Примечание
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
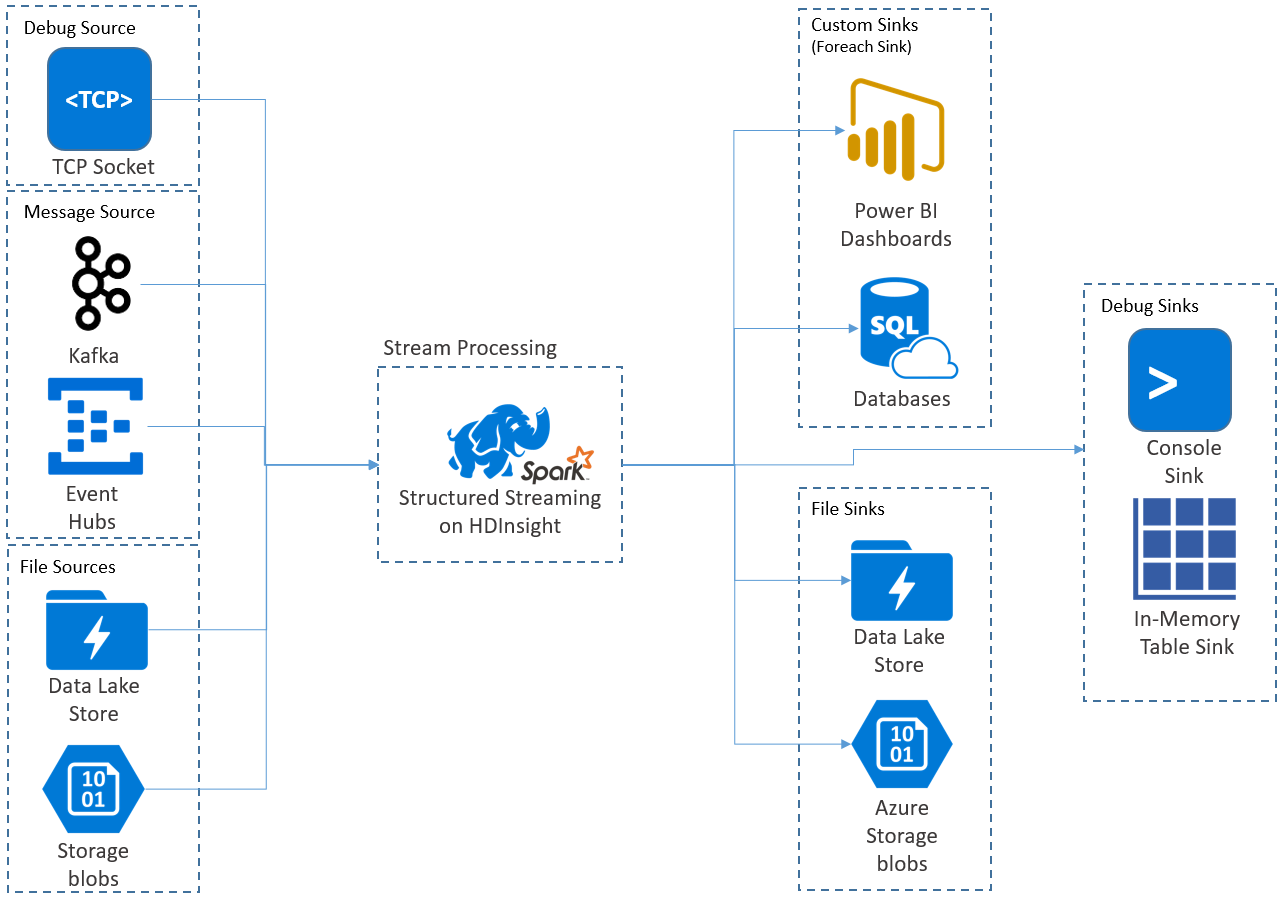
Структурированная потоковая передача Apache Spark дает возможность реализовывать масштабируемые отказоустойчивые приложения с высокой пропускной способностью для обработки потоков данных. Структурированная потоковая передача выполняется на базе ядра Spark SQL и улучшает конструкции из кадров и наборов данных Spark SQL, поэтому вы можете писать запросы потоковой передачи так же, как и пакетные запросы.
