Мониторинг производительности кластера в Azure HDInsight
Мониторинг работоспособности и производительности кластера HDInsight важен для обеспечения оптимальной производительности и эффективного использования ресурсов. Мониторинг может также помочь вам обнаружить и устранить ошибки конфигурации кластера и проблемы с пользовательским кодом.
В следующих разделах описывается, как отслеживать и оптимизировать нагрузку на кластеры, очереди Apache Hadoop YARN и обнаруживать проблемы регулирования хранилища.
Мониторинг загрузки кластера
Кластеры Hadoop могут обеспечить наиболее оптимальную производительность, когда нагрузка на кластер равномерно распределена по всем узлам. Это позволяет избежать ограничения задач обработки из-за нехватки ресурсов ОЗУ, ЦП и дисков на отдельных узлах.
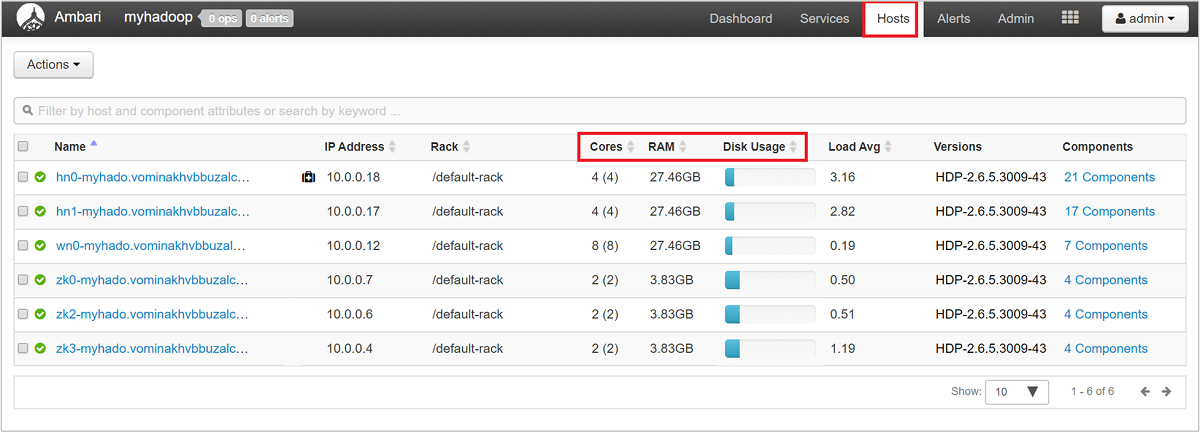
Чтобы получить общее представление об узлах кластера и их загрузке, войдите в Управление кластерами HDInsight с помощью веб-интерфейса Ambari, а затем выберите вкладку Узлы. Для узлов в списке указаны их полные доменные имена. Состояние каждого узла обозначается цветным индикатором работоспособности.
| Color | Description |
|---|---|
| Красный | Как минимум один ведущий компонент на узле не работает. Наведите указатель мыши, чтобы просмотреть подсказку с перечнем затронутых компонентов. |
| Orange | Как минимум один ведомый компонент на узле не работает. Наведите указатель мыши, чтобы просмотреть подсказку с перечнем затронутых компонентов. |
| Желтый | Сервер Ambari не получал пульс от узла более 3 минут. |
| Зеленый | Нормальное рабочее состояние. |
Вы также увидите столбцы с указанием количества ядер и объема ОЗУ для каждого узла, сведений об использовании дисков и средней загрузки.
Выберите любое имя узла, чтобы подробное изучить компоненты, работающие на этом узле, и их метрики. Метрики отображаются в виде доступной для выбора временной шкалы использования ЦП, загрузки, использование диска, использование памяти, использование сети и числа процессов.
