Автоматическое масштабирование кластеров Azure HDInsight
Функция автоматического масштабирования Azure HDInsight позволяет автоматически увеличивать или уменьшать число рабочих узлов в кластере на основе метрик кластера и политики масштабирования, принятых клиентами. Работа функции автомасштабирования заключается в масштабировании количества узлов в заранее заданных пределах на основе метрик производительности или заданного расписания операций увеличения и уменьшения масштаба
Как это работает
Функция автомасштабирования использует для активации событий масштабирования условия двух типов: пороговые значения для различных метрик производительности кластера (масштабирования на основе нагрузки) и триггеры на основе времени (масштабирование на основе расписания). Масштабирование на основе нагрузки изменяет количество узлов в кластере в пределах заданного диапазона с целью обеспечения оптимального использования ЦП и снижения стоимости владения. Масштабирование на основе расписания изменяет количество узлов в кластере на основе расписания операций увеличения и уменьшения масштаба.
В следующем видео представлены общие сведения о проблемах, которые решают автомасштабирование и как можно управлять затратами с помощью HDInsight.
Выбор масштабирования на основе нагрузки или на основе расписания
Можно использовать масштабирование на основе расписания:
- Если предполагается, что задания будут выполняться по фиксированным расписаниям и прогнозируемый период времени или если предполагается низкая нагрузка в определенное время суток, например в средах тестирования и разработки в нерабочее время, при выполнении заданий, завершаемых в конце дня.
Можно использовать масштабирование на основе нагрузки:
- Когда шаблоны нагрузки значительно и непредсказуемо изменяются в течение дня. Например, упорядочивание обработки данных с случайными колебаниями шаблонов нагрузки на основе различных факторов
Метрики кластера
Автомасштабирование постоянно выполняет мониторинг кластера и собирает следующие метрики:
| Метрическая | Description |
|---|---|
| Total Pending CPU (Общее число ожидающих ЦП) | Общее число ядер, необходимое для запуска выполнения всех ожидающих контейнеров. |
| Total Pending Memory (Общий объем ожидающей памяти) | Общий объем памяти (в МБ), необходимый для запуска выполнения всех отложенных контейнеров. |
| Total Free CPU (Общее число свободных ЦП) | Сумма всех неиспользуемых ядер на активных рабочих узлах. |
| Total Free Memory (Общий объем свободной памяти) | Сумма неиспользуемой памяти (в МБ) на активных рабочих узлах. |
| Used Memory per Node (Объем используемой памяти на каждом узле) | Нагрузка на рабочем узле. Рабочий узел, на котором используется 10 ГБ памяти, пребывает под большей нагрузкой, чем рабочий узел с 2 ГБ используемой памяти. |
| Число основных контейнеров приложений на каждом узле | Число основных контейнеров приложений, работающих на рабочем узле. Рабочий узел, на котором размещаются два основных контейнера, считается более важным, чем рабочий узел, на котором нет основных контейнеров. |
Эти метрики проверяются каждые 60 секунд. Компонент автомасштабирования увеличивает и уменьшает масштаб на основе этих метрик.
Условия масштабирования на основе нагрузки
При обнаружении следующих условий автомасштабирование выдает запрос на масштабирование:
| Вертикальное масштабирование | Вертикальное уменьшение масштаба |
|---|---|
| Общее число ожидающих ЦП больше, чем общее число свободных ЦП, в течение более чем 3-5 минут. | Общее количество ожидающих ЦП меньше общего объема свободного ЦП в течение более 3–5 минут. |
| Общий объем ожидающей памяти больше, чем общий объем свободной памяти, в течение более чем 3-5 минут. | Общий объем ожидающей памяти меньше общей свободной памяти в течение более 3–5 минут. |
При увеличении масштаба функция автомасштабирования отправляет запрос на увеличение масштаба с целью добавления требуемого числа узлов. Увеличение масштаба зависит от числа новых рабочих узлов, необходимого для удовлетворения текущих требований к ЦП и памяти.
Для уменьшения масштаба автомасштабирование выдает запрос на удаление некоторых узлов. Уменьшение масштаба зависит от числа основных контейнеров приложений на каждом узле. А также на текущих требованиях к ЦП и памяти. Служба также определяет, какие узлы являются кандидатами на удаление в зависимости от текущего состояния выполнения задания. При вертикальном уменьшении масштаба сначала узлы выводятся из эксплуатации, а затем они удаляются из кластера.
