Ввод в эксплуатацию конвейера аналитики данных
Конвейеры данных лежат в основе многих решений для анализа данных. Как очевидно из названия, конвейер данных принимает необработанные данные, очищает их и изменяет при необходимости их структуру, а затем стандартным образом выполняет вычисления или статистические функции, после чего сохраняет обработанные данные. Обработанные данные используются клиентами, отчетами или API-интерфейсами. Конвейер данных должен возвращать повторяемые результаты по расписанию или во время активации с помощью новых данных.
В этой статье описывается ввод в эксплуатацию конвейеров данных для обеспечения повторяемости результатов с помощью решения Oozie, работающего в кластерах HDInsight Hadoop. Из этого примера сценария вы узнаете о конвейере данных, с помощью которого выполняется подготовка и обработка данных временных рядов рейсов авиакомпании.
В сценарии ниже входящие данные представляют собой неструктурированный файл, содержащий пакет данных о рейсах за месяц. Эти данные о рейсах содержат сведения о пункте назначения и вылета, пройденном расстоянии между ними, времени прибытия и отправления и т. д. С помощью этого конвейера вы суммируете результат ежедневных вылетов, где для каждой авиалинии предусмотрена одна запись за один день со средним временем задержки при отправлении и прибытии (в минутах), а также общее число километров, пройденных за день.
| YEAR | MONTH | DAY_OF_MONTH | CARRIER | AVG_DEP_DELAY | AVG_ARR_DELAY | TOTAL_DISTANCE |
|---|---|---|---|---|---|---|
| 2017 | 1 | 3 | AA | 10,142229 | 7,862926 | 2 644 539 |
| 2017 | 1 | 3 | AS | 9,435449 | 5,482143 | 572 289 |
| 2017 | 1 | 3 | DL | 6,935409 | -2,1893024 | 1 909 696 |
Этот пример конвейера ожидает, пока обновится время данных о рейсе за следующий период. Затем эти подробные сведения сохранятся в хранилище данных Apache Hive для долгосрочного анализа. Конвейер также создает набор данных значительно меньшего размера, с помощью которого суммируются данные только ежедневных рейсов. Эти сводные данные о ежедневных рейсах отправляются в Базу данных SQL для формирования отчетов, например для веб-сайта.
Этот пример конвейера представлен на схеме ниже.
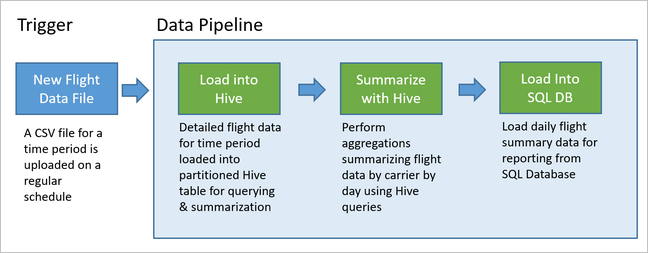
Обзор решения Apache Oozie
Этот конвейер использует запуск Apache Oozie в кластере HDInsight Hadoop.
Oozie представляет свои конвейеры с точки зрения действий, рабочих процессов и координаторов. Действия определяют фактическую работу, которую нужно выполнить, такую как запуск запроса Hive. Рабочие процессы определяют последовательность действий. Координаторы определяют расписания для запуска рабочих процессов. Они также могут ожидать, когда станут доступны новые данные, а затем запускать экземпляр рабочего процесса.
На схеме ниже показана высокоуровневая архитектура этого примера конвейера Oozie.
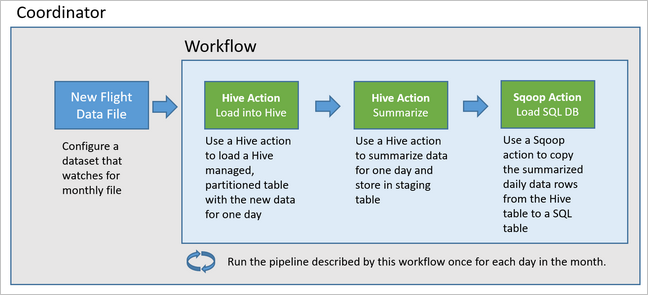
Подготовка ресурсов Azure
Для работы этого конвейера требуются база данных SQL Azure и кластер HDInsight Hadoop в одном расположении. В Базе данных SQL Azure хранятся сводные данные, созданные конвейером, и хранилище метаданных Oozie.
Подготовка базы данных SQL Azure
Создайте Базу данных SQL Azure. См. статью Создание Базы данных SQL Azure на портале Azure.
