Настройка политик Apache Ranger для Spark SQL в HDInsight с корпоративным пакетом безопасности
В этой статье описывается настройка политик Apache Ranger для Spark SQL с корпоративным пакетом безопасности в HDInsight.
Вы узнаете, как выполнять следующие задачи:
- Создайте политики Apache Ranger.
- Проверьте примененные политики Ranger.
- Примените рекомендации по настройке Apache Ranger для Spark SQL.
Необходимые компоненты
- Кластер Apache Spark в HDInsight версии 5.1 с корпоративным пакетом безопасности
Подключение в пользовательский интерфейс администратора Apache Ranger
В браузере подключитесь к пользовательскому интерфейсу администратора Ranger с помощью URL-адреса
https://ClusterName.azurehdinsight.net/Ranger/.Измените
ClusterNameимя кластера Spark.Войдите с помощью учетных данных администратора Microsoft Entra. Учетные данные администратора Microsoft Entra не совпадают с учетными данными кластера HDInsight или учетными данными узла Secure Shell (SSH) linux HDInsight.
Создание пользователей домена
Сведения о создании sparkuser пользователей домена см. в статье "Создание кластера HDInsight с помощью ESP". В рабочем сценарии пользователи домена приходят из клиента Microsoft Entra.
Создание политики Ranger
В этом разделе описано, как создать две политики Ranger:
- Политика доступа для доступа
hivesampletableиз Spark SQL - Политика маскирования для маскирования столбцов в
hivesampletable
Создание политики доступа Ranger
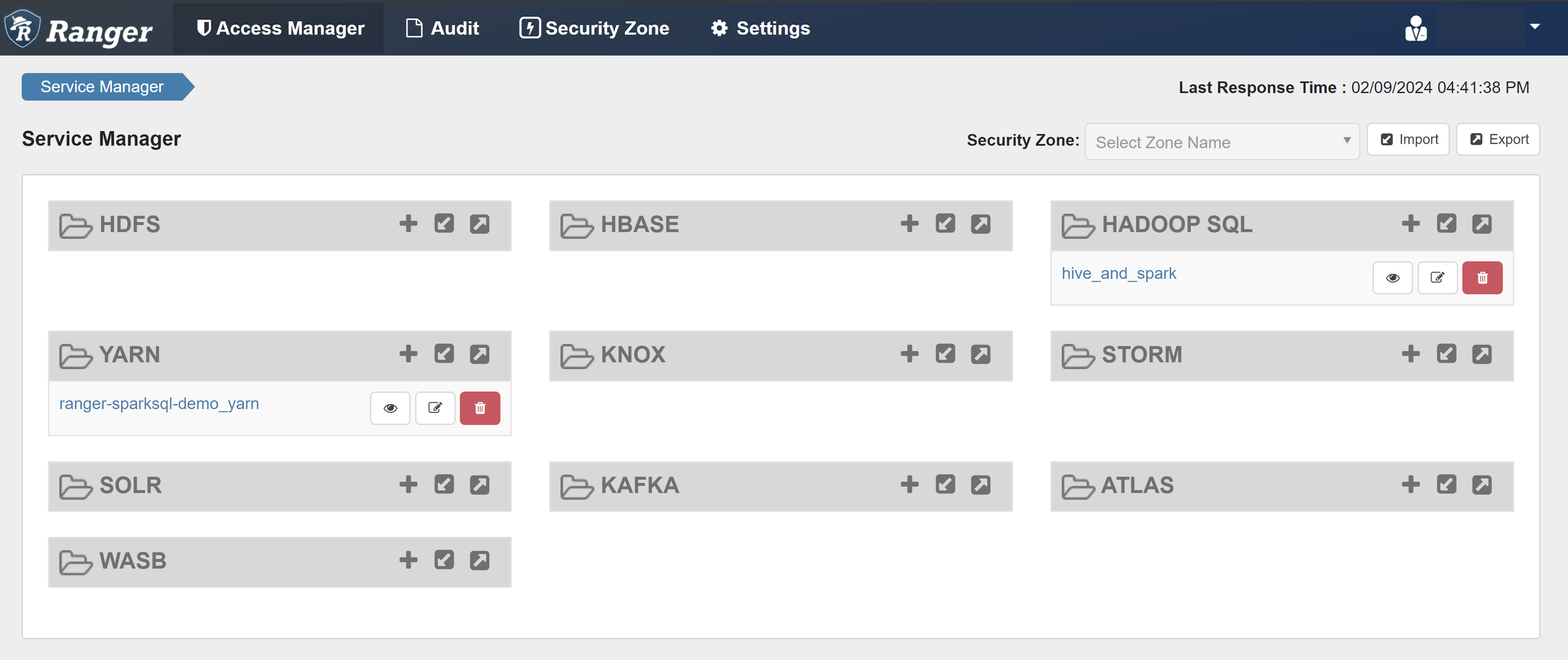
Откройте пользовательский интерфейс администратора Ranger.
В разделе HADOOP SQL выберите hive_and_spark.
На вкладке Access выберите "Добавить новую политику".