Рекомендации по настройке размера базы данных Ambari для автомасштабирования
Рекомендуется правильно настроить размер базы данных Ambari, чтобы получить преимущества автомасштабирования. Клиенты должны использовать правильный уровень базы данных и использовать пользовательскую базу данных Ambari для кластеров больших размеров. Ознакомьтесь с рекомендациями по размеру базы данных и headnode.
Совместимость кластера
Внимание
Функция автомасштабирования Azure HDInsight появилась в общедоступной версии от 7 ноября 2019 года для кластеров Spark и Hadoop. В эту версию включены усовершенствования, недоступные в предварительной версии этой функции. Если вы создали кластер Spark до 7 ноября 2019 года и хотите использовать функцию автомасштабирования в этом кластере, рекомендуется создать новый кластер и включить автомасштабирование в этом новом кластере.
Функция автомасштабирования для Interactive Query (LLAP) выпущена в виде общедоступной версии для HDI 4.0 27 августа 2020 г. Автомасштабирование доступно только в кластерах Spark, Hadoop и Interactive Query
Следующая таблица содержит типы и версии кластеров, совместимых с функцией автомасштабирования.
| Версия | Spark | Куст | Интерактивный запрос | HBase | Kafka |
|---|---|---|---|---|---|
| HDInsight 4.0 без ESP | Да | Да | Да* | No | No |
| HDInsight 4.0 с ESP | Да | Да | Да* | No | No |
| HDInsight 5.0 без ESP | Да | Да | Да* | No | No |
| HDInsight 5.0 с ESP | Да | Да | Да* | No | No |
* Кластеры Interactive Query можно настроить только для масштабирования на основе расписания. Для масштабирования на основе нагрузки их настроить нельзя.
Начать
Создание кластера с автомасштабированием на основе нагрузки
