Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Внимание
На этой странице содержатся инструкции по управлению компонентами Операций Интернета вещей Azure с помощью манифестов развертывания Kubernetes, который находится в предварительной версии. Эта функция предоставляется с несколькими ограничениями и не должна использоваться для рабочих нагрузок.
Юридические условия, применимые к функциям Azure, которые находятся в состоянии бета-версии, предварительной версии или иным образом еще не выпущены в общедоступной версии, см. на странице Дополнительные условия использования предварительных версий в Microsoft Azure.
Поток данных — это путь, который данные принимают из источника в место назначения с необязательными преобразованиями. Вы можете настроить поток данных, создав поток данных настраиваемый ресурс или используя веб-интерфейс интерфейса взаимодействия с операциями. Поток данных состоит из трех частей: источника, преобразования и назначения.

Чтобы определить источник и назначение, необходимо настроить конечные точки потока данных. Преобразование является необязательным и может включать такие операции, как обогащение данных, фильтрация данных и сопоставление данных с другим полем.
Внимание
Каждый поток данных должен иметь локальную конечную точку брокера MQTT в Azure IoT Operations по умолчанию в качестве источника или назначения.
Вы можете использовать опыт в операциях IoT в Azure для создания потока данных. Интерфейс операций предоставляет визуальный интерфейс для настройки потока данных. Вы также можете использовать Bicep для создания потока данных с помощью файла Bicep или использования Kubernetes для создания потока данных с помощью YAML-файла.
Продолжайте чтение, чтобы узнать, как настроить источник, преобразование и назначение.
Предварительные условия
Потоки данных можно развернуть сразу после того, как у вас есть экземпляр Azure IoT Operations, используя профиль потока данных по умолчанию и конечную точку. Однако может потребоваться настроить профили потока данных и конечные точки для настройки потока данных.
Профиль потока данных
Если для потоков данных не нужны разные параметры масштабирования, используйте профиль потока данных по умолчанию, предоставляемый операциями Интернета вещей Azure. Следует избегать связывания слишком большого количества потоков данных с одним профилем потока данных. Если у вас большое количество потоков данных, распределите их по нескольким профилям потока данных, чтобы снизить риск превышения ограничения размера конфигурации профиля потока данных 70.
Сведения о настройке нового профиля потока данных см. в разделе "Настройка профилей потока данных".
Конечные точки потока данных
Конечные точки потока данных необходимы для настройки источника и назначения для потока данных. Чтобы быстро приступить к работе, можно использовать конечную точку по умолчанию потока данных для локального брокера MQTT. Вы также можете создавать другие типы конечных точек потока данных, таких как Kafka, Центры событий, OpenTelemetry или Azure Data Lake Storage. Сведения о настройке каждой конечной точки потока данных см. в разделе "Настройка конечных точек потока данных".
Начало работы
После получения необходимых компонентов можно приступить к созданию потока данных.
Чтобы создать поток данных в рабочей среде, выберите Поток данных>.
Выберите имя заполнителя new-data-flow , чтобы задать свойства потока данных. Введите имя потока данных и выберите используемый профиль потока данных. Профиль потока данных по умолчанию выбирается по умолчанию. Дополнительные сведения о профилях потока данных см. в разделе "Настройка профиля потока данных".

Внимание
При создании потока данных можно выбрать только профиль потока данных. После создания потока данных невозможно изменить профиль потока данных. Если вы хотите изменить профиль потока данных существующего потока данных, удалите исходный поток данных и создайте новый с новым профилем потока данных.
Настройте исходную, преобразование и целевую конечную точку для потока данных, выбрав элементы на схеме потока данных.