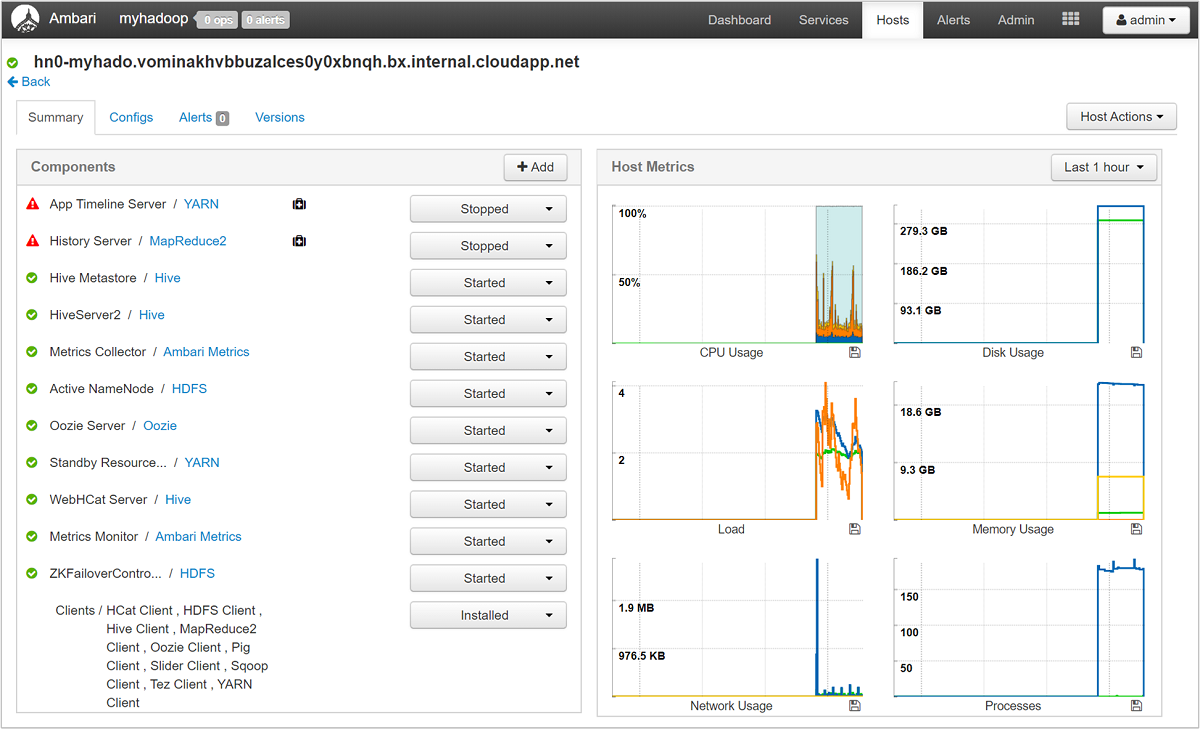
Подробные сведения о настройке оповещений и просмотре метрик см. в статье Управление кластерами HDInsight с помощью веб-интерфейса Ambari.
Конфигурация очереди YARN
На распределенной платформе Hadoop выполняются различные службы. YARN (Yet Another Resource Negotiator, что переводится как "Еще одна система управления ресурсами") координирует эти службы, выделяет ресурсы кластера для обеспечения равномерного распределения нагрузки по кластеру.
YARN разделяет две обязанности JobTracker: управление ресурсами и планирование и мониторинг заданий — между двумя управляющими программами: глобальным приложением Resource Manager и приложением ApplicationMaster для каждого приложения (AM).
Resource Manager является только планировщиком и единолично управляет доступными ресурсами для всех конкурирующих приложений. Resource Manager обеспечивает постоянное использование всех ресурсов, оптимизируя различные константы, такие как соглашения об уровне обслуживания, гарантии емкости и т. д. ApplicationMaster согласовывает ресурсы, полученные от Resource Manager, и работает с экземплярами NodeManager для выполнения и отслеживания контейнеров и их потребления ресурсов.
Если несколько клиентов совместно используют большой кластер, то они конкурируют за его ресурсы. CapacityScheduler является подключаемым планировщиком, который упрощает предоставление общего доступа к ресурсам, ставя запросы в очередь. Кроме того, CapacityScheduler поддерживает иерархические очереди, чтобы обеспечить совместное использование ресурсов подочередями организации прежде, чем очереди других приложений смогут использовать свободные ресурсы.
YARN позволяет выделять ресурсы для этих очередей, а также показывает, назначены ли все доступные ресурсы. Чтобы просмотреть сведения об очередях, войдите в пользовательский веб-интерфейс Ambari и в верхнем меню щелкните YARN Queue Manager (Диспетчер очередей YARN).
В левой части страницы "YARN Queue Manager" (Диспетчер очередей YARN) отображается список очередей, а также назначенный каждой из них процент емкости.