Чтобы включить функцию автомасштабирования с масштабированием на основе нагрузки, выполните следующие действия в рамках обычного процесса создания кластера.
На вкладке Конфигурация и цены установите флажок Включить автомасштабирование.
Выберите значение На основе нагрузки в поле Тип автомасштабирования.
Укажите требуемые значения для следующих свойств.
- Первоначальное число узлов для рабочего узла.
- Минимальное число рабочих узлов.
- Максимальное число рабочих узлов.
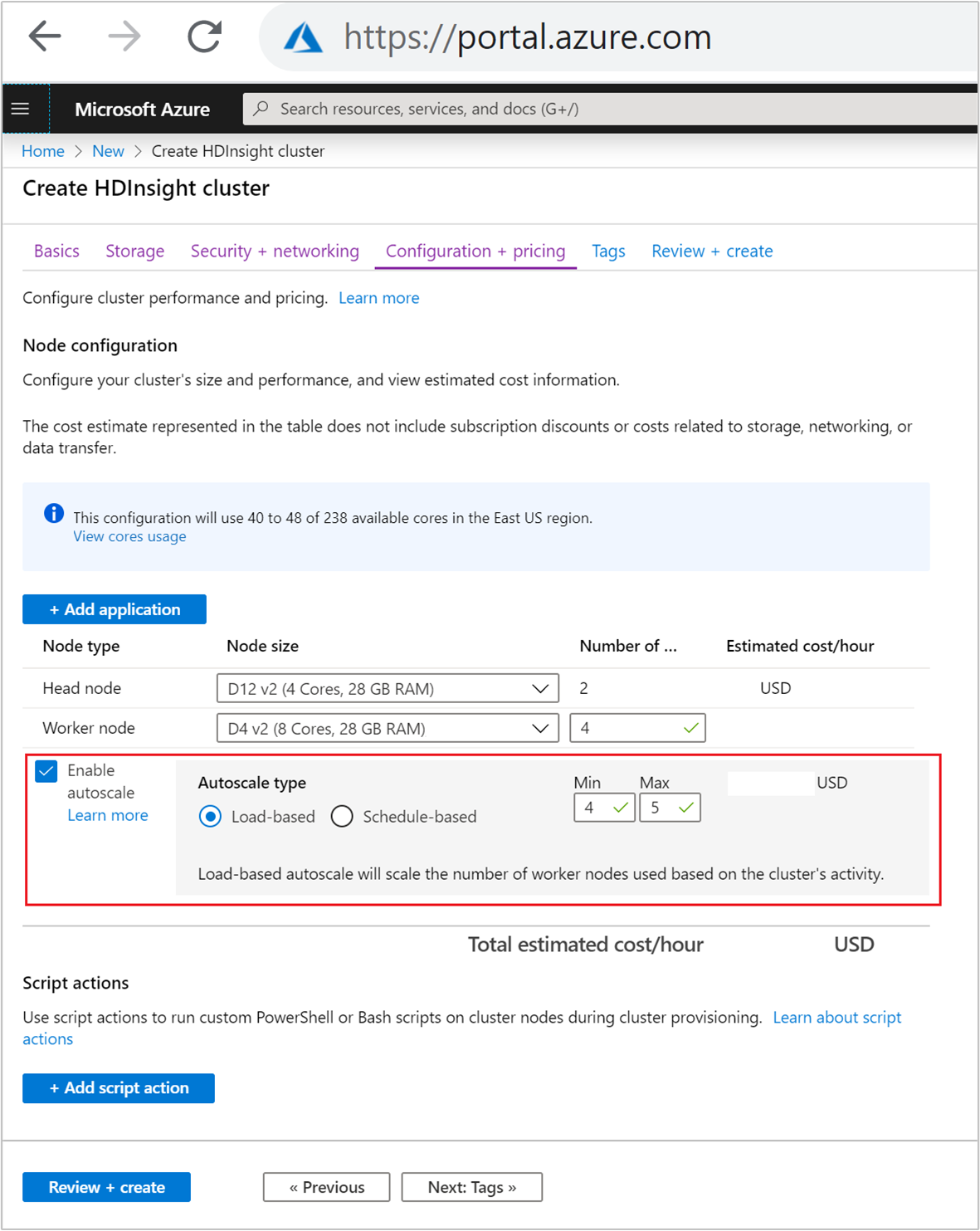
Начальное количество рабочих узлов должно быть в диапазоне между максимальным и минимальным количеством. Это значение определяет начальный размер кластера при его создании. В качестве минимального числа рабочих узлов следует указать три или более. Масштабирование кластера менее чем до трех узлов может привести к его зависанию в безопасном режиме вследствие недостаточной репликации файлов. Дополнительные сведения см. в разделе Зависание в безопасном режиме.
Создание кластера с автомасштабированием на основе расписания
Чтобы включить функцию автомасштабирования с масштабированием на основе расписания, выполните следующие действия в рамках обычного процесса создания кластера.
На вкладке Конфигурация и цены установите флажок Включить автомасштабирование.
Укажите число узлов для рабочего узла. Этот параметр управляет пределом увеличения масштаба кластера.
Выберите вариант На основе расписания в поле Тип автомасштабирования.
Нажмите кнопку Настройка, чтобы открыть окно Конфигурация автомасштабирования.
Выберите часовой пояс и нажмите кнопку + Добавить условие.
Выберите дни недели, к которым должно применяться новое условие.
Измените время вступления условия в силу и число узлов, до которого необходимо масштабировать кластер.
При необходимости добавьте дополнительные условия.