Приложения структурированной потоковой передачи выполняются в кластерах HDInsight Spark и подключаются к данным потоковой передачи из Apache Kafka, сокета TCP (для целей отладки), службы хранилища Azure или Azure Data Lake Storage. Последние два варианта, которые полагаются на внешние службы хранения данных, позволяют отслеживать добавление новых файлов в хранилище и обрабатывать их содержимое, как если бы они были потоковыми.
При структурированной потоковой передаче создается долго выполняющийся запрос, в рамках которого ко входным данным применяются такие операции, как выбор, проецирование, агрегация, разграничение по временным окнам и объединение потокового кадра данных с запрашиваемыми кадрами данных. Затем результаты выводятся в хранилище файлов (Azure Storage Blob или Data Lake Storage) или в любое хранилище данных с использованием специального кода (например, базы данных SQL или Power BI). Кроме того, при структурированной потоковой передаче данные выводятся на консоль для отладки в локальной среде и в таблицу в памяти, чтобы вы могли видеть данные, созданные для отладки в HDInsight.
Примечание.
Структурированная потоковая обработка данных Spark заменяет потоковую обработку данных Spark (DStreams). В дальнейшем для структурированной потоковой передачи планируется усовершенствование и обслуживание, а DStreams будут находиться только в режиме обслуживания. Структурированная потоковая передача в настоящее время не является такой полной по функциям, как DStreams, для источников и приемников, которые она поддерживает без дополнительной настройки. Поэтому проанализируйте ваши требования, чтобы выбрать подходящий вариант потоковой обработки Spark.
Потоки как таблицы
Структурированная потоковая передача Spark представляет поток данных в виде таблицы, которая является неограниченной по глубине, то есть таблица продолжает увеличиваться по мере поступления новых данных. Эта таблица входных данных непрерывно обрабатывается с помощью долго выполняющегося запроса, а результаты обработки записываются в выходную таблицу:

В структурированной потоковой передаче данные передаются в систему и сразу же поступают во входную таблицу. Вы пишете запросы, используя API DataFrame и Dataset, для выполнения операций над этой входной таблицей. Выходные данные запроса поступают в другую таблицу — таблицу результатов. В таблице результатов содержатся результаты запроса, из которых извлекаются данные для отправки во внешнее хранилище, например реляционную базу данных. С помощью интервала триггера задается расписание для обработки данных во входной таблице. По умолчанию интервал триггера равен нулю, поэтому структурированная потоковая передача пытается обрабатывать данные по мере их поступления. На практике это означает, что как только структурированная потоковая передача завершает обработку выполнения предыдущего запроса, она запускает следующую обработку новых полученных данных. Можно настроить триггер на запуск через определенные интервалы, чтобы потоковые данные обрабатывались в пакетах по времени.
Данные в таблице результатов можно обновлять каждый раз, когда поступают новые данные, благодаря чему таблица будет включать все выходные данные с момента отправки запроса потоковой передачи (полный режим), или же таблица может содержать только новые данные, поступившие после последней обработки запроса (режим добавления).
Режим добавления
В режиме добавления в таблице результатов содержатся только записи, добавленные после последнего выполнения запроса, и только они записываются во внешнее хранилище. Например, самый простой запрос просто копирует все данные из таблицы входных данных в таблицу результатов без изменений. Каждый раз, когда интервал триггера истекает, новые данные обрабатываются, а строки, представляющие эти новые данные, отображаются в таблице результатов.
Рассмотрим сценарий, где выполняется обработка телеметрии датчиков температуры, например термостата. Предположим, что первый триггер обработал одно событие в 00:01 для устройства 1 с показателем температуры 95 градусов. При первом триггере запроса в таблице результатов появляется только строка со временем 00:01. В 00:02, когда поступает другое событие, единственной новой строкой является строка со временем 00:02, поэтому таблица результатов будет содержать только эту одну строку.