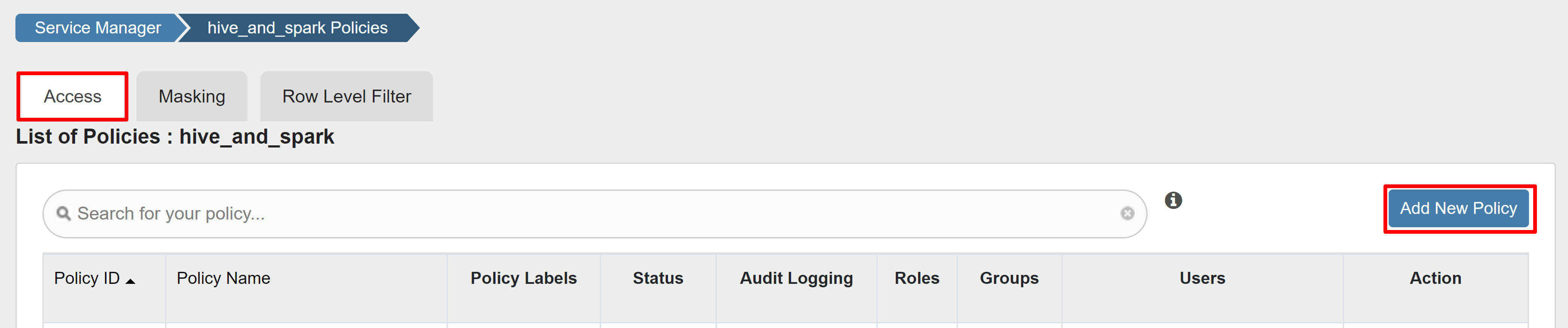
Введите следующие значения:
Свойство Значение Имя политики read-hivesampletable-all database default table hivesampletable столбец * Выбор пользователя sparkuserРазрешения select 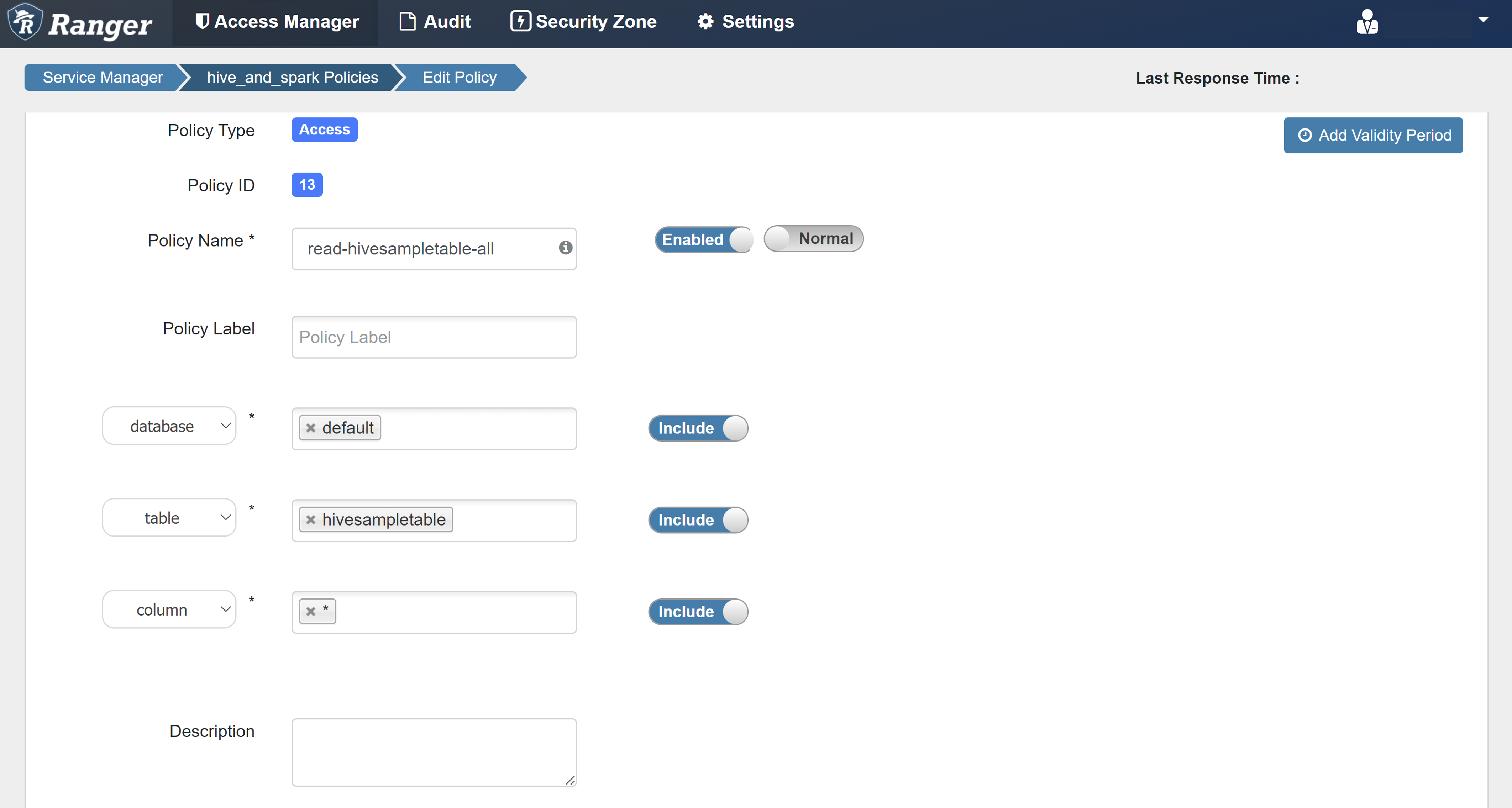
Если пользователь домена не заполняется автоматически для выбора пользователя, подождите несколько минут, пока Ranger будет синхронизироваться с идентификатором Microsoft Entra ID.