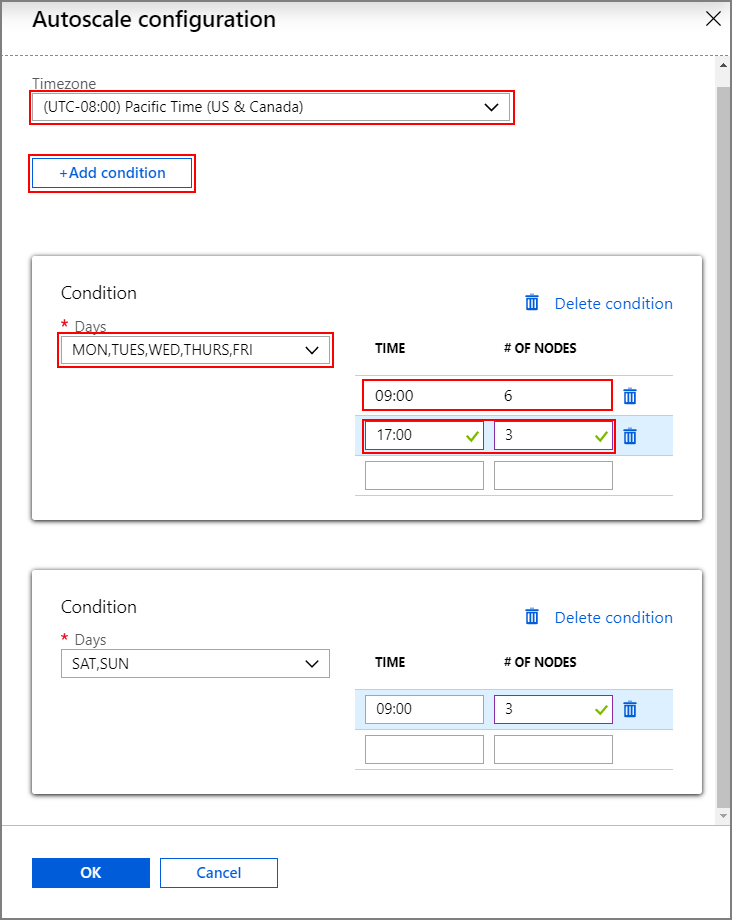
Число узлов должно находиться в диапазоне от 3 до максимального числа рабочих узлов, указанного перед добавлением условий.
Заключительные этапы создания
Выберите тип виртуальной машины для рабочих узлов. Для этого выберите виртуальную машину из раскрывающегося списка в поле Размер узла. После выбора типа виртуальной машины для каждого типа узла вы сможете увидеть предполагаемый диапазон затрат для всего кластера. Настройте типы виртуальных машин в соответствии с бюджетом.
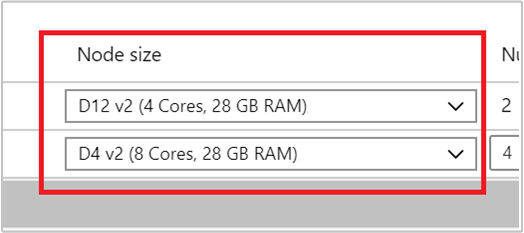
Ваша подписка имеет квоту емкости для каждого региона. Общее число ядер на головных узлах в сочетании с максимальным числом рабочих узлов не может превышать квоту емкости. Тем не менее эта квота — нестрогое ограничение. Вы всегда можете создать запрос в службу поддержки, чтобы легко ее повысить.
Примечание.
Если вы превысите общую квоту на ядра, вы получите сообщение о том, что максимальное число узлов превышает количество доступных ядер в регионе и нужно выбрать другой регион или обратиться в службу поддержки, чтобы увеличить квоту.
Дополнительные сведения о создании кластера HDInsight с помощью портала Azure см. в статье Создание кластеров под управлением Linux в HDInsight с помощью портала Azure.
Создание кластера с помощью шаблона Resource Manager
Автомасштабирование на основе нагрузки
Вы можете создать кластер HDInsight с автомасштабированием на основе нагрузки шаблона Azure Resource Manager, добавив autoscale узел в computeProfileworkernode>раздел со свойствами minInstanceCount и maxInstanceCount как показано в фрагменте json. Полный шаблон Resource Manager см . в разделе "Краткое руководство. Развертывание кластера Spark с включенным автомасштабированием на основе нагрузки".
{
"name": "workernode",
"targetInstanceCount": 4,
"autoscale": {
"capacity": {
"minInstanceCount": 3,
"maxInstanceCount": 10
}
},
"hardwareProfile": {
"vmSize": "Standard_D13_V2"
},
"osProfile": {
"linuxOperatingSystemProfile": {
"username": "[parameters('sshUserName')]",
"password": "[parameters('sshPassword')]"
}
},
"virtualNetworkProfile": null,
"scriptActions": []
}
Автомасштабирование на основе расписания
Чтобы создать кластер HDInsight с автомасштабированием на основе расписания с помощью шаблона Azure Resource Manager, добавьте узел autoscale в раздел computeProfile >workernode. Узел autoscale содержит объект recurrence , имеющий и timezoneschedule описывающий, когда происходит изменение. Полный шаблон Resource Manager см. здесь: Развертывание кластера Spark с поддержкой автомасштабирования на основе расписания.
