Использование средств Spark и Hive для Visual Studio Code
Узнайте, как использовать Apache Spark & Hive Tools для Visual Studio Code. Эти средства используются для создания и отправки пакетных заданий Hive, интерактивных запросов Apache Hive и сценариев PySpark для Apache Spark. Сначала мы покажем, как установить Spark & Hive Tools в Visual Studio Code. Затем мы рассмотрим, как отправлять задания в Spark & Hive Tools.
Spark & Hive Tools можно установить на платформах, поддерживаемых Visual Studio Code. Ниже приведены предварительные требования для разных платформ.
Необходимые компоненты
Для выполнения действий, описанных в этой статье, необходимо следующее:
- Кластер Azure HDInsight. Сведения о создании кластера см. в статье о начале работы с HDInsight. Или используйте кластер Spark и Hive, поддерживающий конечную точку Apache Livy.
- Visual Studio Code.
- Mono. Mono требуется только для Linux и macOS.
- Интерактивная среда PySpark для Visual Studio Code.
- Локальный каталог. В этой статье используется C:\HD\HDexample.
Установка Spark & Hive Tools
После выполнения предварительных требований можно установить Spark & Hive Tools для Visual Studio Code в соответствии с приведенными ниже инструкциями.
Откройте Visual Studio Code.
В строке меню выберите Вид>Расширения.
В поле поиска введите Spark & Hive.
Выберите Spark & Hive Tools в результатах поиска и щелкните Установить.
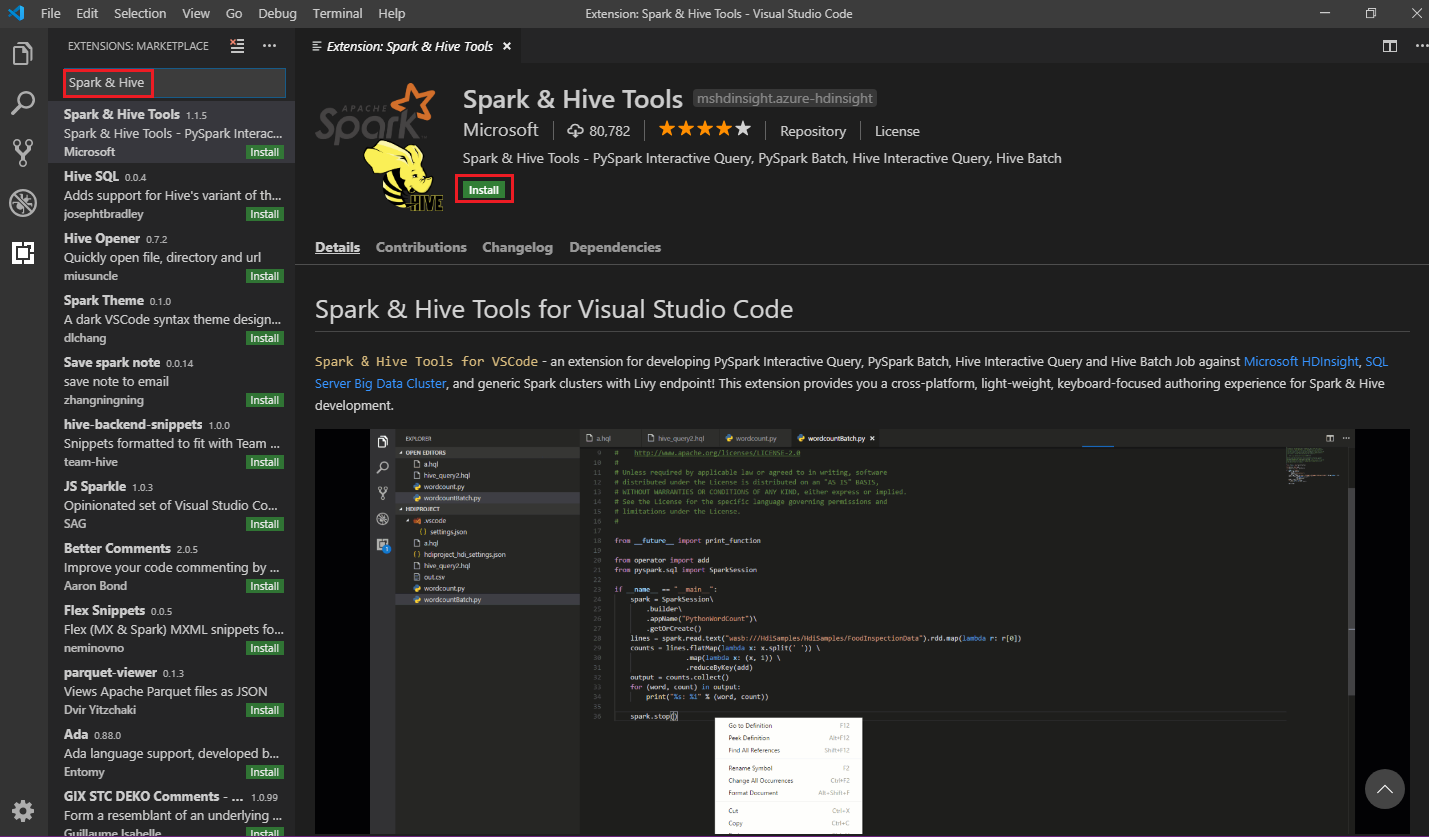
При необходимости выберите Перезагрузить.
Открытие рабочей папки
Чтобы открыть рабочую папку и создать файл в Visual Studio Code, выполните следующие действия.
В строке меню выберите Файл>Открыть папку...>C:\HD\HDexample, а затем нажмите кнопку Выбрать папку. Папка отображается в представлении проводника слева.
В интерфейсе проводника выберите папку HDexample, а затем — значок Создать файл рядом с рабочей папкой:
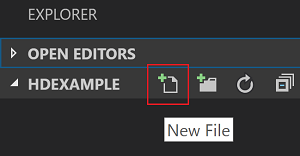
Назовите этот новый файл, используя расширение
.hql(запросы Hive) или.py(сценарий Spark). В этом примере используется файл HelloWorld.hql.
Настройка среды Azure
Если вы пользователь национального облака, выполните следующие действия, чтобы сначала настроить среду Azure, а затем используйте команду Azure: Sign In, чтобы войти в Azure.
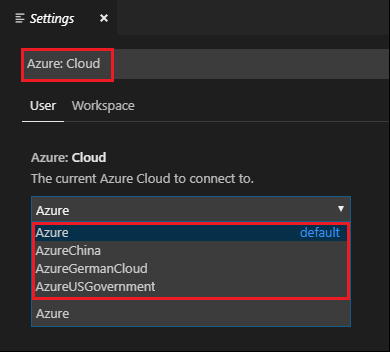
Выберите Файл>Настройки>Параметры.
Выполните поиск по следующей строке: Azure: Cloud.
Выберите национальное облако в списке:
Подключение к учетной записи Azure
Прежде чем отправлять скрипты в кластеры из Visual Studio Code, пользователь может войти в подписку Azure или связать кластер HDInsight. Для подключения к кластеру HDInsight используйте имя пользователя/пароль или учетные данные, присоединенные к домену, для кластера ESP. Для подключения к Azure выполните следующие действия.