Щелкните Добавить, чтобы сохранить политику.
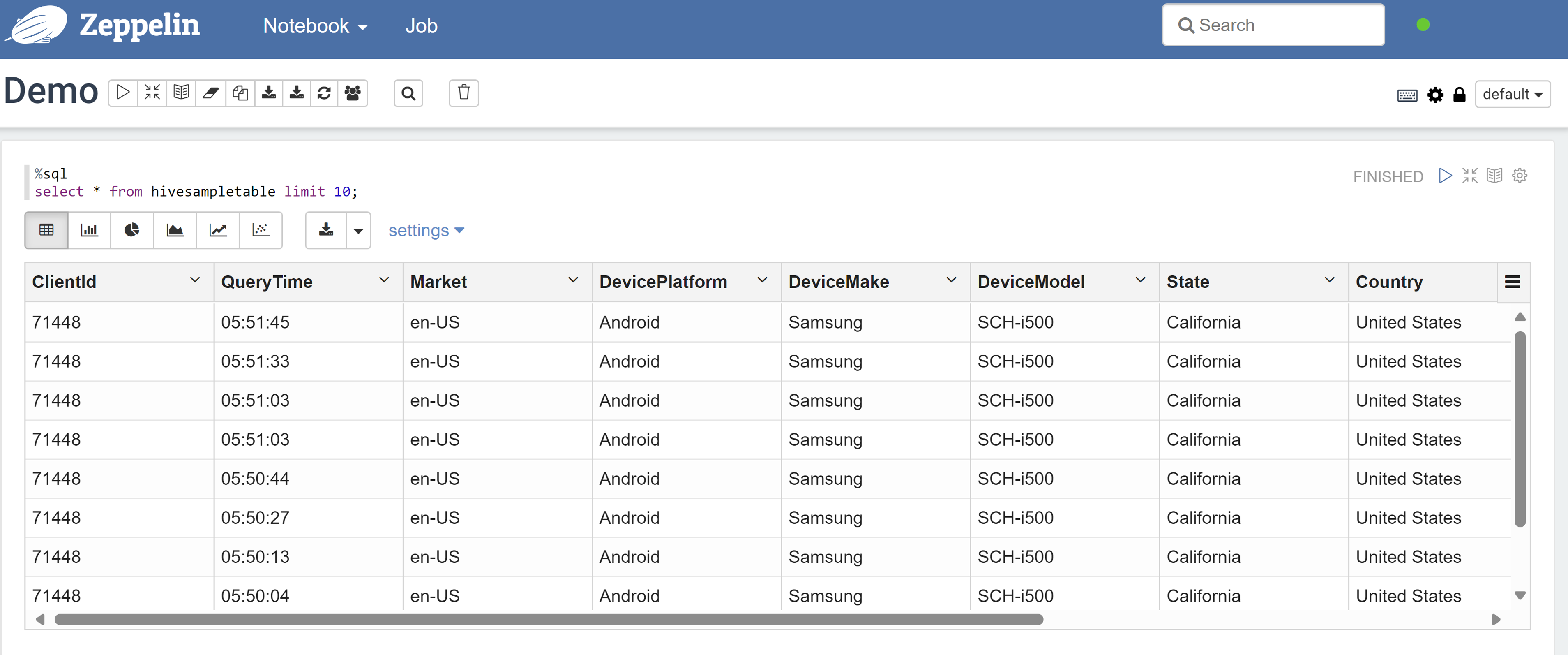
Откройте записную книжку Zeppelin и выполните следующую команду, чтобы проверить политику:
%sql select * from hivesampletable limit 10;Ниже приведен результат перед применением политики:
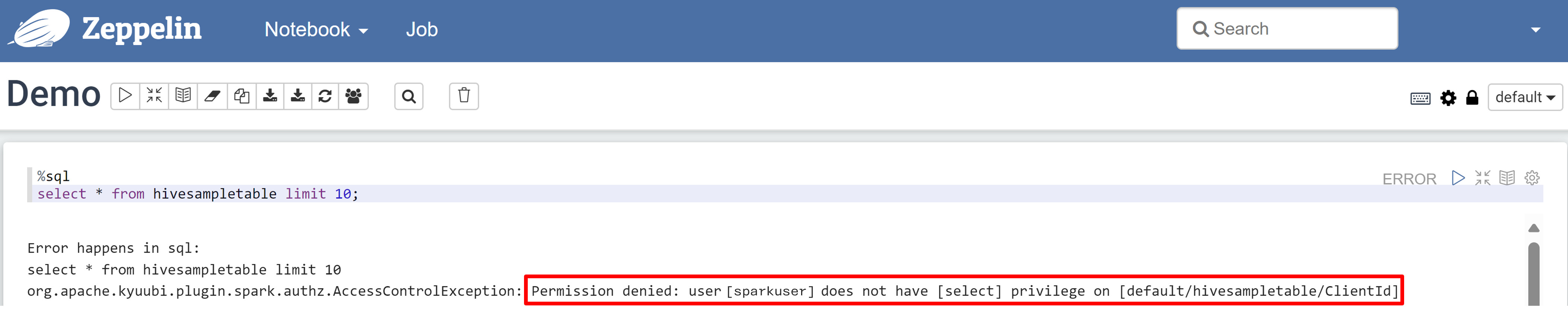
Ниже приведен результат после применения политики:




Создание политики маскирования Ranger
В следующем примере показано, как создать политику для маскирования столбца:
На вкладке "Маскирование" выберите "Добавить новую политику".