{
"autoscale": {
"recurrence": {
"timeZone": "Pacific Standard Time",
"schedule": [
{
"days": [
"Monday",
"Tuesday",
"Wednesday",
"Thursday",
"Friday"
],
"timeAndCapacity": {
"time": "11:00",
"minInstanceCount": 10,
"maxInstanceCount": 10
}
}
]
}
},
"name": "workernode",
"targetInstanceCount": 4
}
Включение и отключение автомасштабирования для работающего кластера
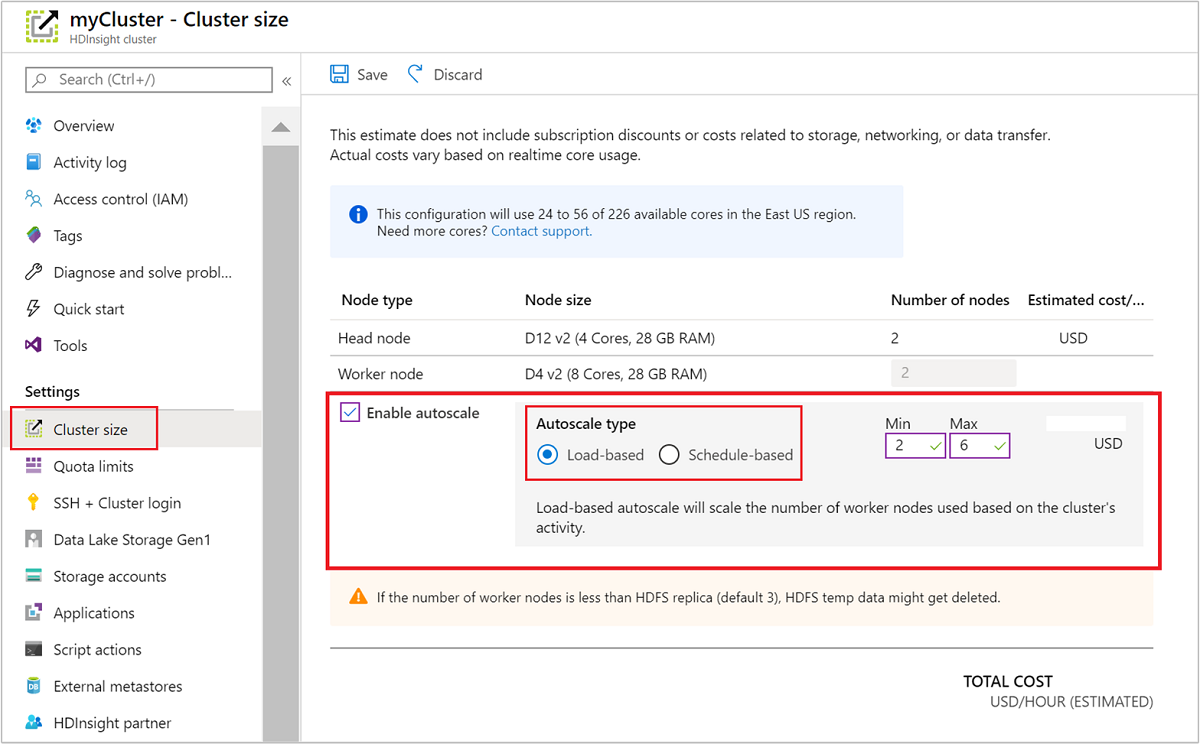
Использование портала Azure
Чтобы включить автомасштабирование на запущенном кластере, выберите Размер кластера в разделе Параметры. Затем выберите Включить автомасштабирование. Выберите требуемый тип автомасштабирования и укажите параметры масштабирования на основе нагрузки или расписания. Наконец, щелкните Сохранить.
Использование REST API
Чтобы включить или отключить автомасштабирование на запущенном кластере с помощью REST API, выполните запрос POST к конечной точке автомасштабирования:
https://management.azure.com/subscriptions/{subscription Id}/resourceGroups/{resourceGroup Name}/providers/Microsoft.HDInsight/clusters/{CLUSTERNAME}/roles/workernode/autoscale?api-version=2018-06-01-preview
Используйте в полезных данных запроса надлежащие параметры. Для включения автомасштабирования можно использовать следующие полезные данные JSON. Используйте полезные данные {autoscale: null} для отключения автомасштабирования.
