Заметка
Доступ к этой странице требует авторизации. Вы можете попробовать войти в систему или изменить каталог.
Доступ к этой странице требует авторизации. Вы можете попробовать сменить директорию.
Из этого руководства вы узнаете, как создать приложение Apache Spark, написанное в Scala, с помощью Apache Maven с IntelliJ IDEA. В этой статье в качестве системы сборки используется Apache Maven. И начинается с существующего архетипа Maven для Scala, предоставляемого IntelliJ IDEA. Создание приложения Scala в IntelliJ IDEA включает следующие действия.
- Используйте Maven в качестве системы сборки.
- Обновите файл объектной модели проекта (POM), чтобы устранить зависимости модуля Spark.
- Напишите приложение в Scala.
- Создайте JAR-файл, который можно отправить в кластеры HDInsight Spark.
- Запустите приложение в кластере Spark с помощью Livy.
В этом руководстве описано, как:
- Установите плагин Scala для IntelliJ IDEA
- Разработка приложения Scala Maven с помощью IntelliJ
- Создание автономного проекта Scala
Предпосылки
Кластер Apache Spark в HDInsight. Для получения инструкций см. Создание кластеров Apache Spark в Azure HDInsight.
Комплект разработчика Oracle Java. В этом руководстве используется Java версии 8.0.202.
Интегрированная среда разработки Java. В этой статье используется IntelliJ IDEA Community 2018.3.4.
Azure Toolkit for IntelliJ. Дополнительные сведения см. в статье Установка набора средств Azure для IntelliJ.
Установка плагина Scala для IntelliJ IDEA
Выполните следующие действия, чтобы установить плагин Scala:
Откройте IntelliJ IDEA.
На экране приветствия перейдите к разделу "Настройка>подключаемых модулей" , чтобы открыть окно "Подключаемые модули ".
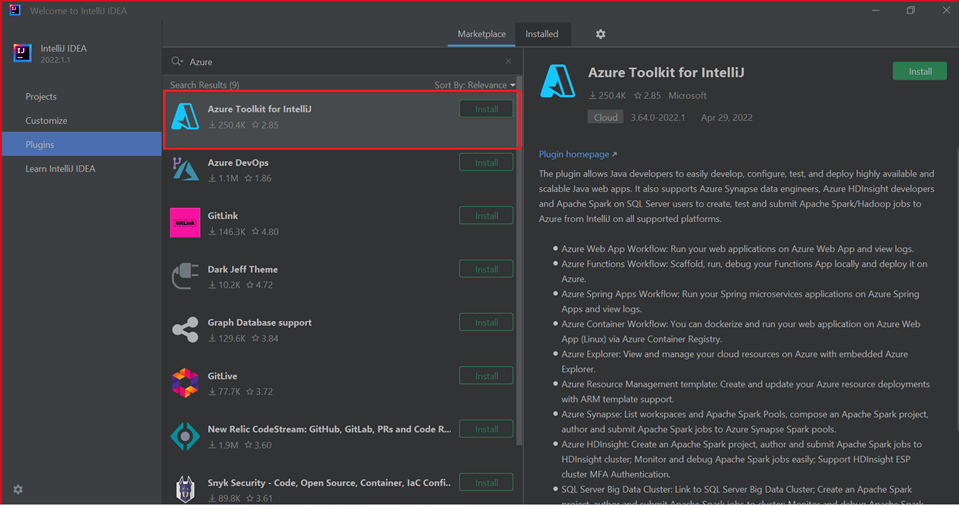
Выберите "Установить " для набора средств Azure для IntelliJ.