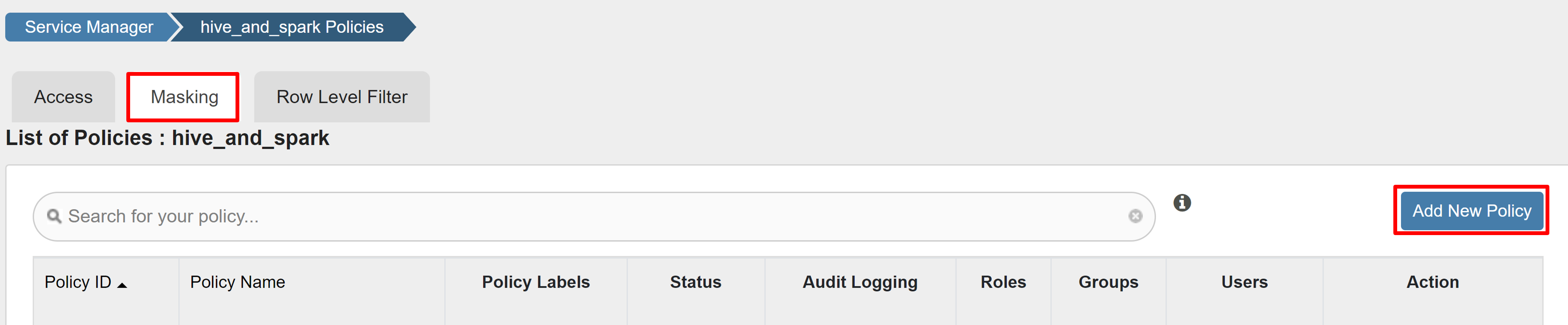
Введите следующие значения:
Свойство Значение Имя политики mask-hivesampletable База данных Hive default Таблица Hive hivesampletable Столбец куста devicemake Выбор пользователя sparkuserТипы доступа select Выбор параметра маскирования Hash 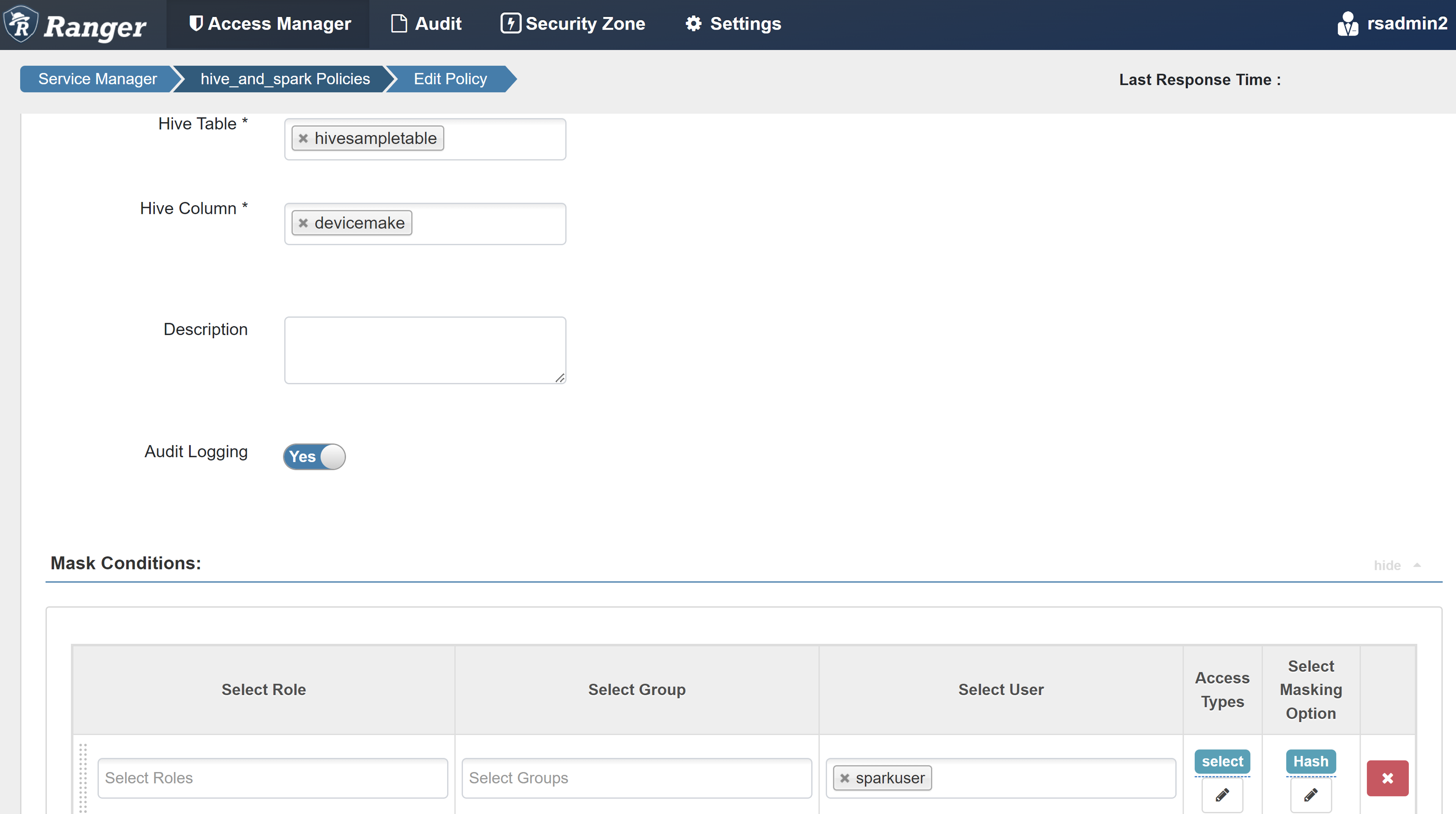
Нажмите кнопку "Сохранить", чтобы сохранить политику.
