Компонент группировки данных в бункеры
В этой статье описывается, как использовать компонент "Группирование данных в ячейки" в конструкторе машинного обучения Azure для группировки чисел или изменения распределения непрерывных данных.
Компонент "Группирование данных в ячейки" поддерживает несколько вариантов группирования данных. Вы можете настроить, каким образом задаются границы ячеек и как по ним распределяются значения. Например, администратор может сделать следующее:
- вручную ввести ряд значений, которые будут использоваться в качестве границ ячеек;
- присвоить значения ячейкам с помощью квантилей или процентилей;
- принудительно установить равномерное распределение значений по ячейкам.
Дополнительные сведения о квантовании и группировании
Группирование или группировка данных (иногда называемая квантование) — важный инструмент при подготовке числовых данных для машинного обучения. Это полезно в таких случаях.
Столбец непрерывных чисел содержит слишком много уникальных значений для эффективного моделирования. Таким образом, вы автоматически или вручную назначаете значения группам, чтобы создать меньший набор дискретных диапазонов.
Вы хотите заменить столбец чисел категориальными значениями, которые представляют определенные диапазоны.
Например, можно сгруппировать значения в столбце возраста в настраиваемые диапазоны, например 1–15, 16–22, 23–30 и т. д., для анализа демографического состава пользователей.
Набор данных включает несколько значений, которые значительно выходят за пределы ожидаемого диапазона, и эти значения оказывают слишком сильное влияние на обучаемую модель. Чтобы уменьшить смещение в модели, вы можете преобразовать данные в равномерное распределение с помощью метода квантилей.
При использовании этого метода компонент "Группирование данных в ячейки" определяет оптимальные расположения и ширину ячеек, чтобы в каждую ячейку попало приблизительное равное количество выборок. Затем, в зависимости от выбранного вами метода нормализации, значения в ячейках либо преобразуются в процентили, либо сопоставляются с номером ячейки.
Примеры группирования
На следующей схеме показано распределение числовых значений до и после группирования с помощью метода квантилей. Обратите внимание, что по сравнению с необработанными данными в левой части данные были сгруппированы и преобразованы в нормальное распределение с единичной дисперсией.
Так как существует много способов группирования данных и все из них можно настраивать, мы рекомендуем поэкспериментировать с различными методами и значениями.
Как настроить модуль "Группирование данных в ячейки"
Добавьте компонент Группирование данных в ячейки в ваш конвейер Конструктора. Этот компонент можно найти в категории Преобразование данных.
Соедините набор данных, содержащий числовые данные, с ячейкой. Квантование можно применять только к столбцам, содержащим числовые данные.
Если набор данных содержит столбцы с нечисловыми данными, используйте компонент Выбор столбцов в наборе данных, чтобы выбрать подмножество столбцов для работы.
Укажите режим группирования. Режим группирования определяет другие параметры, поэтому не забудьте сначала выбрать опцию Режим группирования. Поддерживаются следующие типы группирования:
Quantiles (Квантили). В рамках метода квантилей значения распределяются по ячейкам на основе процентильных рангов. Этот метод также известен как группирование по высоте.
Равные интервалы: с помощью этого параметра вы должны указать общее количество ячеек. Значения из столбца данных помещаются в ячейки таким образом, чтобы каждая ячейка имела одинаковый интервал между начальным и конечным значениями. В результате в некоторых ячейках может оказаться больше элементов, если значения плотнее распределены в районе определенной точки.
Custom Edges (Настраиваемые границы). Для каждой ячейки можно задать начальное значение. Значение границы всегда является нижней границей ячейки.
Например, предположим, что вы хотите сгруппировать значения в две ячейки. У одного будут значения больше 0, а у другого будут значения меньше или равные 0. В этом случае для границ ячеек вы вводите 0 в разделенном запятыми списке границ ячеек. Выходные данные компонента будут 1 и 2, что указывает индекс ячейки для каждого значения строки. Обратите внимание, что список значений, разделенных запятыми, должен быть в порядке возрастания, например 1, 3, 5, 7.
Примечание
Режим MDL энтропии определен в Studio (классическая), а соответствующий пакет с открытым исходным кодом, который можно использовать для поддержки в конструкторе, еще не существует.
Если вы применяете режимы группирования Квантили и Равные интервалы, используйте параметр Число интервалов, чтобы указать, сколько интервалов или квантилей вы хотите создать.
Для параметра Столбцы в группировании с помощью селектора выберите столбцы, значения в которых нужно группировать. Столбцы должны содержать данные числового типа.
Для всех подходящих столбцов из тех, что вы выберете, применяется одинаковое правило группирования. Если вам нужно объединить несколько столбцов с помощью другого метода, используйте отдельный экземпляр компонента "Группирование данных в ячейки" для каждого набора столбцов.
Предупреждение
Если вы выберете столбец недопустимого типа, будет сгенерирована ошибка времени выполнения. Компонент возвращает ошибку, как только он обнаруживает столбец недопустимого типа. Если появляется сообщение об ошибке, проверьте все выбранные столбцы. В ошибке не приводится список недопустимых столбцов.
