Диагностика Load Balancer (цен. категория "Стандартный") с помощью метрик, оповещений и сведений о работоспособности ресурсов
Azure Load Balancer предоставляет следующие возможности диагностики:
Многомерные метрики и оповещения: предоставляет многомерные возможности диагностики с помощью Azure Monitor для конфигураций Azure Load Balancer. Можно отслеживать ресурсы Load Balancer (цен. категория "Стандартный"), управлять ими и устранять связанные с ними неполадки.
Работоспособность ресурсов. Состояние работоспособности ресурсов Load Balancer доступно на странице Работоспособность ресурсов в разделе Монитор. Эта автоматическая проверка информирует о текущей доступности ресурса Load Balancer.
Эта статья содержит краткий обзор этих возможностей и способов их использования для Load Balancer (цен. категория "Стандартный").
Многомерные метрики
Azure Load Balancer предоставляет многомерные метрики посредством решения "Метрики Azure" на портале Azure и позволяет получить сведения для диагностики ресурсов подсистемы балансировки нагрузки в режиме реального времени. Обратите внимание, что многомерные метрики не поддерживаются для базовых подсистем балансировки нагрузки
Различные конфигурации Load Balancer предоставляют следующие метрики:
| Метрика | Тип ресурса | Description | Рекомендуемый агрегат |
|---|---|---|---|
| Data Path Availability (Доступность пути к данным) | Общедоступная и внутренняя подсистемы балансировки нагрузки | Подсистема балансировки нагрузки постоянно использует путь к данным из региона к интерфейсу подсистемы балансировки нагрузки в сеть, поддерживающую виртуальную машину. Пока остаются работоспособные экземпляры, измерение выполняется по тому же пути, что и трафик приложения с балансировкой нагрузки. Используемый путь к данным подтвержден. Измерение является невидимым для приложения и не влияет на работоспособность других операций. | По средней |
| Health Probe Status (Состояние пробы работоспособности) | Общедоступная и внутренняя подсистемы балансировки нагрузки | Подсистема балансировки нагрузки использует распределенную службу проверки работоспособности, которая отслеживает работоспособность конечной точки приложения в соответствии с параметрами конфигурации. Эта метрика обеспечивает агрегированное или отфильтрованное представление для каждой конечной точки экземпляра в пуле подсистемы балансировки нагрузки. Вы можете посмотреть, как в службе Load Balancer исследуется работоспособность вашего приложения в соответствии с заданными настройками пробы. | По средней |
| Число SYN | Общедоступная и внутренняя подсистемы балансировки нагрузки | Подсистема балансировки нагрузки не прерывает подключения протокола TCP или не взаимодействует с потоками пакетов TCP или пользовательских данных (UDP). Потоки и их подтверждения всегда происходят между источником и экземпляром виртуальной машины. Чтобы оптимизировать устранение неполадок для всех сценариев протокола TCP, вы можете использовать счетчики пакетов SYN. С их помощью можно определить число попыток подключения TCP. Эта метрика указывает количество принятых пакетов TCP SYN. | Sum |
| Число подключений для преобразования сетевых адресов источника (SNAT) | общедоступная подсистема балансировки нагрузки; | Подсистема балансировки нагрузки сообщает количество исходящих потоков, которые маскируются на внешний интерфейс общедоступного IP-адреса. SNAT-порты являются ограниченным ресурсом. Эта метрика может дать представление о том, насколько сильно ваше приложение зависит от SNAT для исходящих потоков. Вы можете использовать счетчики успешных и неудавшихся исходящих потоков SNAT, чтобы устранять неполадки и оценивать работоспособность исходящих потоков. | Sum |
| Allocated SNAT Ports | общедоступная подсистема балансировки нагрузки; | Подсистема балансировки нагрузки сообщает количество портов SNAT, выделенных для каждого внутреннего экземпляра. | Среднее. |
| Used SNAT Ports | общедоступная подсистема балансировки нагрузки; | Подсистема балансировки нагрузки сообщает количество портов SNAT, используемых для каждого внутреннего экземпляра. | По средней |
| Количество байтов | Общедоступная и внутренняя подсистемы балансировки нагрузки | Подсистема балансировки нагрузки сообщает данные, обработанные на каждом интерфейсе. Вы можете заметить, что байты не распределяются равномерно между экземплярами серверной части. Это ожидаемо, так как алгоритм Load Balancer в Azure использует потоки. | Sum |
| Число пакетов | Общедоступная и внутренняя подсистемы балансировки нагрузки | Подсистема балансировки нагрузки сообщает о пакетах, обработанных на каждом интерфейсе. | Sum |
Примечание.
Метрики, связанные с пропускной способностью, такие как пакет SYN, число байтов и число пакетов, не будут записывать трафик во внутреннюю подсистему балансировки нагрузки через UDR (например, из NVA или брандмауэра).
Максимальное и минимальное объединения недоступны для метрик количества SYN, количества пакетов, количества подключений SNAT и количества байтов. Не рекомендуется использовать агрегирование Count для метрик доступности пути к данным и состояния пробы работоспособности. Вместо этого используйте вычисление среднего числа для оптимального представления данных о работоспособности.
Просмотр метрик подсистемы балансировки нагрузки на портале Azure
Портал Azure предоставляет метрики подсистемы балансировки нагрузки на странице метрик. Эта страница доступна на странице конкретного ресурса подсистемы балансировки нагрузки и на странице Azure Monitor.
Примечание.
Azure Load Balancer не отправляет пробы работоспособности для освобожденных виртуальных машин. При освобождении виртуальных машин подсистема балансировки нагрузки остановит метрики отчетов для этого экземпляра. Метрики, недоступные, будут отображаться как пунктирная строка на портале или отображать сообщение об ошибке, указывающее, что метрики не могут быть получены.
Чтобы просмотреть метрики для ресурсов подсистемы балансировки нагрузки, выполните следующие действия.
Перейдите на страницу метрик и выполните одно из следующих действий:
На странице ресурсов подсистемы балансировки нагрузки выберите тип метрики в раскрывающемся списке.
На странице Azure Monitor выберите ресурс подсистемы балансировки нагрузки.
Выберите соответствующий тип объединения метрик.
При необходимости настройте требуемые фильтрацию и группирование.
При необходимости настройте объединение и диапазон времени. По умолчанию время отображается в формате UTC.
Примечание.
Объединение времени важно при интерпретации определенных метрик при ежеминутной выборке данных. Если для параметра времени объединения задано значение 5 минут и для типа объединения метрик выбрано "Сумма", на диаграмме пять раз будут отображаться выделенные порты SNAT.
Рекомендация: при анализе типа агрегирования метрик Sum и Count рекомендуется использовать значение времени агрегирования больше одной минуты.
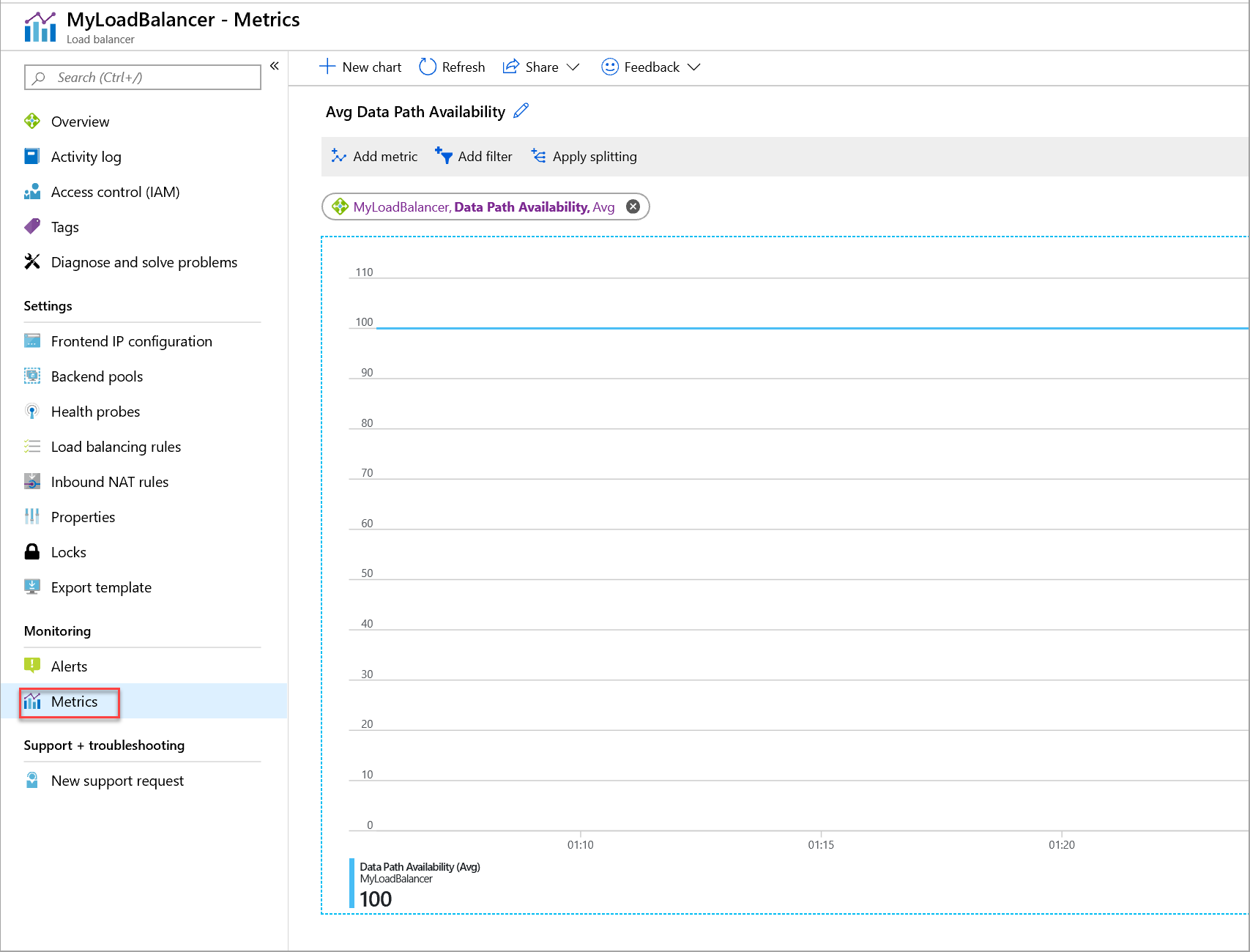
Рисунок. Метрика доступности пути к данным для Load Balancer (цен. категория "Стандартный")
Получение многомерных метрик через API-интерфейсы программным образом
Инструкции по получению определений и значений многомерных метрик с помощью API см. в статье Azure Monitoring REST API walkthrough (Пошаговое руководство по REST API Azure Monitor). Эти метрики можно записать в учетную запись хранения, добавив параметр диагностики для категории "Все метрики".
Распространенные сценарии диагностики и рекомендуемые представления
Доступен ли путь к данным для внешнего интерфейса Load Balancer?
Развертывание
Метрика доступности пути данных описывает работоспособность в регионе пути к вычислительному узлу, где находятся виртуальные машины. Метрика — это отражение работоспособности подсистемы балансировки нагрузки на основе конфигурации и инфраструктуры Azure. Используя эту метрику, можно:
отслеживать внешнюю доступность вашей службы;
изучать платформу, на которой развернута служба, и определять ее работоспособность; определять, является ли гостевая ОС или экземпляр приложения работоспособными;
определить, к чему относится событие: к службе или к базовой плоскости данных. Не путайте эту метрику с метрикой состояния проверки работоспособности.
Чтобы получить доступность пути к данным для ресурсов подсистемы балансировки нагрузки, выполните следующие действия.
Убедитесь, что выбран правильный ресурс подсистемы балансировки нагрузки.
В раскрывающемся списке Метрика выберите Доступность пути к данным.
В раскрывающемся списке Агрегирование выберите Среднее.
Кроме того, добавьте фильтр на внешний IP-адрес или внешний порт в качестве измерения с необходимым IP-адресом внешнего интерфейса или интерфейсным портом. Затем сгруппировать их по выбранному измерению.
Рисунок. Сведения о пробе интерфейса Load Balancer
Метрика создается службой проверки в регионе, который имитирует трафик. Служба проверки периодически создает пакет, соответствующий правилу внешнего интерфейса развертывания и балансировки нагрузки. Затем пакет проходит по региону от источника к узлу виртуальной машины в серверном пуле. Инфраструктура подсистемы балансировки нагрузки выполняет те же операции балансировки нагрузки и преобразования, что и для остального трафика. После прибытия пробы на узел, где находится виртуальная машина в серверном пуле, узел создает ответ на службу проверки. Ваша виртуальная машина не видит этот трафик.
Обратите внимание, что метрика доступности пути к данным будет создана только в конфигурациях внешних IP-адресов с правилами балансировки нагрузки.
Метрика доступности пути данных может быть понижена по следующим причинам:
в вашем развертывании нет исправных виртуальных машин, оставшихся в серверном пуле;
произошел сбой инфраструктуры.
В целях диагностики можно использовать метрику доступности пути к данным и сведения о состоянии пробы работоспособности.
Для большинства сценариев используйте тип статистического вычисления Среднее.
Отвечают ли серверные экземпляры для моего Load Balancer на пробы?
Развертывание
Метрика состояния пробы работоспособности описывает работоспособность развертывания приложения, настроенного при настройке пробы работоспособности подсистемы балансировки нагрузки. Подсистема балансировки нагрузки использует состояние пробы работоспособности, чтобы определить, куда отправлять новые потоки. Пробы работоспособности исходят из адреса инфраструктуры Azure и видны в гостевой ОС виртуальной машины.
Чтобы получить метрику состояния пробы работоспособности для ресурсов подсистемы балансировки нагрузки:
Выберите метрику Состояние пробы работоспособности с типом агрегации Среднее.
Примените фильтр для соответствующего интерфейсного IP-адреса или порта (или обоих вместе).
Пробы работоспособности завершаются ошибками по следующим причинам:
Вы настроили проверку работоспособности для порта, который не ожидает передачи данных, не отвечает или же использует неправильный протокол. Если служба использует прямые или плавающие правила IP-адресов, убедитесь, что служба прослушивает IP-адрес конфигурации IP-адресов сетевого адаптера и обратный цикл, настроенный с интерфейсным IP-адресом.
Группа безопасности сети, брандмауэр гостевой ОС виртуальной машины или фильтры уровня приложений не разрешают трафик пробы работоспособности.
Для большинства сценариев используйте тип статистического вычисления Среднее.
Как проверить статистику исходящего подключения?
Развертывание
Метрика подключений SNAT предоставляет сведения о числе успешных и неудачных подключений для исходящих потоков.
Число подключений со сбоями, превышающее нуль, указывает на нехватку портов SNAT. Нужно продолжить исследование, чтобы определить, что может вызвать эти сбои. При нехватке портов SNAT нельзя установить исходящие потоки. Просмотрите статью об исходящих подключениях, чтобы составить представление о сценариях и механизмах работы, а также узнать, как уменьшить риск и избежать нехватки портов SNAT.
Чтобы получить статистику по подключениям SNAT, сделайте следующее:
Выберите тип метрики SNAT Connections (Подключения SNAT) и тип агрегирования Сумма.
Сгруппируйте подключения SNAT по состоянию подключения (успешные и неудачные), число которых будет представлено разными линиями.
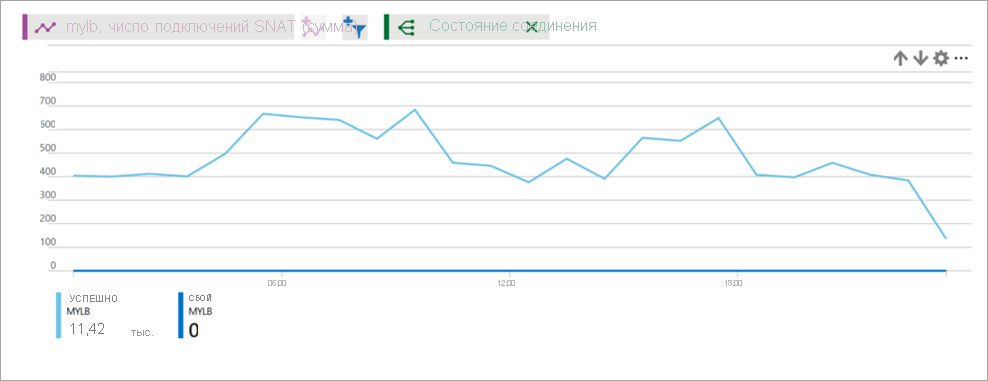
Рисунок. Количество подключений SNAT для Load Balancer
Как проверить использование и выделение портов SNAT?
Развертывание
Используемая метрика портов SNAT отслеживает количество используемых портов SNAT для поддержки исходящих потоков. Эта метрика указывает, сколько уникальных потоков устанавливается между источником Интернета и серверной виртуальной машиной или масштабируемым набором виртуальных машин, которые находятся за подсистемой балансировки нагрузки и не имеют общедоступного IP-адреса. Сравнивая количество портов SNAT, которые вы используете, с выделенной метрикой портов SNAT, можно определить, что служба испытывает или ожидает нехватку SNAT, что приведет к сбою исходящего потока.
Если метрики указывают на риск сбоя исходящего потока, пересмотрите статью и примите меры по устранению сбоя, чтобы обеспечить работоспособность службы.
Чтобы просмотреть сведения об использовании и выделении портов SNAT, сделайте следующее:
Задайте для объединения времени диаграммы значение 1 минута, чтобы обеспечить отображение нужных данных.
Выберите Используемые порты SNAT и/или Выделенные порты SNAT в качестве типа метрики и Среднее в качестве объединения.
По умолчанию эти метрики — это среднее количество портов SNAT, выделенных или используемых каждой серверной виртуальной машиной или масштабируемым набором виртуальных машин. Они соответствуют всем внешним общедоступным IP-адресам, сопоставленным с подсистемой балансировки нагрузки, агрегированным по протоколу TCP и UDP.
Чтобы просмотреть все порты SNAT, используемые или выделенные для подсистемы балансировки нагрузки, используйте объединение метрик Сумма.
Фильтрация по определенному Типу протокола, набору Серверных IP-адресов и (или) Интерфейсных IP-адресов.
Для мониторинга работоспособности серверного или интерфейсного экземпляра примените разделение.
- Обратите внимание, что одно разделение позволяет отображать только одну метрику за раз.
Например, чтобы отслеживать использование SNAT для TCP-потоков на компьютере, выполните объединение по Среднему, выполните разделение по серверным IP-адресам и отфильтруйте по Типу протокола.
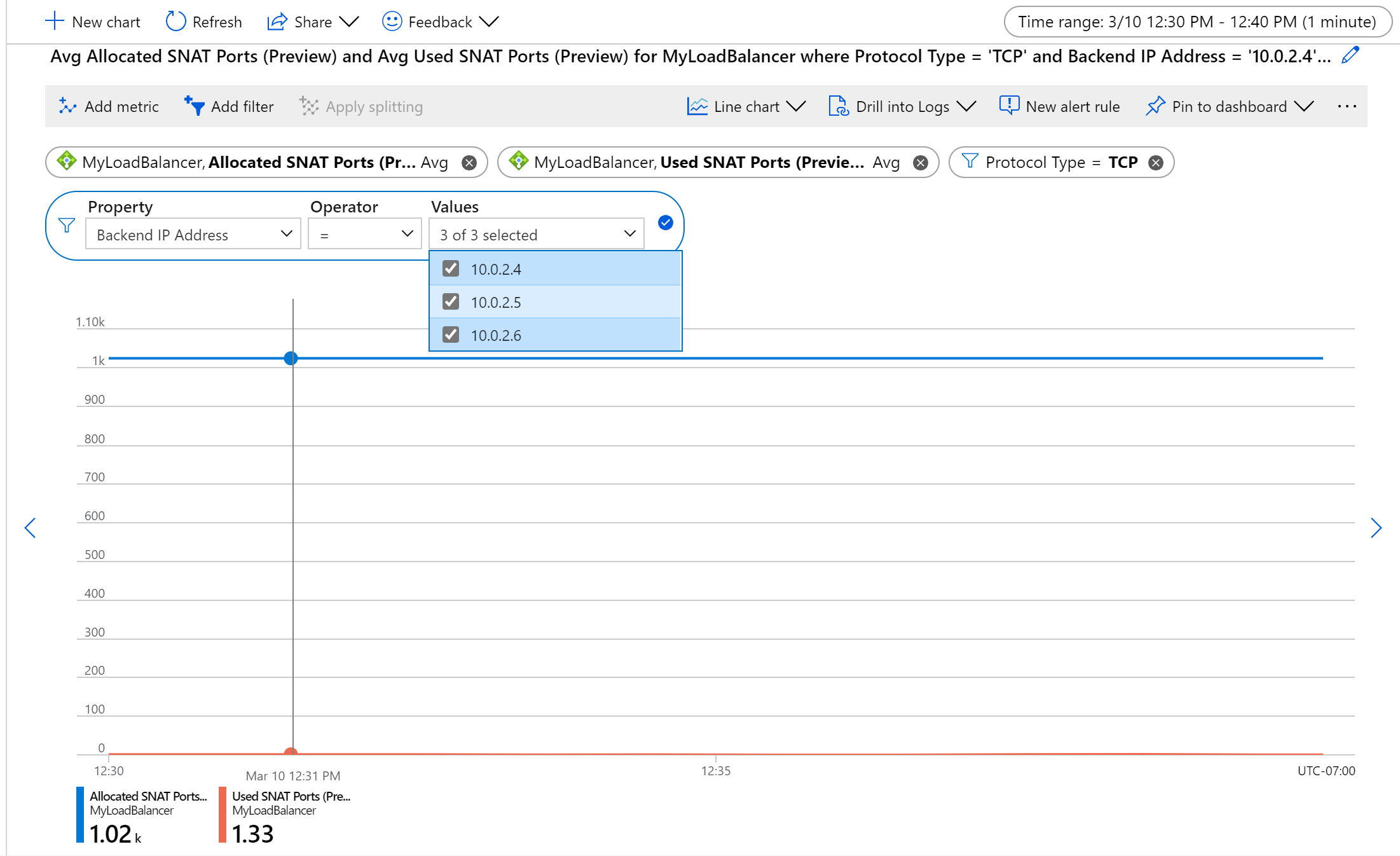
Рисунок. Выделение и использование портов TCP SNAT по среднему для набора серверных виртуальных машин
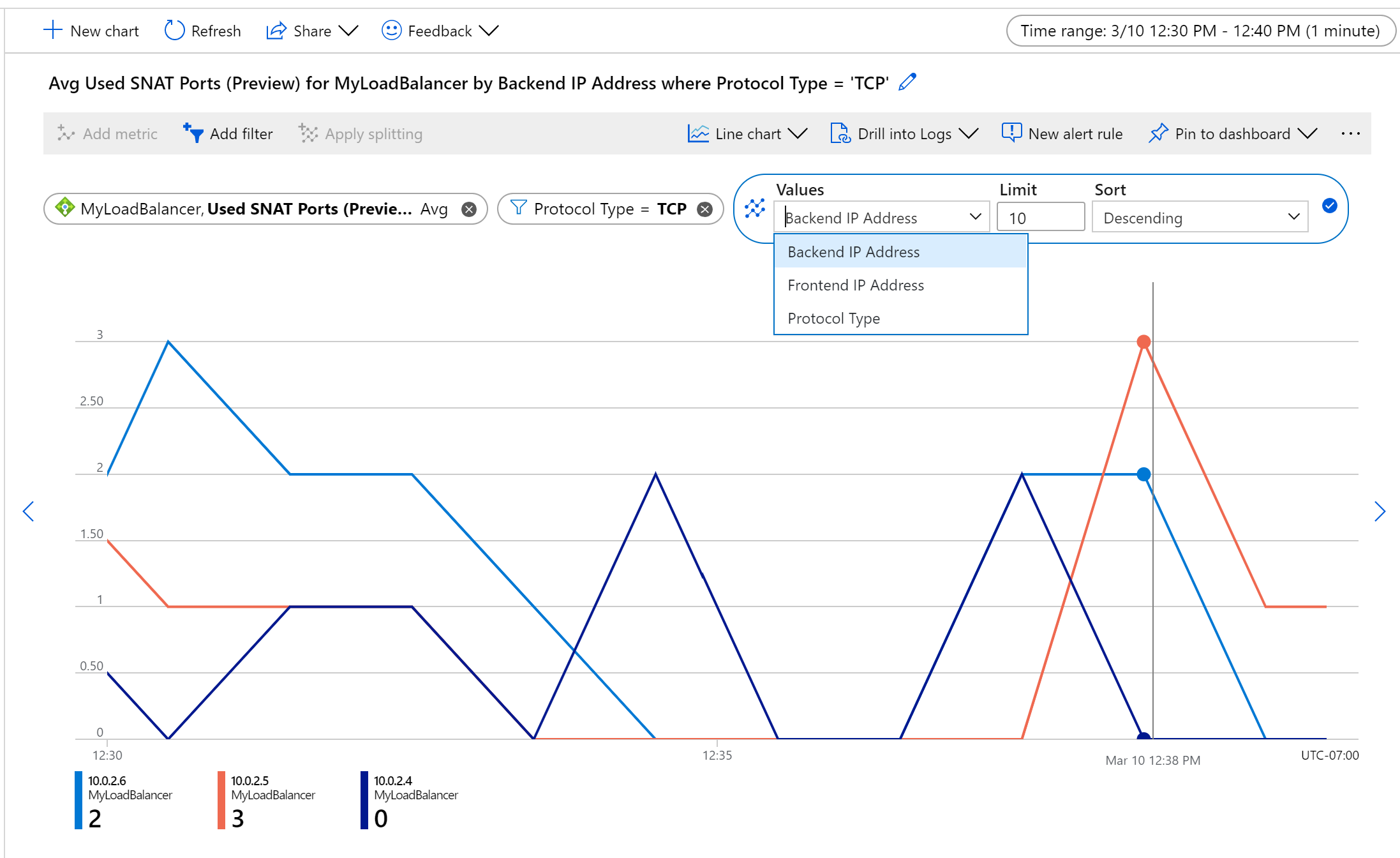
Рисунок. Использование TCP-портов SNAT серверным экземпляром
Как проверить попытки входящих и исходящих подключений для службы?
Развернуть
Метрика пакетов SYN предоставляет сведения о числе принятых или отправленных пакетов TCP SYN (для исходящих потоков), связанных с определенным внешним интерфейсом. Эта метрика позволяет проанализировать попытки подключения TCP к вашей службе.Дополнительные сведения об исходящих подключениях см. в разделе Преобразование исходных сетевых адресов (SNAT) для исходящих подключений.
Для большинства сценариев используйте тип статистической обработки Сумма.
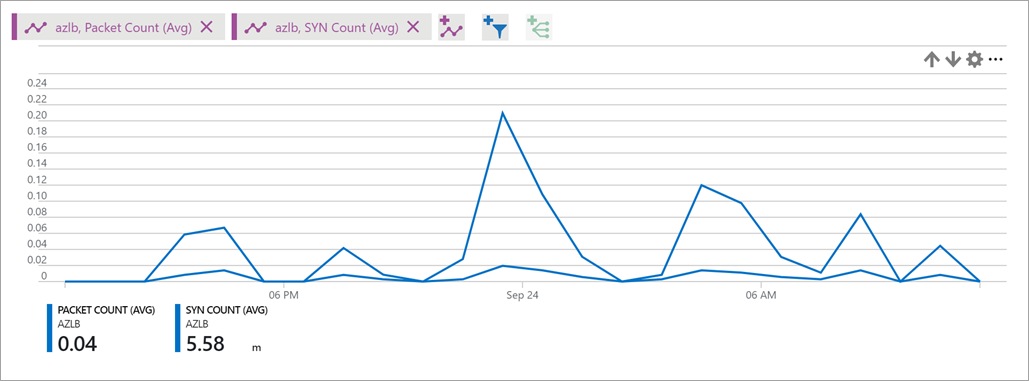
Рисунок. Количество подключений SYN для Load Balancer
Как проверить потребление пропускной способности сети?
Развертывание
Метрика счетчиков байтов и пакетов описывает объем байтов и пакетов, отправляемых или полученных службой на основе внешнего интерфейса.
Для большинства сценариев используйте тип статистической обработки Сумма.
Чтобы получить статистику количества байтов или пакетов, сделайте следующее:
Выберите тип метрики Bytes Count (Количество байтов) и (или) Packet Count (Количество пакетов), а также тип объединения Сумма.
Выполните одно из приведенных ниже действий.
Примените фильтр для определенного внешнего IP-адреса, внешнего порта, внутреннего IP-адреса или внутреннего порта.
Получите общую статистику для ресурсов подсистемы балансировки нагрузки без какой-либо фильтрации.
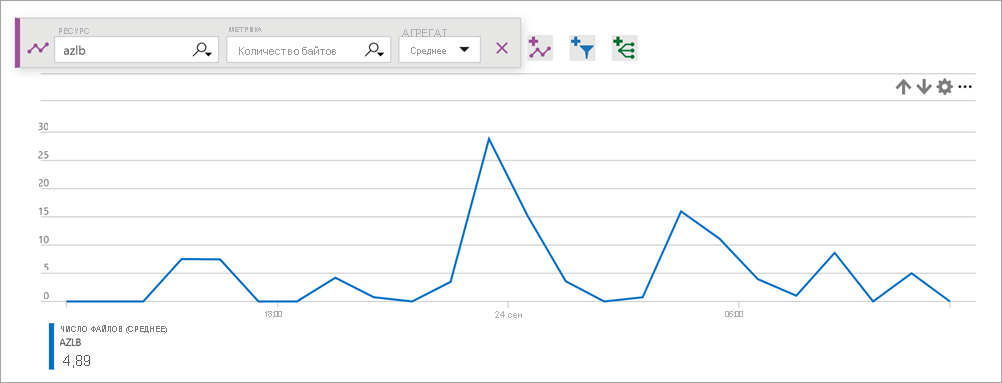
Рисунок. Количество байтов Load Balancer
Как выполнить диагностику развертывания подсистемы балансировки нагрузки?
Развертывание
Сочетание метрик доступности пути к данным и состояния пробы работоспособности на одной диаграмме позволяет определить причину и решение проблемы. Благодаря этой информации вы можете удостовериться в том, что Azure работает правильно. Кроме того, с помощью этих сведений можно достоверно определить, что является первопричиной проблемы: конфигурация или приложение.
Вы можете использовать метрики пробы работоспособности, чтобы понять, как Azure рассматривает работоспособность вашего развертывания в соответствии с предоставленной вами конфигурацией. Просмотр проб работоспособности — отличный первый шаг при мониторинге или определении причины.
Вы можете перейти к следующему этапу и использовать метрику доступности пути к данным, чтобы получить представление о том, как в Azure исследуется работоспособность базовой плоскости данных, отвечающей за конкретное развертывание. Если вы объедините обе метрики, можно будет определить, где возникла ошибка, как показано в этом примере:
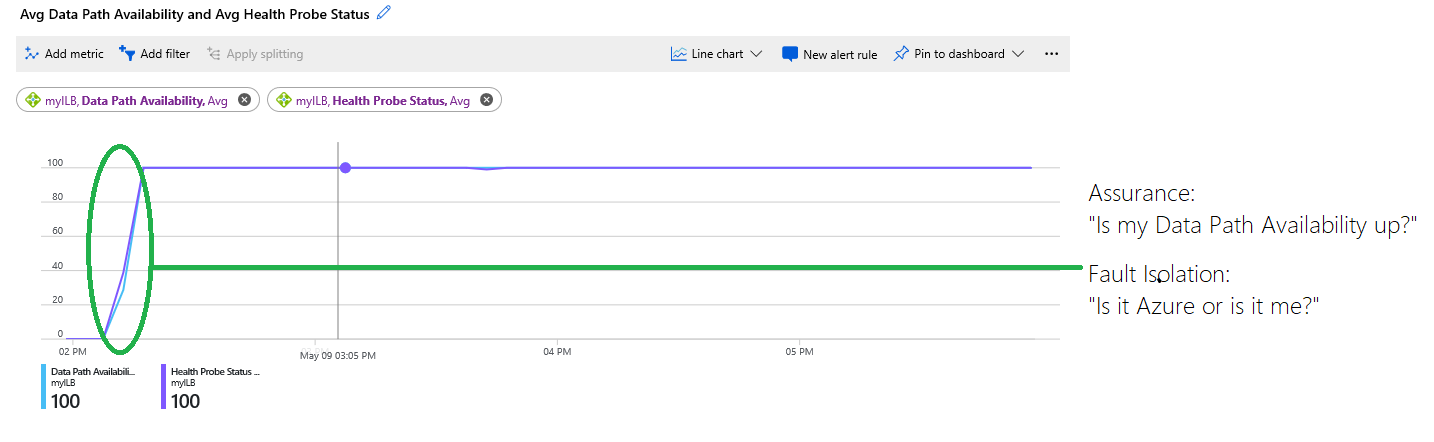
Рисунок. Объединение метрик доступности пути к данным и состояния пробы работоспособности
На диаграмме представлена следующая информация:
Инфраструктура, в которой размещены виртуальные машины, была недоступна и в начале диаграммы составляла 0 %. Позднее инфраструктура стала работоспособной и ВМ стали доступны, а на сервере были размещены несколько виртуальных машин. Об этом свидетельствует синяя линия доступности пути к данным, которая достигает 100 %.
Состояние пробы работоспособности, обозначенное фиолетовой трассировкой, равно 0 % в начале диаграммы. Кругом зеленого цвета отмечен период, когда система получила статус пробы работоспособности. В этот момент развертывание клиента смогло принять новые потоки.
Благодаря диаграмме клиенты могут самостоятельно устранять проблемы с развертыванием без необходимости обращаться в службу поддержки или угадывать, были ли другие проблемы. При проверках работоспособности служба была недоступна по причине сбоев из-за неправильной конфигурации или неисправности приложения.
Настройка оповещений для многомерных метрик
Azure Load Balancer поддерживает легко настраиваемые оповещения для многомерных метрик. Настройте пользовательские пороговые значения для конкретных метрик, чтобы активировать предупреждения с различными уровнями серьезности и повысить эффективность мониторинга ресурсов без вмешательства пользователя.
Чтобы настроить оповещения, сделайте следующее:
Перейдите на страницу оповещений для подсистемы балансировки нагрузки
Создание правила генерации оповещений
Настройка условия генерации оповещений (Примечание. Чтобы избежать шумных оповещений, рекомендуется настроить оповещения с типом агрегирования, заданным для среднего, возвращаясь к пятиминутном окне данных и пороговым значением 95%)
(Необязательно) Добавление группы действий для автоматического исправления
Назначение предупреждению уровня серьезности, имени и описания для ясности
Входящее предупреждение о доступности
Примечание.
Если серверные пулы подсистемы балансировки нагрузки пусты, у подсистемы балансировки нагрузки не будет путей к данным для тестирования. В результате метрика доступности пути к данным будет отсутствовать, а настроенные оповещения Azure для этой метрики не будут активироваться.
Чтобы предупреждать о доступности входящего канала, можно создать два отдельных предупреждения, используя метрики доступности пути к данным и состояния пробы работоспособности. Клиенты могут иметь различные сценарии, требующие конкретной логики оповещения, но приведенные ниже примеры полезны для большинства конфигураций.
С помощью доступности пути к данным можно активировать предупреждения всякий раз, когда определенное правило балансировки нагрузки становится недоступным. Это предупреждение можно настроить, задав условие предупреждения для доступности пути к данным и разбиения по всем текущим и будущим значениям для внешнего порта и внешнего IP-адреса. Если задать для логики предупреждения значение меньше или равное 0, это предупреждение будет запускаться каждый раз, когда любое правило балансировки нагрузки перестанет отвечать. Задайте точность объединения и частоту оценки в соответствии с требуемой оценкой.
С состоянием пробы работоспособности можно предупредить, если заданный серверный экземпляр не сможет реагировать на пробу работоспособности в течение значительного времени. Настройте условие предупреждения для использования метрики состояния проверки работоспособности и разбиения по серверному IP-адресу и порту. Это гарантирует, что вы можете генерации оповещений отдельно для каждого отдельного экземпляра серверного экземпляра обслуживать трафик на определенном порту. Используйте средний тип агрегирования и задайте пороговое значение в соответствии с тем, как часто проверяется внутренний экземпляр и считается здоровым пороговым значением.
Можно также оповещать на уровне серверного пула, не прерывая ни одного измерения и не используя тип объединения Среднее. Это позволяет настроить такие правила генерации оповещений, как оповещение, если 50% членов внутреннего пула неработоспособны.
Исходящее предупреждение о доступности
Для исходящей доступности можно настроить два отдельных оповещения с помощью счетчика подключений SNAT и используемых метрик портов SNAT.
Для обнаружения сбоев исходящих подключений настройте предупреждение с помощью метрики количества подключений SNAT и фильтрации по значению Состояние соединения = Сбой. Используйте объединение Всего. Затем вы можете разделить это по внутреннему IP-адресу, заданному для всех текущих и будущих значений, чтобы генерация оповещений отдельно для каждого экземпляра серверной части возникали сбои подключений. Установите пороговое значение больше нуля или более, если вы хотите видеть сбои исходящих подключений.
Используя используемые порты SNAT, вы можете предупредить о более высоком риске нехватки SNAT и сбоя исходящего подключения. При использовании этого предупреждения убедитесь, что разделение выполняется по серверному IP-адресу и протоколу. Используйте агрегирование Среднее. Установите пороговое значение, превышающее процентное соотношение количества выделенных портов на экземпляр, который вы определили как ненадежный. Например, настройте предупреждение с низким уровнем серьезности, когда серверный экземпляр использует 75 % выделенных портов. Настройте предупреждение с высоким уровнем серьезности, когда будет задействовано 90 % или 100 % выделенных портов.
Состояние работоспособности ресурсов
Состояние работоспособности ресурсов Load Balancer (цен. категория "Стандартный") можно узнать на странице Работоспособность ресурсов в разделе Мониторинг > Работоспособность служб. Показатель вычисляется каждые две минуты путем измерения доступности пути к данным, которая определяет, доступны ли интерфейсные конечные точки балансировки нагрузки.
| Состояние работоспособности ресурсов | Описание |
|---|---|
| На месте | Ресурс стандартной подсистемы балансировки нагрузки работоспособен и доступен. |
| Деградация | Стандартная подсистема балансировки нагрузки имеет инициированные платформой или пользователем события, влияющие на производительность. Метрика доступности пути к данным сообщила, что состояние работоспособности в течение как минимум двух минут ниже 90 %, но больше 25 %. С этим состоянием вы можете столкнуться с умеренным воздействием на производительность. Ознакомьтесь с руководством по устранению неполадок RHC, чтобы определить наличие событий, инициированных пользователем, которые негативно сказываются на доступности. |
| Рекомендации недоступны | Ресурс Load Balancer (цен. категория "Стандартный") неработоспособен. Метрика доступности пути к данным сообщила, что состояние работоспособности в течение как минимум двух минут ниже 25 %. При таком состоянии вы испытываете значительный эффект производительности или отсутствие доступности для входящего подключения. Возможно, недоступность вызывают события на стороне пользователя или платформы. Ознакомьтесь с руководством по устранению неполадок RHC, чтобы определить наличие событий, инициированных пользователем, которые негативно влияют на доступность. |
| Неизвестно | Состояние работоспособности для ресурса подсистемы балансировки нагрузки не было обновлено или не получило сведений о доступности пути к данным за последние 10 минут. Это временное состояние. Правильное состояние будет отображено сразу после получения данных. |
Чтобы просмотреть работоспособность ресурсов общедоступной службы Load Balancer (цен. категория "Стандартный"), сделайте следующее:
Выберите Монитор>Работоспособность службы.
Рисунок. Ссылка "Работоспособность службы" в Azure Monitor
Выберите Работоспособность ресурсов и убедитесь, что выбран идентификатор подписки, а для типа ресурса установлено значение Load Balancer.
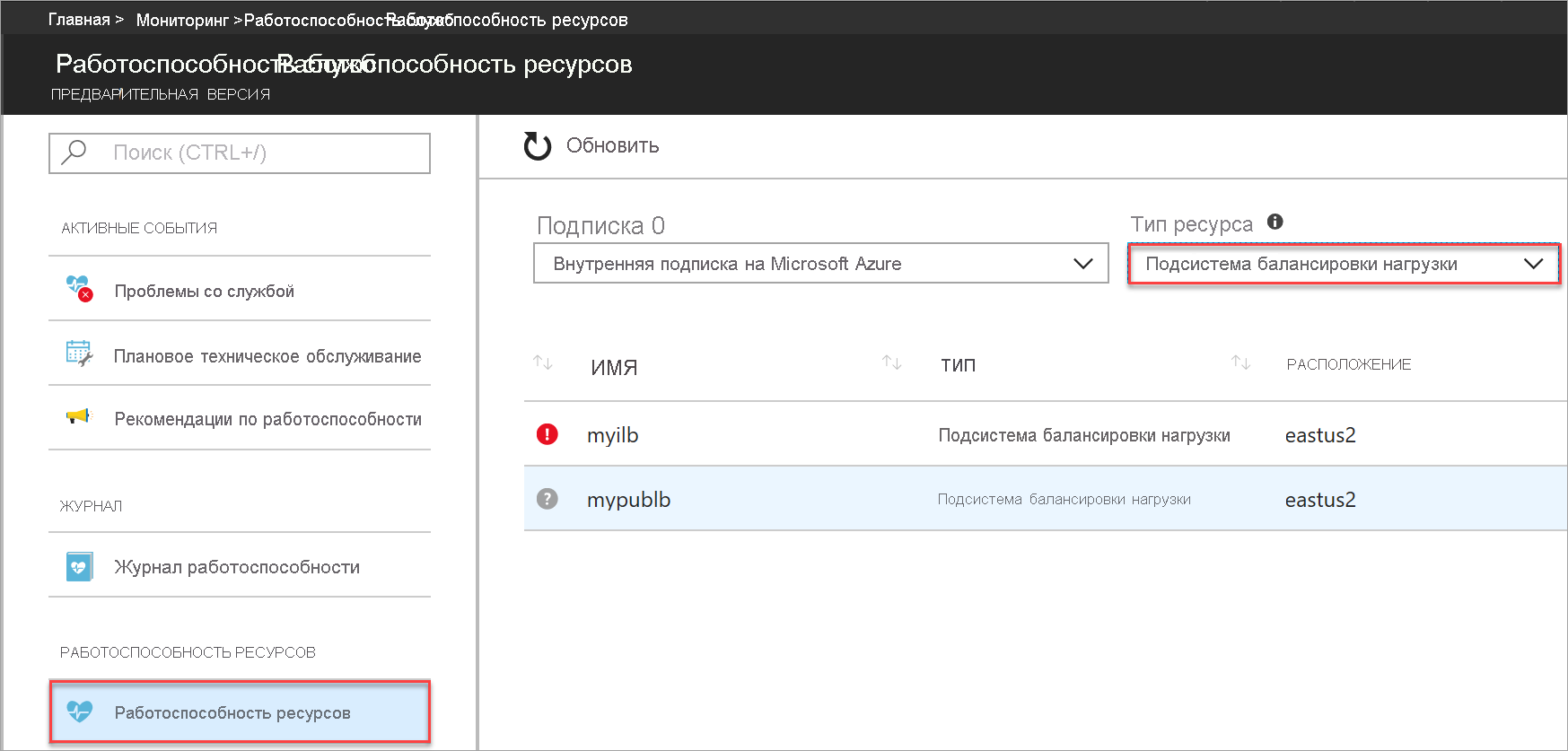
Рисунок. Выбор ресурса для представления работоспособности
В списке щелкните ресурс подсистемы балансировки нагрузки, чтобы просмотреть историю его состояния работоспособности.
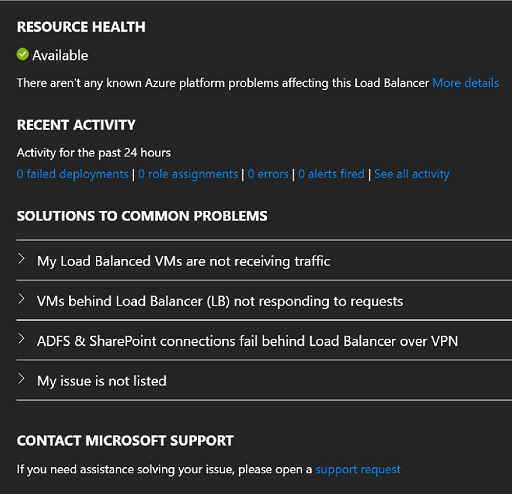
Рис. Состояние работоспособности ресурсов
Общее описание состояния работоспособности ресурсов доступно в документации по работоспособности ресурсов.
Оповещения о состоянии ресурсов
Оповещения Azure Работоспособность ресурсов могут уведомлять вас в режиме реального времени, когда состояние работоспособности ресурса Load Balancer изменяется. Рекомендуется настроить оповещения о работоспособности ресурсов, чтобы уведомить вас о том, что ресурс подсистемы балансировки нагрузки находится в состоянии "Понижение" или "Недоступно".
При создании оповещений о работоспособности ресурсов Azure для Load Balancer Azure отправляет уведомления о работоспособности ресурсов в подписку Azure. Вы можете создавать и настраивать оповещения на основе:
- Затронутая подписка
- Затронутая группа ресурсов
- Затронутый тип ресурса (Load Balancer)
- Конкретный ресурс (любой ресурс подсистемы балансировки нагрузки, для который вы решили настроить оповещение)
- Состояние события затронутого ресурса Подсистемы балансировки нагрузки
- Текущее состояние затронутого ресурса Подсистемы балансировки нагрузки
- Предыдущее состояние затронутого ресурса Подсистемы балансировки нагрузки
- Тип причины затронутого ресурса Подсистемы балансировки нагрузки
Вы также можете настроить, кому следует отправить оповещение:
- Новая группа действий (которая может использоваться для будущих оповещений)
- Существующая группа действий
Дополнительные сведения о настройке этих оповещений о работоспособности ресурсов см. в следующих статье:
- Оповещения о работоспособности ресурсов с помощью портал Azure
- Оповещения о работоспособности ресурсов с помощью шаблонов Resource Manager
Следующие шаги
- Узнайте больше об аналитике сети.
- Сведения об использовании Аналитики для просмотра этих метрик, предварительно настроенных для подсистемы балансировки нагрузки.
- Узнайте больше о Load Balancer (цен. категории "Стандартный").