Ознакомьтесь со следующими разделами, чтобы узнать, как настроить типы операций потока данных.
Источник
Чтобы настроить источник потока данных, укажите ссылку на конечную точку и список источников данных для конечной точки. Выберите один из следующих параметров в качестве источника потока данных.
Если конечная точка по умолчанию не используется в качестве источника, она должна использоваться в качестве назначения. Дополнительные сведения об использовании локальной конечной точки брокера MQTT см. в статье "Потоки данных" должны использовать локальную конечную точку брокера MQTT.
Вариант 1. Использование конечной точки брокера сообщений по умолчанию в качестве источника
В разделе "Исходные сведения" выберите брокер сообщений.

Введите следующие параметры для источника брокера сообщений:
Настройка Описание Конечная точка потока данных Выберите по умолчанию, чтобы использовать стандартную конечную точку брокера сообщений MQTT. Тема Фильтр раздела для подписки на входящие сообщения. Используйте Тему(ы)>Добавить строку, чтобы добавить несколько тем. Дополнительные сведения о разделах см. в разделе "Настройка MQTT" или "Kafka". Схема сообщений Схема, используемая для десериализации входящих сообщений. См. раздел "Указание схемы для десериализации данных". Выберите Применить.
Так как dataSources можно указать разделы MQTT или Kafka без изменения конфигурации конечной точки, можно повторно использовать конечную точку для нескольких потоков данных, даже если разделы отличаются. Дополнительные сведения см. в разделе "Настройка источников данных".
Вариант 2. Использование ресурса в качестве источника
Вы можете использовать ресурс в качестве источника для потока данных. Использование актива в качестве источника доступно только в интерфейсе операций.
В разделе "Исходные сведения" выберите "Ресурс".
Выберите ресурс, который вы хотите использовать в качестве исходной конечной точки.
Выберите Продолжить.
Отображается список точек данных для выбранного ресурса.