{ "autoscale": { "capacity": { "minInstanceCount": 3, "maxInstanceCount": 5 } } }
Полное описание всех параметров полезных данных см. в предыдущем разделе о включении автомасштабирования на основе нагрузки. Не рекомендуется принудительно отключать службу автомасштабирования в работающем кластере.
Мониторинг действий автомасштабирования
Состояние кластера
Состояние кластера на портале Azure можно использовать для мониторинга действий автомасштабирования.
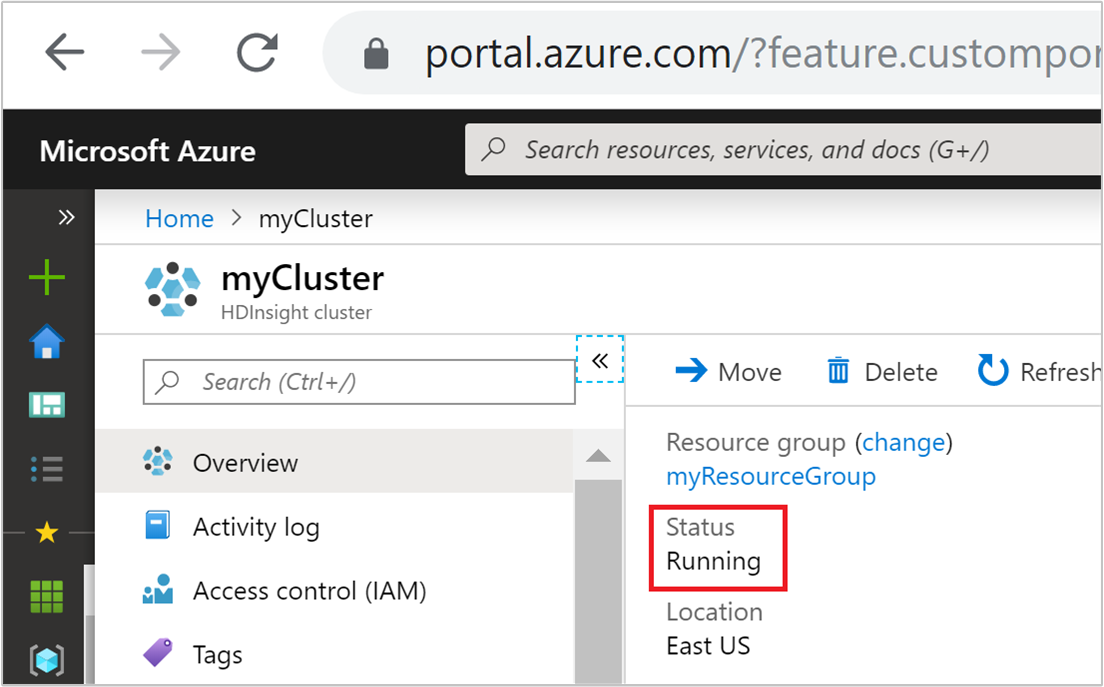
Все сообщения о состоянии кластера, которые могут отображаться, описаны в следующем списке.
| Состояние кластера | Description |
|---|---|
| Выполняется | Кластер работает в обычном режиме. Все предыдущие действия автомасштабирования успешно завершены. |
| Обновление | Выполняется обновление конфигурации автомасштабирования кластера. |
| Конфигурация HDInsight | Выполняется операция увеличения или уменьшения масштаба кластера. |
| Ошибка обновления | При обновлении конфигурации автомасштабирования в HDInsight возникли проблемы. Клиенты могут либо повторить попытку обновления, либо отключить автомасштабирование. |
| Ошибка | Что-то не так с кластером, и использовать его нельзя. Удалите этот кластер и создайте новый. |
Чтобы просмотреть текущее число узлов в кластере, откройте диаграмму Размер кластера на странице Обзор для кластера. Или в разделе Параметры выберите Размер кластера.