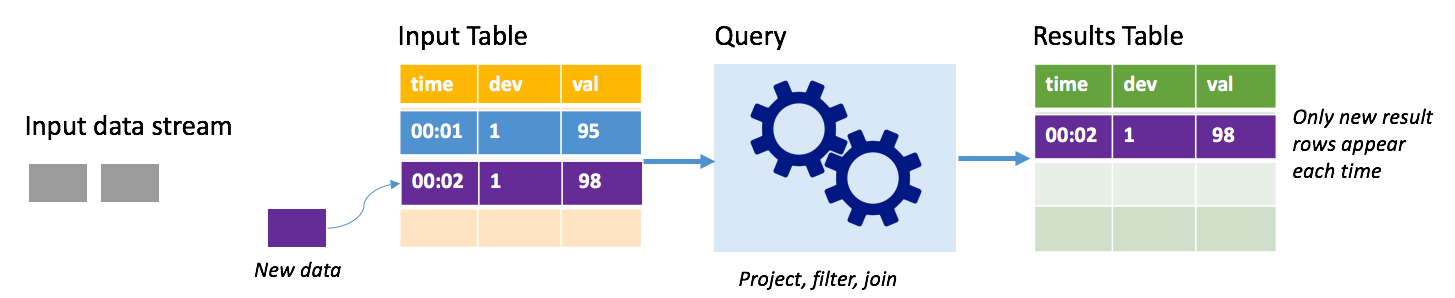
При использовании режима добавления в запросе будут применяться проекции (выбор нужных столбцов), фильтрация (выбор только строк, соответствующих определенным условиям) или объединение (дополнение данных данными из статической таблицы поиска). Режим дополнения позволяет отправлять только нужные новые данные во внешнее хранилище.
Полный режим
Рассмотрим тот же сценарий с применением полного режима. В полном режиме вся таблица выходных данных обновляется при каждом триггере, поэтому она включает данные не только из последнего выполнения триггера, а из всех выполнений. Полный режим можно использовать для копирования данных из таблицы входных данных без изменений в таблицу результатов. При каждом запуске новые строки результатов появляются вместе со всеми предыдущими строками. Таким образом в таблице результатов будут сохраняться все данные, собранные с момента начала запроса, из-за чего в конце концов возникнет нехватка памяти. Полный режим предназначен для использования со статистическими запросами, которые обобщают входящие данные определенным образом, поэтому при каждом триггере таблица результатов обновляется с учетом новой сводки.
Предположим, что данные за пять секунд уже обработаны, теперь необходимо обработать данные за шестую секунду. В таблице входных данных есть события для времени 00:01 и времени 00:03. Рассматриваемый пример запроса предоставляет среднюю температуру устройства каждые пять секунд. В реализации этого запроса применяется статистическое выражение, которое принимает все значения, которые попадают в каждое 5-секундное окно, усредняет температуру и создает строку для средней температуры за этот интервал. По завершении первых 5 секунд есть два кортежа: (00:01, 1, 95) и (00:03, 1, 98). Итак, для окна 00:00–00:05 агрегация создает кортеж со средней температурой 96,5 градуса. В следующем 5-секундном окне в 00:06 имеется только одна точка данных, поэтому средняя температура составляет 98 градусов. При использовании полного режима в 00:10 таблица результатов имеет строки для обоих окон (00: 00–00: 05 и 00:05–00:10), потому что запрос выводит все объединенные строки, а не только новые. Поэтому таблица результатов продолжает увеличиваться по мере добавления новых окон.