Выберите "Применить" , чтобы использовать ресурс в качестве исходной конечной точки.
При использовании ресурса в качестве источника определение ресурса используется для вывода схемы потока данных. Определение ресурса включает схему для точек данных ресурса. Дополнительные сведения см. в статье "Удаленное управление конфигурациями ресурсов".
После настройки данные с устройства поступают в поток данных через локальный брокер MQTT. Таким образом, при использовании ресурса в качестве источника поток данных использует локальную конечную точку брокера MQTT по умолчанию в качестве источника в действительности.
Вариант 3. Использование пользовательской конечной точки потока данных MQTT или Kafka в качестве источника
Если вы создали пользовательскую конечную точку потока данных MQTT или Kafka (например, для использования с сеткой событий или Центрами событий), ее можно использовать в качестве источника потока данных. Помните, что конечные точки типа хранилища, такие как Data Lake или Fabric OneLake, нельзя использовать в качестве источника.
В разделе "Исходные сведения" выберите брокер сообщений.
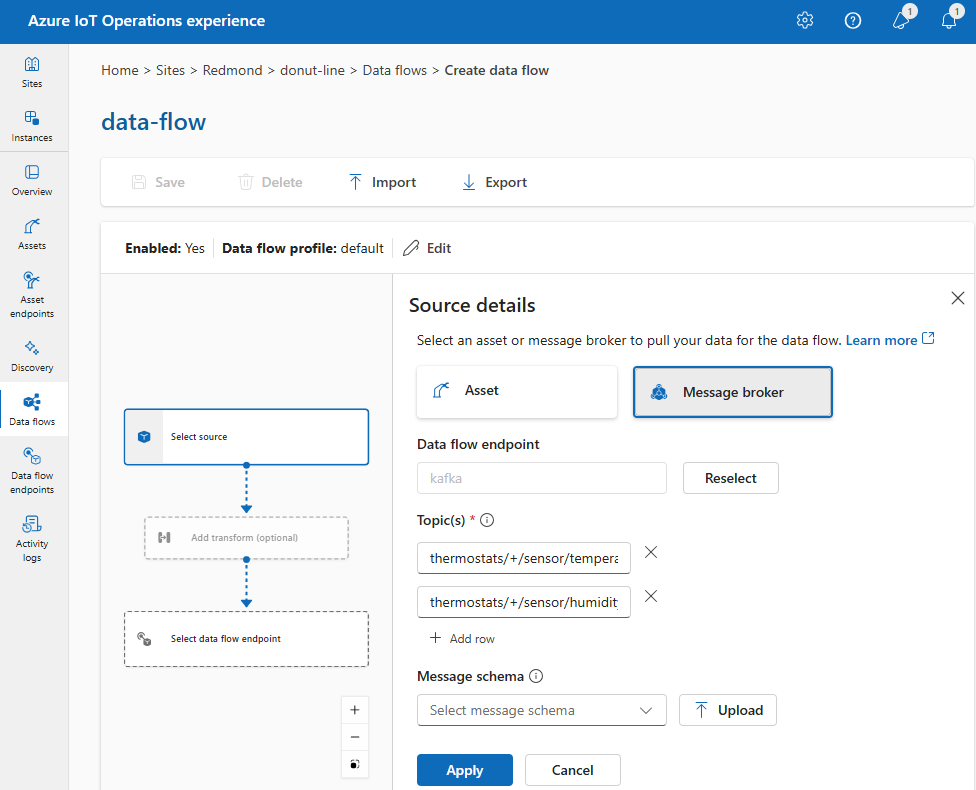
Введите следующие параметры для источника брокера сообщений:
Настройка Описание Конечная точка потока данных Нажмите кнопку повторного выбора , чтобы выбрать пользовательскую конечную точку потока данных MQTT или Kafka. Дополнительные сведения см. в разделе Настройка конечных точек потока данных MQTT или Настройка конечных точек потока данных Azure Event Hubs и Kafka. Тема Фильтр раздела для подписки на входящие сообщения. Используйте Тему(ы)>Добавить строку, чтобы добавить несколько тем. Дополнительные сведения о разделах см. в разделе "Настройка MQTT" или "Kafka". Схема сообщений Схема, используемая для десериализации входящих сообщений. См. раздел "Указание схемы для десериализации данных". Выберите Применить.
Настроить источники данных (топики MQTT или Kafka)
Можно указать несколько разделов MQTT или Kafka в источнике, не изменив конфигурацию конечной точки потока данных. Эта гибкость означает, что одна конечная точка может использоваться повторно в нескольких потоках данных, даже если разделы различаются. Дополнительные сведения см. в статье "Повторное использование конечных точек потока данных".
Темы MQTT
Если источником является конечная точка MQTT (включенная сетка событий), можно использовать фильтр раздела MQTT для подписки на входящие сообщения. Фильтр разделов может включать подстановочные знаки для подписки на несколько разделов. Например, thermostats/+/sensor/temperature/# подписывается на все сообщения датчика температуры из термостатов. Чтобы настроить фильтры раздела MQTT, выполните следующие действия.
В сведениях о источнике потока данных для операций выберите брокер сообщений, а затем используйте поле "Темы", чтобы указать фильтры разделов MQTT для подписки на входящие сообщения. Вы можете добавить несколько разделов MQTT, выбрав "Добавить строку " и введя новый раздел.
Общие подписки
Чтобы использовать общие подписки с источниками брокера сообщений, можно указать раздел общей подписки в виде $shared/<GROUP_NAME>/<TOPIC_FILTER>.
В данных о потоке операций о сведениях источника выберите Брокер сообщений и используйте поле "Тема", чтобы указать группу совместной подписки и тему.
Если число экземпляров в профиле потока данных больше одного, общая подписка автоматически включается для всех потоков данных, использующих источник брокера сообщений. В этом случае добавляется префикс $shared, и автоматически создаётся имя общей группы подписок. Например, если у вас есть профиль потока данных с числом экземпляров 3, а поток данных использует конечную точку брокера сообщений в качестве источника, настроенного с topic1 разделами, и topic2они автоматически преобразуются в общие подписки как $shared/<GENERATED_GROUP_NAME>/topic1 и $shared/<GENERATED_GROUP_NAME>/topic2.
Вы можете явно создать раздел с именем $shared/mygroup/topic в конфигурации. Однако явное добавление $shared раздела не рекомендуется, так как $shared префикс автоматически добавляется при необходимости. Потоки данных могут выполнять оптимизацию с именем группы, если она не задана. Например, $share не задано, и данные потоки могут работать только с именем раздела.
Внимание
Потоки данных, которые требуют общую подписку, когда количество экземпляров превышает один, особенно важны при использовании брокера MQTT Event Grid в качестве источника, так как он не поддерживает общие подписки. Чтобы избежать пропуска сообщений, задайте для экземпляра профиля потока данных значение один при использовании брокера MQTT Event Grid в качестве источника. Это происходит, когда поток данных выступает в роли подписчика и получает сообщения из облака.
Темы Kafka
Если источником является конечная точка Kafka (включая Event Hubs), укажите отдельные топики Kafka, на которые нужно подписаться для получения входящих сообщений. Подстановочные знаки не поддерживаются, поэтому необходимо указать каждый раздел статически.
Примечание.
При работе с узлами событий через конечную точку Kafka каждый отдельный узел событий в пространстве имен является темой Kafka. Например, если у вас есть пространство имен Центров событий с двумя концентраторами событий, thermostats и humidifiers, то можно указать каждый концентратор событий в качестве темы Kafka.
Чтобы настроить разделы Kafka, выполните следующие действия.
В данных об опыте операций Source details выберите Message broker, а затем используйте поле Топик, чтобы указать фильтр топика Kafka для подписки на входящие сообщения.
Примечание.
В опыте работы с операциями можно указать только один фильтр тем. Чтобы использовать несколько фильтров разделов, используйте Bicep или Kubernetes.
Указание исходной схемы
При использовании MQTT или Kafka в качестве источника можно указать схему для отображения списка точек данных в пользовательском веб-интерфейсе операций. Использование схемы для десериализации и проверки входящих сообщений в настоящее время не поддерживается.
Если источник является ресурсом, схема автоматически выводится из определения ресурса.
Совет
Чтобы создать схему из файла с образцом данных, используйте помощник Schema Gen.
Чтобы настроить схему, используемую для десериализации входящих сообщений из источника:
В операционном опыте потока данных Сведения об источнике, выберите брокер сообщений и используйте поле Схема сообщений, чтобы указать схему. Для отправки файла схемы можно использовать кнопку "Отправить ". Дополнительные сведения см. в статье "Общие сведения о схемах сообщений".
Дополнительные сведения см. в статье "Общие сведения о схемах сообщений".
Запрос сохраняемости диска
Сохраняемость диска запроса позволяет потокам данных сохранять состояние во время перезапуска. При включении этой функции граф восстанавливает состояние обработки при перезапуске подключенного брокера. Эта функция полезна для сценариев обработки с отслеживанием состояния, когда потеря промежуточных данных является проблемой. При включении сохраняемости диска запроса брокер сохраняет данные MQTT, такие как сообщения в очереди подписчиков, на диск. Этот подход гарантирует, что источник данных потока данных не теряет данные во время сбоя питания или перезапуска брокера. Брокер поддерживает оптимальную производительность, так как сохраняемость настраивается для каждого потока данных, поэтому только те потоки данных, которые нуждаются в сохраняемости, используют эту функцию.
Граф потока данных запрашивает эту сохраняемость во время подписки с помощью свойства пользователя MQTTv5. Эта функция работает только в том случае, если:
- Поток данных использует брокер MQTT или ресурс в качестве источника
- Брокер MQTT включил сохраняемость с динамическим режимом сохраняемости, заданным
Enabledдля типа данных, например очередей подписчиков
Эта конфигурация позволяет клиентам MQTT, таким как потоки данных, запрашивать сохраняемость дисков для своих подписок с помощью свойств пользователя MQTTv5. Дополнительные сведения о конфигурации сохраняемости брокера MQTT см. в разделе "Настройка сохраняемости брокера MQTT".
Параметр принимает Enabled или Disabled.
Disabled — это значение по умолчанию.
При создании или изменении потока данных выберите "Изменить", а затем нажмите кнопку "Да" рядом с сохраняемостью данных запроса.
Преобразование
Операция преобразования заключается в том, что перед отправкой данных в место назначения можно преобразовать данные из источника. Преобразования являются необязательными. Если вам не нужно вносить изменения в данные, не включайте операцию преобразования в конфигурацию потока данных. Несколько преобразований выполняются на различных стадиях вне зависимости от порядка, в котором они указаны в конфигурации. Порядок этапов всегда:
- Обогащение. Добавьте дополнительные данные в исходные данные, заданные набором данных и условием для сопоставления.
- Фильтр. Фильтрация данных на основе условия.
- Сопоставление, вычисление, переименование или добавление нового свойства: перемещение данных из одного поля в другое с необязательным преобразованием.
В этом разделе приведены общие сведения о преобразованиях потока данных. Дополнительные сведения см. в разделе "Сопоставление данных с помощью потоков данных", "Преобразование данных с помощью преобразований потоков данных" и "Обогащение данных" с помощью потоков данных.
В интерфейсе операций выберите "Добавить преобразование потока>данных" (необязательно).