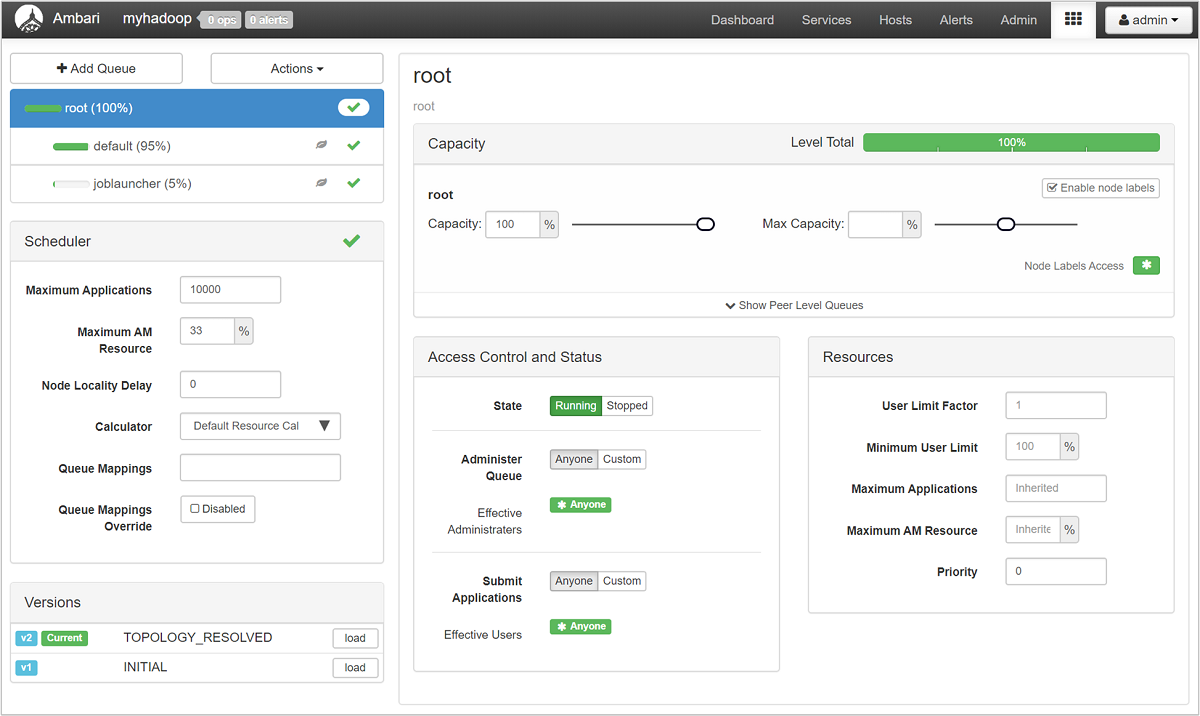
Чтобы более подробно изучить очереди, на панели мониторинга Ambari из списка слева выберите службу YARN. Затем из раскрывающегося меню Quick Links (Быстрые ссылки) выберите Resource Manager UI (Пользовательский интерфейс Resource Manager) под активным узлом.
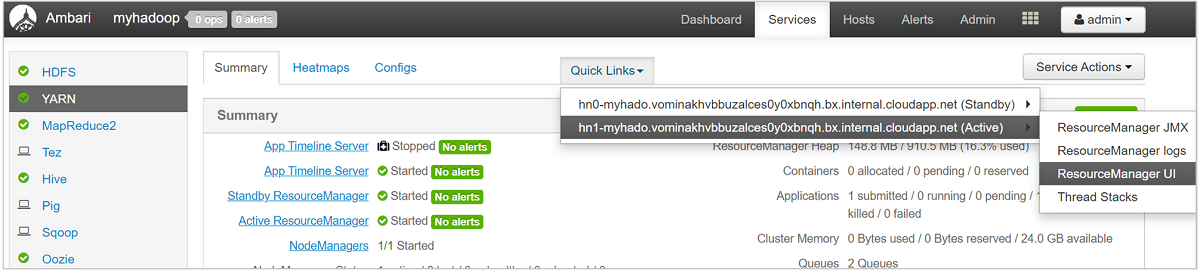
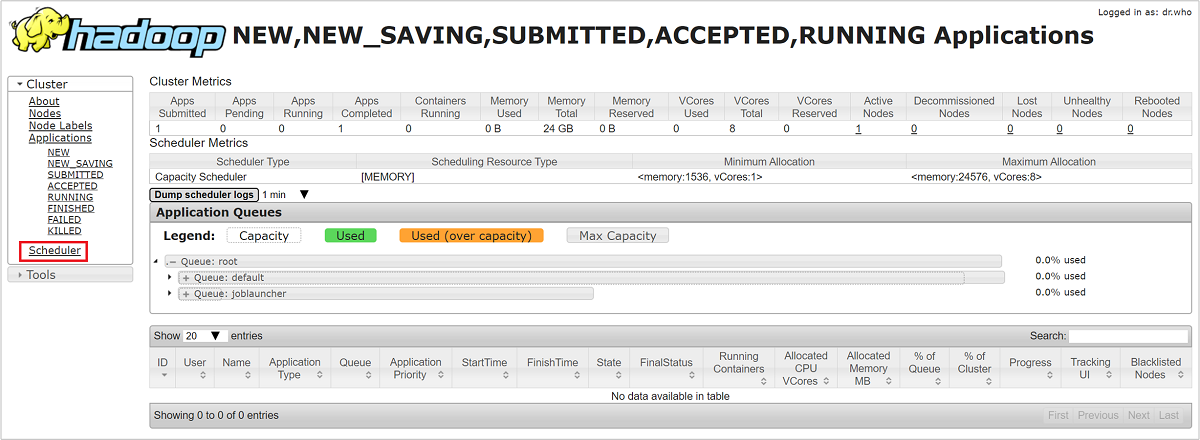
В пользовательском интерфейсе Resource Manager в меню слева выберите Scheduler (Планировщик). Список очередей отобразится в разделе Application Queues (Очереди приложений). Здесь можно просмотреть емкость, используемую для каждой из очередей, узнать, насколько хорошо задания распределены между ними, и имеются ли задания, которым не хватает ресурсов.