В строке меню перейдите в меню "Просмотр>палитры команд..." и введите Azure: войдите:
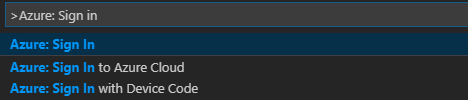
Следуйте инструкциям по входу, чтобы войти в Azure. После подключения имя учетной записи Azure будет отображаться в строке состояния внизу окна Visual Studio Code.
Связывание кластера
Связывание: Azure HDInsight
Вы можете связать обычный кластер с помощью управляемого имени пользователя Apache Ambari, а защищенный кластер Hadoop с пакетом безопасности Enterprise — с помощью имени пользователя домена (например, user1@contoso.com).
В строке меню выберите Вид>Палитра команд... и введите Spark/Hive: связать кластер.

Выберите связанный тип кластера Azure HDInsight.
Введите URL-адрес кластера HDInsight.
Введите имя пользователя Ambari; значение по умолчанию — admin.
Введите пароль Ambari.
Выберите тип кластера.
Задайте отображаемое имя кластера (необязательно).
Просмотрите представление OUTPUT для проверки.
Примечание.
Если кластер зарегистрирован в подписке Azure и связан, используется имя пользователя и пароль для связывания.
Связь: общая конечная точка Generic Livy
В строке меню выберите Вид>Палитра команд... и введите Spark/Hive: связать кластер.
Выберите связанный тип кластера Generic Livy Endpoint (Общая конечная точка Livy).
Введите универсальную конечную точку Livy. Например: http://10.172.41.42:18080.
Выберите тип авторизации Базовый или Нет. Выберите Базовый:
Введите имя пользователя Ambari; значение по умолчанию — admin.
Введите пароль Ambari.
Просмотрите представление OUTPUT для проверки.
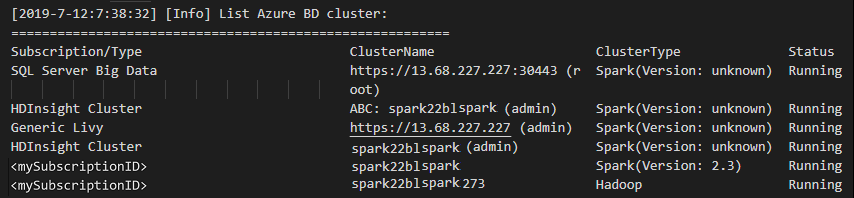
список кластеров
В строке меню выберите Вид>Палитра команд... и введите Spark/Hive: добавить кластер в список.
Выберите подписку, которую хотите использовать.
Просмотрите представление OUTPUT. В этом представлении отображается связанный кластер (или кластеры) и все кластеры в подписке Azure.
Настройка кластера по умолчанию
Повторно откройте папку HDexample, которая упоминалась ранее, если она была закрыта.
Выберите файл HelloWorld.hql, созданный ранее. Он откроется в редакторе скриптов.
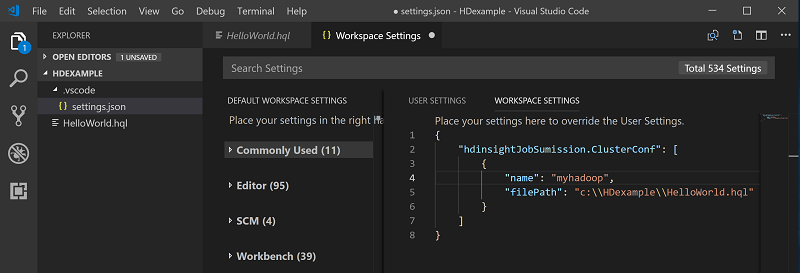
Щелкните редактор скриптов правой кнопкой мыши и выберите Spark / Hive: задать кластер по умолчанию.
Подключитесь к учетной записи Azure или привяжите кластер, если вы еще этого не сделали.
Выберите кластер в качестве используемого по умолчанию для текущего файла скрипта. Средства автоматически обновляют файл конфигурации .VSCode\settings.json.
Отправка интерактивных запросов Hive и пакетных сценариев Hive
Средства Spark и Hive для Visual Studio Code позволяют отправлять интерактивные запросы Hive и пакетные сценарии Hive в кластеры.
Повторно откройте папку HDexample, которая упоминалась ранее, если она была закрыта.
Выберите файл HelloWorld.hql, созданный ранее. Он откроется в редакторе скриптов.
Скопируйте следующий код и вставьте его в файл Hive, а затем сохраните файл.
SELECT * FROM hivesampletable;Подключитесь к учетной записи Azure или привяжите кластер, если вы еще этого не сделали.
Щелкните правой кнопкой мыши окно редактора сценариев и выберите Hive Interactive (Интерактивный запрос Hive), чтобы отправить запрос, или воспользуйтесь сочетанием клавиш Ctrl+Alt+I. Выберите Hive: пакет, чтобы отправить сценарий, или используйте сочетание клавиш Ctrl+Alt+H.
Выберите кластер, если вы не указали кластер по умолчанию. Эти средства также позволяют отправить блок кода вместо целого файла скрипта с помощью контекстного меню. Через несколько секунд на новой вкладке появятся результаты запроса.
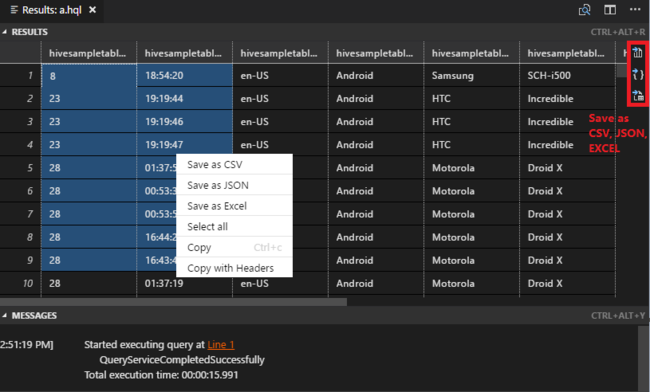
Область результатов: вы можете сохранить все результаты в виде файла CSV, JSON или Excel по локальному пути или просто выбрать несколько строк.
Область сообщений: выбрав номер строки, вы можете перейти к первой строке выполняемого скрипта.
Отправка интерактивных запросов PySpark
Предварительные требования для интерактивного использования Pyspark
Обратите внимание, что версия расширения Jupyter (ms-jupyter): версия 2022.1.1001614873 и версия расширения Python (ms-python): v2021.12.1559732655, Python 3.6.x и 3.7.x требуются для интерактивных запросов PySpark в HDInsight.
Пользователи могут работать с PySpark в интерактивном режиме, как описано ниже.
Использование интерактивной команды PySpark в файле PY
Чтобы отправить запросы с помощью интерактивной команды PySpark, выполните следующие действия.
Повторно откройте папку HDexample, которая упоминалась ранее, если она была закрыта.
Создайте новый файл HelloWorld.py, выполнив приведенные выше инструкции.
Скопируйте и вставьте в файл скрипта следующий код:
from operator import add from pyspark.sql import SparkSession spark = SparkSession.builder \ .appName('hdisample') \ .getOrCreate() lines = spark.read.text("/HdiSamples/HdiSamples/FoodInspectionData/README").rdd.map(lambda r: r[0]) counters = lines.flatMap(lambda x: x.split(' ')) \ .map(lambda x: (x, 1)) \ .reduceByKey(add) coll = counters.collect() sortedCollection = sorted(coll, key = lambda r: r[1], reverse = True) for i in range(0, 5): print(sortedCollection[i])В правом нижнем углу окна появится запрос на установку ядра PySpark или Synapse Pyspark. Можно нажать кнопку Установить, чтобы перейти к установке PySpark или Synapse Pyspark, или Пропустить, чтобы пропустить этот шаг.