Обогащение: добавление ссылочных данных
Чтобы обогатить данные, сначала добавьте ссылочный набор данных в операционное хранилище состояний Azure IoT . Набор данных используется для добавления дополнительных данных в исходные данные на основе условия. Условие указывается в качестве поля в исходных данных, которые соответствуют полю в наборе данных.
Вы можете загрузить образцы данных в хранилище состояний с помощью интерфейса командной строки хранилища состояний. Имена ключей в хранилище состояний соответствуют набору данных в конфигурации потока данных.
В настоящее время этап обогащения не поддерживается в интерфейсе операций.
Если набор данных содержит запись с asset полем, аналогично:
{
"asset": "thermostat1",
"location": "room1",
"manufacturer": "Contoso"
}
Данные из источника, в котором поле deviceId соответствует thermostat1, имеют поля location и manufacturer, доступные на этапах фильтрации и отображения.
Дополнительные сведения о синтаксисе условий см. в разделе "Обогащение данных с помощью потоков данных" и "Преобразование данных с помощью потоков данных".
Фильтр: фильтрация данных на основе условия
Чтобы отфильтровать данные по условию, используется этап filter. Условие указывается в качестве поля в исходных данных, которые соответствуют значению.
В разделе «Преобразование (необязательно)» выберите «Фильтр»>«Добавить».

