Оптимизация запросов Apache в Hive в Azure HDInsight
В этой статье описываются некоторые популярные способы оптимизации производительности, которые можно использовать для повышения производительности запросов Apache Hive.
Выбор типа кластера
В Azure HDInsight можно выполнять запросы Apache Hive на нескольких разных типах кластеров.
Выберите подходящий тип кластера, чтобы оптимизировать производительность конкретной рабочей нагрузки.
- Тип кластера Интерактивные запросы дает оптимизацию для интерактивных запросов
ad hoc. - Выберите тип кластера Apache Hadoop, чтобы оптимизировать его для запросов Hive, используемых в качестве пакетной обработки.
- Типы кластеров Spark и HBase также могут выполнять запросы Hive и могут быть подходящими при выполнении этих рабочих нагрузок.
Дополнительные сведения о выполнении запросов Hive кластерами различных типов см. в статье Обзор Apache Hive и HiveQL в Azure HDInsight.
Горизонтальное увеличение масштаба рабочих узлов
Увеличение числа рабочих узлов в кластере HDInsight позволяет большему числу модулей сопоставления и сжатия работать параллельно. В HDInsight можно увеличить масштаб двумя способами.
Количество рабочих узлов можно указать при создании кластера с помощью портала Azure, Azure PowerShell или интерфейса командной строки. Дополнительные сведения см. в статье Создание кластеров Hadoop в HDInsight. На следующем снимке экрана показана рабочая конфигурация узла на портале Azure:
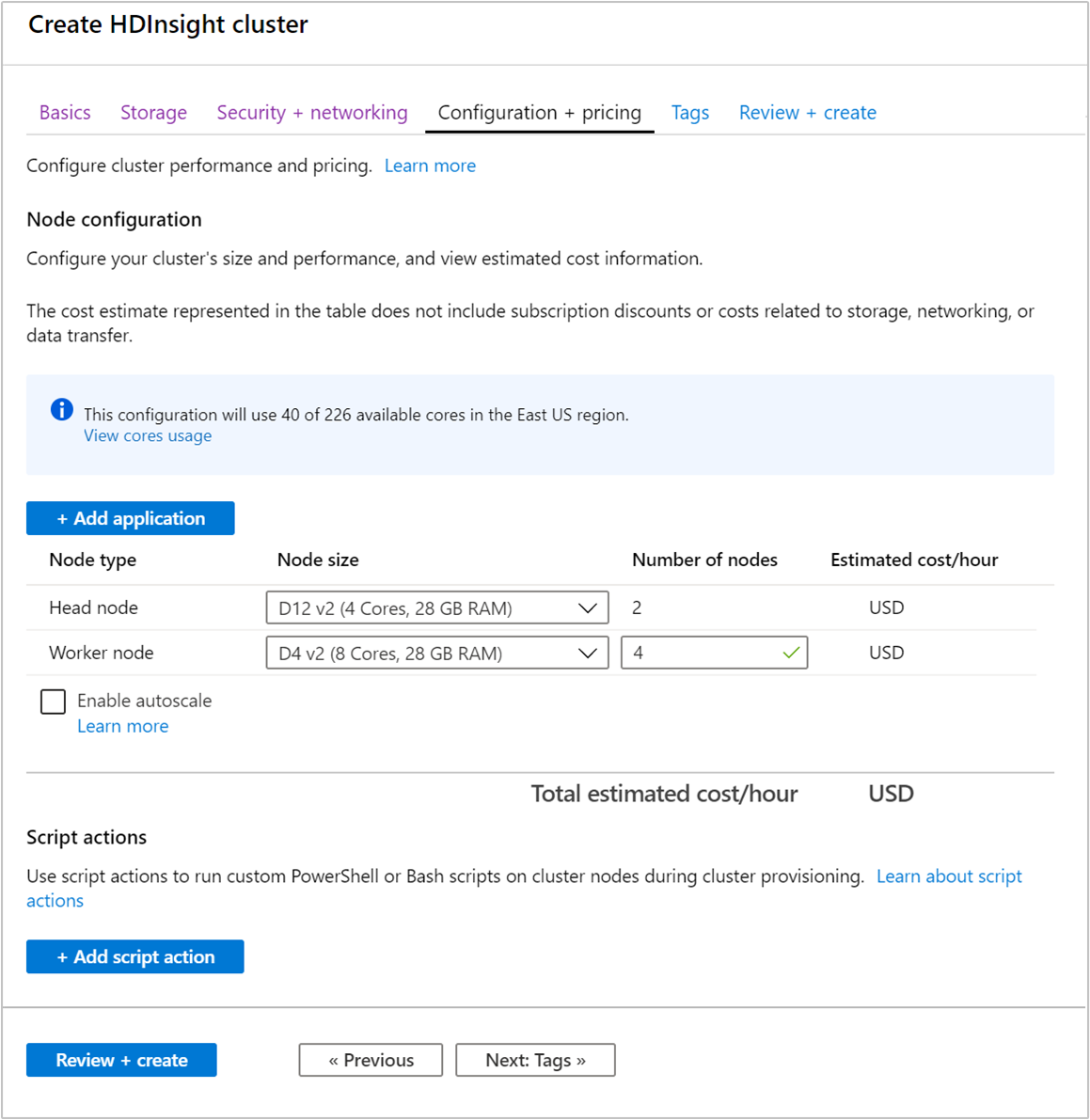
После создания кластера можно также изменить количество рабочих узлов, чтобы горизонтально увеличить масштаб кластера без необходимости его повторного создания.
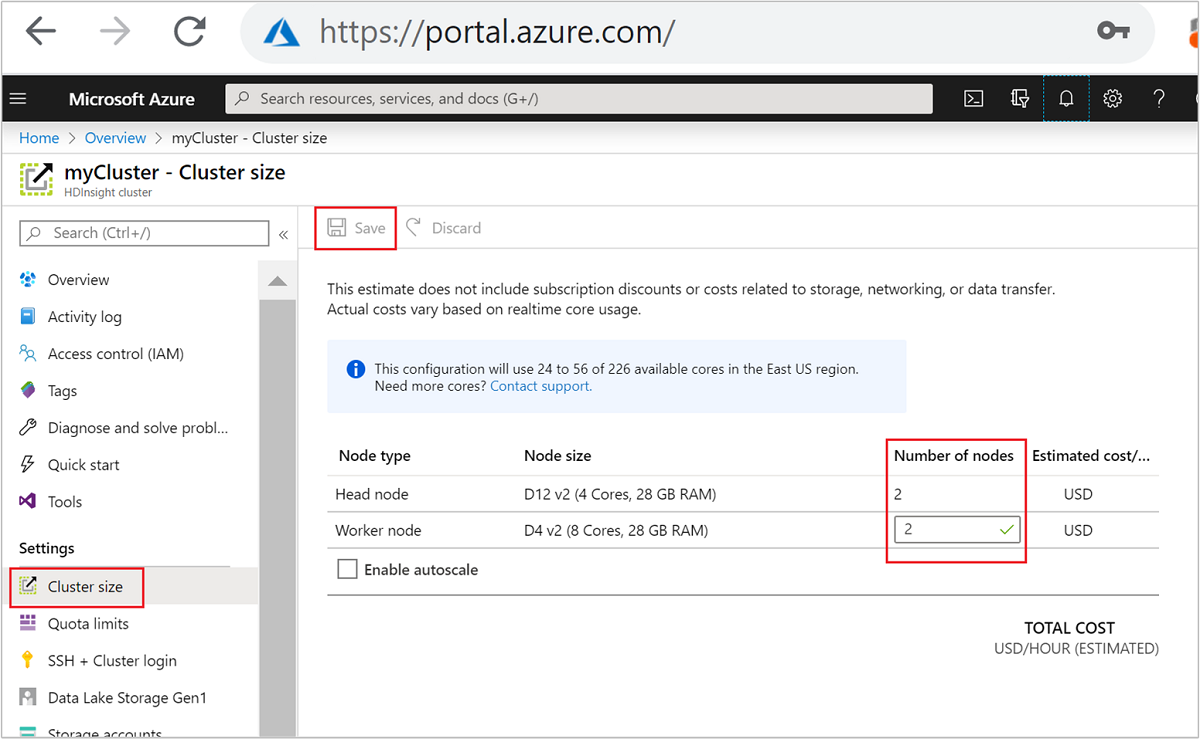
Дополнительные сведения о масштабировании HDInsight см. в статье Масштабирование кластеров HDInsight.