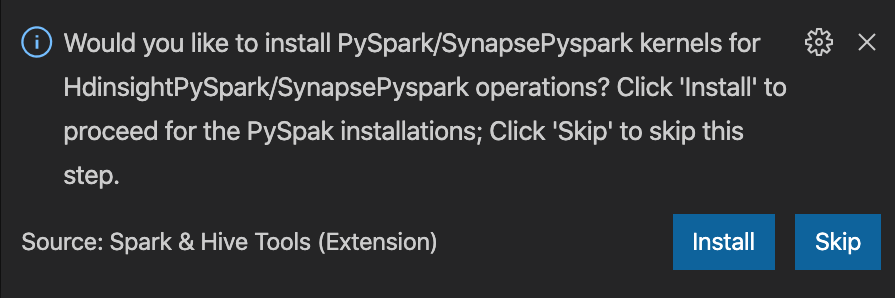
Если вы хотите установить его позже, последовательно выберите Файл>Настройки>Параметры, а затем снимите флажок Hdinsight: Enable Skip PySpark Installation (Разрешить пропуск установки PySpark).
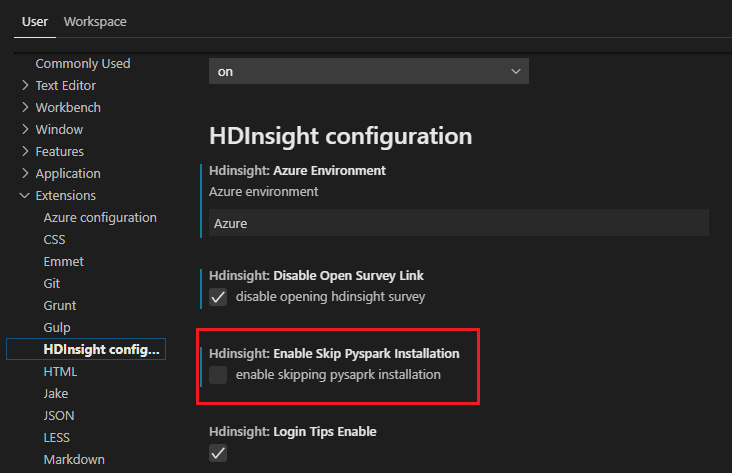
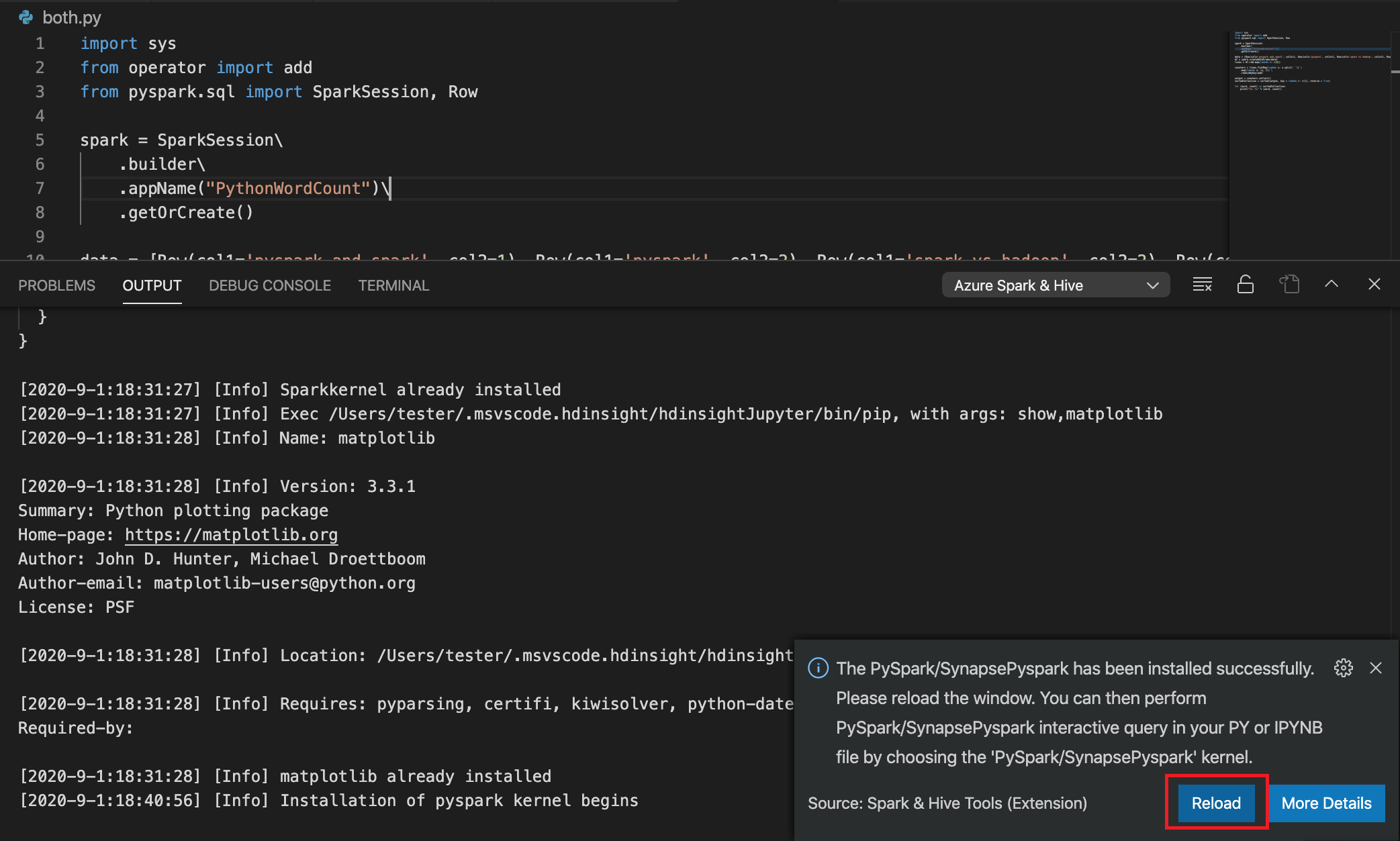
Если на шаге 4 установка PySpark или Synapse PySpark прошла успешно, в правом нижнем углу окна появится сообщение PySpark installed successfully (Расширение PySpark успешно установлено). Нажмите кнопку Перезагрузить, чтобы перезагрузить окно.
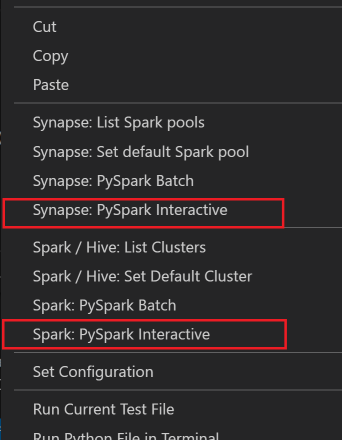
В строке меню перейдите в меню "Просмотреть>палитру команд" или используйте сочетание клавиш SHIFT+P и введите Python: выберите интерпретатор для запуска Jupyter Server.