В параметре Output mode (Режим вывода) укажите, как следует выводить квантованные значения:
Append (Добавление): создается новый столбец с разделенными на группы значениями и добавляется во входную таблицу.
Inplace (Замещение). Исходные значения в наборе данных заменяются новыми.
ResultOnly (Только результат). Возвращаются только столбцы с результирующими данными.
Если вы выбираете режим Квантилей, используйте опцию Нормализация квантилей, чтобы определить, как значения нормализуются перед сортировкой по квантилям. Обратите внимание, что нормализация значений преобразует значения, но не влияет на конечное количество ячеек.
Поддерживаются следующие типы нормализации:
Percent (Проценты): значения нормализованы в диапазоне [0,100].
PQuantile (Параллельные квантили): значения нормализованы в диапазоне [0,1].
QuantileIndex (Индекс квантилей): значения нормализованы в диапазоне [1, количество ячеек].
Если вы выбрали вариант Custom Edges (Настраиваемые границы), введите разделенный запятыми список чисел, которые будут использоваться как границы ячеек, в текстовое поле Comma-separated list of bin edges (Разделенный запятыми список границ ячейки).
Значения отмечают точку, разделяющую ячейки. Например, если вы введете одно значение граничной ячейки, будут созданы две ячейки. При вводе двух граничных значений ячейки будут созданы три ячейки.
Значения должны быть отсортированы в порядке создания ячеек, от самого низкого до самого высокого.
Выберите параметр Пометить столбцы как категориальные, чтобы указать, что квантованные столбцы следует обрабатывать как категориальные переменные.
Отправьте конвейер.
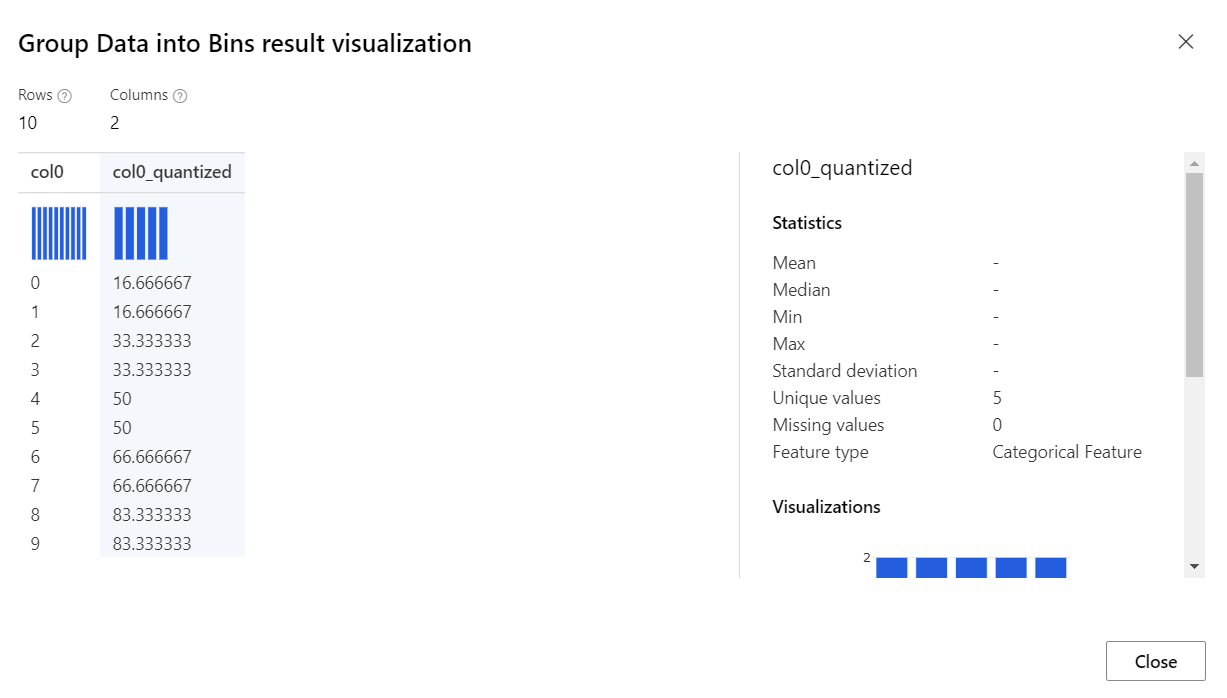
Результаты
Компонент "Группирование данных в ячейки" возвращает набор данных, в котором все элементы сгруппированы в соответствии с выбранным режимом.
Он также возвращает Преобразование группирования. Эту функцию можно передать компоненту Применение преобразования для объединения новых выборок данных с использованием того же режима и параметров группирования.
Совет
Если вы используете группирование для своих обучающих данных, вы должны использовать тот же метод группирования для данных, который вы используете для тестирования и прогнозирования. Также вам необходимо использовать одни и те же ячейки и ширину ячеек.
Чтобы данные всегда преобразовывались с использованием одного и того же метода группирования, мы рекомендуем сохранять полезные преобразования данных. Затем примените их к другим наборам данных с помощью компонента Применить преобразование.
Дальнейшие действия
Ознакомьтесь с набором доступных компонентов для Машинного обучения Azure.