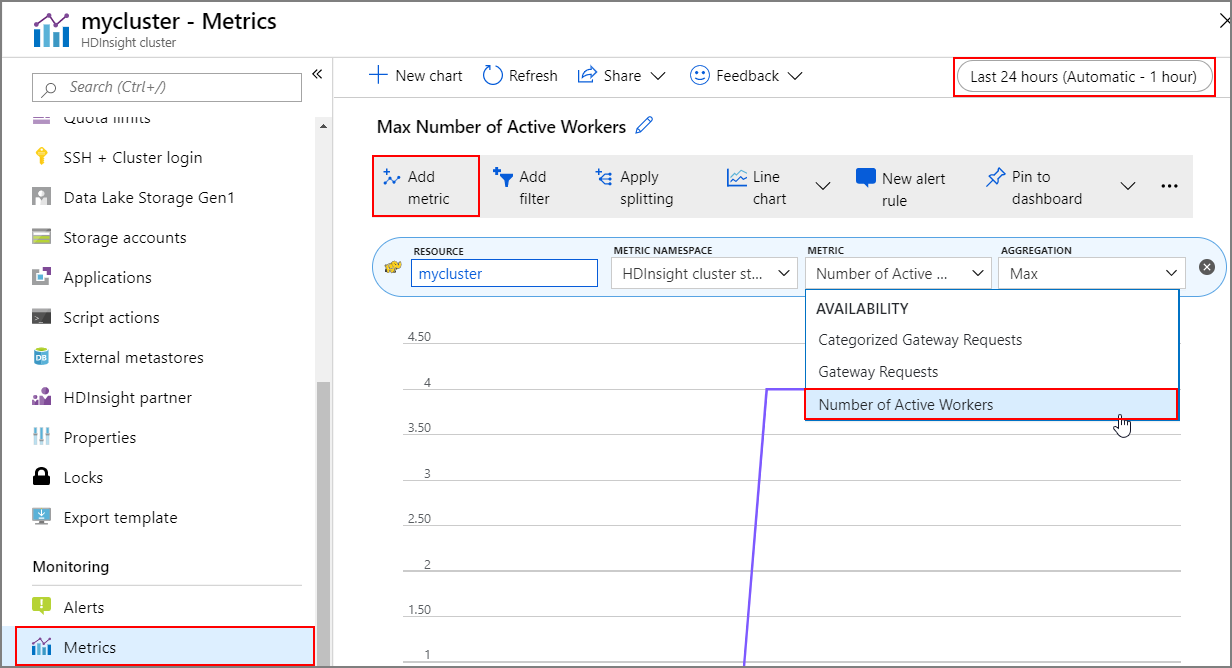
Журнал операций
Журнал операций увеличения и уменьшения масштаба кластера можно просматривать как часть метрик кластера. Кроме того, можно вывести список всех действий масштабирования за последний день, неделю или другой период времени.
В разделе Мониторинг выберите Метрики. Затем в раскрывающемся списке Метрика выберите Добавить метрику и Число активных рабочих ролей. Нажмите кнопку в правом верхнем углу, чтобы изменить диапазон времени.
Рекомендации
Учитывайте задержку операций вертикального увеличения или уменьшения масштаба.
Выполнение операции масштабирования в целом может занять от 10 до 20 минут. Запланируйте эту задержку при настройке пользовательского расписания. Например, если к 09:00 размер кластера должен составлять 20, задайте для триггера по расписанию более раннее время, например 08:30 или ранее, чтобы выполнить операцию масштабирования к 09:00.
Подготовка к вертикальному уменьшению масштаба
В процессе вертикального уменьшения масштаба кластера функция автомасштабирования выводит из употребления узлы для соответствия целевому размеру. При автомасштабировании на основе нагрузки, если задачи выполняются на этих узлах, автомасштабирование ожидает завершения задач для кластеров Spark и Hadoop. Поскольку каждый рабочий узел также играет роль в HDFS, временные данные сдвигаются на оставшиеся рабочие узлы. Убедитесь в том, что на оставшихся узлах достаточно места для размещения всех временных данных.
Примечание.
В случае автоматического уменьшения масштаба на основе расписания корректное прекращение использования не поддерживается. Это может вызвать сбои заданий во время операции уменьшения масштаба, и рекомендуется планировать расписания на основе предполагаемых шаблонов расписаний заданий, чтобы предусмотреть достаточное время для выполнения текущих заданий. Вы можете задать расписания с учетом диапазонов затраченного времени при выполнении предыдущих заданий, что позволит избежать сбоев заданий.