Введите необходимые параметры.
Настройка Описание Условие фильтра Условие фильтрации данных на основе поля в исходных данных. Описание Укажите описание условия фильтра. В поле условия фильтра введите значение
@или нажмите CTRL+ПРОБЕЛ, чтобы выбрать точки данных из выпадающего списка.Вы можете ввести свойства метаданных MQTT с помощью формата
@$metadata.user_properties.<property>или@$metadata.topic. Вы также можете ввести заголовки $metadata с помощью формата@$metadata.<header>. Синтаксис$metadataнеобходим только для свойств MQTT, входящих в заголовок сообщения. Для получения дополнительной информации см. справочную информацию о полях.Условие может использовать поля в исходных данных. Например, можно использовать условие фильтрации, такое как
@temperature > 20, чтобы отфильтровать данные, равные или меньшие 20, на основе поля температуры.Выберите Применить.
Карта: перемещение данных из одного поля в другое
Чтобы сопоставить данные с другим полем с необязательным преобразованием, можно использовать операцию map. Преобразование указывается в виде формулы, которая использует поля в исходных данных.
В интерфейсе операций сопоставление на данный момент поддерживается с помощью трансформаций вычисления, переименования и нового свойства.
Вычислить
Вы можете использовать преобразование Вычисление, чтобы применить формулу к исходным данным. Эта операция используется для применения формулы к исходным данным и хранения поля результатов.
В разделе «Преобразование» (необязательно) выберите «Вычисления»>«Добавить».

Введите необходимые параметры.
Настройка Описание Выбор формулы Выберите существующую формулу из раскрывающегося списка или выберите "Пользователь" , чтобы ввести формулу вручную. Выходные данные Укажите имя для отображения результата. Формула Введите формулу, применяемую к исходным данным. Описание Укажите описание преобразования. Последнее известное значение При необходимости используйте последнее известное значение, если текущее значение недоступно. В поле "Формула" можно ввести или изменить формулу. Формула может использовать поля в исходных данных. Введите
@или нажмите клавиши CTRL + ПРОБЕЛ, чтобы выбрать точки данных из выпадающего списка. Для встроенных формул выберите<dataflow>плейсхолдер, чтобы просмотреть список доступных точек информации.Вы можете ввести свойства метаданных MQTT с помощью формата
@$metadata.user_properties.<property>или@$metadata.topic. Вы также можете ввести заголовки $metadata с помощью формата@$metadata.<header>. Синтаксис$metadataнеобходим только для свойств MQTT, входящих в заголовок сообщения. Для получения дополнительной информации см. справочную информацию о полях.Формула может использовать поля в исходных данных. Например, можно использовать
temperatureполе в исходных данных для преобразования температуры в Цельсию и хранения его вtemperatureCelsiusполе вывода.Выберите Применить.
Переименовать
Можно переименовать точку данных с помощью преобразования «Переименовать». Эта операция используется для переименования точки данных в исходных данных в новое имя. Новое имя можно использовать на последующих этапах потока данных.
В разделе "Преобразование( необязательно)" выберите "Переименовать>добавить".

Введите необходимые параметры.
Настройка Описание Точка данных Выберите точку данных из раскрывающегося списка или введите заголовок $metadata. Новое имя точки данных Введите новое имя точки данных. Описание Укажите описание преобразования. Вы можете ввести свойства метаданных MQTT с помощью формата
@$metadata.user_properties.<property>или@$metadata.topic. Вы также можете ввести заголовки $metadata с помощью формата@$metadata.<header>. Синтаксис$metadataнеобходим только для свойств MQTT, входящих в заголовок сообщения. Для получения дополнительной информации см. справочную информацию о полях.Выберите Применить.
Новое свойство
Вы можете добавить новое свойство в исходные данные с помощью преобразования нового свойства . Эта операция используется для добавления нового свойства в исходные данные. Новое свойство можно использовать на последующих этапах потока данных.
В разделе "Преобразование" (необязательно) выберите "Добавить новое свойство>".

Введите необходимые параметры.
Настройка Описание Ключ свойства Введите ключ для нового свойства. Значение свойства Введите значение нового свойства. Описание Укажите описание нового свойства. Выберите Применить.
Дополнительные сведения см. в статье "Сопоставление данных с помощью потоков данных" и "Преобразование данных" с помощью потоков данных.
Удалить
По умолчанию все точки данных включены в выходную схему. С помощью преобразования Remove можно удалить любую точку данных из назначения.
В разделе "Преобразование( необязательно)" нажмите кнопку "Удалить".
Выберите точку данных, чтобы удалить из выходной схемы.

