Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
В этой статье описывается компонент выполнения скрипта Python в конструкторе Машинное обучение Azure.
Используйте этот компонент для выполнения кода Python. Дополнительные сведения об архитектуре и принципах проектирования Python см. в статье выполнение кода Python в конструкторе машинного обучения Azure.
С помощью Python можно выполнять задачи, которые не поддерживаются существующими компонентами, например:
- Визуализация данных с помощью
matplotlib. - Использование библиотек Python для перечисления наборов данных и моделей в рабочей области.
- Чтение, загрузка и обработка данных из источников, которые не поддерживаются компонентом импорта данных.
- Запустите собственный код глубокого обучения.
Поддерживаемые пакеты Python
Машинное обучение Azure использует дистрибутив Python Anaconda, который включает множество стандартных служебных программ для обработки данных. Мы будем обновлять версию Anaconda автоматически. Текущая версия:
- Распределение Anaconda для Python 3.10
Полный список см. в разделе с предварительно установленными пакетами Python.
Чтобы установить пакеты, отсутствующие в предварительно установленном списке (например, scikit-misc), добавьте в сценарий следующий код:
import os
os.system(f"pip install scikit-misc")
Используйте следующий код, чтобы установить пакеты для повышения производительности, особенно для вывода:
import importlib.util
package_name = 'scikit-misc'
spec = importlib.util.find_spec(package_name)
if spec is None:
import os
os.system(f"pip install scikit-misc")
Примечание.
Если конвейер содержит несколько компонентов выполнения скрипта Python, для которых требуются пакеты, отсутствующие в списке предварительно установленных, установите пакеты в каждый компонент.
Предупреждение
Компонент выполнения скрипта Python не поддерживает установку пакетов, зависящих от дополнительных собственных библиотек, с помощью команды вроде "apt-get", например Java, PyODBC и т. д. Это происходит потому, что этот компонент выполняется только в простой среде с предварительно установленным Python и не имеет разрешений администратора.
Доступ к текущей рабочей области и зарегистрированным наборам данных
Чтобы получить доступ к зарегистрированным наборам данных в рабочей области, можно обратиться к следующему примеру кода:
def azureml_main(dataframe1 = None, dataframe2 = None):
# Execution logic goes here
print(f'Input pandas.DataFrame #1: {dataframe1}')
from azureml.core import Run
run = Run.get_context(allow_offline=True)
#access to current workspace
ws = run.experiment.workspace
#access to registered dataset of current workspace
from azureml.core import Dataset
dataset = Dataset.get_by_name(ws, name='test-register-tabular-in-designer')
dataframe1 = dataset.to_pandas_dataframe()
# If a zip file is connected to the third input port,
# it is unzipped under "./Script Bundle". This directory is added
# to sys.path. Therefore, if your zip file contains a Python file
# mymodule.py you can import it using:
# import mymodule
# Return value must be of a sequence of pandas.DataFrame
# E.g.
# - Single return value: return dataframe1,
# - Two return values: return dataframe1, dataframe2
return dataframe1,
Отправить файлы
Компонент выполнения скрипта Python поддерживает отправку файлов с помощью пакета SDK для машинного обучения Azure Python.
В следующем примере показано, как передать файл изображения в компонент выполнения скрипта Python:
# The script MUST contain a function named azureml_main,
# which is the entry point for this component.
# Imports up here can be used to
import pandas as pd
# The entry point function must have two input arguments:
# Param<dataframe1>: a pandas.DataFrame
# Param<dataframe2>: a pandas.DataFrame
def azureml_main(dataframe1 = None, dataframe2 = None):
# Execution logic goes here
print(f'Input pandas.DataFrame #1: {dataframe1}')
from matplotlib import pyplot as plt
plt.plot([1, 2, 3, 4])
plt.ylabel('some numbers')
img_file = "line.png"
plt.savefig(img_file)
from azureml.core import Run
run = Run.get_context(allow_offline=True)
run.upload_file(f"graphics/{img_file}", img_file)
# Return value must be of a sequence of pandas.DataFrame
# For example:
# - Single return value: return dataframe1,
# - Two return values: return dataframe1, dataframe2
return dataframe1,
После завершения выполнения конвейера можно предварительно просмотреть образ в правой панели компонента.