Чтобы обеспечить кластеру HDInsight доступ к подключенной Базе данных SQL Azure, настройте правила брандмауэра Базы данных SQL Azure таким образом, чтобы предоставить службам и ресурсам Azure доступ к серверу. Вы можете включить этот параметр на портале Azure, выбрав пункты Задать брандмауэр сервера и ВКЛ. в разделе Разрешить службам и ресурсам Azure доступ к серверу для Базы данных SQL Azure. Дополнительные сведения см. в разделе о создании правил брандмауэра для IP-адресов и управление ими.
В редакторе запросов введите следующие инструкции SQL для создания таблицы
dailyflights, в которой будут храниться суммарные данные из каждого запуска конвейера.CREATE TABLE dailyflights ( YEAR INT, MONTH INT, DAY_OF_MONTH INT, CARRIER CHAR(2), AVG_DEP_DELAY FLOAT, AVG_ARR_DELAY FLOAT, TOTAL_DISTANCE FLOAT ) GO CREATE CLUSTERED INDEX dailyflights_clustered_index on dailyflights(YEAR,MONTH,DAY_OF_MONTH,CARRIER) GO
Теперь ваша база данных SQL Azure готова.
Подготовка к работе кластера Apache Hadoop
Создайте кластер Apache Hadoop с настраиваемым хранилищем метаданных. Во время создания кластера на вкладке Хранилище на портале убедитесь, что в разделе Параметры хранилища метаданных выбрана База данных SQL. Дополнительные сведения о выборе хранилище метаданных см. в разделе Выбор настраиваемого хранилища метаданных во время создания кластера. Дополнительные сведения о создании кластера см. в статье, посвященной началу работы с HDInsight на платформе Linux.
Проверка установки туннелирования SSH
Чтобы использовать веб-консоль Oozie для просмотра состояния экземпляров координатора и рабочих процессов, настройте туннель SSH для кластера HDInsight. Дополнительные сведения см. в статье Использование туннелирования SSH для доступа к пользовательскому веб-интерфейсу Ambari, JobHistory, NameNode, Oozie и другим пользовательским веб-интерфейсам.
Примечание.
Вы можете также использовать Chrome с расширением Foxy Proxy для просмотра веб-ресурсов кластера через туннель SSH. Настройте его для просмотра всех запросов к прокси-серверу через узел localhost порта туннеля 9876. Этот подход совместим с подсистемой Windows для Linux, также известной как Bash в Windows 10.
Выполните следующую команду, чтобы открыть туннель SSH к кластеру, где
CLUSTERNAME— это имя кластера:ssh -C2qTnNf -D 9876 sshuser@CLUSTERNAME-ssh.azurehdinsight.netПроверьте работоспособность туннеля, перейдя в Ambari на головном узле. Затем перейдите по ссылке:
http://headnodehost:8080Чтобы получить доступ к веб-консоли Oozie из Ambari, перейдите в раздел Oozie>Быстрые ссылки>[Активный сервер] >Пользовательский веб-интерфейс Oozie.
Настройка Hive
Отправка данных
Скачайте пример CSV-файла, в котором содержатся данные о рейсах за один месяц. Скачайте его ZIP-файл
2017-01-FlightData.zipиз репозитория HDInsight GitHub и распакуйте его в CSV-файл2017-01-FlightData.csv.Скопируйте этот CSV-файл в учетную запись хранения Azure, подключенную к кластеру HDInsight, и разместите в папке
/example/data/flights.Используйте точку подключения службы для копирования файлов с локального компьютера в локальное хранилище головного узла кластера HDInsight.
scp ./2017-01-FlightData.csv sshuser@CLUSTERNAME-ssh.azurehdinsight.net:2017-01-FlightData.csvС помощью команды ssh command подключитесь к кластеру. Измените приведенную ниже команду, заменив
CLUSTERNAMEименем своего кластера, а затем введите команду:ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.netВ сеансе SSH используйте команду HDFS, чтобы скопировать файл из локального хранилища головного узла в служба хранилища Azure.
hadoop fs -mkdir /example/data/flights hdfs dfs -put ./2017-01-FlightData.csv /example/data/flights/2017-01-FlightData.csv
Создание таблиц
Образец данных теперь доступен. Однако конвейеру требуются две таблицы Hive для обработки данных: одна для входящих данных (rawFlights) и одна для сводных (flights). Создайте эти таблицы в Ambari, как показано ниже:
Войдите в Ambari, перейдя по ссылке
http://headnodehost:8080.В списке служб выберите Hive.
