Компонент "Обучение модели"
В этой статье описывается компонент в конструкторе Машинного обучения Azure.
С помощью этого компонента можно обучать модель классификации или регрессии. Обучение выполняется после определения модели и установки ее параметров. Также требуется наличие данных с тегами. Модуль Обучение модели можно также использовать для повторного обучения существующей модели с новыми данными.
Принцип работы процесса обучения
В Машинном обучении Azure создание и использование модели машинного обучения обычно состоит из трех этапов.
Необходимо настроить модель, выбрав определенный тип алгоритма и определив ее параметры или гиперпараметры. Выберите любой из следующих типов моделей:
- Модели классификации на основе нейронных сетей, деревьев и лесов принятия решений и других алгоритмов.
- Модели регрессии, которые могут включать стандартную линейную регрессию или использовать другие алгоритмы, включая нейронные сети и байесовскую регрессию.
Предоставьте помеченный набор данных, который имеет данные, совместимые с алгоритмом. Подключите данные и модель к модулю Обучение модели.
При обучении создается определенный двоичный формат (iLearner), который позволяет инкапсулировать шаблоны статистики, полученные из данных. Вы не можете напрямую изменять или читать этот формат. Однако другие компоненты могут использовать эту обученную модель.
Вы также можете просматривать свойства модели. Дополнительные сведения см. в разделе результатов.
После завершения обучения используйте обученную модель с одним из компонентов оценки, чтобы создать прогнозы на основе новых данных.
Использование модуля "Модель обучения"
Добавьте компонент Обучение модели в конвейер. Этот компонент можно найти в категории Машинное обучение. Раскройте узел Обучение и перетащите компонент Модель обучения в свой конвейер.
В левой части входных данных присоедините необученную модель. Прикрепите набор данных для обучения к правому вводу параметра Модель обучения.
Набор данных для обучения должен содержать столбец меток. Все строки без меток игнорируются.
В разделе Столбец меток выберите Изменить столбец на правой панели компонента и выберите один столбец, содержащий результаты, которые модель может использовать для обучения.
Для решения проблем с классификацией столбец меток должен содержать либо категориальные, либо дискретные значения. Примеры могут включать оценку с ответами "да/нет", код или имя классификации заболеваний или группу по уровню доходов. Если выбрать некатегориальный столбец, компонент будет возвращать ошибку во время обучения.
Для проблем регрессии столбец метки должен содержать числовые данные, которые представляют переменную ответа. В идеале числовые данные представляют числовую шкалу.
В качестве примера можно привести оценку кредитного риска, прогнозируемое время на отказ для жесткого диска или прогнозируемое количество звонков в центр обработки вызовов для заданного дня или времени. Если не выбрать числовой столбец, может появиться сообщение об ошибке.
- Если не указан используемый столбец метки, машинное обучение Azure попытается определить подходящий столбец метки с помощью метаданных набора данных. Если вы выбрали неправильный столбец, используйте селектор столбцов, чтобы исправить его.
Совет
Если при использовании селектора столбцов возникают проблемы, просмотрите советы в статье Выбор столбцов в наборе данных. В ней описаны некоторые распространенные сценарии и советы по использованию параметров WITH RULES (С правилами) и По имени.
Отправьте конвейер. Если у вас много данных, это может занять некоторое время.
Важно!
Если у вас есть столбец идентификатора, который является идентификатором для каждой строки, или текстовый столбец, который содержит слишком много уникальных значений, в модуле Обучение модели может возникнуть сообщение об ошибке Number of unique values in column: "{column_name}" is greater than allowed (Число уникальных значений в столбце "{имя_столбца}" больше допустимого).
Это связано с тем, что столбец достиг порога уникальных значений и могут возникнуть проблемы нехватки памяти. Вы можете использовать функцию Изменить метаданные, чтобы пометить столбец как Clear feature (Очистить функцию), и он не будет использоваться для обучения. Или используйте компонент Extract N-Gram Features from Text (Извлечение N-грамм из текста), чтобы выполнить предварительную обработку текстового столбца. Дополнительные сведения об ошибке см. в статье Код ошибки конструктора.
Интерпретируемость модели
Интерпретируемость модели позволяет понять модель машинного обучения и представить основу для принятия решений в понятной для людей форме.
В настоящее время компонент Обучение модели поддерживает использование пакета интерпретации для пояснения моделей машинного обучения. Поддерживаются следующие встроенные алгоритмы:
- Линейная регрессия
- Регрессия нейронной сети
- Регрессия увеличивающегося дерева принятия решений
- Регрессия с использованием модели леса принятия решений
- Регрессия Пуассона
- Двухклассовая регрессионная логистическая модель
- Двухклассовая машина опорных векторов
- Двухклассовое увеличивающееся дерево принятия решений
- Двухклассовый лес принятия решений
- Многоклассовый лес принятия решений.
- Многоклассовая логистическая регрессия
- Многоклассовая нейронная сеть
Чтобы создать пояснение к модели, можно выбрать значение True в раскрывающемся списке Model Explanation (Пояснение к модели) в компоненте "Обучение модели". По умолчанию в компоненте Обучение модели задано значение False. Обратите внимание, что для создания пояснений требуются дополнительные затраты на вычисление.