Откройте записную книжку Zeppelin и выполните следующую команду, чтобы проверить политику:
%sql select clientId, deviceMake from hivesampletable;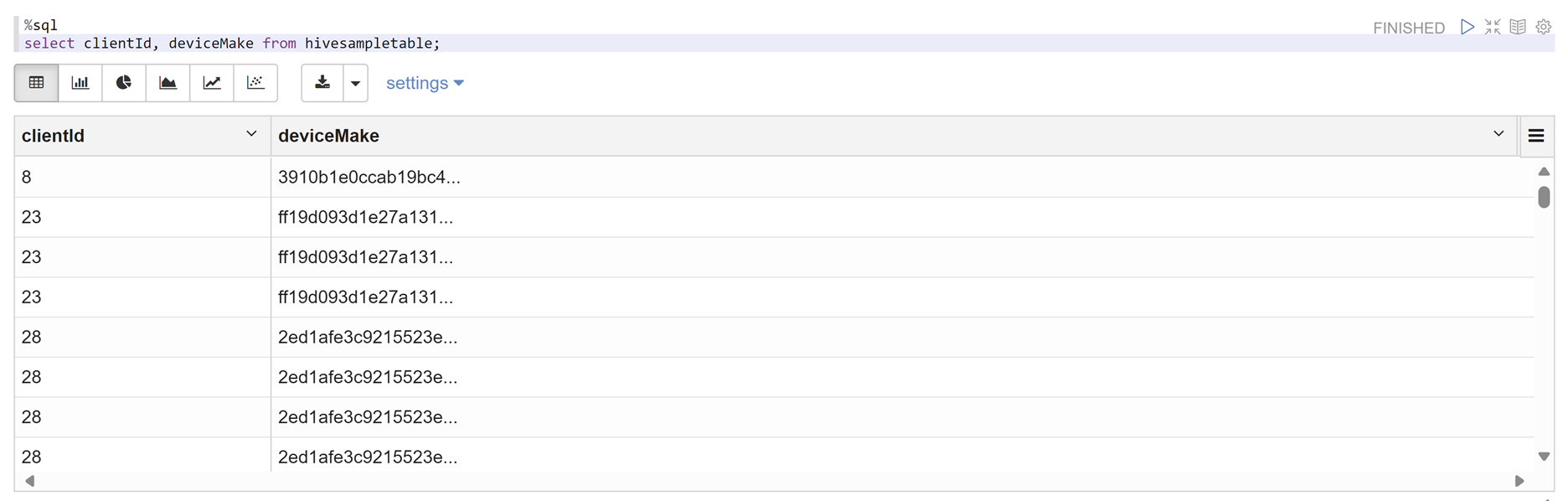



Примечание.
По умолчанию политики Для Hive и Spark SQL распространены в Ranger.
Применение рекомендаций по настройке Apache Ranger для Spark SQL
В следующих сценариях рассматриваются рекомендации по созданию кластера HDInsight 5.1 Spark с помощью новой базы данных Ranger и использования существующей базы данных Ranger.
Сценарий 1. Использование новой базы данных Ranger при создании кластера HDInsight 5.1 Spark
При использовании новой базы данных Ranger для создания кластера соответствующий репозиторий Ranger, содержащий политики Ranger для Hive и Spark, создается под именем hive_and_spark в службе Hadoop SQL в базе данных Ranger.

При изменении политик они применяются как к Hive, так и к Spark.
Рассмотрим следующие моменты:
Если у вас есть две базы данных хранилища метаданных с одинаковым именем, используемым для каталогов Hive (например, DB1) и Spark (например, DB1):
- Если Spark использует каталог Spark (
metastore.catalog.default=spark), политики применяются к базе данных DB1 каталога Spark. - Если Spark использует каталог Hive (
metastore.catalog.default=hive), политики применяются к базе данных DB1 каталога Hive.
С точки зрения Ranger, нет способа различать db1 каталогов Hive и Spark.
В таких случаях рекомендуется:
- Используйте каталог Hive для Hive и Spark.
- Сохраняйте разные имена баз данных, таблиц и столбцов для каталогов Hive и Spark, чтобы политики не применялись к базам данных в разных каталогах.