Выберите параметр Перейти к представлению рядом с меткой Hive View 2.0.
В текстовом поле запроса вставьте следующие инструкции для создания таблицы
rawFlights. Эта таблицаrawFlightsпредоставит схему при считывании CSV-файлов в папке/example/data/flightsв службе хранилища Azure.CREATE EXTERNAL TABLE IF NOT EXISTS rawflights ( YEAR INT, MONTH INT, DAY_OF_MONTH INT, FL_DATE STRING, CARRIER STRING, FL_NUM STRING, ORIGIN STRING, DEST STRING, DEP_DELAY FLOAT, ARR_DELAY FLOAT, ACTUAL_ELAPSED_TIME FLOAT, DISTANCE FLOAT) ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde' WITH SERDEPROPERTIES ( "separatorChar" = ",", "quoteChar" = "\"" ) LOCATION '/example/data/flights'Нажмите кнопку Выполнить, чтобы создать таблицу.
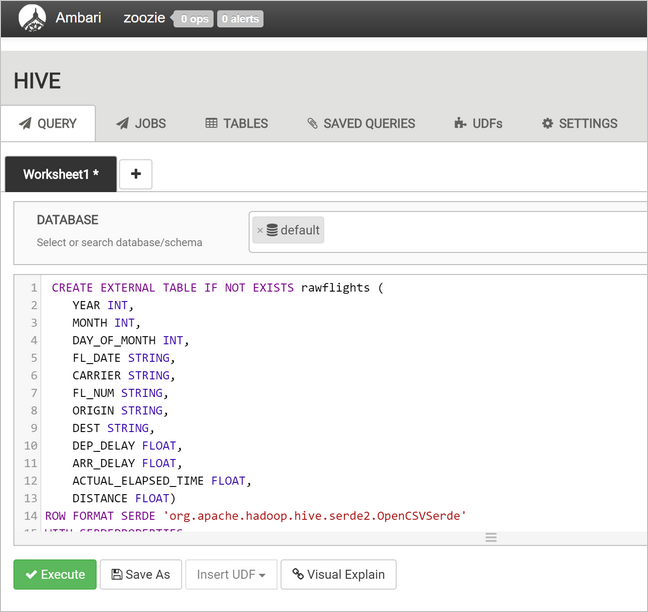
Чтобы создать таблицу
flights, замените текст в текстовом поле запроса инструкциями ниже. Таблицаflightsпредставляет собой управляемую таблицу Hive, которая секционирует загруженные в нее данные по году, месяцу и дням месяца. Эта таблица будет содержать данные всех рейсов с наименьшей степенью детализации в исходных данных одной записи за вылет.SET hive.exec.dynamic.partition.mode=nonstrict; CREATE TABLE flights ( FL_DATE STRING, CARRIER STRING, FL_NUM STRING, ORIGIN STRING, DEST STRING, DEP_DELAY FLOAT, ARR_DELAY FLOAT, ACTUAL_ELAPSED_TIME FLOAT, DISTANCE FLOAT ) PARTITIONED BY (YEAR INT, MONTH INT, DAY_OF_MONTH INT) ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde' WITH SERDEPROPERTIES ( "separatorChar" = ",", "quoteChar" = "\"" );Нажмите кнопку Выполнить, чтобы создать таблицу.
Создание рабочего процесса Oozie
Конвейеры обычно обрабатывают данные в пакетах в соответствии с определенным временным интервалом. В этом случае конвейер ежедневно обрабатывает данные рейсов. Такой подход обеспечивает ежедневное, еженедельное, ежемесячное или годовое поступление входных CSV-файлов.
Пример рабочего процесса изо дня в день обрабатывает данные рейсов с использованием трех основных этапов:
- Выполните запрос Hive, чтобы извлечь данные для диапазона дат этого дня из исходного CSV-файла, представленного таблицей
rawFlightsи вставьте эти данные в таблицуflights. - Выполните запрос Hive для динамического создания промежуточной таблицы в Hive для определенного дня, в которой будет храниться копия данных рейсов, суммированных по дням и оператору.
- Используйте Apache Sqoop, чтобы скопировать все данные из ежедневной промежуточной таблицы в Hive в таблицу назначения
dailyflightsв базе данных SQL Azure. Sqoop считывает исходные строки из данных в таблице Hive, находящейся в службе хранилища Azure, и загружает их в базу данных SQL с помощью подключения JDBC.
Эти три шага координируются рабочим процессом Oozie.
Из локальной рабочей станции создайте файл с именем
job.properties. Используйте приведенный ниже текст в качестве начального содержимого файла. Затем обновите значения для конкретной среды. В таблице под текстом суммированы все свойства, а также приведены расположения значений вашей среды.nameNode=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net jobTracker=[ACTIVERESOURCEMANAGER]:8050 queueName=default oozie.use.system.libpath=true appBase=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/oozie oozie.wf.application.path=${appBase}/load_flights_by_day hiveScriptLoadPartition=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/oozie/load_flights_by_day/hive-load-flights-partition.hql hiveScriptCreateDailyTable=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/oozie/load_flights_by_day/hive-create-daily-summary-table.hql hiveDailyTableName=dailyflights${year}${month}${day} hiveDataFolder=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/example/data/flights/day/${year}/${month}/${day} sqlDatabaseConnectionString="jdbc:sqlserver://[SERVERNAME].database.windows.net;user=[USERNAME];password=[PASSWORD];database=[DATABASENAME]" sqlDatabaseTableName=dailyflights year=2017 month=01 day=03Свойство Источник значения nameNode Полный путь к контейнеру службы хранилища Azure, присоединенному к кластеру HDInsight. jobTracker Внутреннее имя узла в активном головном узле YARN в кластере. На домашней странице Ambari выберите YARN из списка служб, а затем выберите активный диспетчер ресурсов. В верхней области страницы появится универсальный код ресурса (URI) имени узла. Добавьте порт 8050. queueName Имя очереди YARN, используемое при планировании действий Hive. Оставьте для использования по умолчанию. oozie.use.system.libpath Оставьте значение true. appBase Путь к вложенной папке в службе хранилища Azure, где развертывается рабочий процесс Oozie и вспомогательные файлы. oozie.wf.application.path Расположение рабочего процесса Oozie workflow.xmlдля запуска.hiveScriptLoadPartition Путь в службе хранилища Azure к файлу запроса Hive hive-load-flights-partition.hql.hiveScriptCreateDailyTable Путь в службе хранилища Azure к файлу запроса Hive hive-create-daily-summary-table.hql.hiveDailyTableName Динамически созданное имя для промежуточной таблицы. hiveDataFolder Путь в службе хранилища Azure к данным в промежуточной таблице. sqlDatabaseConnectionString Строка подключения синтаксиса JDBC к базе данных SQL Azure. sqlDatabaseTableName Имя таблицы в базе данных SQL Azure, в которую вставляются сводные строки. Оставьте имя dailyflights.year Компонент года дня, для которого вычисляются суммарные результаты данных о рейсах. Оставьте значение по умолчанию. Месяц Компонент месяца дня, для которого вычисляются суммарные результаты данных о рейсах. Оставьте значение по умолчанию. дн. День месяца, для которого вычисляются суммарные результаты данных о рейсах. Оставьте значение по умолчанию. Из локальной рабочей станции создайте файл с именем
hive-load-flights-partition.hql. Используйте приведенный ниже код в качестве содержимого для файла.SET hive.exec.dynamic.partition.mode=nonstrict; INSERT OVERWRITE TABLE flights PARTITION (YEAR, MONTH, DAY_OF_MONTH) SELECT FL_DATE, CARRIER, FL_NUM, ORIGIN, DEST, DEP_DELAY, ARR_DELAY, ACTUAL_ELAPSED_TIME, DISTANCE, YEAR, MONTH, DAY_OF_MONTH FROM rawflights WHERE year = ${year} AND month = ${month} AND day_of_month = ${day};Переменные Oozie используют синтаксис
${variableName}. В файлеjob.propertiesзадаются значения следующих переменных. Oozie подставляет фактические значения во время выполнения.Из локальной рабочей станции создайте файл с именем
hive-create-daily-summary-table.hql. Используйте приведенный ниже код в качестве содержимого для файла.DROP TABLE ${hiveTableName}; CREATE EXTERNAL TABLE ${hiveTableName} ( YEAR INT, MONTH INT, DAY_OF_MONTH INT, CARRIER STRING, AVG_DEP_DELAY FLOAT, AVG_ARR_DELAY FLOAT, TOTAL_DISTANCE FLOAT ) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' STORED AS TEXTFILE LOCATION '${hiveDataFolder}'; INSERT OVERWRITE TABLE ${hiveTableName} SELECT year, month, day_of_month, carrier, avg(dep_delay) avg_dep_delay, avg(arr_delay) avg_arr_delay, sum(distance) total_distance FROM flights GROUP BY year, month, day_of_month, carrier HAVING year = ${year} AND month = ${month} AND day_of_month = ${day};Этот запрос создает промежуточную таблицу, в которой будут храниться только сводные данные за один день. Запишите инструкцию SELECT, с помощью которой вычисляется среднее время задержки и общая дистанция, пройденная перевозчиком за день. Данные, вставленные в эту таблицу, хранятся в известном расположении (путь указывается с помощью переменной hiveDataFolder), так что оно может использоваться как источник для Sqoop на следующем шаге.
Из локальной рабочей станции создайте файл с именем
workflow.xml. Используйте приведенный ниже код в качестве содержимого для файла. Приведенные выше действия представлены в файле рабочего процесса Oozie как отдельные действия.<workflow-app name="loadflightstable" xmlns="uri:oozie:workflow:0.5"> <start to = "RunHiveLoadFlightsScript"/> <action name="RunHiveLoadFlightsScript"> <hive xmlns="uri:oozie:hive-action:0.2"> <job-tracker>${jobTracker}</job-tracker> <name-node>${nameNode}</name-node> <configuration> <property> <name>mapred.job.queue.name</name> <value>${queueName}</value> </property> </configuration> <script>${hiveScriptLoadPartition}</script> <param>year=${year}</param> <param>month=${month}</param> <param>day=${day}</param> </hive> <ok to="RunHiveCreateDailyFlightTableScript"/> <error to="fail"/> </action> <action name="RunHiveCreateDailyFlightTableScript"> <hive xmlns="uri:oozie:hive-action:0.2"> <job-tracker>${jobTracker}</job-tracker> <name-node>${nameNode}</name-node> <configuration> <property> <name>mapred.job.queue.name</name> <value>${queueName}</value> </property> </configuration> <script>${hiveScriptCreateDailyTable}</script> <param>hiveTableName=${hiveDailyTableName}</param> <param>year=${year}</param> <param>month=${month}</param> <param>day=${day}</param> <param>hiveDataFolder=${hiveDataFolder}/${year}/${month}/${day}</param> </hive> <ok to="RunSqoopExport"/> <error to="fail"/> </action> <action name="RunSqoopExport"> <sqoop xmlns="uri:oozie:sqoop-action:0.2"> <job-tracker>${jobTracker}</job-tracker> <name-node>${nameNode}</name-node> <configuration> <property> <name>mapred.compress.map.output</name> <value>true</value> </property> </configuration> <arg>export</arg> <arg>--connect</arg> <arg>${sqlDatabaseConnectionString}</arg> <arg>--table</arg> <arg>${sqlDatabaseTableName}</arg> <arg>--export-dir</arg> <arg>${hiveDataFolder}/${year}/${month}/${day}</arg> <arg>-m</arg> <arg>1</arg> <arg>--input-fields-terminated-by</arg> <arg>"\t"</arg> <archive>mssql-jdbc-7.0.0.jre8.jar</archive> </sqoop> <ok to="end"/> <error to="fail"/> </action> <kill name="fail"> <message>Job failed, error message[${wf:errorMessage(wf:lastErrorNode())}] </message> </kill> <end name="end"/> </workflow-app>
Доступ к запросам Hive можно получить с помощью путей в службе хранилища Azure, а остальные значения переменной можно получить с помощью файла свойств job.properties. С помощью этого файла рабочий процесс был настроен для выполнения 3 января 2017 года.
Развертывание и запуск рабочего процесса Oozie
Используйте точку подключения службы своего сеанса Bash, чтобы развернуть рабочий процесс Oozie (workflow.xml), запросы Hive (hive-load-flights-partition.hql и hive-create-daily-summary-table.hql) и конфигурацию задания (job.properties). В Oozie в локальном хранилище головного узла может располагаться только файл job.properties. Остальные файлы должны храниться в HDFS, в этом случае — в службе хранилища Azure. Действие Sqoop, используемое рабочим процессом, зависит от драйвера JDBC для обмена данными с базой данных SQL, которую нужно скопировать из головного узла в HDFS.
Создайте подпапку
load_flights_by_dayниже пути пользователя в локальном хранилище головного узла. В открытом сеансе SSH выполните следующую команду:mkdir load_flights_by_dayСкопируйте все файлы в текущем каталоге (файлы
workflow.xmlиjob.properties) в подпапкуload_flights_by_day. В локальной рабочей станции выполните следующую команду:scp ./* sshuser@CLUSTERNAME-ssh.azurehdinsight.net:load_flights_by_dayСкопируйте файлы рабочих процессов в HDFS. В открытом сеансе SSH выполните следующие команды:
cd load_flights_by_day hadoop fs -mkdir -p /oozie/load_flights_by_day hdfs dfs -put ./* /oozie/load_flights_by_dayСкопируйте файл
mssql-jdbc-7.0.0.jre8.jarиз локального головного узла в папку рабочих процессов в HDFS. При необходимости измените команду, если кластер содержит другой JAR-файл. Внесите необходимые изменения в файлworkflow.xmlв соответствии с другим JAR-файлом. В открытом сеансе SSH выполните следующую команду:hdfs dfs -put /usr/share/java/sqljdbc_7.0/enu/mssql-jdbc*.jar /oozie/load_flights_by_dayЗапуск бизнес-процесса. В открытом сеансе SSH выполните следующую команду:
oozie job -config job.properties -runПроследите его состояние с помощью веб-консоли Oozie. В Ambari выберите Oozie, Быстрые ссылки, Oozie Web Console (Веб-консоль Oozie). На вкладке заданий рабочего процесса выберите Все задания.
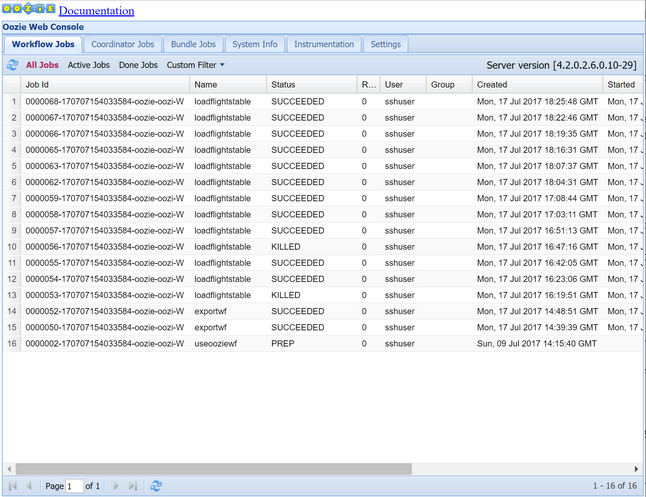
Если для параметра состояния используется значение "Успешно", запросите таблицу Базы данных SQL, чтобы просмотреть вставленные строки. С помощью портала Azure перейдите в область базы данных SQL, нажмите кнопку Инструменты и откройте редактор запросов.
SELECT * FROM dailyflights
Теперь, когда рабочий процесс выполняется для отдельного тестового дня, можно поместить этот рабочий процесс в оболочку с координатором планирования такого процесса для его ежедневного запуска.
Запуск рабочего процесса с помощью координатора
Чтобы запланировать ежедневный запуск этого рабочего процесса (или запуск на протяжении всех дней в диапазоне дат), можно использовать координатор. Координатор определяется с помощью XML-файла, например coordinator.xml:
<coordinator-app name="daily_export" start="2017-01-01T00:00Z" end="2017-01-05T00:00Z" frequency="${coord:days(1)}" timezone="UTC" xmlns="uri:oozie:coordinator:0.4">
<datasets>
<dataset name="ds_input1" frequency="${coord:days(1)}" initial-instance="2016-12-31T00:00Z" timezone="UTC">
<uri-template>${sourceDataFolder}${YEAR}-${MONTH}-FlightData.csv</uri-template>
<done-flag></done-flag>
</dataset>
</datasets>
<input-events>
<data-in name="event_input1" dataset="ds_input1">
<instance>${coord:current(0)}</instance>
</data-in>
</input-events>
<action>
<workflow>
<app-path>${appBase}/load_flights_by_day</app-path>
<configuration>
<property>
<name>year</name>
<value>${coord:formatTime(coord:nominalTime(), 'yyyy')}</value>
</property>
<property>
<name>month</name>
<value>${coord:formatTime(coord:nominalTime(), 'MM')}</value>
</property>
<property>
<name>day</name>
<value>${coord:formatTime(coord:nominalTime(), 'dd')}</value>
</property>
<property>
<name>hiveScriptLoadPartition</name>
<value>${hiveScriptLoadPartition}</value>
</property>
<property>
<name>hiveScriptCreateDailyTable</name>
<value>${hiveScriptCreateDailyTable}</value>
</property>
<property>
<name>hiveDailyTableNamePrefix</name>
<value>${hiveDailyTableNamePrefix}</value>
</property>
<property>
<name>hiveDailyTableName</name>
<value>${hiveDailyTableNamePrefix}${coord:formatTime(coord:nominalTime(), 'yyyy')}${coord:formatTime(coord:nominalTime(), 'MM')}${coord:formatTime(coord:nominalTime(), 'dd')}</value>
</property>
<property>
<name>hiveDataFolderPrefix</name>
<value>${hiveDataFolderPrefix}</value>
</property>
<property>
<name>hiveDataFolder</name>
<value>${hiveDataFolderPrefix}${coord:formatTime(coord:nominalTime(), 'yyyy')}/${coord:formatTime(coord:nominalTime(), 'MM')}/${coord:formatTime(coord:nominalTime(), 'dd')}</value>
</property>
<property>
<name>sqlDatabaseConnectionString</name>
<value>${sqlDatabaseConnectionString}</value>
</property>
<property>
<name>sqlDatabaseTableName</name>
<value>${sqlDatabaseTableName}</value>
</property>
</configuration>
</workflow>
</action>
</coordinator-app>
Как видите, большая часть координатора только передает сведения о конфигурации в экземпляр рабочего процесса. Однако можно вызвать некоторые важные компоненты.
Точка 1. Атрибуты
startиendв элементеcoordinator-appсамостоятельно управляют интервалом времени запуска координатора.<coordinator-app ... start="2017-01-01T00:00Z" end="2017-01-05T00:00Z" frequency="${coord:days(1)}" ...>Координатор отвечает за планирование действий в рамках диапазона дат
startиendв соответствии с интервалом, указанным с помощью атрибутаfrequency. В свою очередь каждое запланированное действие запускает рабочий процесс согласно настройкам. В приведенном выше определении координатора он был настроен на запуск действий с 1 до 5 января 2017 года. Для частоты с помощью выражения частоты${coord:days(1)}языка выражений Oozie было задано значение 1 день. В результате координатор планировал действие (и следовательно рабочий процесс) один раз в день. Для диапазонов дат, которые прошли, как показано в этом примере, запуск действия был запланирован без задержек. Начало даты, в соответствии с которой планируется запуск действия, называется номинальным временем. Например, для обработки данных за 1 января 2017 года координатор запланировал действие с номинальным временем 2017-01-01T00:00:00 GMT.Точка 2. В рамках диапазона дат рабочего процесса элемент
datasetуказывает, где в HDFS искать данные для определенного диапазона дат, и настраивает способ определения готовности данных к обработке в Oozie.<dataset name="ds_input1" frequency="${coord:days(1)}" initial-instance="2016-12-31T00:00Z" timezone="UTC"> <uri-template>${sourceDataFolder}${YEAR}-${MONTH}-FlightData.csv</uri-template> <done-flag></done-flag> </dataset>Путь к данным в HDFS создается динамически в соответствии с выражением в элементе
uri-template. В этом координаторе для набора данных также используется частота в один день. Тогда как начальная и конечная даты в элементе координатора управляют временем планирования запуска действий (и определяют их номинальное время),initial-instanceиfrequencyв наборе данных управляют расчетом даты, используемой в созданииuri-template. В этом случае задайте начальный экземпляр на один день до начала координатора, чтобы убедиться, что он получает данные первого дня (1 января 2017 г.). При расчете даты набора данных выполняется накат из значенияinitial-instance(31.12.2016) с интервалом приращения частоты набора данных (один день) пока не будет найдена последняя дата, не выходящая за рамки номинального времени, заданного координатором (2017-01-01T00:00:00 GMT для первого действия).Пустой элемент
done-flagуказывает, что когда Oozie проверяет наличие входных данных в назначенное время, Oozie выполняет поиск данных, доступность которых определяется наличием каталога или файла. В этом случае наличием CSV-файла. Если CSV-файл имеется, Oozie предполагает, что данные готовы и запускает экземпляр рабочего процесса для обработки файла. Если этого файла нет, Oozie предполагает, что данные не готовы и запуск рабочего процесса находится в режиме ожидания.Точка 3. Элемент
data-inуказывает определенную метку времени как номинальное время при замене значений вuri-templateдля связанного набора данных.<data-in name="event_input1" dataset="ds_input1"> <instance>${coord:current(0)}</instance> </data-in>В этом случае задайте выражение
${coord:current(0)}для экземпляра, которое преобразуется в номинальное время действия, первоначально запланированное координатором. Другими словами, когда координатор планирует запуск действия в соответствии с номинальным временем 01.01.2017, это время используется для замены переменных года (2017) и месяца (январь) в шаблоне URI. После вычисления шаблона URI для этого экземпляра Oozie проверяет, доступен ли ожидаемый файл или каталог и, соответственно, планирует следующий запуск рабочего процесса.