Выберите параметр python ниже.

В строке меню перейдите в меню "Просмотреть>палитру команд" или используйте сочетание клавиш SHIFT+CTRL+P и введите "Разработчик: перезагрузить окно".

Подключитесь к учетной записи Azure или привяжите кластер, если вы еще этого не сделали.
Выберите весь код, щелкните редактор скриптов правой кнопкой мыши и выберите пункт Spark: PySpark Interactive/Synapse: PySpark Interactive (Spark: интерактивный запрос PySpark/Synapse: интерактивный запрос PySpark), чтобы отправить запрос.
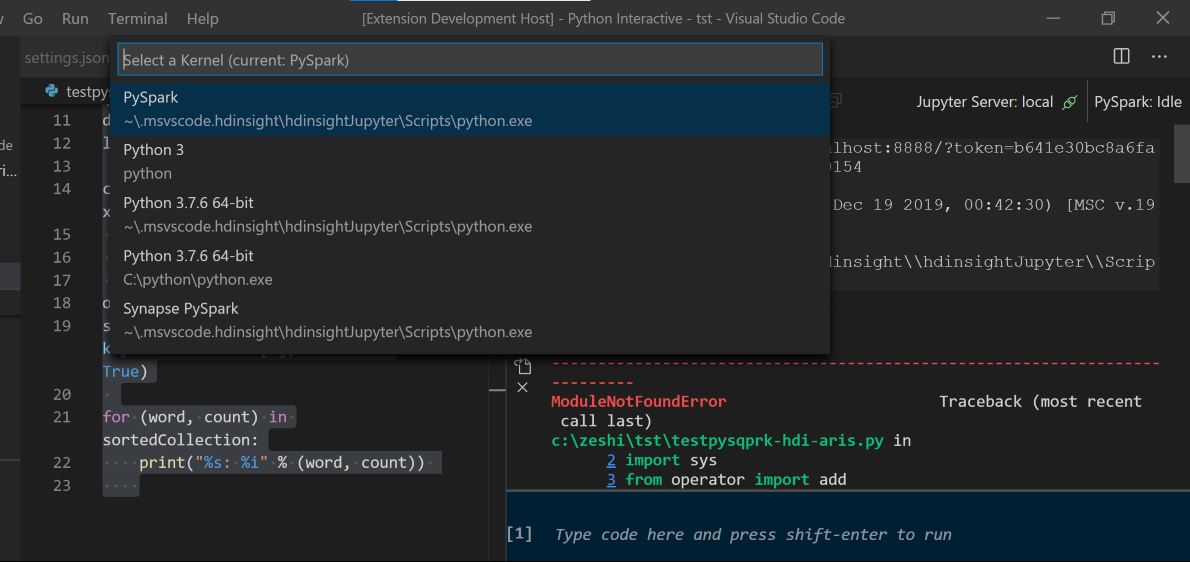
Выберите кластер, если вы не указали кластер по умолчанию. Через несколько секунд на новой вкладке отображаются результаты интерактивной команды Python. Щелкните PySpark, чтобы переключить ядро на PySpark/Synapse PySpark, и код будет выполнен успешно. Если вы хотите переключиться на ядро Synapse PySpark, рекомендуется отключить автоматическую настройку параметров на портале Azure. В противном случае для активации кластера и установки ядра synapse при первом использовании может потребоваться много времени. Эти средства также позволяют отправить блок кода вместо целого файла скрипта с помощью контекстного меню.
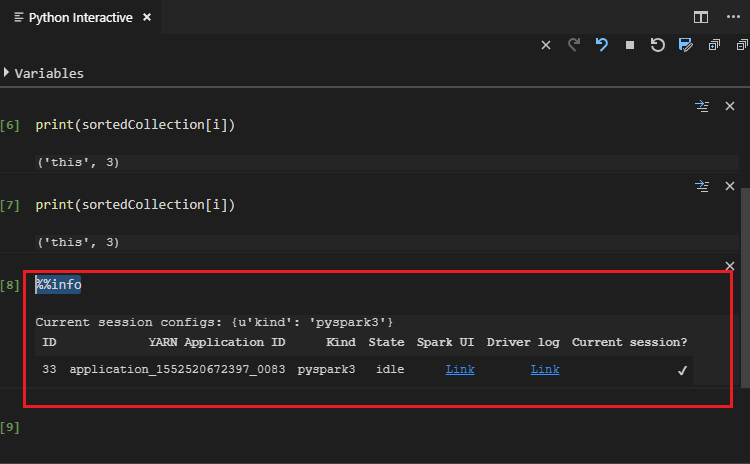
Введите %%info и нажмите клавиши Shift+Enter, чтобы посмотреть сведения о задании (необязательно):
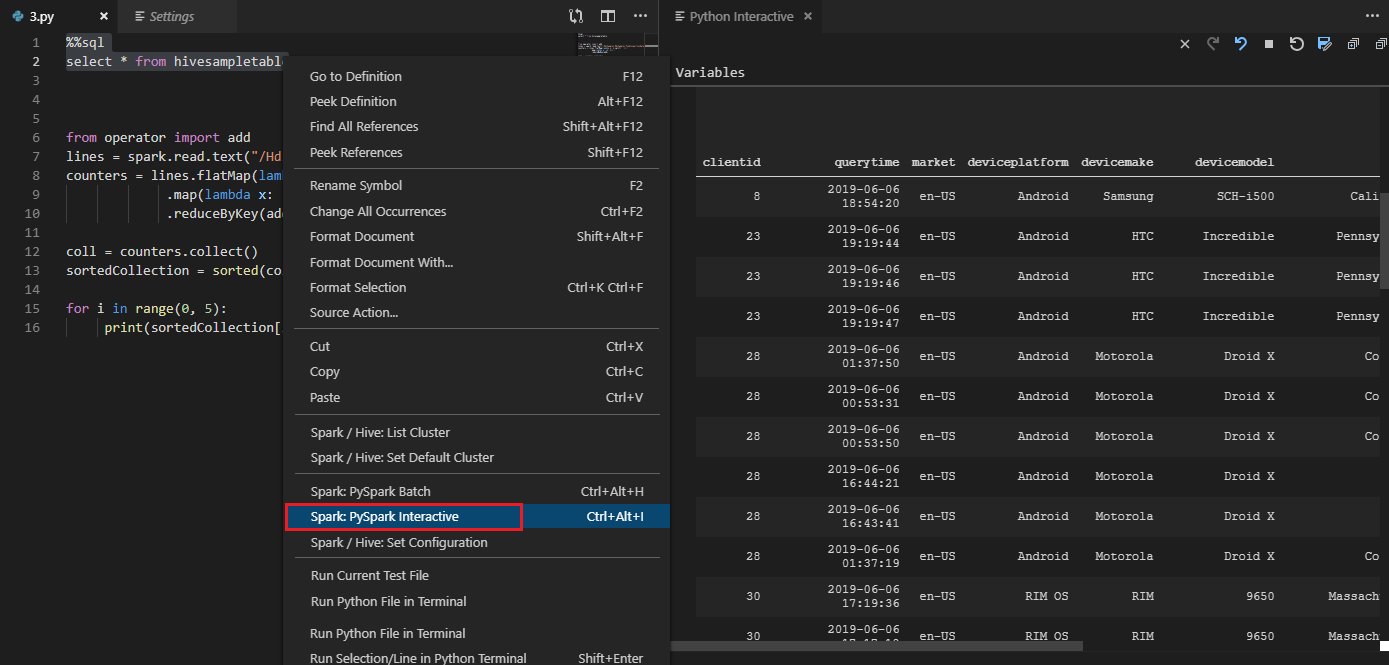
Средство также поддерживает запросы Spark SQL:
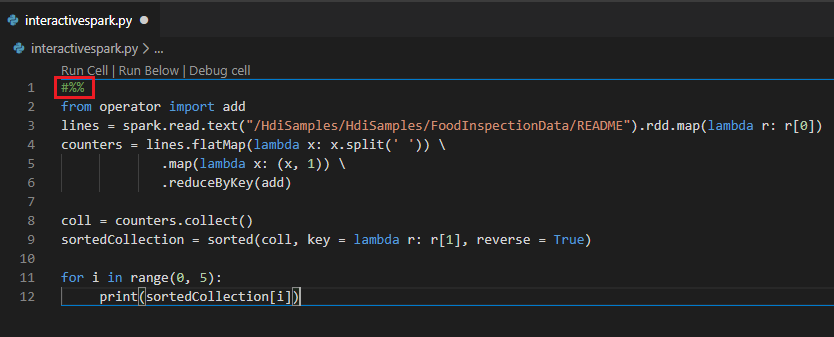
Выполнение интерактивного запроса в файле PY с помощью комментария #%%
Добавьте #%% перед кодом Py, чтобы работать, как с блокнотом.