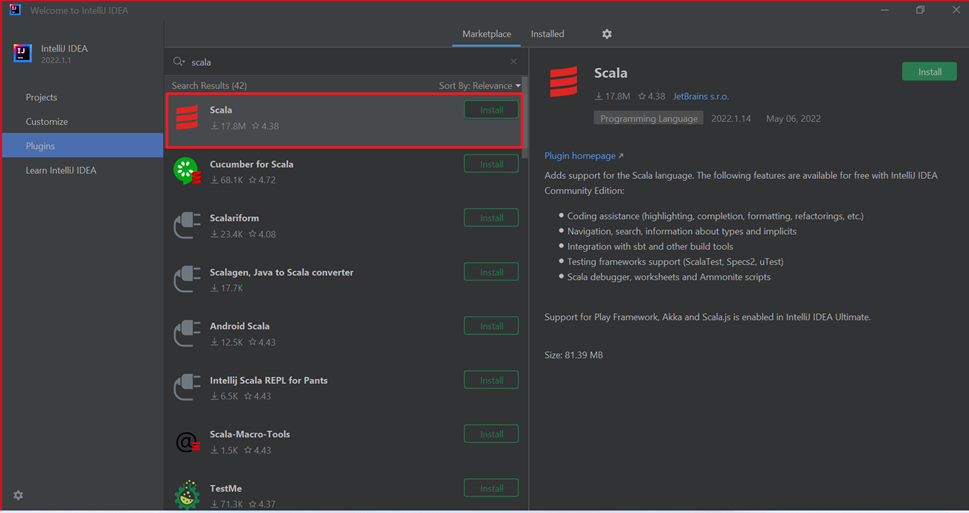
Выберите Установить для плагина Scala, который представлен в новом окне.
После успешной установки подключаемого модуля необходимо перезапустить интегрированную среду разработки.
Создание приложения с помощью IntelliJ
Запустите IntelliJ IDEA и выберите Create New Project (Создать проект), чтобы открыть окно New Project (Новый проект).
На панели слева выберите Azure Spark/HDInsight.
Выберите проект Spark (Scala) в главном окне.
В раскрывающемся списке средства сборки выберите одно из следующих значений:
- Maven для поддержки мастера создания проекта Scala.
- SBT для управления зависимостями и сборки проекта Scala.
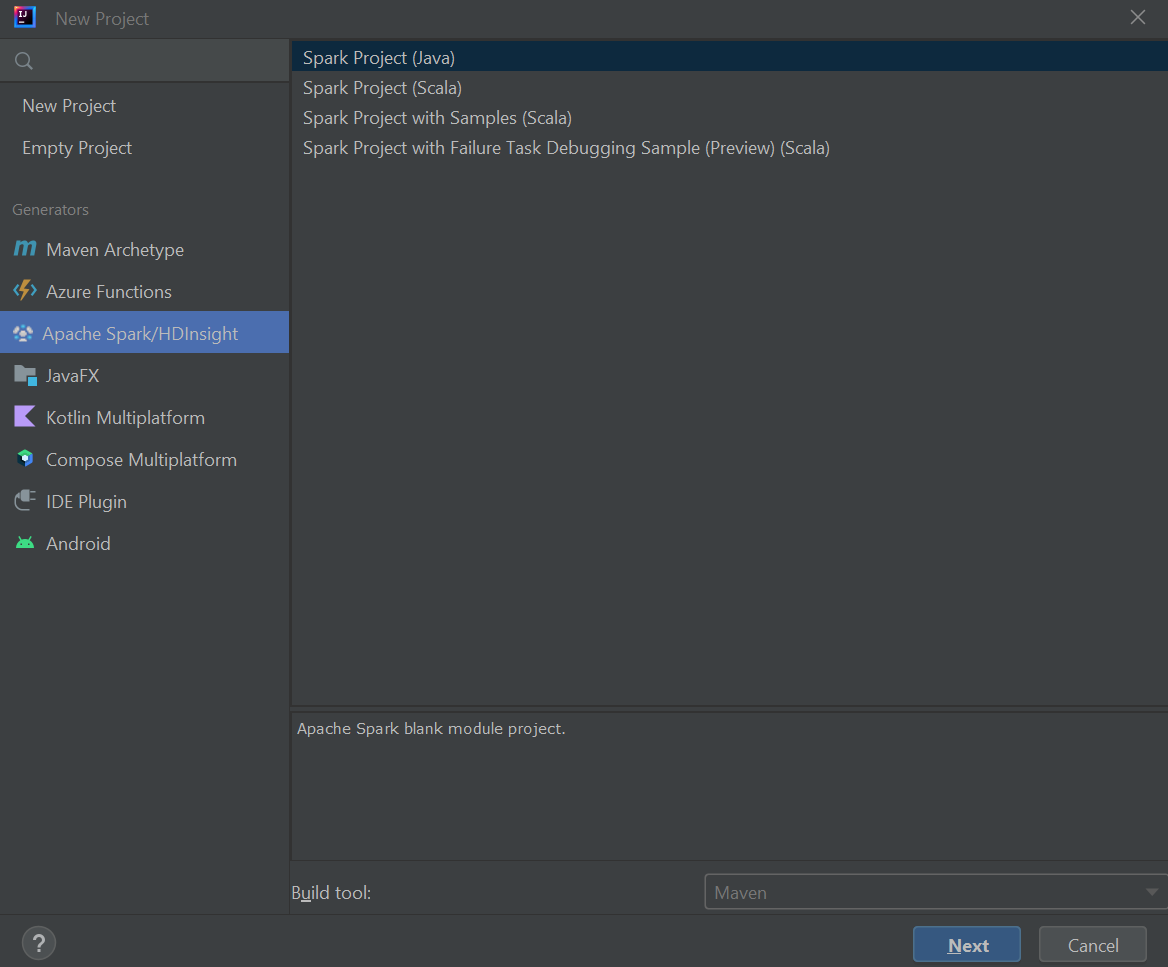
Выберите Далее.
В окне New Project (Новый проект) укажите следующую информацию:
Недвижимость Описание Имя проекта Введите имя. Расположение проекта Введите расположение для сохранения проекта. Project SDK (Пакет SDK проекта) Это поле будет пустым при первом использовании IDEA. Выберите New... (Создать...) и перейдите к JDK. Версия Spark Мастер создания интегрирует правильную версию пакетов SDK для Spark и Scala. Если используется версия кластера Spark более ранняя, чем 2.0, выберите Spark 1.x. В противном случае выберите Spark2.x. В этом примере используется Spark 2.3.0 (Scala 2.11.8). 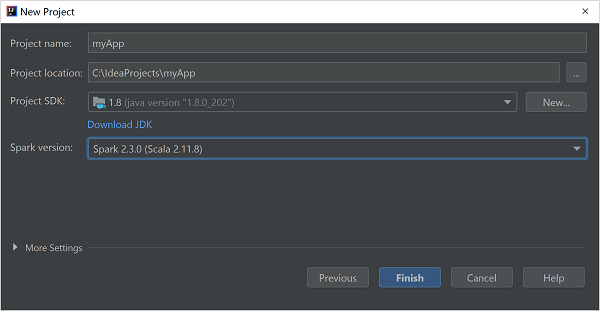
Нажмите Готово.
Создание автономного проекта Scala
Запустите IntelliJ IDEA и выберите Create New Project (Создать проект), чтобы открыть окно New Project (Новый проект).
Выберите Maven в левой области.
Укажите пакет SDK для Project. Если пусто, выберите "Создать" и перейдите в каталог установки Java.
Установите флажок "Создать" из архетипа .
В списке архетипов выберите
org.scala-tools.archetypes:scala-archetype-simple. Этот архетип создает правильную структуру каталогов и загружает необходимые зависимости по умолчанию для записи программы Scala.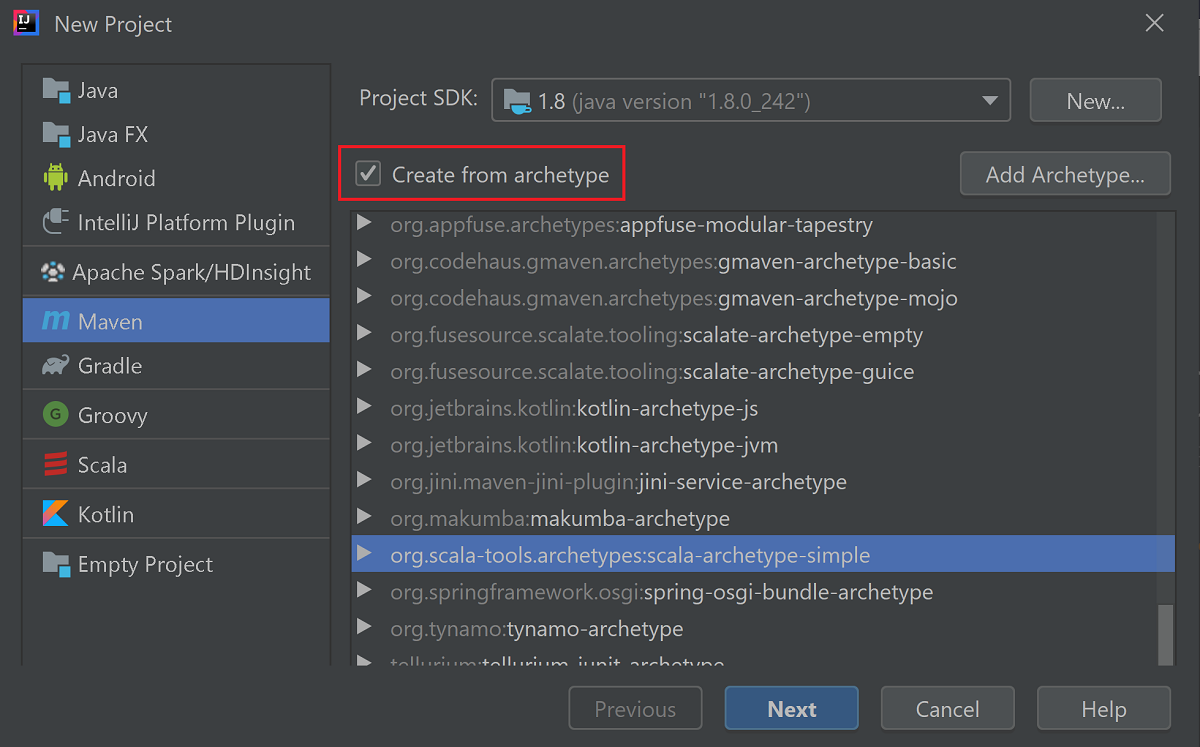
Выберите Далее.
Разверните координаты артефакта. Укажите соответствующие значения для GroupId и ArtifactId. Имя и расположение автоматически заполняются. В этом руководстве используются следующие значения:
- GroupId: com.microsoft.spark.example
- ArtifactId: SparkSimpleApp
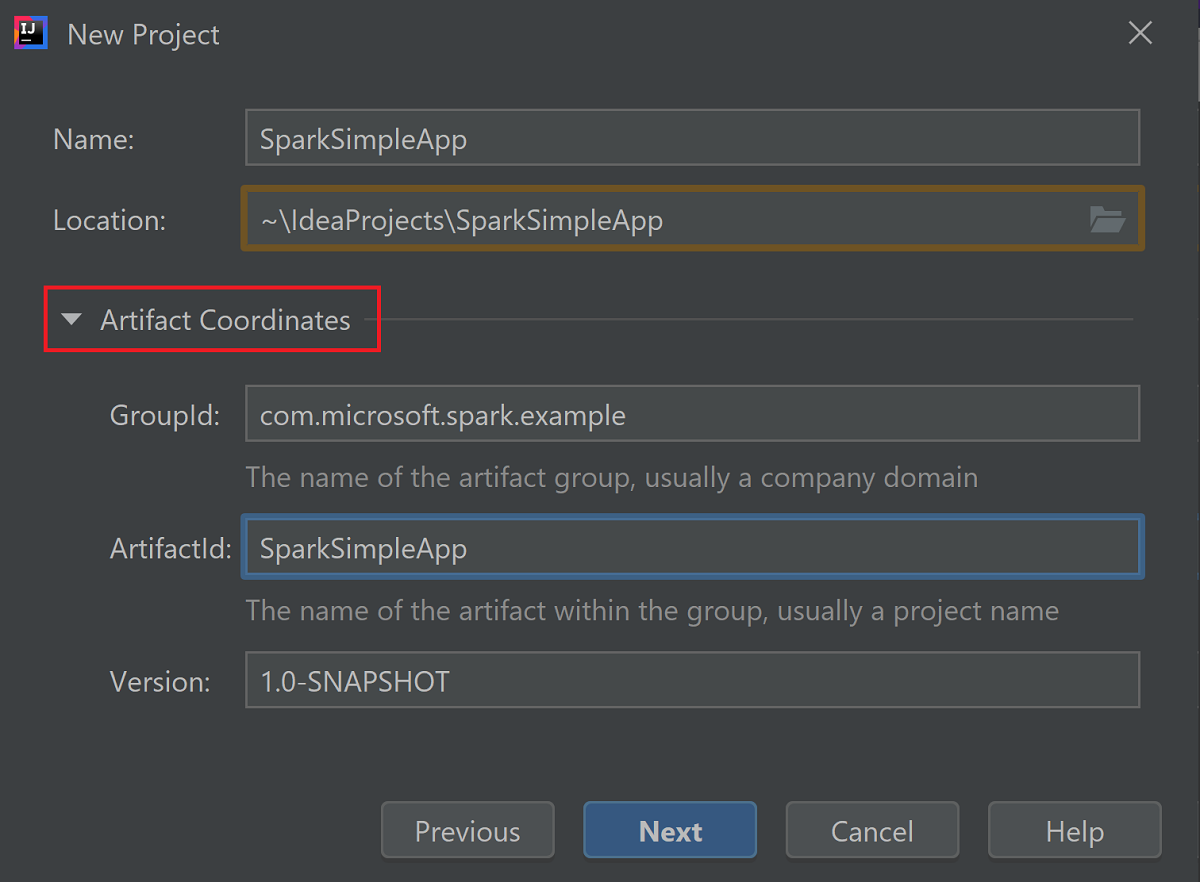
Выберите Далее.
Проверьте параметры и нажмите кнопку "Далее".
Проверьте имя и расположение проекта, а затем нажмите кнопку Готово. Для импорта проекта потребуется несколько минут.
После импорта проекта в левой области перейдите к SparkSimpleApp>src>test>scala>com>microsoft>spark>example. Щелкните MySpec правой кнопкой мыши и выберите "Удалить...". Этот файл не нужен для приложения. Нажмите кнопку ОК в диалоговом окне.
В последующих шагах вы обновите pom.xml , чтобы определить зависимости для приложения Spark Scala. Чтобы эти зависимости загружались и разрешались автоматически, необходимо настроить Maven.
В меню "Файл" выберите "Параметры" , чтобы открыть окно "Параметры ".
В окне "Настройки" перейдите в Build, Execution, Deployment>Build Tools>Maven>Importing.
Установите флажок "Импорт проектов Maven" автоматически .
Выберите Применить, а затем выберите ОК. Затем вы вернетесь в окно проекта.
:::image type="content" source="./media/apache-spark-create-standalone-application/configure-maven-download.png" alt-text="Configure Maven for automatic downloads." border="true":::В левой области перейдите к src>main> scala >com.microsoft.spark.example, а затем дважды щелкните приложение, чтобы открытьApp.scala.
Замените существующий пример кода следующим кодом и сохраните изменения. Этот код считывает данные из HVAC.csv (доступно во всех кластерах HDInsight Spark). Извлекает строки, имеющие только одну цифру в шестом столбце. И записывает выходные данные в /HVACOut в контейнер хранилища по умолчанию для кластера.
package com.microsoft.spark.example import org.apache.spark.SparkConf import org.apache.spark.SparkContext /** * Test IO to wasb */ object WasbIOTest { def main (arg: Array[String]): Unit = { val conf = new SparkConf().setAppName("WASBIOTest") val sc = new SparkContext(conf) val rdd = sc.textFile("wasb:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv") //find the rows which have only one digit in the 7th column in the CSV val rdd1 = rdd.filter(s => s.split(",")(6).length() == 1) rdd1.saveAsTextFile("wasb:///HVACout") } }В левой области дважды щелкните pom.xml.
В
<project>\<properties>добавьте следующие сегменты:<scala.version>2.11.8</scala.version> <scala.compat.version>2.11.8</scala.compat.version> <scala.binary.version>2.11</scala.binary.version>В пределах
<project>\<dependencies>добавьте следующие сегменты:<dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_${scala.binary.version}</artifactId> <version>2.3.0</version> </dependency>Save changes to pom.xml.Создайте файл .jar. IntelliJ IDEA позволяет создавать JAR-файл в качестве артефакта проекта. Выполните следующие действия.
В меню "Файл" выберите "Структура проекта...".
В окне Структуры проекта перейдите к Артефактам>, нажмите на символ плюс +>JAR>из модулей с зависимостями....
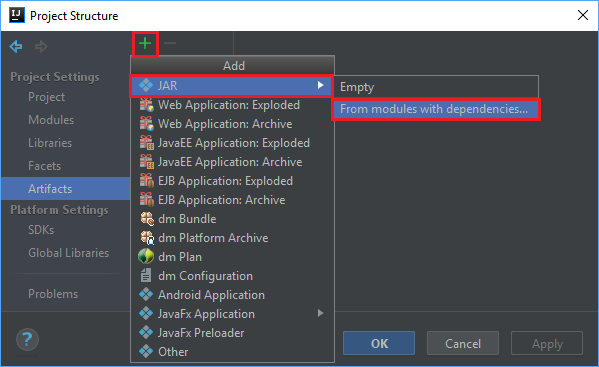
В окне "Создание JAR-файла из модулей " выберите значок папки в текстовом поле "Основной класс ".
В окне "Выбор главного класса " выберите класс, который отображается по умолчанию, и нажмите кнопку "ОК".
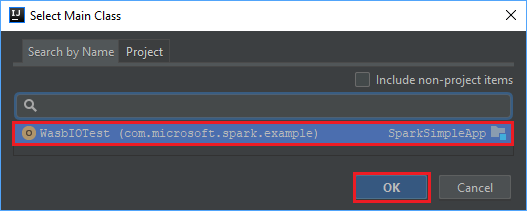
В окне "Создание JAR-файла из модулей " убедитесь, что выбран параметр извлечения в целевой JAR-файл , а затем нажмите кнопку "ОК". Этот параметр создает один JAR-файл со всеми зависимостями.
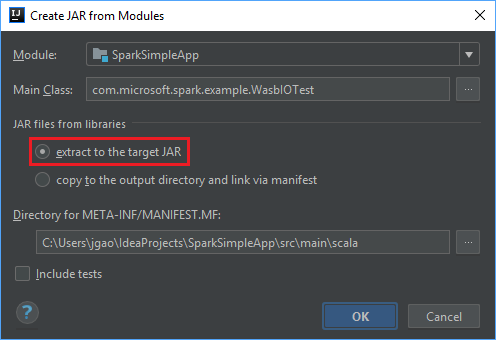
На вкладке "Макет выходных данных " перечислены все jar-файлы, включенные в проект Maven. Вы можете выбрать и удалить те, от которых приложение Scala не имеет прямой зависимости. Для приложения, которое вы создаете здесь, вы можете удалить все, кроме последнего (выходные данные компиляции SparkSimpleApp). Выберите jars для удаления и выберите отрицательный символ -.

Убедитесь, что установлен флажок "Включить в сборку проекта ". Этот параметр гарантирует, что JAR-файл создается каждый раз при создании или обновлении проекта. Выберите Применить, а затем ОК.
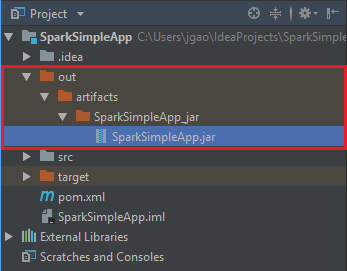
Чтобы создать JAR-файл, перейдите в Сборка>Артефакты сборки>Сборка. Проект будет компилироваться около 30 секунд. Выходной jar-файл создается в папке \out\artifacts.
Запуск приложения в кластере Apache Spark
Для запуска приложения в кластере можно использовать следующие подходы:
Скопируйте jar-файл приложения в blob-объект хранилища Azure, связанный с кластером. Для этого можно использовать AzCopy, служебную программу командной строки. Существует множество других клиентов, которые можно использовать для отправки данных. Дополнительные сведения см. в разделе "Отправка данных для заданий Apache Hadoop" в HDInsight.
Используйте Apache Livy для удаленной отправки задания приложения в кластер Spark. Кластеры Spark в HDInsight включают Livy, предоставляющий конечные точки REST для удалённой отправки заданий Spark. Дополнительные сведения см. в статье "Отправка заданий Apache Spark удаленно с помощью Apache Livy с кластерами Spark в HDInsight".
Очистка ресурсов
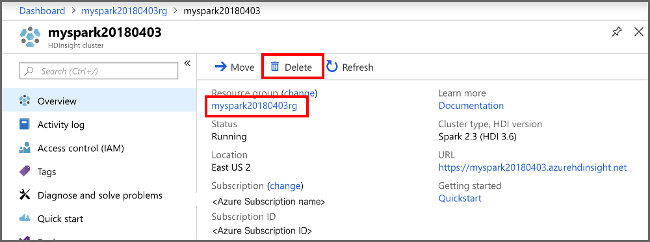
Если вы не собираетесь использовать это приложение в дальнейшем, удалите созданный кластер, сделав следующее:
Войдите на портал Azure.
В поле Поиск в верхней части страницы введите HDInsight.
Выберите Кластеры HDInsight в разделе Службы.
В списке кластеров HDInsight, который отобразится, выберите ... рядом с кластером, созданным для этого учебного пособия.
Выберите команду Удалить. Выберите Да.
Следующий шаг
Из этой статьи вы узнали, как создать приложение Apache Spark scala. Перейдите к следующей статье, чтобы узнать, как запустить это приложение в кластере HDInsight Spark с помощью Livy.