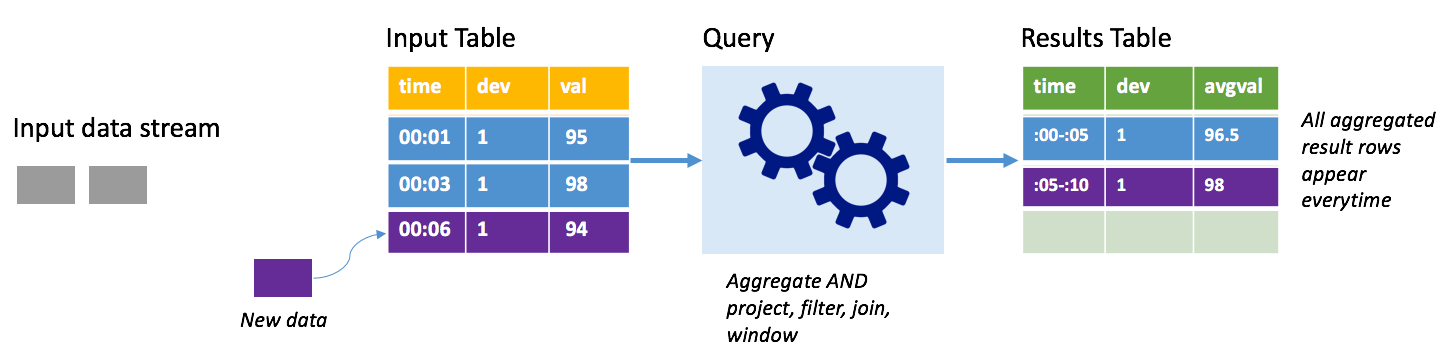
Не все запросы при использовании полного режима приведут к тому, что таблица будет расти без ограничений. Предположим, что в предыдущем примере вместо усреднения температуры по временному окну выполняется усреднение по идентификатору устройства. Таблица результатов содержит фиксированное количество строк (по одной на устройство) со средней температурой для устройства по всем полученным от него точкам данных. По мере получения новых температур таблица результатов обновляется. Таким образом в ней всегда содержатся актуальные средние значения.
Компоненты приложения структурированной потоковой передачи Spark
Простой пример запроса может суммировать показания температуры по часовым окнам. В этом случае данные хранятся в JSON-файлах в службе хранилища Azure (в качестве хранилища по умолчанию кластера HDInsight):
{"time":1469501107,"temp":"95"}
{"time":1469501147,"temp":"95"}
{"time":1469501202,"temp":"95"}
{"time":1469501219,"temp":"95"}
{"time":1469501225,"temp":"95"}
Эти JSON-файлы хранятся во вложенной папке temps в контейнере кластера HDInsight.
Определение источника входных данных
Сначала настройте кадр данных, который описывает источник данных, и задайте параметры, необходимые этому источнику. Этот пример базируется на JSON-файлах в Azure Storage и применяет к ним схему во время чтения.
import org.apache.spark.sql.types._
import org.apache.spark.sql.functions._
//Cluster-local path to the folder containing the JSON files
val inputPath = "/temps/"
//Define the schema of the JSON files as having the "time" of type TimeStamp and the "temp" field of type String
val jsonSchema = new StructType().add("time", TimestampType).add("temp", StringType)
//Create a Streaming DataFrame by calling readStream and configuring it with the schema and path
val streamingInputDF = spark.readStream.schema(jsonSchema).json(inputPath)
Примените запрос
Затем примените запрос, который содержит нужные операции к потоковому кадру данных. В этом случае агрегация группирует все строки в 1-часовые окна, а затем вычисляет минимальное, среднее и максимальное значение температуры в этом 1-часовом окне.
val streamingAggDF = streamingInputDF.groupBy(window($"time", "1 hour")).agg(min($"temp"), avg($"temp"), max($"temp"))
Определение приемника выходных данных
Затем определите место назначения для строк, добавляемых в таблицу результатов в каждом интервале триггера. Этот пример выводит все строки в таблицу в памяти temps, которую можно позже запросить с помощью SparkSQL. Полный режим выходных данных гарантирует, что каждый раз выводятся все строки для всех окон.
val streamingOutDF = streamingAggDF.writeStream.format("memory").queryName("temps").outputMode("complete")
Запуск запроса
Запустите запрос потоковой передачи и продолжайте его выполнение, пока не будет получен сигнал завершения.
