Ссылка на функции извлечения N-граммов из компонента текста
В этой статье описывается компонент в конструкторе Машинного обучения Azure. Используйте функции компонента извлечения N-граммов из текста для Создания признаков неструктурированных текстовых данных.
Настройка функций компонента извлечения N-граммов из текста
Компонент поддерживает следующие сценарии использования словаря N-граммов:
Создать новый словарь N-граммов из столбца с произвольным текстом.
Используйте существующий набор текстовых функций для создания признаков из столбца с произвольным текстом.
Оценка или развертывание модели, использующей N-граммы.
Создание нового словаря N-граммов
Добавьте функции компонента извлечения N-граммов из текста в конвейер и подключите набор данных, содержащий текст, который требуется обработать.
Используйте Текстовый столбец, чтобы выбрать столбец строкового типа, содержащий текст для извлечения. Поскольку результаты содержат большое количество текста, можно обрабатывать только один столбец за раз.
Задайте для параметра Режим словаря значение Создать, чтобы указать, что вы создаете новый список функций N-граммов.
Задайте Размер N-граммов, чтобы указать максимальный размер N-граммов для извлечения и хранения.
Например, если ввести 3, будут созданы униграмм, биграмм и триграмм.
Функция взвешивания задает способ построения вектора возможностей документа и способ извлечения словаря из документов.
Вес двоичных файлов присваивает извлеченным N-граммам двоичное значение присутствия. Значение для каждого N-грамма равно 1, если он есть в документе, и 0 в противном случае.
Вес Tf назначает значение частотности терминов (TF) для извлеченных N-граммов. Значение каждого N-грамма равно частотности появления в документе.
Вес IDF назначает обратную оценку частотности в документе извлеченным N-граммам. Значение для каждого N-грамма — это журнал размера всего корпуса, поделенный на частотность во всем корпусе.
IDF = log of corpus_size / document_frequencyВес TF-IDF задает оценку частотности и обратной частотности появления в документе для извлеченных N-граммов. Значение каждого N-грамма — это произведение его частотности на обратную частотность в документе.
Задайте Минимальное число букв в одном слове в N-граммах.
Задайте Максимальное число букв в одном слове в N-граммах.
По умолчанию разрешено не более 25 символов на слово или токен.
Используйте Минимальную абсолютную частотность N-грамма в документе, чтобы определить минимальное число появлений для любого N-грамма, необходимое для его включения в словарь N-граммов.
Например, если значение по умолчанию равно 5, то все N-граммы должны появляться в корпусе как минимум пять раз, чтобы их можно было включить в словарь.
Задайте Максимальный коэффициент N-граммов документа — максимальное количество строк, содержащих определенные N-граммы, поделенное на число строк во всем корпусе.
Например, коэффициент 1 указывает, что даже если определенные N-граммы встречаются в каждой строке, они все равно будут добавлены в словарь. Как правило, слово, встречающиеся в каждой строке, считаются пропускаемыми и на входят в словарь. Чтобы отфильтровать зависимые от домена пропускаемые слова, попробуйте уменьшить этот коэффициент.
Важно!
Частота вхождений отдельных слов неоднородна. Она меняется от документа к документу. Например, при анализе комментариев клиента о конкретном продукте название продукта может быть очень частотным и близко к пропускаемому слову, но при этом быть важным термином в других контекстах.
Выберите параметр Нормализовать векторы признаков N-граммов для нормализации векторов признаков. Если этот параметр включен, каждый вектор признаков N-граммов делится на нормы L2.
Отправьте конвейер.
Использование существующего словаря N-граммов
Добавьте функции компонента извлечения N-граммов из текста в конвейер и подключите набор данных, содержащий текст, который требуется обработать, к порту Набор данных.
Используйте Текстовый столбец, чтобы выбрать столбец, содержащий текст, который необходим для создания признаков. По умолчанию компонент выбирает все столбцы типа строка. Для получения наилучших результатов обрабатывайте по одному столбцу за раз.
Добавьте сохраненный набор данных, содержащий ранее созданный словарь N-граммов, и подключите его к входному порту словаря. Кроме того, можно подключить выходные данные Результирующего словаря вышестоящего экземпляра компонента функций извлечения N-граммов из текста.
В поле Режим словарявыберите параметр обновить Только для чтения из раскрывающегося списка.
Параметр Только для чтения определяет только входной корпус словаря. Вместо определения частотности терминов из нового текстового набора данных (на левом входе) веса N-граммов из входного словаря применяются в текущем виде.
Совет
Используйте этот параметр, если вы оцениваете классификатор текста.
Дополнительные сведения о других параметрах см. в описании свойств в предыдущем разделе.
Отправьте конвейер.
Создание конвейера вывода, использующего N-граммы для развертывания конечной точки в режиме реального времени
Конвейер обучения, который содержит функцию извлечения N-граммов из текста и модель оценки для создания прогноза на основе тестового набора данных, имеет следующую структуру:
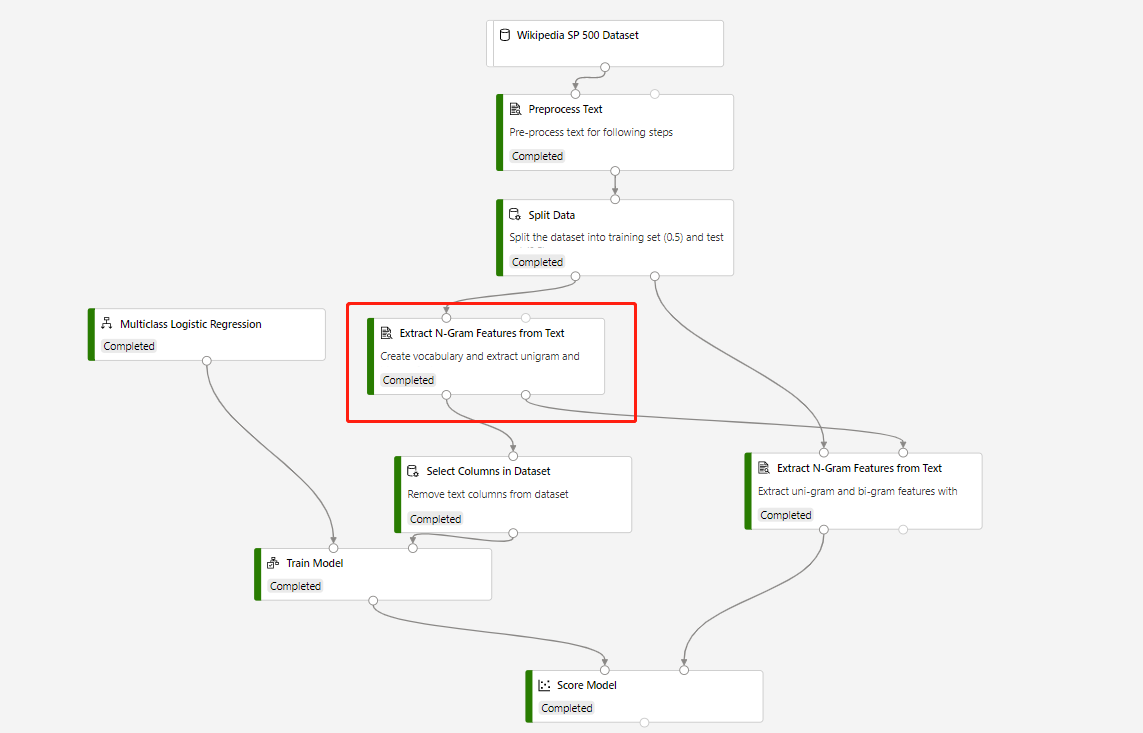
Режим словаря для обведенного компонента функции извлечения N-граммов из текста — Создать, Режим словаря для компонента, подключающегося к компоненту Оценки модели, — Только для чтения.
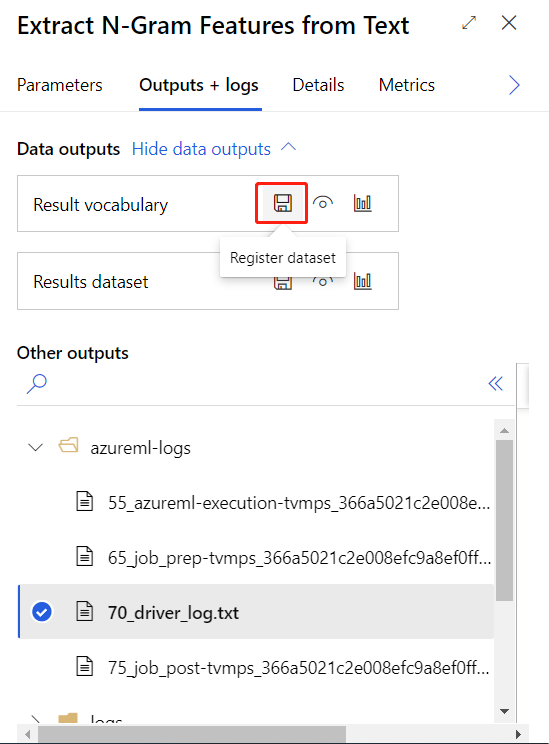
После успешной отправки конвейера обучения можно зарегистрировать выходные данные компонента в качестве набора данных.
Затем можно создать конвейер вывода в режиме реального времени. После создания конвейера вывода необходимо настроить конвейер вручную следующим образом:
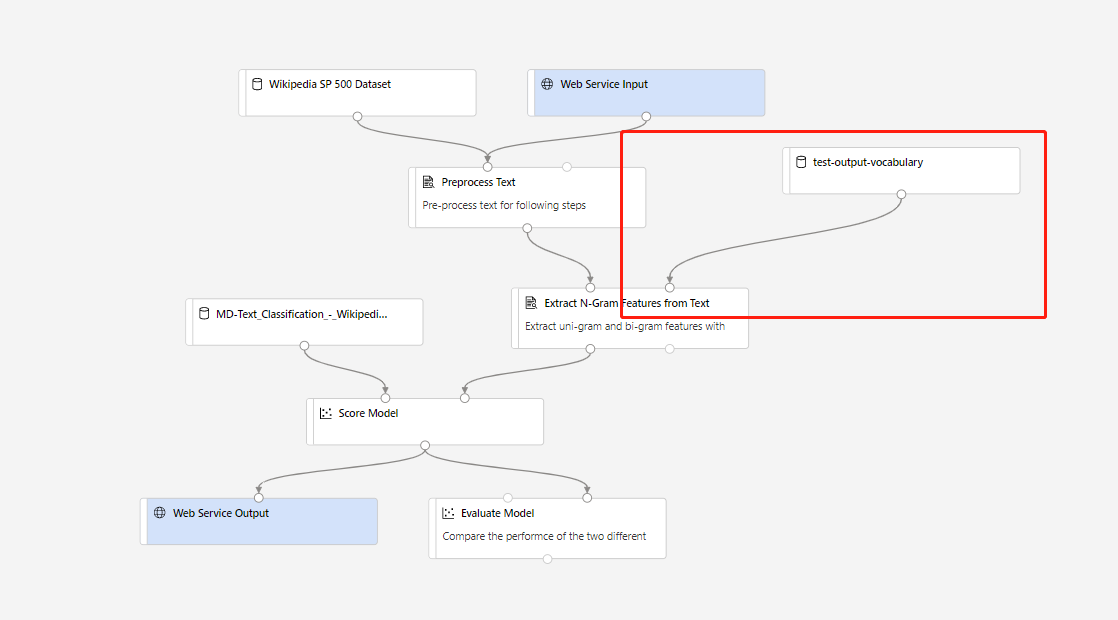
Затем отправьте конвейер вывода и разверните конечную точку в режиме реального времени.
Результаты
Компонент функций извлечения N-граммов из текста выводит два типа данных:
Результирующий набор данных. Эти выходные данные представляют собой сводку проанализированного текста вместе с извлеченными N-граммами. Столбцы, которые не были выбраны в параметре Текстовый столбец, не попадают в выходные данные. Для каждого столбца анализируемого текста компонент создает следующие столбцы:
- Матрица вхождений N-граммов: компонент создает столбец для каждого N-грамма, найденного в общей совокупности, и в каждом столбце добавляет оценку веса N-грамма в этой строке.
Результирующий словарь: в словаре содержится фактический словарь N-граммов, а также оценка частотности, полученная в ходе анализа. Набор данных можно сохранить для повторного использования с другим набором входных параметров или для последующего обновления. Можно также повторно использовать словарь для моделирования и оценки.
Результирующий словарь
Результирующий словарь: представляет собой фактический словарь N-граммов, а также содержит оценку частотности, полученную в ходе анализа. Показатели DF и IDF создаются независимо от других параметров.
- ID: идентификатор, формируемый для каждого уникального N-грамма.
- NGram: N-граммы. Пробелы или другие разделители слов заменяются символом подчеркивания.
- DF: оценка частоты для N-граммов в исходном корпусе.
- IDF: обратный коэффициент частотности N-грамма в исходном корпусе.
Этот набор данных можно обновить вручную, но при этом могут возникнуть ошибки. Пример:
- Если компонент находит дублирующиеся строки с одним и тем же ключом во входном словаре, отображается ошибка. Убедитесь, что ни одна из двух строк в словаре не содержит повторяющееся слово.
- Входная схема наборов данных словаря должна точно совпадать, включая имена и типы столбцов.
- Столбцы ID и DF должны содержать целые числа.
- Столбец IDF должен содержать числа с плавающей точкой.
Примечание
Не подключайте вывод данных непосредственно к компоненту обучения модели. Прежде чем передавать данные в модель обучения, необходимо удалить столбцы с произвольным текстом. В противном случае столбцы с произвольным текстом будут рассматриваться как функции категориальные значения.
Дальнейшие действия
Ознакомьтесь с набором доступных компонентов для Машинного обучения Azure.