Регулирование хранилища
Узкое место производительности кластера может возникнуть на уровне хранилища. Узкое место такого типа чаще всего возникает из-за блокировки операций ввода-вывода, что происходит, когда запущенные задачи отправляют больше операций ввода-вывода, чем может обработать служба хранилища. Эта блокировка приводит к образованию очереди запросов на ввод-вывод, ожидающих обработки после завершения обработки текущих операций ввода-вывода. Блокировка происходит из-за регулирования хранилища, что обусловлено не физическими ограничениями, а, скорее, ограничениями службы хранилища, установленными в соответствии с соглашением об уровне обслуживания. Это ограничение гарантирует невозможность монополизации службы каким-ибо одним клиентом. Соглашение об уровне обслуживания ограничивает число операций ввода-вывода в секунду (IOPS) для службы хранилища Azure. Дополнительные сведения см. в разделе Целевые показатели масштабируемости и производительности для стандартных учетных записей хранения.
Если вы используете службу хранилища Azure, то сведения об отслеживании проблем, связанных с хранилищем, включая сведения о регулировании, можно получить в разделе Мониторинг, диагностика и устранение неисправностей службы хранилища Microsoft Azure.
Если резервным хранилищем кластера является Azure Data Lake Storage (ADLS), то регулирование, вероятнее всего, возникает из-за ограничения пропускной способности. В данном случае регулирование можно заметить, отслеживая ошибки регулирования в журналах задач. Сведения об использовании ADLS приведены в разделе о регулировании для соответствующей службы в следующих статьях:
- Рекомендации по настройке производительности для Hive в HDInsight и Azure Data Lake Storage
- Рекомендации по настройке производительности для MapReduce в HDInsight и Azure Data Lake Storage
Устранение низкой производительности узла
В некоторых случаях снижение скорости может возникать из-за нехватки дискового пространства в кластере. Изучите следующие шаги.
Используйте команду SSH для подключения к каждому из узлов.
Проверьте использование диска, выполнив одну из следующих команд:
df -h du -h --max-depth=1 / | sort -hПроверьте выходные данные и наличие больших файлов, например в папке
mntили других папках. Как правило, папкиusercacheиappcache(mnt/resource/hadoop/yarn/local/usercache/hive/appcache/) содержат файлы большого размера.Наличие больших файлов означает, что текущее задание приводит к увеличению файла или что проблема связана с неудачным завершением предыдущих заданий. Чтобы проверить, связано ли это поведение с текущим заданием, выполните следующую команду:
sudo du -h --max-depth=1 /mnt/resource/hadoop/yarn/local/usercache/hive/appcache/Если эта команда возвращает конкретное задание, попробуйте завершить это задание с помощью следующей команды:
yarn application -kill -applicationId <application_id>Замените
application_idна идентификатор приложения. Если конкретные задания не определены, перейдите к следующему шагу.После выполнения приведенной выше команды или при отсутствии определенных заданий удалите большие файлы, которые вы нашли, выполнив команду, подобную следующей:
rm -rf filecache usercache
Дополнительные сведения о проблемах с дисковым пространством см. в разделе Недостаточно места на диске.
Примечание.
Если у вас есть большие файлы, которые вы хотите сохранить, но их наличие вызывает нехватку места на диске, увеличьте масштаб кластера HDInsight и перезапустите службы. После выполнения этой процедуры подождите несколько минут. Скорее всего, нагрузка на хранилище снизится и восстановится нормальная производительность узла.
Следующие шаги
Перейдите по следующим ссылкам, чтобы получить дополнительные сведения об устранении неполадок и мониторинге кластеров: