Общие сведения об Apache Kafka в Azure HDInsight
Apache Kafka — это распределенная платформа потоковой передачи с открытым исходным кодом, которую можно использовать для создания конвейеров и приложений потоковой передачи данных в режиме реального времени. Kafka также предоставляет функцию брокера сообщений, подобную очереди сообщений, с помощью которой можно выполнять публикацию и подписываться на именованные потоки данных.
Ниже приведены характеристики Kafka в HDInsight.
Это управляемая служба, которая упрощает процесс настройки. Она создает конфигурацию, проверенную и поддерживаемую корпорацией Майкрософт.
Корпорация Майкрософт предоставляет соглашение об уровне обслуживания (SLA), гарантирующее 99,9 % время непрерывной работы Kafka. Дополнительные сведения см. в документе Соглашение об уровне обслуживания для HDInsight.
В качестве резервного хранилища для Kafka используются управляемые диски Azure. Управляемые диски могут обеспечить до 16 ТБ хранилища для каждого брокера Kafka. См. сведения о настройке числа управляемых дисков и повышении степени масштабируемости для Apache Kafka в HDInsight.
См. дополнительные сведения об управляемых дисках Azure.
Служба Kafka была разработана для одномерной стойки. Azure разделяет стойку на два измерения — домены обновления (UD) и домены сбоя (FD). Корпорация Майкрософт предоставляет инструменты, которые могут выполнять перераспределение секций и реплик Kafka в доменах обновления и доменах сбоя.
Дополнительные сведения см. в статье Обеспечение высокого уровня доступности данных с помощью Apache Kafka в HDInsight.
HDInsight позволяет изменить количество рабочих узлов (в которых размещается брокер Kafka) после создания кластера. Вертикальное увеличение масштаба можно выполнить на портале Azure, в Azure PowerShell и других интерфейсах управления Azure. Для Kafka выполните повторную балансировку реплик секций после масштабирования. Балансировка секций позволяет Kafka пользоваться преимуществами нового количества рабочих узлов.
HDInsight Kafka не поддерживает вертикальное уменьшение масштаба или уменьшение числа брокеров в кластере. При попытке уменьшить число узлов будет возвращена ошибка
InvalidKafkaScaleDownRequestErrorCode.Дополнительные сведения см. в статье Обеспечение высокого уровня доступности данных с помощью Apache Kafka в HDInsight.
Журналы Azure Monitor можно использовать для мониторинга Kafka в HDInsight. В журналах Azure Monitor представлена информация об уровне виртуальной машины (например, метрики диска и сетевой карты, а также метрики JMX от Kafka).
Дополнительные сведения см. в статье Анализ журналов для Apache Kafka в HDInsight.
Архитектура Apache Kafka в HDInsight
На приведенной ниже схеме показана стандартная конфигурация Kafka, в которой предусмотрены группы потребителей, секционирование и репликация, чтобы обеспечить параллельное считывание событий и отказоустойчивость.
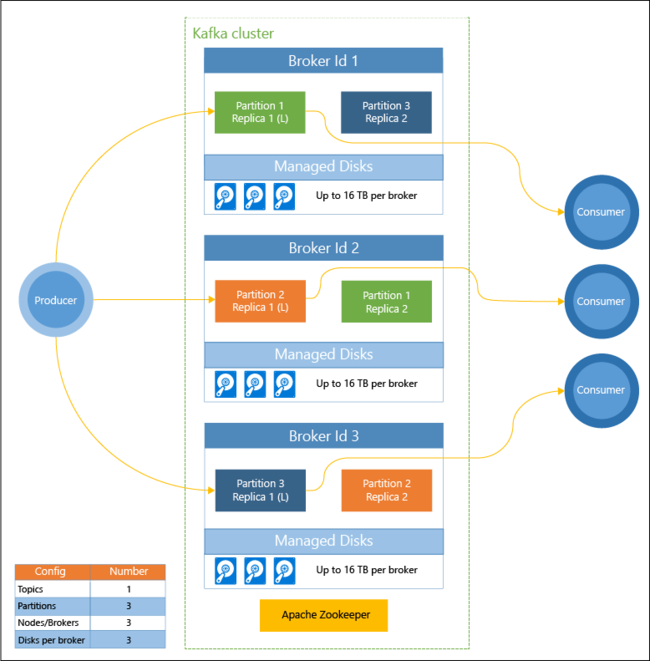
Apache ZooKeeper управляет состоянием кластера Kafka. Служба Zookeeper предназначена для параллельных надежных транзакций с низкой задержкой.
В Kafka записи (данные) хранятся в разделах. Записи создаются производителями, а используются потребителями. Производители отправляют записи в брокеры Kafka. Каждый рабочий узел в кластере HDInsight — это брокер Kafka.
Разделы позволяют распределить записи между брокерами. При считывании записей можно использовать один потребитель на секцию, чтобы обеспечить параллельную обработку данных.
Репликация используется для дублирования секций между узлами, чтобы обеспечить защиту от сбоев узлов (брокеров). Секция, обозначенная на схеме буквой (L), является ведущей (leader) в определенном разделе. Трафик производителя направляется в ведущую секцию каждого узла в зависимости от состояния, которым управляет ZooKeeper.
Для чего использовать Apache Kafka в HDInsight?
Ниже приведены распространенные задачи и шаблоны, которые могут быть выполнены с помощью Kafka в HDInsight.
| Использование | Description |
|---|---|
| Репликация данных Apache Kafka | Kafka предоставляет программу MirrorMaker, которая производит репликацию данных между кластерами Kafka. Сведения об использовании MirrorMaker см. в статье Репликация разделов Apache Kafka с помощью Kafka в HDInsight и MirrorMaker. |
| Модель обмена сообщениями по схеме "публикация — подписка" | Kafka предоставляет API производителя для публикации записей в разделе Kafka. При подписке на раздел используется API пользователя. Дополнительные сведения см. в статье Краткое руководство по созданию Apache Kafka в кластере HDInsight. |
| Потоковая обработка | Kafka часто используется с Spark для обработки потоков в режиме реального времени. Kafka 2.1.1 и 2.4.1 (HDInsight версии 4.0 и 5.0) поддерживает API потоковой передачи, который позволяет создавать решения потоковой передачи, не требуя Spark. Дополнительные сведения см. в статье Краткое руководство по созданию Apache Kafka в кластере HDInsight. |
| Горизонтальное масштабирование | В Kafka потоки разделяются между узлами в кластере HDInsight. Процессы пользователя можно связать с отдельными секциями для обеспечения балансировки нагрузки при использовании записей. Дополнительные сведения см. в статье Краткое руководство по созданию Apache Kafka в кластере HDInsight. |
| Упорядоченная доставка | В каждой секции записи сохраняются в потоке в том порядке, в котором они были получены. Достаточно связать один процесс пользователя с секцией — и записи будут обрабатываться в определенном порядке. Дополнительные сведения см. в статье Краткое руководство по созданию Apache Kafka в кластере HDInsight. |
| Обмен сообщениями | Благодаря поддержке модели обмена сообщениями по схеме "публикация — подписка" Kafka часто используется как брокер сообщений. |
| Отслеживание действий | Kafka предоставляет возможность ведения журнала записей в определенном порядке, поэтому Kafka можно использовать для отслеживания и повторного создания действий. Например, действий пользователя на веб-сайте или в приложении. |
| Агрегат | С помощью потоковой обработки можно объединить информацию из разных потоков для ее централизации в качестве оперативных данных. |
| Преобразование | С помощью потоковой обработки можно объединять и дополнять данные из нескольких входных разделов в один или несколько выходных разделов. |
Следующие шаги
Ниже приведены ссылки на статьи об использовании Apache Kafka в HDInsight.