- Если Spark использует каталог Spark (
Если вы используете каталог Hive для Hive и Spark, рассмотрим следующий пример.
Предположим, что вы создаете таблицу с именем table1 через Hive с текущим пользователем xyz . Он создает файл распределенной файловой системы Hadoop (HDFS) с именем table1.db , владелец которого является пользователем xyz .
Теперь представьте, что пользователь abc используется для запуска сеанса Spark SQL. В этом сеансе пользователя abc, если вы пытаетесь написать что-либо в таблицу1, оно привязано к сбою, так как владелец таблицы является xyz.
В таком случае рекомендуется использовать того же пользователя в Hive и Spark SQL для обновления таблицы. Этот пользователь должен иметь достаточные привилегии для выполнения операций обновления.
Сценарий 2. Использование существующей базы данных Ranger (с существующими политиками) при создании кластера Spark HDInsight 5.1
При создании кластера HDInsight 5.1 с помощью существующей базы данных Ranger в этой базе данных создается новый репозиторий Ranger с именем нового кластера в этом формате: hive_and_spark.

Предположим, что у вас есть политики, определенные в репозитории Ranger, уже под именем oldclustername_hive в существующей базе данных Ranger в службе Hadoop SQL. Вы хотите предоставить общий доступ к тем же политикам в новом кластере HDInsight 5.1 Spark. Чтобы достичь этой цели, выполните следующие действия.
Примечание.
Пользователь, имеющий права администратора Ambari, может выполнять обновления конфигурации.
Откройте пользовательский интерфейс Ambari из нового кластера HDInsight 5.1.
Перейдите в службу Spark3 и перейдите к конфигурациям.
Откройте конфигурацию advanced ranger-spark-security .
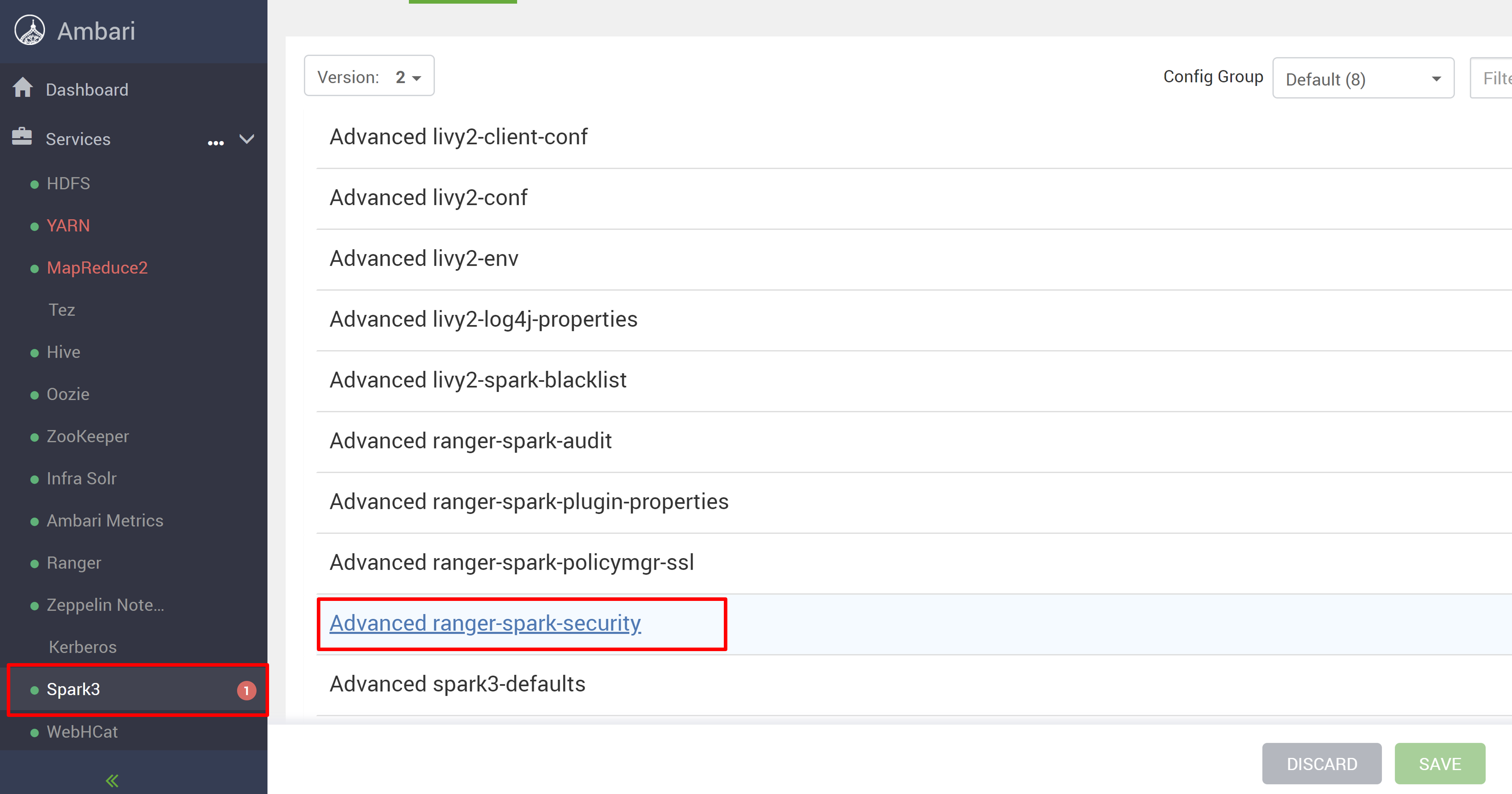
или можно также открыть эту конфигурацию в /etc/spark3/conf с помощью SSH.