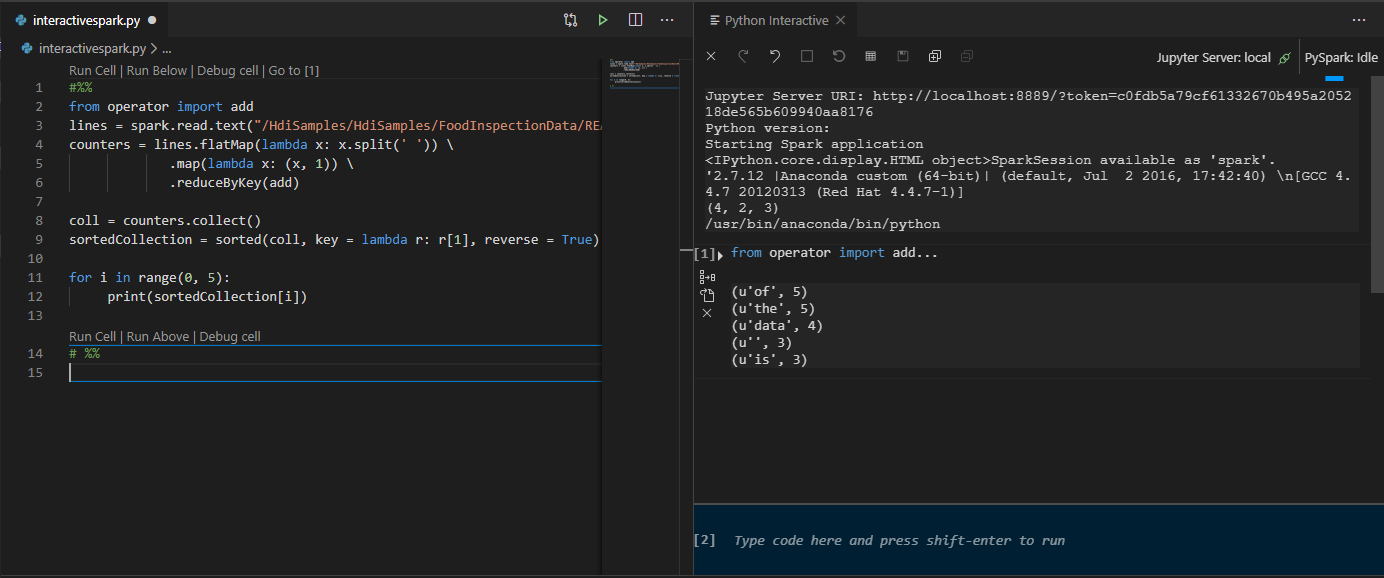
Щелкните Выполнить ячейку. Через несколько секунд на новой вкладке появятся результаты интерактивного окна Python. Щелкните PySpark, чтобы переключить ядро на PySpark/Synapse PySpark, затем щелкните Выполнить ячейку снова, и код будет успешно выполнен.
Использование поддержки IPYNB из расширения Python
Записную книжку Jupyter Notebook можно создать с помощью команды из палитры команд или путем создания нового IPYNB-файла в рабочей области. Дополнительные сведения см. в статье Работа с записными книжками Jupyter Notebook в Visual Studio Code.
Нажмите кнопку Выполнить ячейку, выполните инструкции на экране, чтобы задать стандартный пул Spark (настоятельно рекомендуется перед каждым открытием записной книжки устанавливать стандартный кластер или пул), а затем перезагрузите окно.
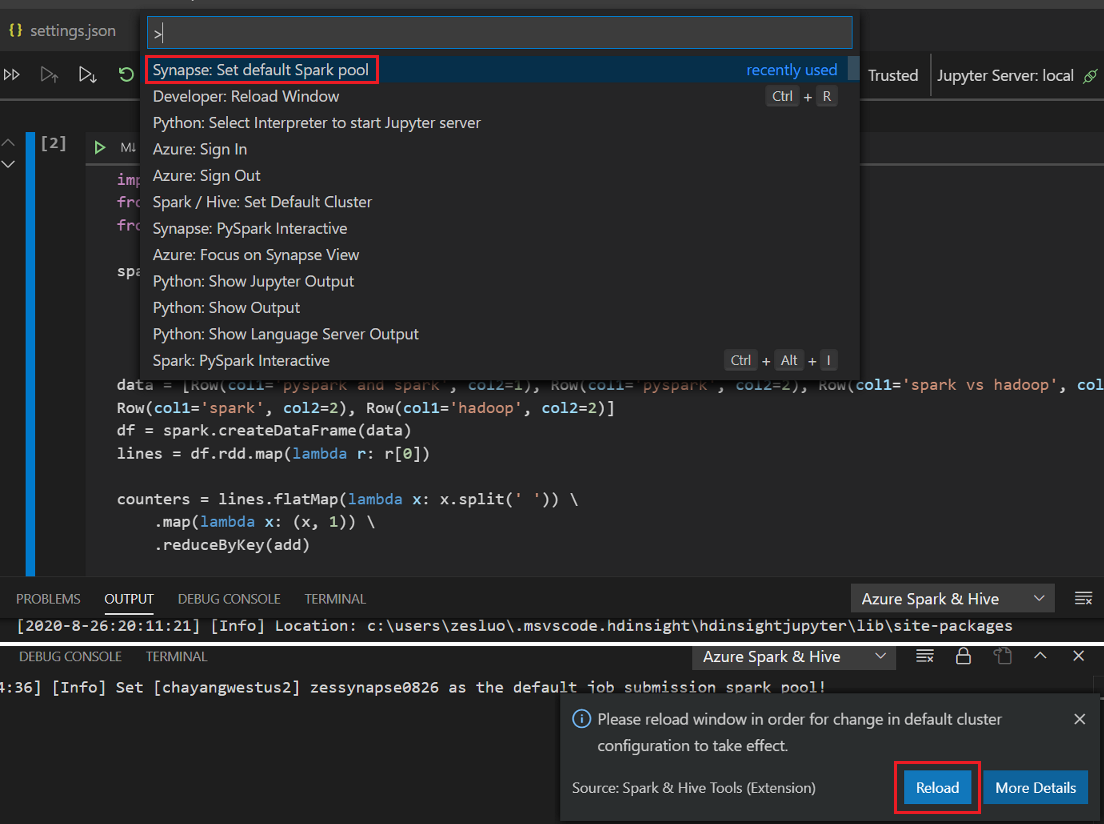
Щелкните PySpark, чтобы переключить ядро на PySpark / Synapse PySpark, а затем щелкните Выполнить ячейку, после чего отобразится результат.