Настройка автомасштабирования на основе расписания на базе шаблона использования
При настройке автомасштабирования на основе расписания необходимо понимать схему использования кластера. Панель мониторинга Grafana поможет разобраться в работе со слотами загрузки и выполнения запросов. На панели мониторинга можно увидеть доступные слоты исполнителя и их общее число.
Ниже приведен способ оценки количества рабочих узлов, необходимых для работы. Рекомендуется предоставить еще 10 % буфера для обработки вариантов рабочей нагрузки.
Количество используемых слотов исполнителя = Всего слотов исполнителя — всего доступных слотов исполнителя.
Требуемое число рабочих узлов = количество фактически используемых слотов исполнителя / (hive.llap.daemon.num.executors + hive.llap.daemon.task.scheduler.wait.queue.size)
*hive.llap.daemon.num.executors можно настроить (значение по умолчанию: 4)
*hive.llap.daemon.task.scheduler.wait.queue.size можно настроить (значение по умолчанию: 10)
Действия настраиваемого сценария
Пользовательские действия скриптов в основном используются для настройки узлов (т. е. HeadNode / WorkerNodes), которые позволяют нашим клиентам настраивать определенные библиотеки и инструменты, которые используются ими. Одним из распространенных вариантов использования является задания, которые выполняются в кластере, могут иметь некоторые зависимости от сторонней библиотеки, принадлежащей клиенту, и она должна быть доступна на узлах для успешного выполнения задания. Для автомасштабирования в настоящее время мы поддерживаем пользовательские действия скриптов, которые сохраняются, поэтому каждый раз, когда новые узлы добавляются в кластер в рамках операции увеличения масштаба, эти сохраненные действия скрипта будут выполняться и отправляться, что контейнеры или задания будут выделены на них. Хотя пользовательские действия скрипта помогают загружать новые узлы, рекомендуется оставить его минимальным, так как это приведет к общей задержке увеличения масштаба и может привести к влиянию запланированных заданий.
Учитывайте минимальный размер кластера.
Не уменьшайте кластер менее чем до трех узлов. Масштабирование кластера менее чем до трех узлов может привести к его зависанию в безопасном режиме вследствие недостаточной репликации файлов. Дополнительные сведения см. в разделе Зависание в безопасном режиме.
Доменные службы Microsoft Entra и операции масштабирования
Если вы используете кластер HDInsight с корпоративным пакетом безопасности (ESP), присоединенным к управляемому домену доменных служб Microsoft Entra, рекомендуется регулировать нагрузку на доменные службы Microsoft Entra. В сложных структурах каталогов область синхронизации рекомендуется избежать влияния на операции масштабирования.
Задание максимального количества одновременных запросов для конфигурации Hive для сценария пикового использования
События автомасштабирования не меняют максимальное количество одновременных запросов конфигурации Hive в Ambari. Это означает, что интерактивная служба Hive Server 2 может обрабатывать только заданное количество одновременных запросов в любой момент времени, даже если число управляющих объектов интерактивного запроса масштабируется вверх и вниз на основе нагрузки и расписания. Общая рекомендация: задать эту конфигурацию для сценария пикового использования, чтобы избежать ручного вмешательства.
Однако при сбое перезапуска Hive Server 2 может возникнуть, если есть только несколько рабочих узлов, а значение для максимального количества одновременных запросов настроено слишком высоко. Минимальное количество рабочих узлов должно быть таким, чтобы разместить заданное количестве Tez AMS (равно конфигурации максимального количества одновременных запросов).
Ограничения
Число управляющих программ Interactive Query
Если кластеры интерактивных запросов с поддержкой автомасштабирования, то событие автомасштабирования вверх и вниз также масштабируется до количества активных рабочих узлов. Изменение числа управляющих программ не сохраняется в конфигурации num_llap_nodes в Ambari. Если службы Hive перезапускаются вручную, число управляющих программ Interactive Query сбрасывается в соответствии с конфигурацией в Ambari.
Если служба Interactive Query перезапускается вручную, необходимо вручную изменить конфигурацию num_llap_node (число узлов, необходимых для запуска управляющей программы Interactive Query Hive) в разделе Advanced hive-interactive-env в соответствии с текущим числом активных рабочих узлов. Кластер Interactive Query поддерживает только автомасштабирование на основе расписания
Следующие шаги
Прочитайте рекомендации по масштабированию кластеров вручную здесь.