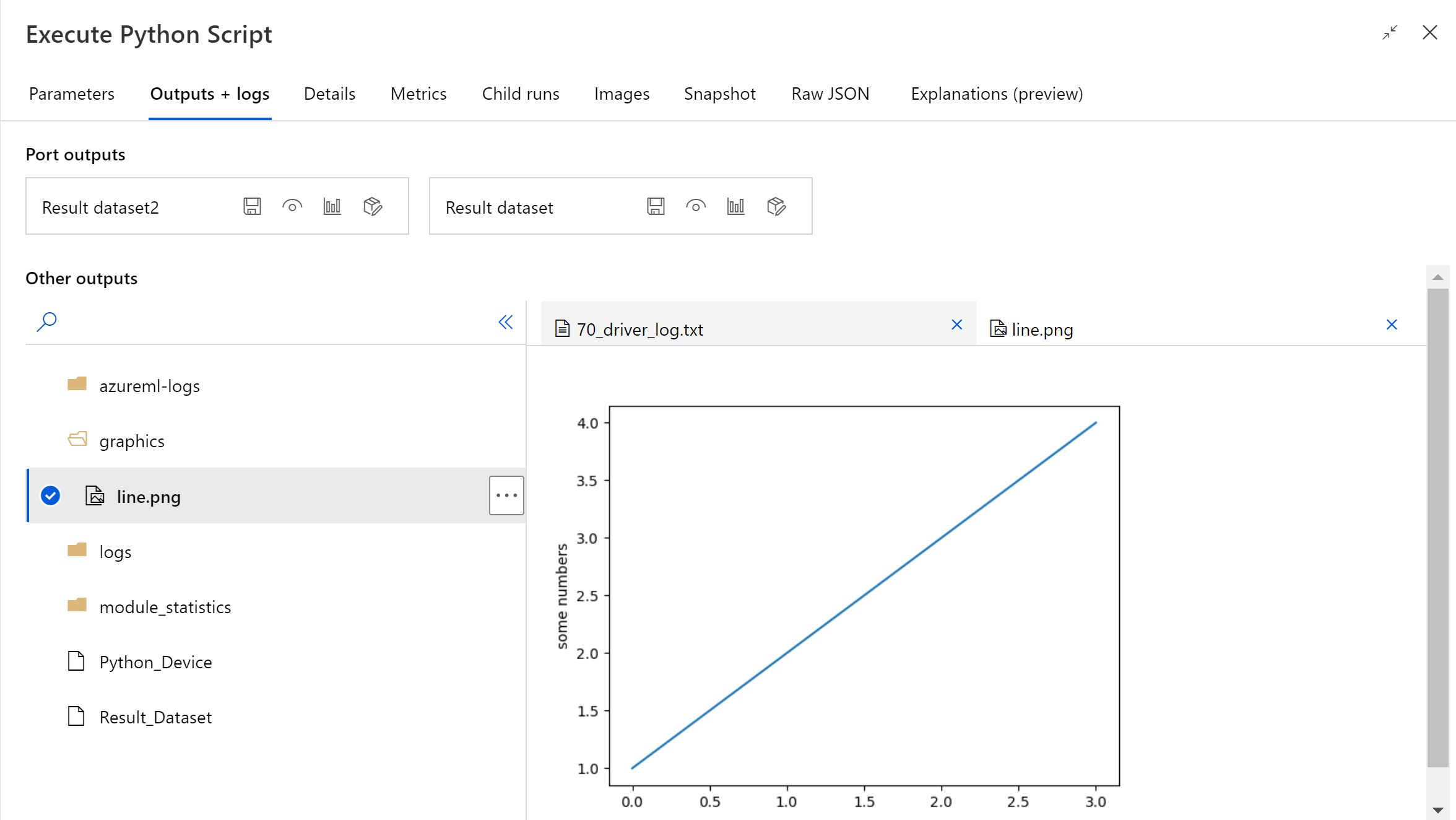
Вы также можете загрузить файл в любое хранилище данных, используя следующий код. Вы можете предварительно просмотреть файл только в своей учетной записи хранения.
import pandas as pd
# The entry point function MUST have two input arguments.
# If the input port is not connected, the corresponding
# dataframe argument will be None.
# Param<dataframe1>: a pandas.DataFrame
# Param<dataframe2>: a pandas.DataFrame
def azureml_main(dataframe1 = None, dataframe2 = None):
# Execution logic goes here
print(f'Input pandas.DataFrame #1: {dataframe1}')
from matplotlib import pyplot as plt
import os
plt.plot([1, 2, 3, 4])
plt.ylabel('some numbers')
img_file = "line.png"
# Set path
path = "./img_folder"
os.mkdir(path)
plt.savefig(os.path.join(path,img_file))
# Get current workspace
from azureml.core import Run
run = Run.get_context(allow_offline=True)
ws = run.experiment.workspace
# Get a named datastore from the current workspace and upload to specified path
from azureml.core import Datastore
datastore = Datastore.get(ws, datastore_name='workspacefilestore')
datastore.upload(path)
return dataframe1,
Настройка выполнения скрипта Python
Компонент выполнения скрипта Python содержит пример кода Python, который можно использовать в качестве отправной точки. Чтобы настроить компонент выполнения скрипта Python, нужно предоставить набор входных данных и выполняемый код Python в текстовом поле скрипт Python.
Добавьте компонент выполнения скрипта Python в конвейер.
Добавьте и подключитесь dataSet1 любые наборы данных из конструктора, которые вы хотите использовать для ввода. Сошлитесь на этот набор данных в скрипте Python как DataFrame1.
Использовать набор данных необязательно. Используйте его, если хотите создать данные с помощью Python, или используйте код Python для импорта данных непосредственно в компонент.
Этот компонент поддерживает добавление второго набора данных в DataSet2. Сошлитесь на этот набор данных в скрипте Python как DataFrame2.
Наборы данных, хранящиеся в модуле Машинного обучения Azure, автоматически преобразуются в кадры с данными из библиотеки Pandas при загрузке с этим компонентом.
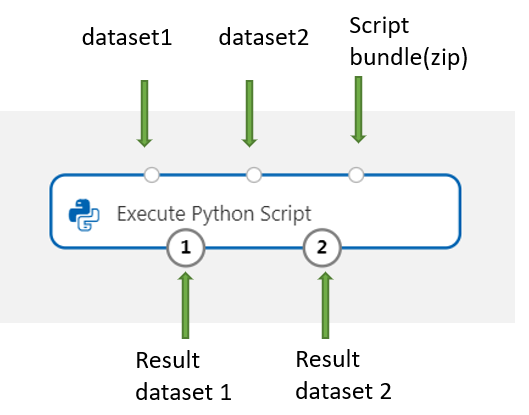
Чтобы включить новые пакеты или код Python, подключите сжатый ZIP-файл, содержащий эти дополнительные ресурсы, в порт пакета сценариев. Если размер скрипта превышает 16 КБ, используйте порт пакета сценариев, чтобы избежать ошибок, например Командная строка, превышает ограничение в 16597 символов.
- Упакуйте скрипт и другие дополнительные ресурсы в ZIP-файл.
- Отправьте ZIP-файл в качестве Файла набора данных в студию.
- Перетащите компонент набора данных из списка Наборы данных в левой панели компонента на странице конструктора разработки.
- Подключите компонент набора данных к порту Пакет скрипта компонента выполнения скрипта Python.
Любой файл, содержащийся в загруженном ZIP-архиве, можно использовать во время выполнения конвейера. Если архив содержит структуру каталогов, структура сохраняется.
Внимание
Используйте уникальное и понятное имя для файлов в пакете сценариев, поскольку некоторые распространенные слова (например
test,appи т. д.) зарезервированы для встроенных служб.Ниже приведен пример пакета сценариев, который содержит файл скрипта Python и txt-файл:
Ниже приведено содержимое
my_script.py:def my_func(dataframe1): return dataframe1Ниже приведен пример кода, демонстрирующий использование файлов в пакете скриптов.
import pandas as pd from my_script import my_func def azureml_main(dataframe1 = None, dataframe2 = None): # Execution logic goes here print(f'Input pandas.DataFrame #1: {dataframe1}') # Test the custom defined Python function dataframe1 = my_func(dataframe1) # Test to read custom uploaded files by relative path with open('./Script Bundle/my_sample.txt', 'r') as text_file: sample = text_file.read() return dataframe1, pd.DataFrame(columns=["Sample"], data=[[sample]])В текстовом поле скрипт Python введите или вставьте допустимый скрипт Python.
Примечание.
Будьте внимательны при написании скрипта. Убедитесь в отсутствии синтаксических ошибок, таких как использование необъявленных переменных или неимпортированных компонентов или функций. Обратите особое внимание на список предварительно установленных компонентов. Чтобы импортировать компоненты, которых нет в списке, установите соответствующие пакеты в скрипте, например:
import os os.system(f"pip install scikit-misc")Текстовое поле скрипта Python заполняется с помощью некоторых инструкций в комментариях, а также образцов кода для доступа к данным и вывода данных. Этот код необходимо изменить или заменить. Следуйте соглашениям Python для отступов и регистра:
- Скрипт должен содержать функцию с именем
azureml_mainв качестве точки входа для этого компонента. - Функция точки входа должна иметь два входных аргумента,
Param<dataframe1>иParam<dataframe2>, даже если эти аргументы не используются в скрипте. - ZIP-файлы, подключенные к третьему порту ввода, распаковываются и хранятся в каталоге
.\Script Bundle, который также добавляется в Pythonsys.path.
Если ZIP-файл содержит
mymodule.py, импортируйте его с помощью командыimport mymodule.В конструктор можно вернуть два набора данных, которые должны быть последовательностью типа
pandas.DataFrame. Вы можете создавать другие выходные данные в коде Python и записывать их непосредственно в службу хранилища Azure.Предупреждение
Не рекомендуется подключаться к базе данных или другим внешним хранилищам в компоненте выполнения скрипта Python. Можно использовать компонент импорта данных и компонент экспорта данных
- Скрипт должен содержать функцию с именем
Отправьте конвейер.
Если компонент завершен, проверьте выходные данные, если они ожидались.
Если произошел сбой компонента, необходимо выполнить некоторые действия по устранению неполадок. Выберите компонент и откройте Выходные данные и журналы в правой панели. Откройте 70_driver_log.txt и выполните поиск в azureml_main, так вы сможете найти строку, которая вызвала ошибку. Например, "File "/tmp/tmp01_ID/user_script.py", line 17, in azureml_main" означает, что ошибка произошла в строке 17 вашего скрипта Python.
Результаты
Результаты любых вычислений с помощью внедренного кода Python должны быть предоставлены как pandas.DataFrame, что автоматически преобразуется в формат набора данных машинное обучение Azure. Затем можно использовать результаты с другими компонентами в конвейере.
Компонент возвращает два набора данных:
Набор данных Results 1, определяемый первым возвращенным кадром данных Pandas в скрипте Python.
Набор данных Results 2, определяемый вторым возвращенным кадром данных Pandas в скрипте Python.
Предварительно установленные пакеты Python
Существуют следующие предустановленные пакеты:
- adal==1.2.2
- applicationinsights==0.11.9
- attrs==19.3.0
- azure-common==1.1.25
- azure-core==1.3.0
- azure-graphrbac==0.61.1
- azure-identity==1.3.0
- azure-mgmt-authorization==0.60.0
- azure-mgmt-containerregistry==2.8.0
- azure-mgmt-keyvault==2.2.0
- azure-mgmt-resource==8.0.1
- azure-mgmt-storage==8.0.0
- azure-storage-blob 1.5.0
- azure-storage-common==1.4.2
- azureml-core==1.1.5.5
- azureml-dataprep-native==14.1.0
- azureml-dataprep==1.3.5
- azureml-defaults==1.1.5.1
- azureml-designer-classic-modules==0.0.118
- azureml-designer-core==0.0.31
- azureml-designer-internal==0.0.18
- azureml-model-management-sdk==1.0.1b6.post1
- azureml-pipeline-core==1.1.5
- azureml-telemetry==1.1.5.3
- backports.tempfile==1.0
- backports.weakref==1.0.post1
- boto3==1.12.29
- botocore==1.15.29
- cachetools==4.0.0
- certifi==2019.11.28
- cffi==1.12.3
- chardet==3.0.4
- click==7.1.1
- cloudpickle==1.3.0
- configparser==3.7.4
- contextlib2==0.6.0.post1
- криптография==2.8
- cycler==0.10.0
- dill==0.3.1.1
- distro==1.4.0
- docker==4.2.0
- docutils==0.15.2
- dotnetcore2==2.1.13
- flask==1.0.3
- fusepy==3.0.1
- gensim==3.8.1
- google-api-core==1.16.0
- google-auth==1.12.0
- google-cloud-core==1.3.0
- google-cloud-storage==1.26.0
- google-resumable-media==0.5.0
- googleapis-common-protos==1.51.0
- gunicorn==19.9.0
- idna==2.9
- imbalanced-learn==0.4.3
- isodate==0.6.0
- itsdangerous==1.1.0
- jeepney==0.4.3
- jinja2==2.11.1
- jmespath==0.9.5
- joblib==0.14.0
- json-logging-py==0.2
- jsonpickle==1.3
- jsonschema==3.0.1
- kiwisolver==1.1.0
- liac-arff==2.4.0
- lightgbm==2.2.3
- MarkupSafe==1.1.1
- matplotlib==3.1.3
- more-itertools==6.0.0
- msal-extensions==0.1.3
- msal==1.1.0
- msrest==0.6.11
- msrestazure==0.6.3
- ndg-httpsclient==0.5.1
- nimbusml==1.6.1
- numpy==1.18.2
- oauthlib==3.1.0
- pandas==0.25.3
- pathspec==0.7.0
- pip==20.0.2
- portalocker==1.6.0
- protobuf==3.11.3
- pyarrow==0.16.0
- pyasn1-modules==0.2.8
- pyasn1==0.4.8
- pycparser==2.20
- pycryptodomex==3.7.3
- pyjwt==1.7.1
- pyopenssl==19.1.0
- pyparsing==2.4.6
- pyrsistent==0.16.0
- python-dateutil==2.8.1
- pytz==2019.3
- requests-oauthlib==1.3.0
- requests==2.23.0
- RSA-4.0
- ruamel.yaml==0.15.89
- s3transfer==0.3.3
- scikit-learn==0.22.2
- scipy==1.4.1
- SecretStorage==3.1.2
- setuptools==46.1.1.post20200323
- шесть==1.14.0
- smart-open==1.10.0
- urllib3==1.25.8
- websocket-client==0.57.0
- werkzeug==0.16.1
- wheel==0.34.2
Следующие шаги
Ознакомьтесь с набором доступных компонентов для машинного обучения Azure.