Использование Apache Tez вместо Map Reduce
Apache Tez — это механизм выполнения, альтернативный механизму MapReduce. При подготовке кластеров HDInsight под управлением Linux платформа Tez включена по умолчанию.
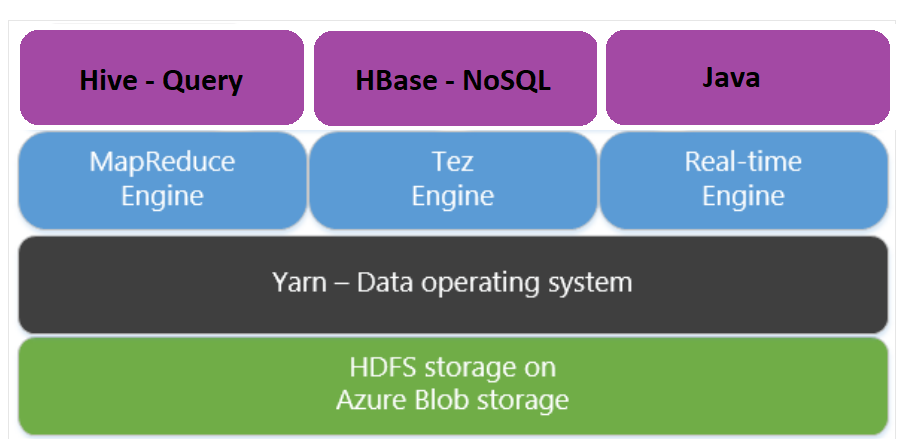
Tez работает быстрее, так как:
- Выполняет задания, представленные в виде направленных ациклических графов (DAG), как единое целое при работе с платформой MapReduce. DAG требует, чтобы набору модулей сопоставления соответствовал набор модулей сжатия. Это требование приводит к созданию множества заданий MapReduce для каждого запроса Hive. Tez не имеет такого ограничения и может обрабатывать сложные графы DAG как единое задание, сводя к минимуму затраты на создание новых заданий.
- Позволяет избежать ненужных операций записи. Чтобы обработать тот же запрос Hive в механизме MapReduce, используются несколько заданий. Выходные данные каждого задания MapReduce записываются в HDFS для промежуточных данных. Так как Tez использует минимальное количество заданий для каждого запроса Hive, вы сможете избежать ненужных операций записи.
- Сводит к минимуму задержки при загрузке. Платформа Tez способствует снижению задержки при запуске благодаря уменьшению количества модулей сопоставления, необходимых для запуска, а также путем оптимизации всего процесса.
- Повторно использует контейнеры. Всегда, насколько это возможно, Tez использует контейнеры повторно, снижая задержки на запуск контейнеров.
- Применяет методы непрерывной оптимизации. Традиционно оптимизация выполняется на этапе компиляции. Однако по мере поступления дополнительных сведений о входных данных появляется возможность улучшить оптимизацию уже на этапе работы. Tez применяет методы непрерывной оптимизации, что позволяет производить дальнейшую оптимизацию плана на этапе работы.
Дополнительные сведения об этих понятиях см. в документе об Apache Tez.
Вы можете выполнить любой запрос Hive, используя платформу Tez, активировав ее с помощью префикса запроса с использованием следующей команды набора:
set hive.execution.engine=tez;
Секционирование данных в Hive
Операции ввода-вывода — это основные ограничивающие факторы производительности при выполнении запросов Hive. Производительность можно повысить, если удастся уменьшить объем данных, которые необходимо считать. По умолчанию запросы Hive просматривают все таблицы Hive. Однако для запросов, которым требуется просмотреть только небольшой объем данных (например, для запросов с фильтрацией), это поведение создает излишнюю нагрузку. Секционирование данных Hive предоставляет запросам Hive доступ только к необходимому объему данных в таблицах Hive.
Секционирование данных в Hive реализуется путем реорганизации необработанных данных в новые каталоги. Каждой секции присвоен собственный каталог файлов. Пользователь определяет секционирование. Следующая схема иллюстрирует секционирование таблицы Hive по столбцу Год. Для каждого года создается новый каталог.