Выберите Применить.
Дополнительные сведения см. в статье "Сопоставление данных с помощью потоков данных" и "Преобразование данных" с помощью потоков данных.
Сериализация данных в соответствии со схемой
Если необходимо сериализовать данные перед отправкой в место назначения, необходимо указать формат схемы и сериализации. В противном случае данные сериализуются в ФОРМАТЕ JSON с выводом типов. Конечные точки хранилища, такие как Microsoft Fabric или Azure Data Lake, требуют схемы для обеспечения согласованности данных. Поддерживаемые форматы сериализации — Parquet и Delta.
Совет
Чтобы создать схему из файла с образцом данных, используйте помощник Schema Gen.
Для опыта работы с операциями вы указываете формат схемы и сериализации в деталях конечной точки потока данных. Конечные точки, поддерживающие форматы сериализации, — Microsoft Fabric OneLake, Azure Data Lake Storage 2-го поколения, Azure Data Explorer и локальное хранилище. Например, чтобы сериализовать данные в разностном формате, необходимо отправить схему в реестр схем и ссылаться на нее в конфигурации конечной точки назначения потока данных.

Дополнительные сведения о реестре схем см. в разделе "Общие сведения о схемах сообщений".
Назначение
Чтобы настроить место назначения для потока данных, укажите ссылку на конечную точку и место назначения данных. Вы можете указать список мест назначения данных для конечной точки.
Чтобы отправить данные в место назначения, отличное от локального брокера MQTT, создайте конечную точку потока данных. Сведения о настройке конечных точек потока данных см. в статье "Настройка конечных точек потока данных". Если назначение не локальный брокер MQTT, его нужно использовать как источник. Дополнительные сведения об использовании локальной конечной точки брокера MQTT см. в статье "Потоки данных" должны использовать локальную конечную точку брокера MQTT.
Внимание
Для конечных точек хранилища требуется схема сериализации. Чтобы использовать поток данных с Microsoft Fabric OneLake, Azure Data Lake Storage, Azure Data Explorer или локальное хранилище, необходимо указать ссылку на схему.
Выберите конечную точку потока данных, используемую в качестве назначения.

Для конечных точек хранилища требуется схема сериализации. Если выбрать конечную точку назначения Microsoft Fabric OneLake, Azure Data Lake Storage, Azure Data Explorer или конечную точку назначения локального хранилища, необходимо указать ссылку на схему. Например, чтобы сериализовать данные в конечную точку Microsoft Fabric в формате Delta, необходимо добавить схему в реестр схем и ссылаться на нее в конфигурации конечной точки потока данных.

Нажмите кнопку "Продолжить", чтобы настроить назначение.
Введите необходимые параметры для назначения, включая раздел или таблицу для отправки данных. Дополнительные сведения см. в разделе "Настройка назначения данных" (раздел, контейнер или таблица).
Настройка назначения данных (раздел, контейнер или таблица)
Как и источники данных, назначение данных — это концепция, используемая для повторного использования конечных точек потока данных в нескольких потоках данных. По сути, это представляет собой подкаталог в конфигурации конечной точки передачи данных. Например, если конечная точка потока данных является конечной точкой хранения, назначение данных — это таблица в учетной записи хранения. Если конечная точка потока данных является конечной точкой Kafka, то назначение данных — это топик Kafka.
| Тип конечной точки | Значение назначения данных | Описание |
|---|---|---|
| MQTT (или сетка событий) | Тема | Раздел MQTT, в котором отправляются данные. Поддерживает как статические разделы, так и динамический перевод тем с помощью таких переменных, как ${inputTopic} и ${inputTopic.index}. Дополнительные сведения см. в разделах о динамическом назначении. |
| Kafka (или Центры событий) | Тема | Раздел Kafka, в котором отправляются данные. Поддерживаются только статические темы, подстановочные символы не поддерживаются. Если конечная точка является пространством имен Хабов событий, назначение данных — это отдельный хаб событий в этом пространстве имен. |
| Azure Data Lake Storage | Контейнер | Контейнер в учетной записи хранения данных. Это не таблица. |
| Microsoft Fabric OneLake | Таблица или папка | Соответствует типу настроенного пути для конечной точки. |
| Azure Data Explorer (инструмент для анализа данных от Azure) | Таблица | Таблица в базе данных Azure Data Explorer. |
| Локальное хранилище | Папка | Имя папки или каталога в локальном хранилище постоянного тома. При использовании хранилища контейнеров Azure, активированного томами Azure Arc Cloud Ingest Edge, это должно соответствовать параметру spec.path созданного подтома. |
| OpenTelemetry | Тема | Раздел OpenTelemetry, в котором отправляются данные. Поддерживаются только статические разделы. |
Чтобы настроить назначение данных, выполните следующие действия.
При использовании интерфейса операций поле назначения данных автоматически интерпретируется на основе типа конечной точки. Например, если конечная точка потока данных является конечной точкой хранения, страница сведений о назначении предложит ввести имя контейнера. Если конечная точка потока данных является конечной точкой MQTT, страница сведений о назначении предложит ввести тему.

Разделы динамического назначения
Для конечных точек MQTT можно использовать динамические переменные раздела в dataDestination поле для маршрутизации сообщений на основе структуры исходного раздела. Доступны следующие переменные:
-
${inputTopic}— полный исходный входной раздел -
${inputTopic.index}— Сегмент входной темы (индекс начинается с 1)
Например, processed/factory/${inputTopic.2} маршрутизирует сообщения из factory/1/dataprocessed/factory/1. Сегменты разделов имеют 1 индексирование, а начальные или конечные косые черты игнорируются.
Если переменная раздела не может быть разрешена (например, ${inputTopic.5} если входной раздел имеет только три сегмента), сообщение удаляется и регистрируется предупреждение. Подстановочные знаки (# и +) не допускаются в разделах назначения.
Примечание.
Символы и $ допустимы в именах разделов {}MQTT, поэтому такой раздел factory/$inputTopic.2 является допустимым, но неверным, если вы намерены использовать переменную динамического раздела.
Пример
В следующем примере приведена конфигурация потока данных, которая использует конечную точку MQTT для источника и назначения. Источник фильтрует данные из топика azure-iot-operations/data/thermostatMQTT. Преобразование переводит температуру в Фаренгейт и фильтрует данные, где произведение температуры на влажность меньше 100000. Назначение отправляет данные в топик MQTT factory.

Дополнительные примеры конфигураций потока данных см. в статье Azure REST API — поток данных и в руководстве по быстрой настройке Bicep.
Проверка работы потока данных
Следуйте руководству: Двунаправленный мост MQTT в Azure Event Grid, чтобы убедиться, что поток данных работает правильно.
Экспорт конфигурации потока данных
Чтобы экспортировать конфигурацию потока данных, можно использовать интерфейс управляемого опыта или экспортировать пользовательский ресурс потока данных.
Выберите поток данных, который вы хотите экспортировать, и выберите " Экспорт " на панели инструментов.

Правильная конфигурация потока данных
Чтобы убедиться, что поток данных работает должным образом, проверьте следующее:
- Конечная точка потока данных MQTT по умолчанию должна использоваться как либо источник, либо назначение.
- Профиль потока данных существует и упоминается в конфигурации потока данных.
- Источник — это конечная точка MQTT, конечная точка Kafka или ресурс. Конечные точки типа хранилища нельзя использовать в качестве источника.
- При использовании Сетки событий в качестве источника число экземпляров профиля потока данных имеет значение 1, так как брокер MQTT сетки событий не поддерживает общие подписки.
- При использовании Центров событий в качестве источника каждый концентратор событий в пространстве имен является отдельным разделом Kafka и должен быть указан в качестве источника данных.
- Если преобразование используется, оно настроено с правильным синтаксисом, включая надлежащее экранирование специальных символов.
- При использовании конечных точек типа хранилища в качестве назначения указывается схема.
- При использовании динамических разделов назначения для конечных точек MQTT убедитесь, что переменные раздела ссылались на допустимые сегменты.