Три точки выше работают совместно, чтобы обеспечить условие, когда координатор планирует обработку исходных данных изо дня в день.
Точка 1. Координатор запускается с наступлением номинальной даты — 01 января 2017 года.
Точка 2. Поиск Oozie данных, доступных в
sourceDataFolder/2017-01-FlightData.csv.Точка 3. Когда Oozie находит этот файл, он планирует экземпляр рабочего процесса, который будет обрабатывать данные 1 января 2017 года. Затем Oozie продолжает обработку для даты 2 января 2017 года. Это действие повторяется до 5 января 2017 года, но не ограничивается этой датой.
В рабочих процессах конфигурация координатора определяется в файле job.properties, который включает расширенный набор параметров, используемых этим процессом.
nameNode=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net
jobTracker=[ACTIVERESOURCEMANAGER]:8050
queueName=default
oozie.use.system.libpath=true
appBase=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/oozie
oozie.coord.application.path=${appBase}
sourceDataFolder=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/example/data/flights/
hiveScriptLoadPartition=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/oozie/load_flights_by_day/hive-load-flights-partition.hql
hiveScriptCreateDailyTable=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/oozie/load_flights_by_day/hive-create-daily-summary-table.hql
hiveDailyTableNamePrefix=dailyflights
hiveDataFolderPrefix=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/example/data/flights/day/
sqlDatabaseConnectionString="jdbc:sqlserver://[SERVERNAME].database.windows.net;user=[USERNAME];password=[PASSWORD];database=[DATABASENAME]"
sqlDatabaseTableName=dailyflights
Единственные новые свойства, представленные в этом файле job.properties:
| Свойство | Источник значения |
|---|---|
| oozie.coord.application.path | Указывает расположение файла coordinator.xml, содержащего координатор для запуска Oozie. |
| hiveDailyTableNamePrefix | Префикс, используемый при динамическом создании имени таблицы в промежуточной таблице. |
| hiveDataFolderPrefix | Префикс пути, где будут храниться все промежуточные таблицы. |
Развертывание и запуск координатора Oozie
Чтобы запустить конвейер с помощью координатора, выполните те же действия, актуальные для запуска рабочего процесса, за исключением того, что вы будете работать с папкой на уровень выше папки, содержащей рабочий процесс. Это соглашение о папках отделяет координаторы от рабочих процессов на диске, поэтому один координатор можно связать с другими дочерними рабочими процессами.
Используйте точку подключения службы с локального компьютера для копирования файлов координатора в локальное хранилище головного узла кластера.
scp ./* sshuser@CLUSTERNAME-ssh.azurehdinsight.net:~Скопируйте ключ SSH в головной узел.
ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.netСкопируйте файлы координатора в HDFS.
hdfs dfs -put ./* /oozie/Запустите координатор.
oozie job -config job.properties -runС помощью веб-консоли Oozie проверьте его состояние. Выберите вкладку Coordinator Jobs (Задания координатора), а затем щелкните Все задания.
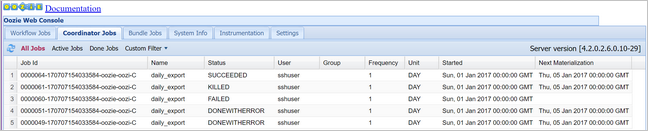
Выберите экземпляр координатора для отображения списка запланированных действий. В этом случае вы должны увидеть четыре действия с номинальным временем в диапазоне от 1 января 2017 г. до 4 января 2017 г.
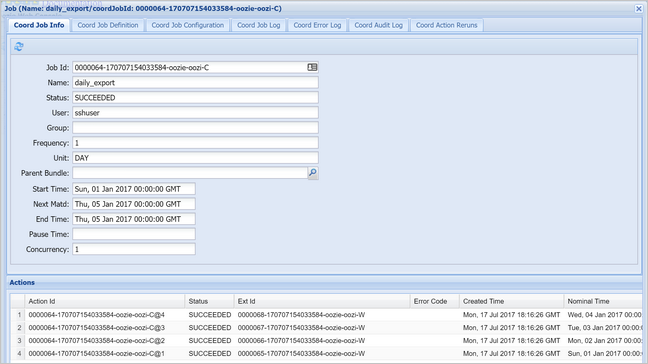
Каждое действие в этом списке соответствует экземпляру рабочего процесса, который обрабатывает данные за один день, и где начало дня обозначается номинальным временем.