному ниже.
{"status":"ok","version":"v1"}
Проверка состояния кластера
HBase на HDInsight поставляется с веб-интерфейсом для наблюдения за кластерами. С помощью веб-интерфейса вы можете запросить статистику или сведения о регионах.
Доступ к основному интерфейсу HBase
Войдите в веб-интерфейс Ambari по адресу
https://CLUSTERNAME.azurehdinsight.net, гдеCLUSTERNAME— это имя кластера HBase.В меню слева выберите HBase.
В верхней части страницы выберите Быстрые ссылки, выберите ссылку на активный узел Zookeeper, а затем щелкните HBase Master UI (Основной интерфейс HBase). Интерфейс откроется в новой вкладке браузера.
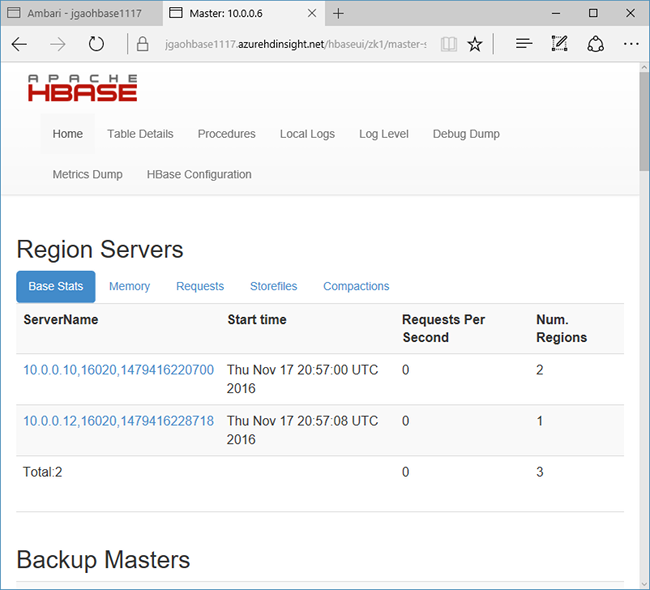
Основной интерфейс HBase состоит из таких разделов:
- региональные серверы;
- главные серверы резервного копирования
- Таблицы
- задачи
- атрибуты ПО.
Воссоздание кластера
После удаления кластера HBase можно создать другой кластер HBase с помощью того же контейнера BLOB-объектов по умолчанию. Новый кластер получит таблицы HBase, созданные в исходном кластере. Но чтобы избежать несогласованности, перед удалением кластера рекомендуется отключить таблицы HBase.
Вы можете использовать команду HBase disable 'Contacts'.
Очистка ресурсов
Если вы не собираетесь использовать это приложение в дальнейшем, удалите созданный кластер HBase, сделав следующее:
- Войдите на портал Azure.
- В поле Поиск в верхней части страницы введите HDInsight.
- Выберите Кластеры HDInsight в разделе Службы.
- В списке кластеров HDInsight, который отобразится, щелкните ... рядом с кластером, созданным при работе с этим руководством.
- Нажмите кнопку Удалить. Нажмите кнопку Да.
Следующие шаги
Из этого руководства вы узнали, как создать кластер Apache HBase. Вы также научились создавать таблицы и просматривать данные в них, используя оболочку HBase. Кроме того вы узнали, как использовать Hive для запроса данных из таблиц HBase И как использовать REST API HBase C# для создания таблицы HBase и получения данных из таблицы. Дополнительные сведения см. на следующих ресурсах: