Повышение производительности рабочих нагрузок Apache Spark с помощью службы IO Cache для Azure HDInsight
Примечание.
- Кэш операций ввода-вывода поддерживается до Spark 2.3 и не будет поддерживаться в Spark 2.4 (HDInsight 4.0) и Spark 3.1.2 (HDInsight 5.0)
IO Cache — это служба кэширования данных для Azure HDInsight, который повышает производительность заданий Apache Spark. IO Cache также поддерживает рабочие нагрузки Apache Tez и Apache Hive, которые могут выполняться в кластерах Apache Spark. IO Cache использует компонент кэширования с открытым исходным кодом RubiX. Локальный дисковый кэш RubiX предназначен для использования с модулями аналитики больших данных, которые получают данные из систем облачного хранения. RubiX выделяется в ряду систем кэширования, поскольку использует для хранения данных не оперативную память, а твердотельные накопители (SSD). Служба IO Cache запускает серверы метаданных RubiX на каждом рабочем узле кластера и управляет ими. Она также настраивает прозрачное использование кэша RubiX для всех служб кластера.
Большинство твердотельных накопителей обеспечивают пропускную способность более 1 ГБ в секунду. Такая пропускная способность в сочетании с файловым кэшем в памяти, который поддерживает операционная система, обеспечивает возможность загружать модули обработки для вычисления больших данных, например Apache Spark. Оперативная память остается доступной Apache Spark для обработки задач с высокой нагрузкой на память, например процессов изменения порядка элементов. Эксклюзивное использование оперативной памяти позволяет Apache Spark добиться оптимального использования ресурсов.
Примечание.
В настоящее время IO Cache использует RubiX в качестве компонента кэширования, но в будущих версиях службы это может измениться. Используйте интерфейсы IO Cache, не создавая никаких прямых зависимостей от реализации RubiX. В настоящее время служба IO Cache поддерживается только для хранилища больших двоичных объектов Azure.
Преимущества IO Cache для Azure HDInsight
Использование IO Cache повышает производительность заданий, которые считывают данные из хранилища BLOB-объектов Azure.
Вам не придется вносить никаких изменений в задания Spark, чтобы заметить повышение производительности от использования IO Cache. При отключенной службе IO Cache этот код Spark считывает данные напрямую из удаленного хранилища BLOB-объектов Azure: spark.read.load('wasbs:///myfolder/data.parquet').count(). При включенной службе IO Cache эта же строка кода считывает данные через IO Cache. В дальнейшем данные уже считываются локально с твердотельного накопителя. Рабочие узлы в кластере HDInsight оснащаются локально подключенными выделенными твердотельными накопителями. IO Cache для HDInsight использует эти локальные твердотельные накопители для кэширования, обеспечивая минимально возможный уровень задержки и повышая пропускную способность.
Начало работы
IO Cache для Azure HDInsight по умолчанию отключен в предварительной версии. Служба IO Cache доступна в кластерах Azure HDInsight 3.6 и более поздних версий с Apache Spark 2.3. Чтобы активировать службу IO Cache в HDInsight 4.0, выполните следующие действия.
В веб-браузере перейдите на страницу
https://CLUSTERNAME.azurehdinsight.net, гдеCLUSTERNAME— это имя вашего кластера.Выберите службу IO Cache в левой части страницы.
Выберите Действия (Действия службы в HDI 3.6) и Активировать.
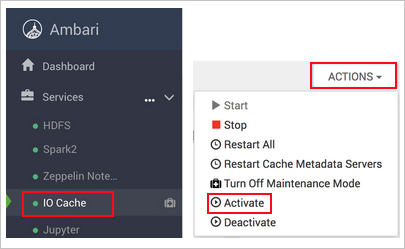
Подтвердите перезапуск всех затрагиваемых служб в кластере.
Примечание.
Несмотря на значение индикатора выполнения, фактически IO Cache активируется только после перезапуска всех затрагиваемых служб.
Устранение неполадок
После включения IO Cache при выполнении заданий Spark могут возникать ошибки отсутствия места на диске. Эти ошибки связаны с тем, что Spark также использует место на локальном диске для хранения данных во время операций перетасовки. Может случиться так, что после включения IO Cache на твердотельном накопителе закончится свободное место для Spark. По умолчанию IO Cache использует половину от общего объема твердотельного накопителя. В Ambari можно настроить параметры использования места на диске для IO Cache. Если вы столкнетесь с ошибками отсутствия места на диске, сократите объем памяти на твердотельном накопителе, используемый для IO Cache, и перезапустите службу. Чтобы изменить настройки пространства для IO Cache, выполните следующие действия:
В Apache Ambari выберите службу HDFS слева.
Выберите вкладки Configs (Конфигурации) и Advanced (Дополнительно).
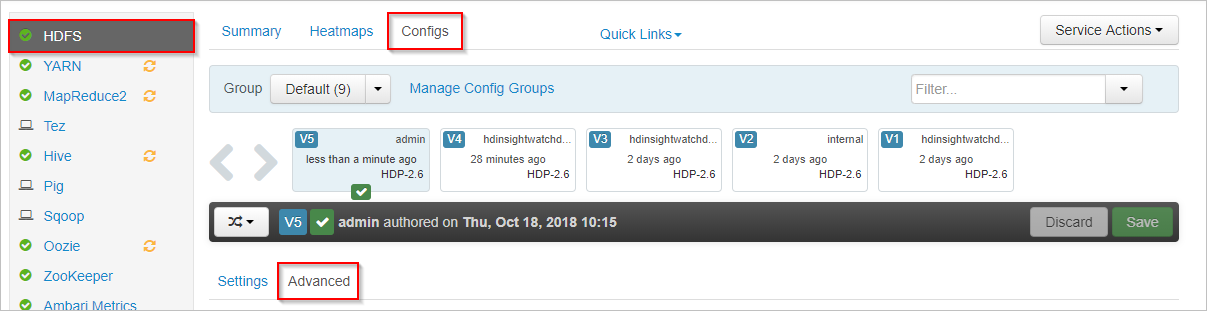
Прокрутите вниз и разверните область Custom core-site (Пользовательский основной сайт).
Найдите свойство hadoop.cache.data.fullness.percentage.
Измените значение в этом поле.
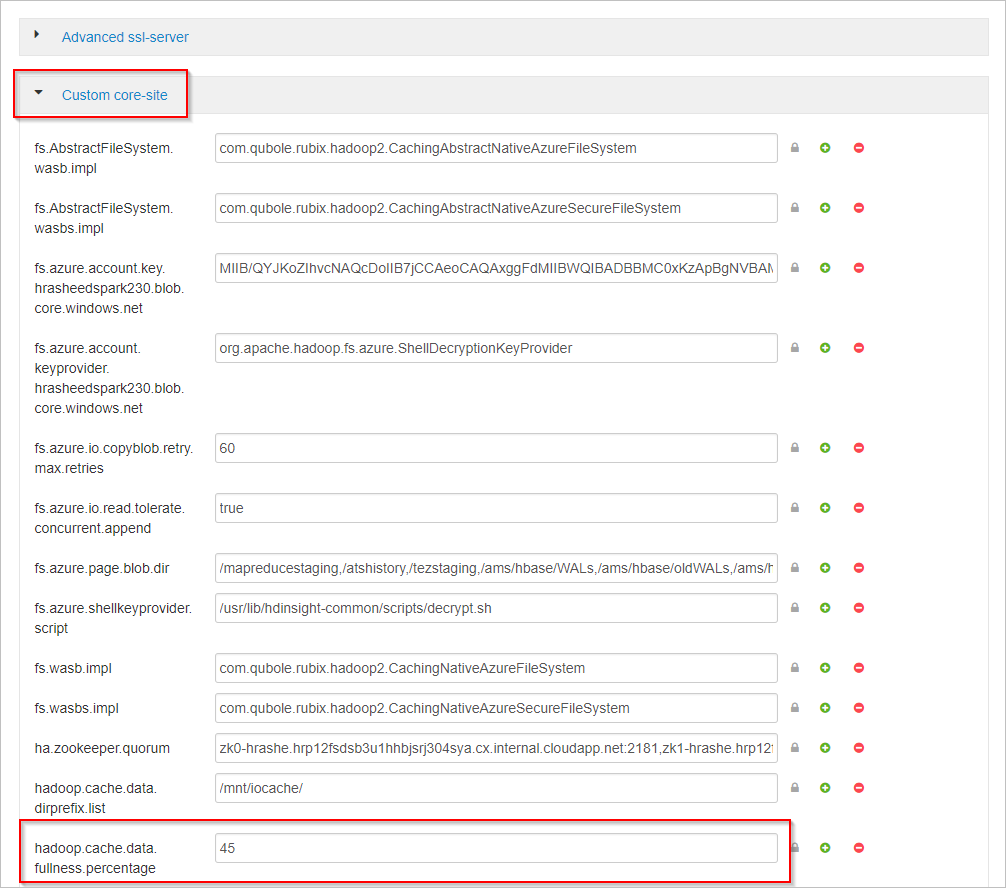
Выберите Сохранить в правом верхнем углу.
Выберите Restart (Перезапустить) >Restart All Affected (Перезапустить все затрагиваемые).

Щелкните Confirm Restart All (Подтвердить перезапуск всех).
Если это не поможет, отключите службу IO Cache.
Next Steps
Дополнительная информация об IO Cache, в том числе о сравнительных тестах производительности, приведена в этой записи блога
Обратная связь
Ожидается в ближайшее время: в течение 2024 года мы постепенно откажемся от GitHub Issues как механизма обратной связи для контента и заменим его новой системой обратной связи. Дополнительные сведения см. в разделе https://aka.ms/ContentUserFeedback.
Отправить и просмотреть отзыв по