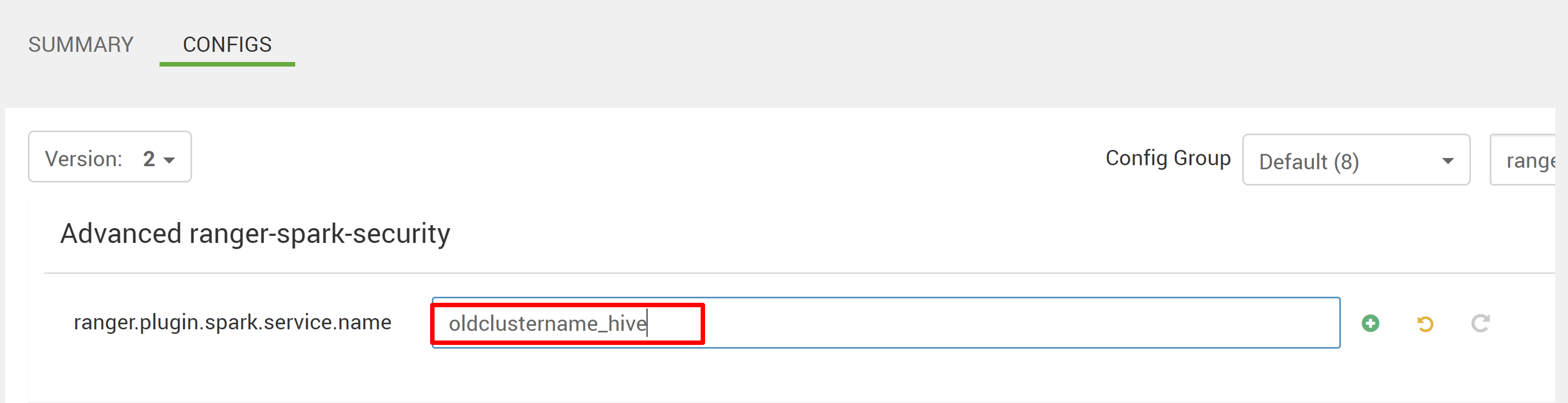
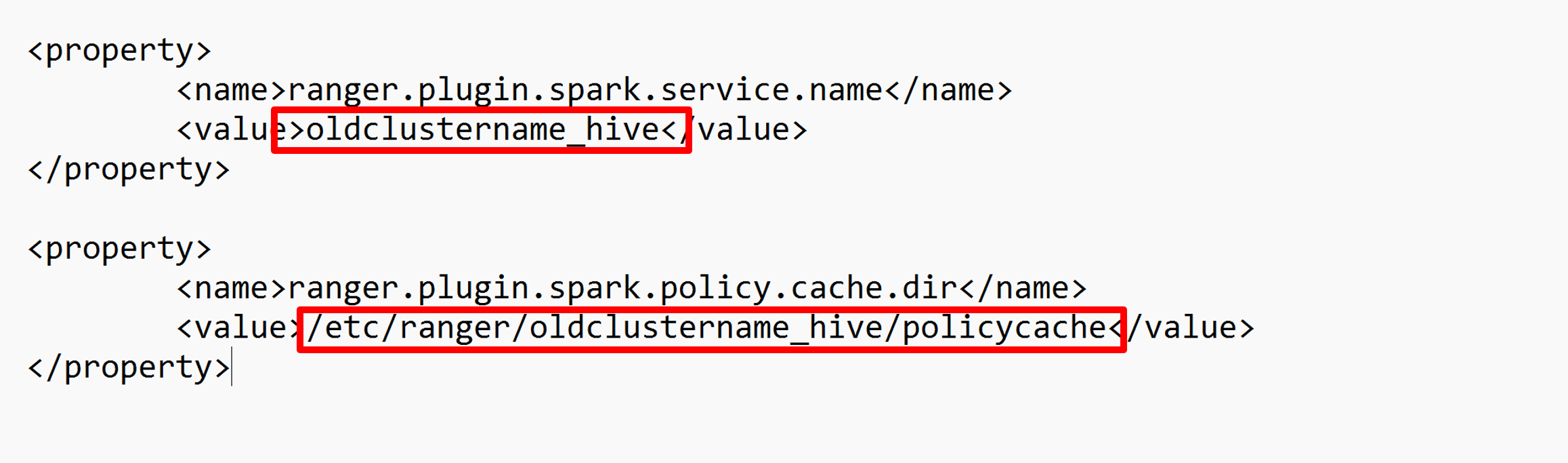
Измените две конфигурации (ranger.plugin.spark.service.name и ranger.plugin.spark.policy.cache.dir), чтобы указать на старый репозиторий политики oldclustername_hive, а затем сохранить конфигурации.
Ambari:
XML-файл:
Перезапустите службы Ranger и Spark из Ambari.
Откройте пользовательский интерфейс администратора Ranger и нажмите кнопку редактирования в службе HADOOP SQL .
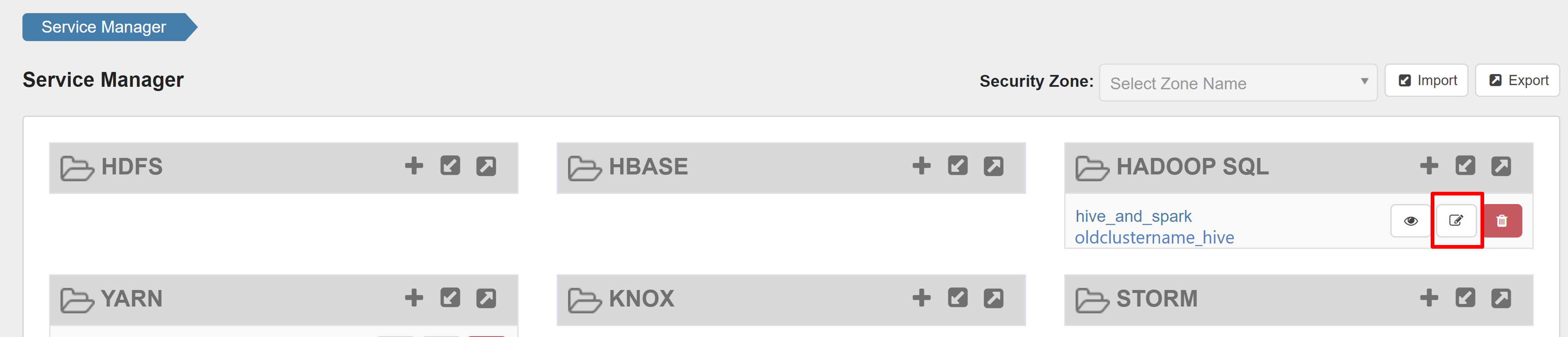
Для службы oldclustername_hive добавьте пользователя rangersparklookup в список policy.download.auth.users и tag.download.auth.users и нажмите кнопку "Сохранить".






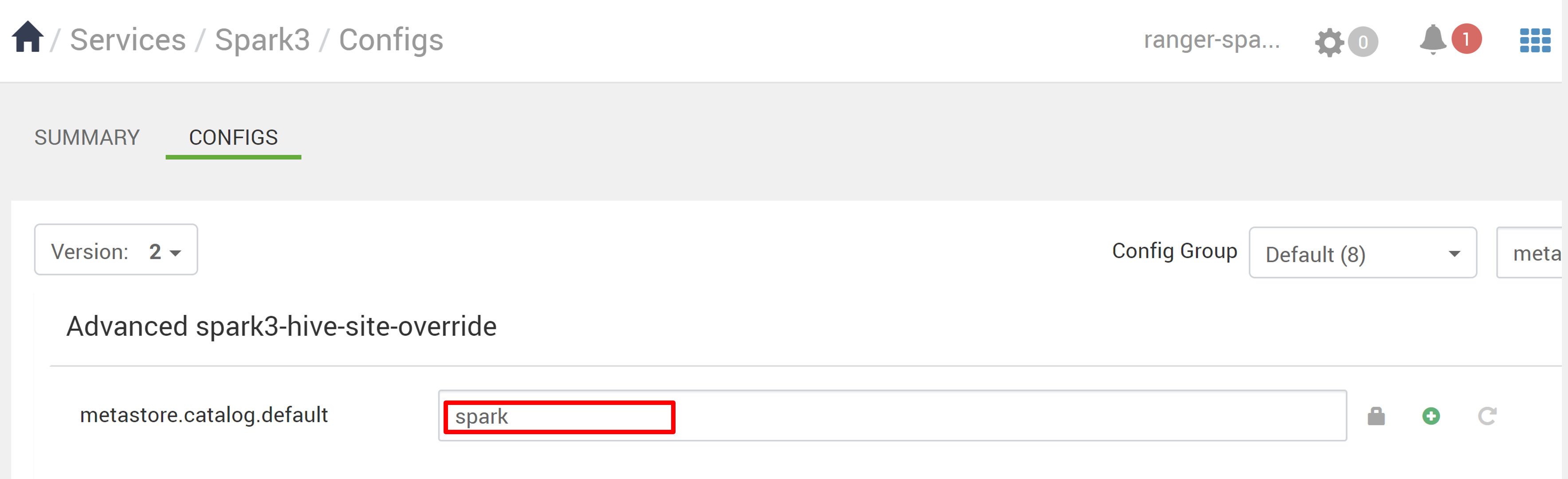
Политики применяются к базам данных в каталоге Spark. Если вы хотите получить доступ к базам данных в каталоге Hive:
В Ambari перейдите в конфигурации Spark3>.
Измените metastore.catalog.default с spark на hive.

Известные проблемы
- Интеграция Apache Ranger с Spark SQL не работает, если администратор Ranger не работает.
- В журналах аудита Ranger при наведении указателя мыши на столбец ресурсов невозможно отобразить весь запущенный запрос.
Обратная связь
Ожидается в ближайшее время: в течение 2024 года мы постепенно откажемся от GitHub Issues как механизма обратной связи для контента и заменим его новой системой обратной связи. Дополнительные сведения см. в разделе https://aka.ms/ContentUserFeedback.
Отправить и просмотреть отзыв по