Примечание.
Что касается ошибок установки Synapse Pyspark, так как ее зависимость больше не будет поддерживаться другой командой, эта возможность также не будет поддерживаться. Если вы пытаетесь использовать интерактивную среду Synapse Pyspark, переключитесь на использование Azure Synapse Analytics вместо нее. Это долгосрочное изменение.
Отправка пакетного задания PySpark
Повторно откройте папку HDexample, которая упоминалась ранее, если она была закрыта.
Создайте новый файл BatchFile.py, выполнив приведенные выше инструкции.
Скопируйте и вставьте в файл скрипта следующий код:
from __future__ import print_function import sys from operator import add from pyspark.sql import SparkSession if __name__ == "__main__": spark = SparkSession\ .builder\ .appName("PythonWordCount")\ .getOrCreate() lines = spark.read.text('/HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv').rdd.map(lambda r: r[0]) counts = lines.flatMap(lambda x: x.split(' '))\ .map(lambda x: (x, 1))\ .reduceByKey(add) output = counts.collect() for (word, count) in output: print("%s: %i" % (word, count)) spark.stop()Подключитесь к учетной записи Azure или привяжите кластер, если вы еще этого не сделали.
Щелкните правой кнопкой мыши по редактору скриптов, а затем выберите Spark: PySpark Batch или Synapse: PySpark Batch*.
Выберите кластер/пул spark, в который необходимо отправить задание PySpark.
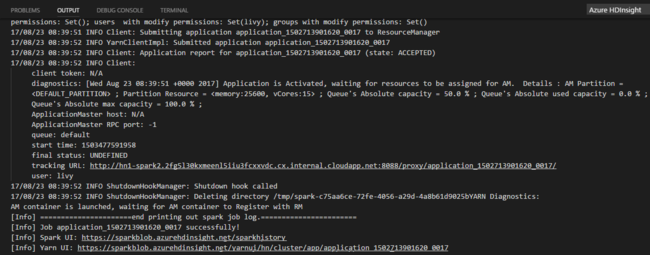
После отправки задания Python журналы отправки отображаются в окне вывода в Visual Studio Code. Также отображаются URL-адрес пользовательского интерфейса Spark и URL-адрес пользовательского интерфейса Yarn. Если пакетное задание отправляется в пул Apache Spark, также отображаются URL-адрес пользовательского интерфейса журнала Spark и URL-адрес пользовательского интерфейса приложения Spark Job. Вы можете открыть этот URL-адрес в браузере для отслеживания состояния задания.
Интеграция с брокером удостоверений HDInsight (HIB)
Подключение к кластеру HDInsight ESP с помощью брокера удостоверений (HIB)
Вы можете выполнить обычный вход в подписку Azure, чтобы подключиться к кластеру HDInsight ESP с брокером удостоверений (HIB). После входа вы увидите список кластеров в Azure Explorer. Указания см. в разделе Подключение к кластеру HDInsight.
Выполнение задания Hive или PySpark в кластере HDInsight ESP с брокером удостоверений (HIB)
Отправку задания в кластер HDInsight ESP с брокером удостоверений (HIB) можно выполнить обычным образом. Дополнительные инструкции см. в разделе Отправка интерактивных запросов Hive и пакетных сценариев Hive.
Чтобы выполнить интерактивное задание PySpark, отправку задания в кластер HDInsight ESP с брокером удостоверений (HIB) можно выполнить обычным образом. См. раздел «Отправка интерактивных запросов PySpark».
Чтобы выполнить пакетное задание PySpark, отправку задания в кластер HDInsight ESP с брокером удостоверений (HIB) можно выполнить обычным образом. Дополнительные инструкции см. в разделе Отправка пакетного задания PySpark.
Конфигурация Apache Livy
Поддерживается конфигурация Apache Livy. Его можно настроить в файле .VSCode\settings.json в папке рабочей области. Сейчас конфигурация Livy поддерживает только скрипт Python. Подробнее см. в файле Livy README.
Метод 1
- В строке меню выберите Файл>Настройки>Параметры.
- В поле Поиск параметров введите Отправка задания HDInsight: Livy Conf.
- Выберите Изменить в settings.json для соответствующего результата поиска.
Метод 2.
Отправьте файл и обратите внимание, что папка .vscode автоматически добавляется в рабочую папку. Чтобы найти конфигурацию Livy, выберите .vscode\settings.json.
Параметры проекта:
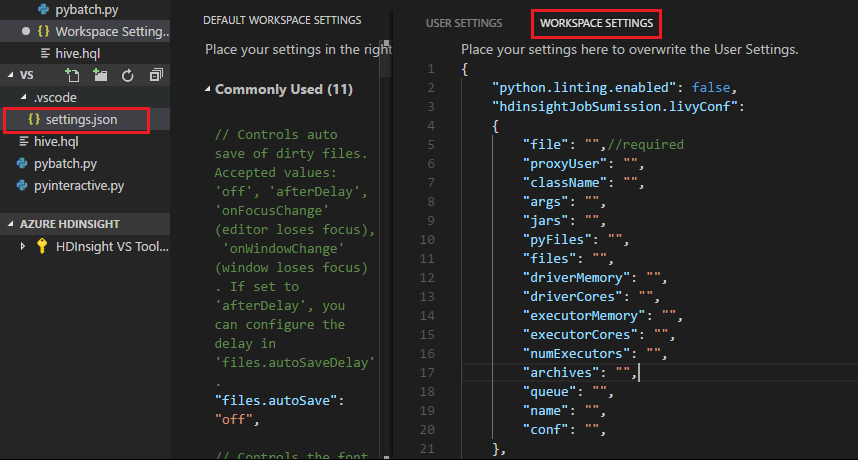
Примечание.
Для параметров driverMemory и executorMemory задайте значение и единицу измерения. Например: 1 ГБ или 1024 МБ.
Поддерживаемые конфигурации Livy:
Пакеты POST
Текст запроса
name описание type файл Файл, содержащий приложение для выполнения путь (обязательно) proxyUser Пользователь, олицетворяемый при выполнении задания Строка className Класс main приложения в Java/Spark Строка args Аргументы командной строки для приложения Список строк jars Файлы JAR для использования в этом сеансе Список строк pyFiles Файлы Python для использования в этом сеансе Список строк files Файлы для использования в этом сеансе Список строк driverMemory Объем памяти, используемый для процесса драйвера Строка driverCores Число ядер, используемых для процесса драйвера Int executorMemory Объем памяти, используемый для каждого процесса исполнителя Строка executorCores Число ядер, используемых для каждого исполнителя Int numExecutors Число исполнителей, которые должны быть запущены для этого сеанса Int archives Архивы для использования в этом сеансе Список строк очередь Имя очереди YARN для отправки Строка name Имя сеанса Строка conf Свойства конфигурации Spark Сопоставление key=val Текст ответа Созданный объект пакета.
name описание type Идентификатор ИД сеанса Int appId Идентификатор приложения для этого сеанса Строка appInfo Подробные сведения о приложении Сопоставление key=val Журнал Строки журнала Список строк state Состояние пакета Строка Примечание.
