Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
В этой статье описывается компонент в конструкторе Машинного обучения Azure.
Используйте этот компонент для измерения точности обученной модели. Вы предоставляете набор данных, содержащий оценки, сформированные на основе модели, и компонент Оценка модели вычисляет набор метрик оценки, стандартных для отрасли.
Метрики, возвращаемые модулем Оценка модели, зависят от типа оцениваемой модели:
- модели классификации;
- модели регрессии;
- модели кластеризации.
Совет
Если вы не знакомы с моделью оценки, мы рекомендуем видеосерию д-р Стивен Элстон, в рамках курса машинного обучения из EdX.
Как использовать оценку модели
Подключите Оцененный набор данных, выданный Оценкой модели или набор данных результатов, выданный Назначением данных кластерам к левому порту ввода Оценки модели.
Примечание.
Если вы используете такие компоненты, как "Выбор столбцов в наборе данных", чтобы выбрать часть входного набора данных, убедитесь, что столбец фактических меток (используемый в обучении), столбец "Оценка вероятностей" и "Оценка меток" существуют для вычисления метрик, таких как AUC, точность для двоичной классификации или обнаружения аномалий. Столбец фактических меток и столбец "Оцененные метки" существуют, чтобы вычислять метрики для многоклассовой классификации и регрессии. Столбец "Назначения" и столбцы "DistancesToClusterCenter no.X" (расстояния до центра кластера № Х) (X — индекс центроида, от 0, ..., число центроидов-1) существуют, чтобы вычислять метрики для кластеризации.
Внимание
- Чтобы оценить результаты, выходной набор данных должен содержать конкретные имена столбцов оценки, которые соответствуют требованиям компонента оценки модели.
- Столбец
Labelsсчитается содержащим фактические метки. - Для задачи регрессии набор данных для оценки должен иметь один столбец с именем
Regression Scored Labels, который представляет метки с оценками. - Для задачи двоичной классификации набор данных для оценки должен иметь два столбца с именами
Binary Class Scored LabelsиBinary Class Scored Probabilities, которые представляют метки с оценками и вероятности соответственно. - Для задачи с несколькими классификациями набор данных для оценки должен иметь один столбец с именем
Multi Class Scored Labels, который представляет метки с оценками. Если выходные данные вышестоящего компонента не содержат этих столбцов, их необходимо изменить в соответствии с требованиями выше.
(Необязательно.) Подключите Оцененный набор данных, выданный Оценкой модели или набор данных результатов, выданный назначением данных кластерам для второй модели к правому порту ввода Оценки модели. Вы легко сможете сравнить результаты двух различных моделей по одним и тем же данным. Два алгоритма ввода должны иметь одинаковый тип алгоритма. Или вы можете сравнить результаты двух различных выполнений по аналогичным данным с разными параметрами.
Примечание.
Тип алгоритма означает "Классификацию с двумя классами", "Многоклассовую классификацию", "Регрессию", "Кластеризацию" в разделе "Алгоритмы Машинного обучения".
Отправьте конвейер, чтобы создать оценки.
Результаты
После запуска Оценки модели выберите компонент, чтобы открыть панель навигации Оценка модели справа. Затем выберите вкладку Результаты + журналы. В разделе Выходные данные на этой вкладке имеется несколько значков. Значок Визуализация имеет значок линейчатой диаграммы и является первым способом просмотра результатов.
Для двоичной классификации после нажатия кнопки Визуализировать можно визуализировать двоичную матрицу несоответствий. Для нескольких классификаций файл матрицы несоответствий можно найти на вкладке Выходные данные и журналы, как в следующем примере:
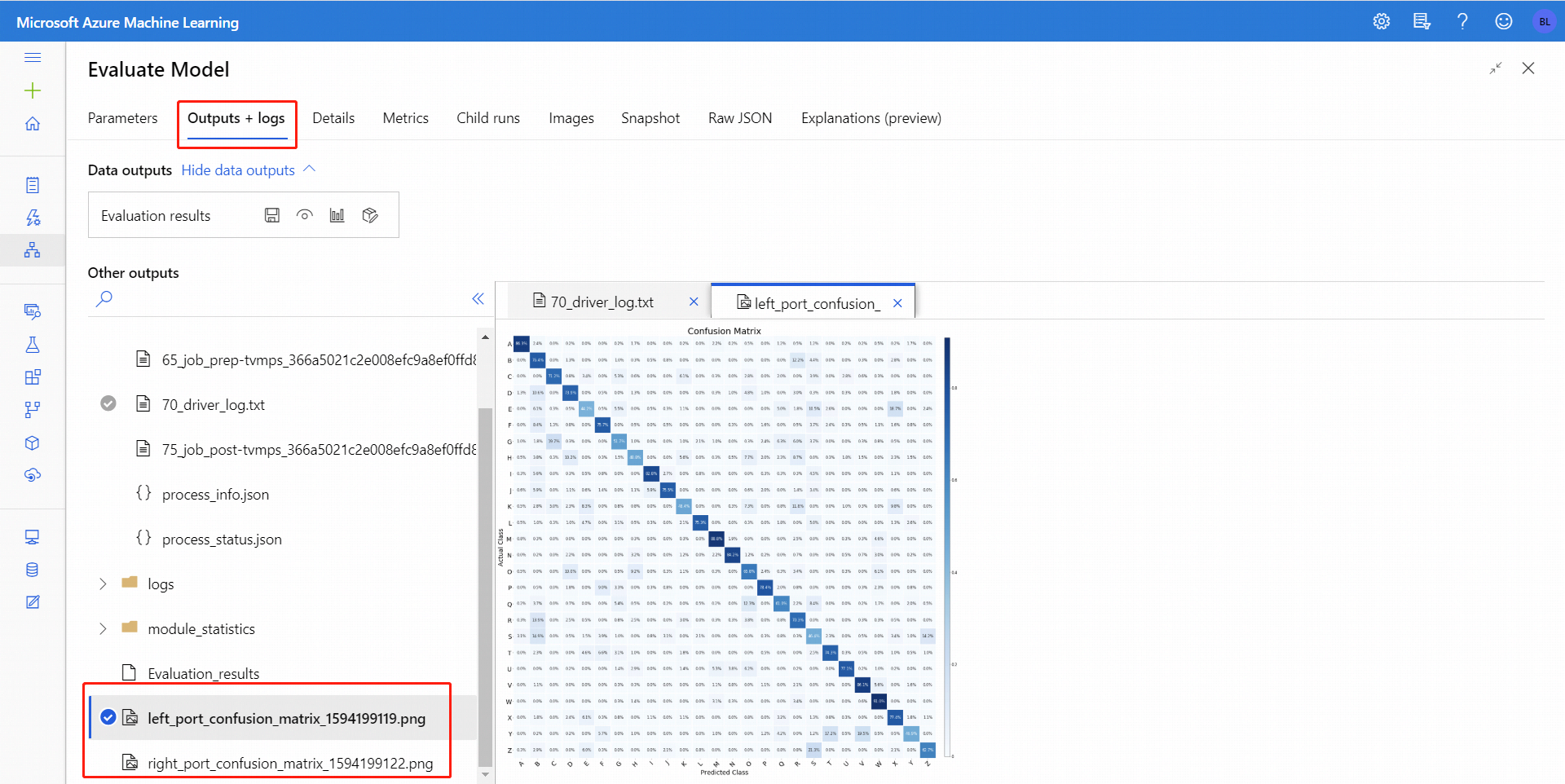
Если вы подключаете наборы данных к обоим входам Оценки модели, результаты будут содержать метрики для обоих наборов данных или обоих моделей. Модель или данные, присоединенные к левому порту, отображаются в отчете первыми, за ними следуют метрики набора данных или модели, присоединенной к правому порту.
Например, на следующем рисунке представлено сравнение результатов из двух моделей кластеризации, созданных на основе одних и тех же данных, но с разными параметрами.
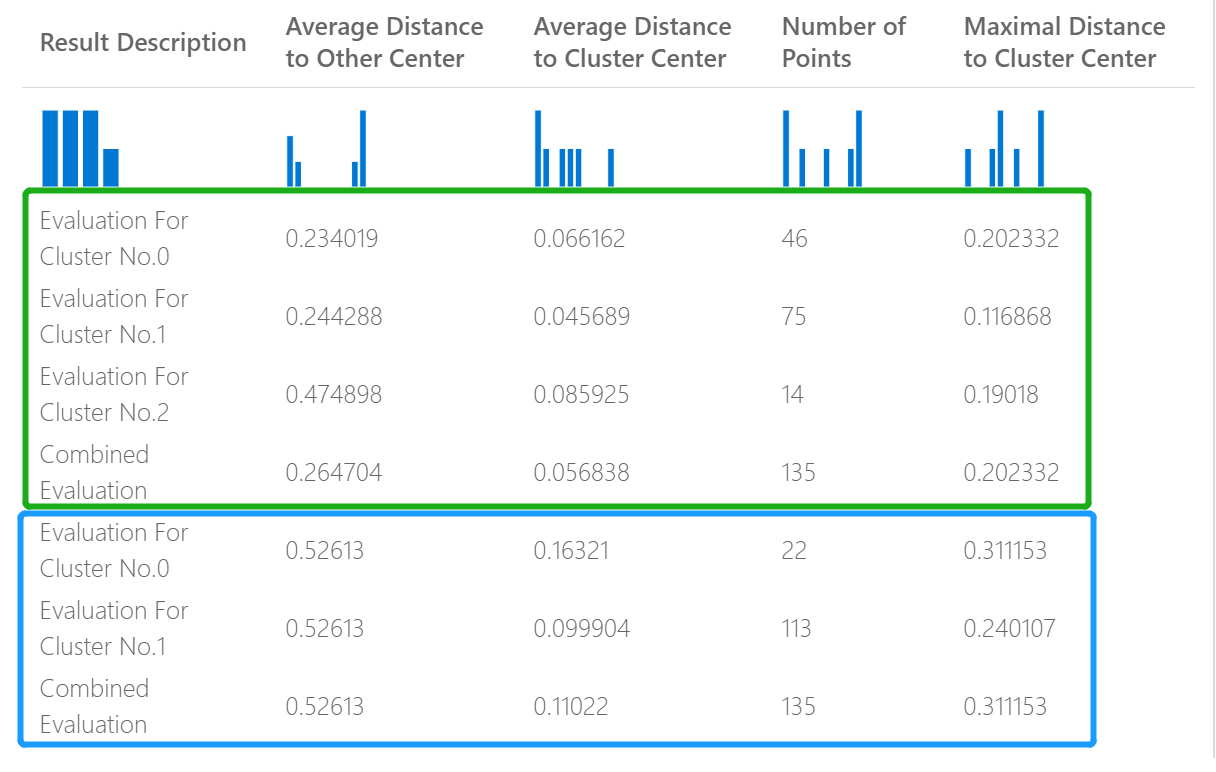
Поскольку это модель кластеризации, результаты оценки отличаются от результатов при сравнении показателей двух моделей регрессии или сравнении двух моделей классификации. Но общая презентация одинакова.
Метрики
В этом разделе описываются метрики, возвращаемые для конкретных типов моделей, использование которых с Оценкой модели поддерживается:
Метрики моделей классификации
При оценке двоичных моделей классификации предоставляются следующие метрики.
Правильность измеряет качество модели классификации как пропорцию истинных результатов к общему числу случаев.
Точность — это пропорция истинных результатов ко всем положительным результатам. Точность = TP / (TP + FP)
Полнота — это доля общего объема соответствующих экземпляров, которые фактически были получены. Полнота = TP / (TP + FN)
Оценка F1 вычисляется как взвешенное среднее значение точности и полноты. Она может иметь значение от 0 до 1, где идеальным значением является 1.
AUC указывает площадь под кривой, построенной в системе, где истинно-положительные результаты откладываются по оси y, а ложноположительные результаты — по оси x. Эта метрика полезна, так как она выражается одним числом, по которому можно сравнивать модели различных типов. AUC является неизменяемым порогом классификации. Он определяет качество прогнозов модели независимо от выбранного порога классификации.
Метрики моделей регрессии
Метрики, возвращаемые для моделей регрессии, предназначены для оценки объема ошибок. Модель считается соответствующей данным, если разница между наблюдаемыми и прогнозируемыми значениями невелика. Однако рассмотрение закономерностей остатков (разницы между любой прогнозируемой точкой и соответствующим ей фактическим значением) может сообщить о потенциальном смещении в модели.
Ниже перечислены метрики для оценки моделей линейной регрессии. Другие модели gression, такие как Быстрая лесная регрессия , могут иметь разные метрики.
Средняя абсолютная ошибка (MAE) измеряет, насколько предсказания близки к фактическим результатам. Чем ниже этот показатель, тем лучше.
Среднеквадратичная ошибка (RMSE) создает одно значение, которое суммирует ошибку в модели. Возводя разницу в квадрат, метрика не учитывает разницу между ошибкой прогноза в большую или меньшую сторону.
Относительная абсолютная ошибка (RAE) — это относительная абсолютная разница между ожидаемым и фактическими значениям; относительна она потому, что средняя разница делится на арифметическое среднее значение.
Относительная квадратичная ошибка (RSE) аналогичным образом нормализует суммарную квадратичную ошибку прогнозируемых значений путем деления на суммарную квадратичную ошибку реальных значений.
Коэффициент определения, часто называемый R2, представляет собой предсказательную силу модели в виде значения от 0 до 1. Ноль означает, что модель является случайной (ничего не объясняет); 1 означает, что она подходит идеально. Но следует соблюдать осторожность при интерпретации значений R2, так как низкие значения могут быть вполне нормальными, а высокие значения — подозрительными.
Метрики для моделей кластеризации
Поскольку модели кластеризации отличаются от моделей классификации и регрессии во многих отношениях, Оценка модели также возвращает другой набор статистических данных для моделей кластеризации.
Статистические данные, возвращаемые для модели кластеризации, описывают, сколько точек данных было назначено каждому кластеру, расстояние между кластерами, а также то, насколько тесно точки данных расположены в каждом кластере.
Статистические данные для модели кластеризации усреднены по всему набору данных, с дополнительными строками, содержащими статистику для каждого кластера.
При оценке моделей кластеризации предоставляются следующие метрики.
Оценки в столбце Среднее расстояние до другого центра показывают, насколько близко в среднем каждая точка в кластере находится к центроидам всех остальных кластеров.
Оценки в столбце Среднее расстояние до центра кластера представляют близость всех точек в кластере к центроиду этого кластера.
В столбце Число точек показано, сколько точек данных было назначено каждому кластеру вместе с общим количеством точек данных во всех кластерах.
Если количество точек данных, назначенных кластерам, меньше общего количества доступных точек данных, это означает, что какие-то точки данных не могут быть назначены кластеру.
Оценки в столбце Максимальное расстояние до центра кластера представляют максимум расстояний между каждой точкой и центроидом кластера этого пункта.
Если это значение велико, это может означать, что кластер широко распределен. Для определения распределения кластера следует проанализировать эту статистику вместе со Средним расстоянием до центра кластера.
Показатель Объединенной оценки в нижней части каждого раздела результатов перечисляет средние оценки для кластеров, созданных в данной модели.
Следующие шаги
Ознакомьтесь с набором доступных компонентов для машинного обучения Azure.