val query = streamingOutDF.start()
Просмотр результатов
Пока выполняется запрос, в том же сеансе SparkSession можно запустить запрос SparkSQL к таблице temps, где хранятся результаты запроса.
select * from temps
Этот запрос выдает результаты наподобие следующих:
| окно | мин(temp) | avg(temp) | max(temp) |
|---|---|---|---|
| {u'start': u'2016-07-26T02:00:00.000Z', u'end'... | 95 | 95.231579 | 99 |
| {u'start': u'2016-07-26T03:00:00.000Z', u'end'... | 95 | 96.023048 | 99 |
| {u'start': u'2016-07-26T04:00:00.000Z', u'end'... | 95 | 96.797133 | 99 |
| {u'start': u'2016-07-26T05:00:00.000Z', u'end'... | 95 | 96.984639 | 99 |
| {u'start': u'2016-07-26T06:00:00.000Z', u'end'... | 95 | 97.014749 | 99 |
| {u'start': u'2016-07-26T07:00:00.000Z', u'end'... | 95 | 96.980971 | 99 |
| {u'start': u'2016-07-26T08:00:00.000Z', u'end'... | 95 | 96.965997 | 99 |
Дополнительные сведения об интерфейсе API структурированной потоковой передачи Spark, а также источниках входных данных, операциях и приемниках выходных данных, которые он поддерживает, см. в руководстве по программированию структурированной потоковой передачи Apache Spark.
Контрольные точки и упреждающее протоколирование
Для обеспечения отказоустойчивости в структурированной потоковой передаче используются контрольные точки, чтобы гарантировать, что потоки обрабатываются непрерывно даже в случае сбоев узлов. В HDInsight Spark создает контрольные точки в долговременном хранилище, таком как Azure Storage или Data Lake Storage. Эти контрольные точки хранят ход выполнения запроса потоковой передачи. Кроме того, в структурированной потоковой передаче используется упреждающее протоколирование (WAL). В журнал WAL записываются принятые данные, которые были получены, но еще не обработаны запросом. Если происходит сбой и обработка перезапускается из WAL, любые события, полученные от источника, не теряются.
Развертывание приложений потоковой передачи Spark
Как правило, приложение потоковой передачи Spark создается локально в JAR-файле, а затем развертывается в Spark в HDInsight путем копирования JAR-файла в хранилище по умолчанию, подключенное к кластеру HDInsight. Можно запустить приложение с использованием интерфейсов REST API Apache Livy, к которым можно получить доступ в кластере с помощью операции POST. Текст операции POST содержит документ JSON, предоставляющий путь к JAR-файлу, имя класса, основной метод которого определяет и выполняет приложение потоковой передачи, а также (необязательно) требования к ресурсам задания (например, количество исполнителей, ядер и объем памяти) и настройки конфигурации, необходимые для кода приложения.
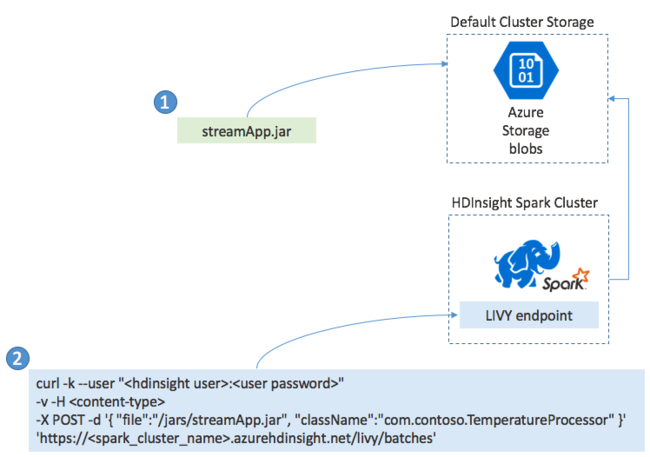
Состояние всех приложений можно также проверить с помощью запроса GET к конечной точке LIVY. Наконец, можно закрыть работающее приложение, выполнив запрос DELETE к конечной точке LIVY. Для получения сведений об API LIVY см. Удаленные задания с Apache LIVY.