Назначенная конфигурация Livy отображается в области вывода при отправке скрипта.
Интеграция с Azure HDInsight в проводнике
Вы можете предварительно просмотреть таблицу Hive в кластерах напрямую с помощью Azure HDInsight Explorer.
Подключитесь к учетной записи Azure, если вы еще этого не сделали.
Щелкните значок Azure в крайнем левом столбце.
В левой области разверните AZURE: HDINSIGHT. В списке перечислены доступные подписки и кластеры.
Разверните кластер, чтобы просмотреть базу метаданных Hive и схему таблиц.
Щелкните правой кнопкой мыши таблицу Hive. Например: hivesampletable. Выберите Предварительный просмотр.
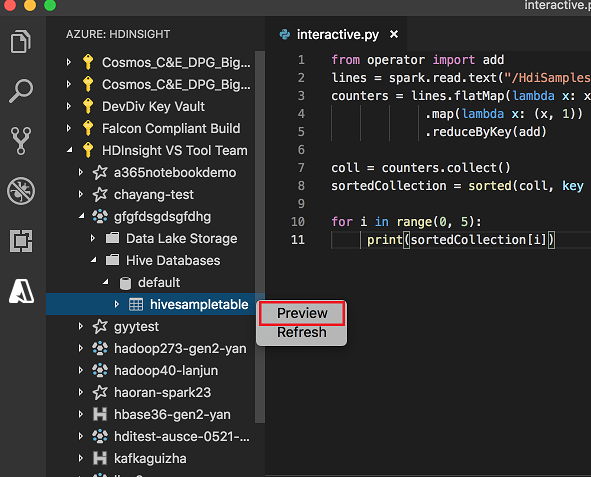
Откроется окно предварительного просмотра результатов:
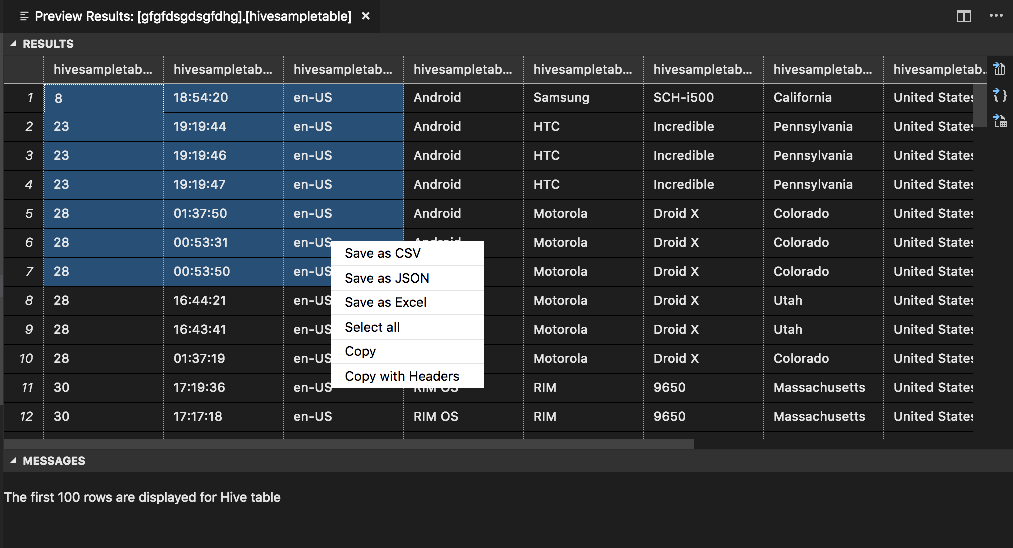
Область результатов
Вы можете сохранить все результаты в виде файла CSV, JSON или Excel по локальному пути или просто выбрать несколько строк.
Область сообщений
Если количество строк в таблице превышает 100, отображается следующее сообщение: "The first 100 rows are displayed for Hive table" (Первые 100 строк отображаются для таблицы Hive).
Если количество строк в таблице меньше или равно 100, отображается следующее сообщение: "60 rows are displayed for Hive table" (Для таблицы Hive отображается 60 строк).
Если в таблице нет содержимого, появится следующее сообщение: "
0 rows are displayed for Hive table.".Примечание.
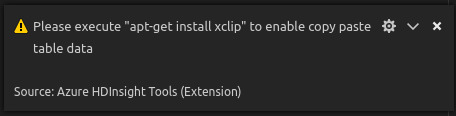
В Linux установите xclip, чтобы включить данные копирования таблицы.
Дополнительные функции
В Spark & Hive для Visual Studio Code поддерживаются следующие функции.
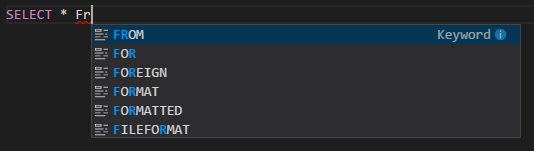
Автозавершение IntelliSense. Появляются предложения для ключевых слов, методов, переменных и других элементов программирования. Разные значки обозначают разные объекты:
Маркер ошибок IntelliSense. Языковая служба подчеркивает ошибки редактирования в скрипте Hive.
Выделение синтаксиса. Языковая служба использует разные цвета, чтобы было легче различать переменные, ключевые слова, тип данных, функции и другие элементы программирования:
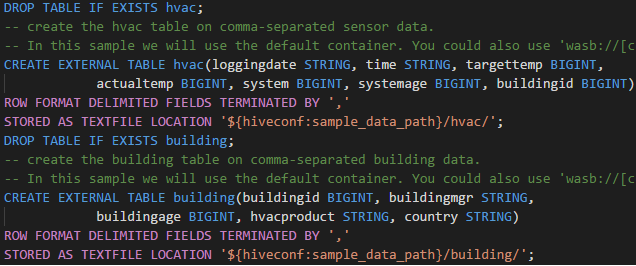
Роль только для чтения
Пользователи, которым назначена для кластера роль только для чтения, не могут отправлять задания в кластер HDInsight и не просматривать базу данных Hive. Обратитесь к администратору кластера, чтобы изменить роль на оператора кластера HDInsight на портале Azure. Если у вас есть действительные учетные данные Ambari, можно связать кластер вручную, следуя приведенным ниже инструкциям.
Просмотр кластера HDInsight
При выборе обозревателя Azure HDInsight для развертывания кластера HDInsight вам будет предложено связать кластер, если для него у вас есть роль только для чтения. Используйте следующий метод для связи с кластером с помощью учетных данных Ambari.