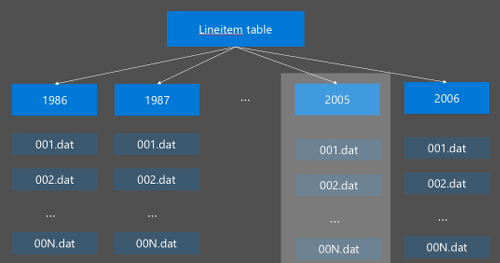
Некоторые рекомендации для выполнения секционирования:
- Секций не должно быть слишком мало. Секционирование по столбцам, содержащим небольшое количество значений, может привести к малому количеству секций. Например, секционирование по половой принадлежности создает только две секции ("мужская" и "женская"), а значит задержку не удастся сократить больше, чем вдвое.
- Секций не должно быть слишком много. С другой стороны, создание секции по столбцу с уникальным значением (например, содержащим идентификатор пользователя userid) приведет к появлению множества секций, что увеличит нагрузку на узел имен кластера из-за необходимости обрабатывать множество каталогов.
- Избегайте неравномерного распределения данных — выбирайте ключ секционирования рационально, таким образом, чтобы все секции были одинакового размера. Например, секционирование в столбце Штат может исказить распределение типов данных. Так как штат Калифорния имеет население почти 30x, что в Вермонте, размер секции потенциально сложен, и производительность может значительно отличаться.
Чтобы выполнить секционирование таблицы, используйте команду Секционирована по :
CREATE TABLE lineitem_part
(L_ORDERKEY INT, L_PARTKEY INT, L_SUPPKEY INT,L_LINENUMBER INT,
L_QUANTITY DOUBLE, L_EXTENDEDPRICE DOUBLE, L_DISCOUNT DOUBLE,
L_TAX DOUBLE, L_RETURNFLAG STRING, L_LINESTATUS STRING,
L_SHIPDATE_PS STRING, L_COMMITDATE STRING, L_RECEIPTDATE STRING,
L_SHIPINSTRUCT STRING, L_SHIPMODE STRING, L_COMMENT STRING)
PARTITIONED BY(L_SHIPDATE STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
STORED AS TEXTFILE;
Как только секционированная таблица будет создана, можно выполнить статическое или динамическое секционирование.
Статическое секционирование означает, что сегментированные данные уже находятся в соответствующих каталогах. С помощью статических секций вы добавляете секции Hive вручную, исходя из расположения каталога. Просмотрите пример в следующем фрагменте кода:
INSERT OVERWRITE TABLE lineitem_part PARTITION (L_SHIPDATE = '5/23/1996 12:00:00 AM') SELECT * FROM lineitem WHERE lineitem.L_SHIPDATE = '5/23/1996 12:00:00 AM' ALTER TABLE lineitem_part ADD PARTITION (L_SHIPDATE = '5/23/1996 12:00:00 AM') LOCATION 'wasb://sampledata@ignitedemo.blob.core.windows.net/partitions/5_23_1996/'Динамическое секционирование означает, что Hive автоматически создаст секции для вас. Так как таблица секционирования уже была создана из промежуточной таблицы, теперь достаточно только выполнить вставку данных в секционированную таблицу:
SET hive.exec.dynamic.partition = true; SET hive.exec.dynamic.partition.mode = nonstrict; INSERT INTO TABLE lineitem_part PARTITION (L_SHIPDATE) SELECT L_ORDERKEY as L_ORDERKEY, L_PARTKEY as L_PARTKEY, L_SUPPKEY as L_SUPPKEY, L_LINENUMBER as L_LINENUMBER, L_QUANTITY as L_QUANTITY, L_EXTENDEDPRICE as L_EXTENDEDPRICE, L_DISCOUNT as L_DISCOUNT, L_TAX as L_TAX, L_RETURNFLAG as L_RETURNFLAG, L_LINESTATUS as L_LINESTATUS, L_SHIPDATE as L_SHIPDATE_PS, L_COMMITDATE as L_COMMITDATE, L_RECEIPTDATE as L_RECEIPTDATE, L_SHIPINSTRUCT as L_SHIPINSTRUCT, L_SHIPMODE as L_SHIPMODE, L_COMMENT as L_COMMENT, L_SHIPDATE as L_SHIPDATE FROM lineitem;
Дополнительные сведения см. в разделе о секционированных таблицах.