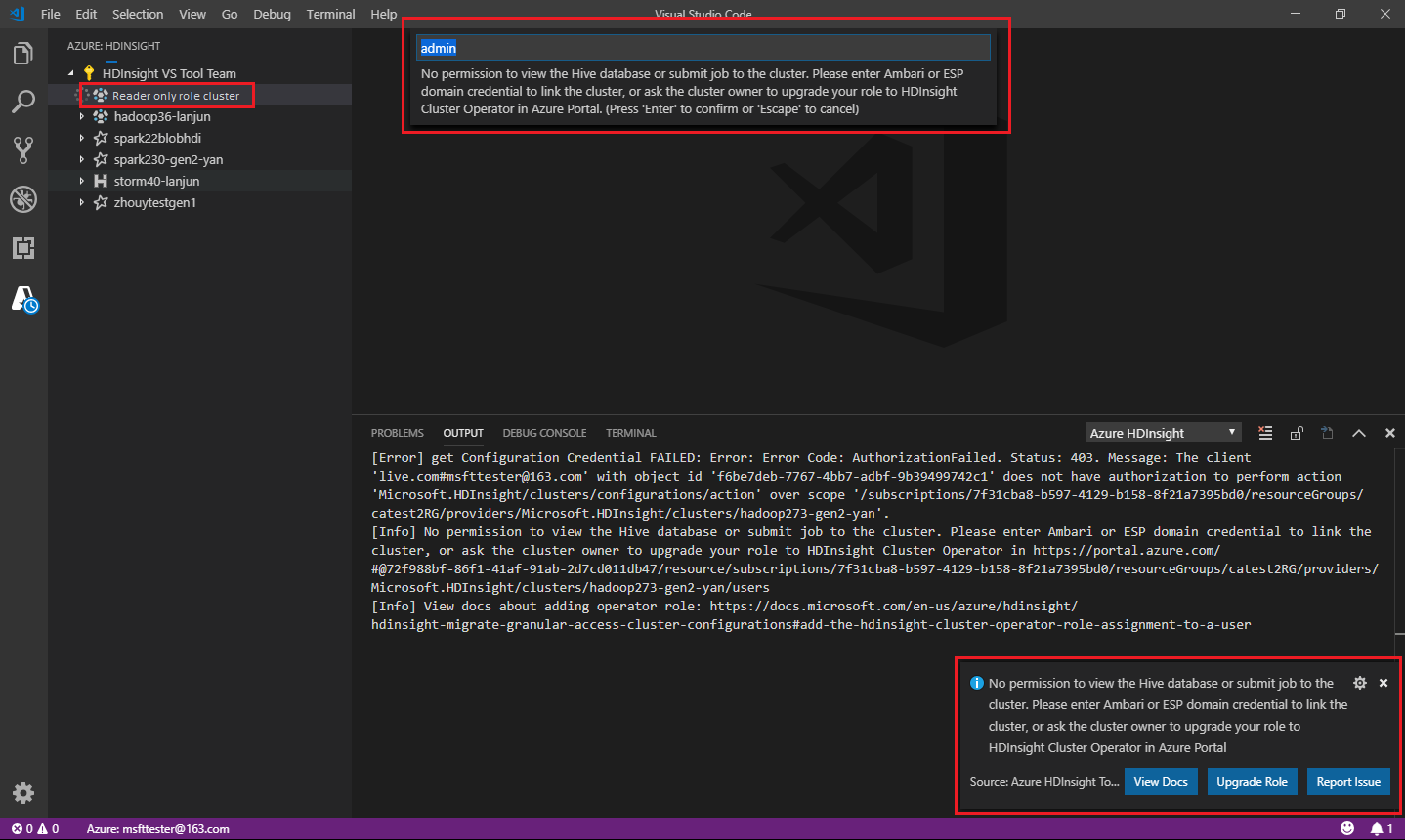
Отправка задания в кластер HDInsight
При отправке задания в кластер HDInsight вам будет предложено связать кластер, если ваша роль для него — только для чтения. Чтобы подключиться к кластеру с помощью учетных данных Ambari, следуйте инструкциям ниже.
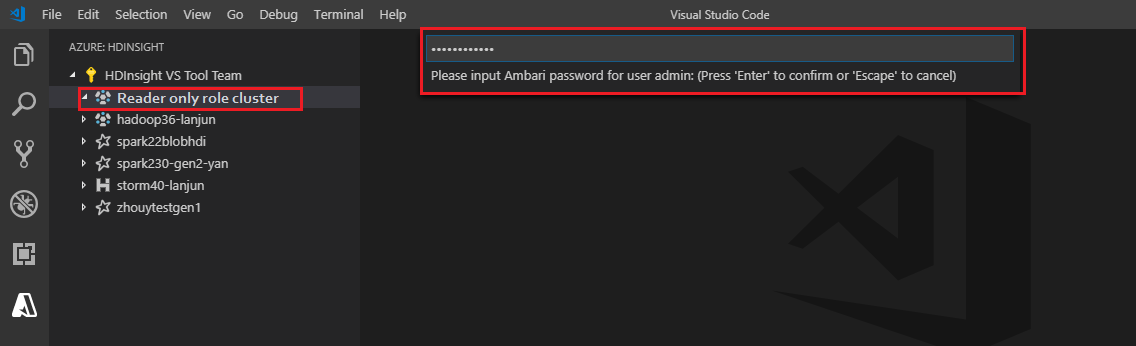
Подключение к кластеру
Введите допустимое имя пользователя Ambari.
Введите допустимый пароль.
Примечание.
Для проверки связанного кластера можно использовать
Spark / Hive: List Cluster:
Azure Data Lake Storage 2-го поколения
Просмотр учетной записи Data Lake Storage 2-го поколения
Выберите обозреватель Azure HDInsight, чтобы развернуть учетную запись Data Lake Storage 2-го поколения. Вам будет предложено ввести ключ доступа к хранилищу, если учетная запись Azure не имеет доступа на запись к хранилищу 2-го поколения. После проверки ключа доступа учетная запись Data Lake Storage 2-го поколения разворачивается автоматически.
Отправка заданий в кластер HDInsight с помощью Data Lake Storage 2-го поколения
Отправьте задание в кластер HDInsight с помощью Data Lake Storage 2-го поколения. Вам будет предложено ввести ключ доступа к хранилищу, если учетная запись Azure не имеет прав на запись в хранилище 2-го поколения. После проверки ключа доступа задание будет успешно отправлено.

Примечание.
Получить ключ доступа для учетной записи хранилища можно на портале Azure. См. сведения о том, как управлять ключами доступа к учетной записи хранения.
Удаление связи кластера
В строке меню выберите Вид>Палитра команд и введите Spark/Hive: отвязать кластер.
Выберите кластер для отмены связи.
Просмотрите представление OUTPUT для проверки.
Выйти
В строке меню выберите Вид>Палитра команд и введите Azure: выход.
Известные проблемы
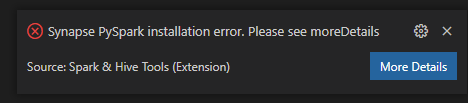
Ошибка установки Synapse PySpark.
Что касается ошибок установки Synapse Pyspark, так как ее зависимость больше не будет поддерживаться другой командой, эта возможность не будет поддерживаться. Если вы пытаетесь использовать интерактивную среду Synapse Pyspark, используйте Azure Synapse Analytics вместо нее. Это долгосрочное изменение.
Следующие шаги
Видео, на котором показано, как пользоваться Spark и Hive для Visual Studio Code, см. здесь.