Использование формата ORC-файлов
Hive поддерживает различные форматы. Например:
- Текст: формат файла по умолчанию работает с большинством сценариев.
- Avro: хорошо подходит для сценариев взаимодействия.
- ORC/Parquet: лучше всего подходит для повышения производительности.
Формат ORC (Optimized Row Columnar) — это очень эффективный способ хранения данных Hive. По сравнению с другими форматами ORC имеет следующие преимущества:
- поддержка сложных типов, в том числе даты и время и частично структурированные и сложные типы;
- обеспечивает показатель сжатия данных до 70 %;
- индексирует каждые 10 000 строк, что позволяет пропускать строки;
- обеспечивает существенное снижение времени выполнения запросов.
Чтобы активировать ORC формат, необходимо сначала создать таблицу командой Хранение в виде ORC:
CREATE TABLE lineitem_orc_part
(L_ORDERKEY INT, L_PARTKEY INT,L_SUPPKEY INT, L_LINENUMBER INT,
L_QUANTITY DOUBLE, L_EXTENDEDPRICE DOUBLE, L_DISCOUNT DOUBLE,
L_TAX DOUBLE, L_RETURNFLAG STRING, L_LINESTATUS STRING,
L_SHIPDATE_PS STRING, L_COMMITDATE STRING, L_RECEIPTDATE STRING,
L_SHIPINSTRUCT STRING, L_SHIPMODE STRING, L_COMMENT STRING)
PARTITIONED BY(L_SHIPDATE STRING)
STORED AS ORC;
Далее необходимо выполнить вставку данных в таблицу ORC из промежуточной таблицы. Например:
INSERT INTO TABLE lineitem_orc
SELECT L_ORDERKEY as L_ORDERKEY,
L_PARTKEY as L_PARTKEY ,
L_SUPPKEY as L_SUPPKEY,
L_LINENUMBER as L_LINENUMBER,
L_QUANTITY as L_QUANTITY,
L_EXTENDEDPRICE as L_EXTENDEDPRICE,
L_DISCOUNT as L_DISCOUNT,
L_TAX as L_TAX,
L_RETURNFLAG as L_RETURNFLAG,
L_LINESTATUS as L_LINESTATUS,
L_SHIPDATE as L_SHIPDATE,
L_COMMITDATE as L_COMMITDATE,
L_RECEIPTDATE as L_RECEIPTDATE,
L_SHIPINSTRUCT as L_SHIPINSTRUCT,
L_SHIPMODE as L_SHIPMODE,
L_COMMENT as L_COMMENT
FROM lineitem;
Вы можете прочесть подробнее о формате ORC на странице руководства по языку Apache Hive.
Векторизация
Векторизация позволяет Hive обрабатывать пакеты из 1024 строк одновременно вместо обработки каждой строки отдельно. Это означает, что простые операции будут выполняться быстрее благодаря меньшему объему внутреннего кода, необходимого для запуска.
Чтобы активировать функцию векторизации, создайте запрос Hive со следующими параметрами:
set hive.vectorized.execution.enabled = true;
Для получения дополнительных сведений обратитесь к разделу Выполнение векторизованного запроса.
Другие методы оптимизации
Существуют дополнительные методы оптимизации, которые также можно использовать, например:
- Группирование Hive — техника, которая позволяет сегментировать или объединять в кластеры большие наборы данных для оптимизации производительности запросов.
- Оптимизация объединений — это оптимизация выполнения запросов Hive с целью повышения эффективности объединений и сокращения действия пользователя. Для получения дополнительных сведений обратитесь к разделу Оптимизация объединений.
- Увеличение модулей сжатия.
Следующие шаги
В этой статье вы узнали некоторые распространенные методы оптимизации запросов Hive. Дополнительные сведения см. в следующих разделах:
Обратная связь
Ожидается в ближайшее время: в течение 2024 года мы постепенно откажемся от GitHub Issues как механизма обратной связи для контента и заменим его новой системой обратной связи. Дополнительные сведения см. в разделе https://aka.ms/ContentUserFeedback.
Отправить и просмотреть отзыв по