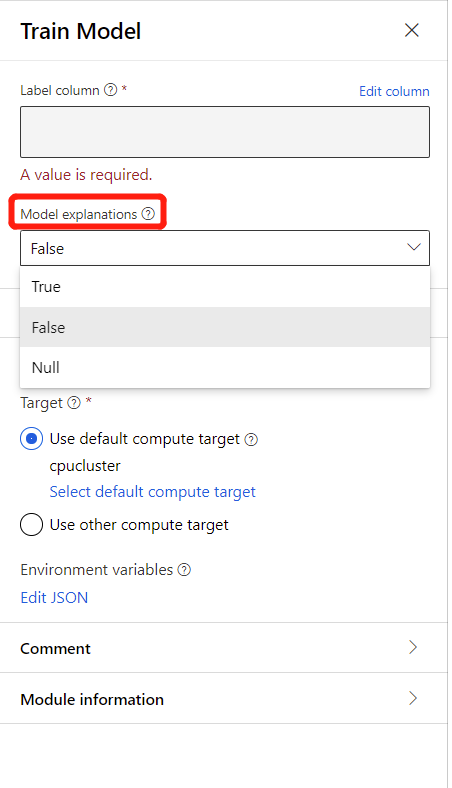
После завершения выполнения конвейера можно перейти на вкладку Explanations (Пояснения) на правой панели компонента Обучение модели и изучить сведения о производительности модели, наборе данных и важности признака.
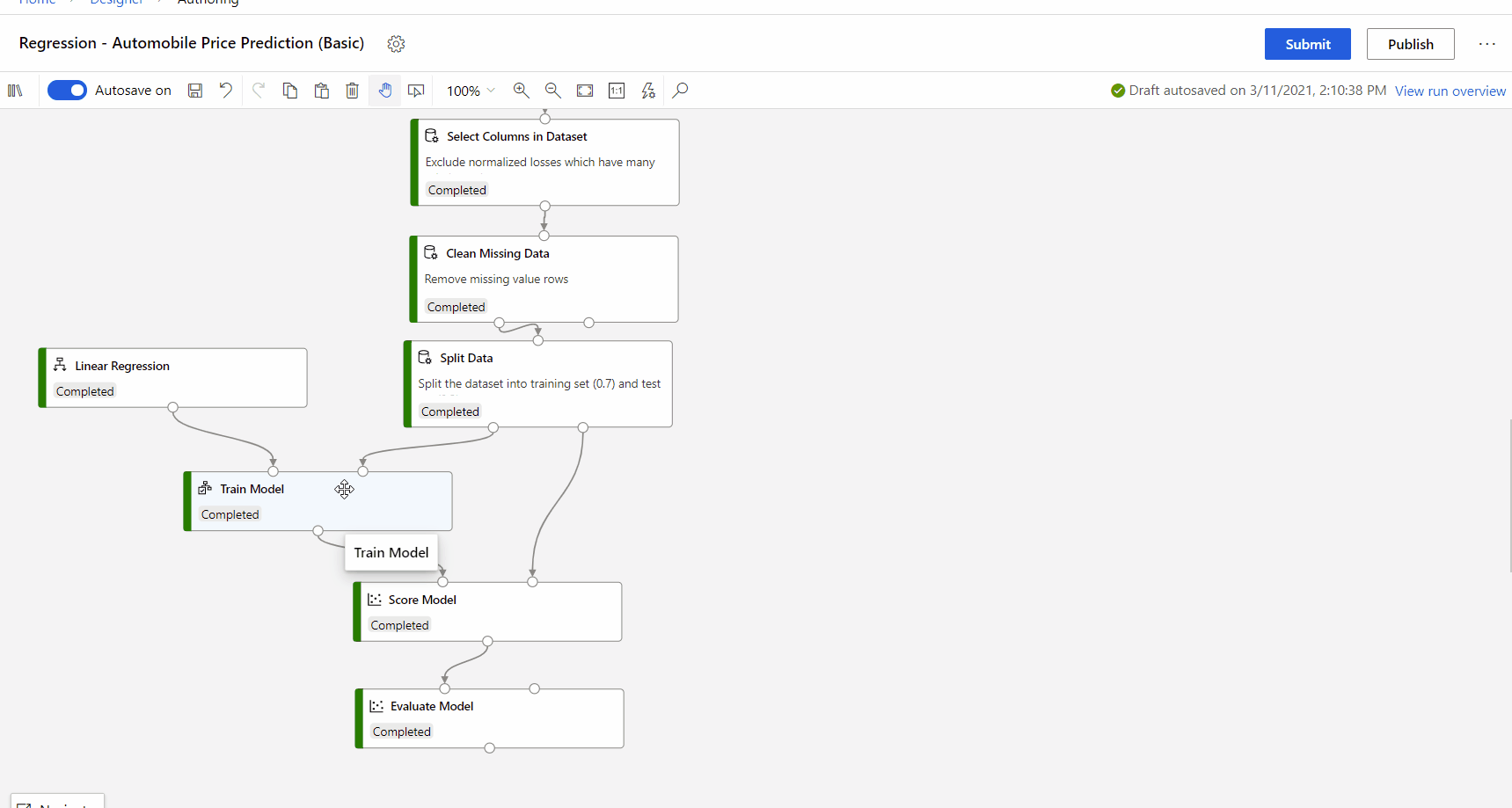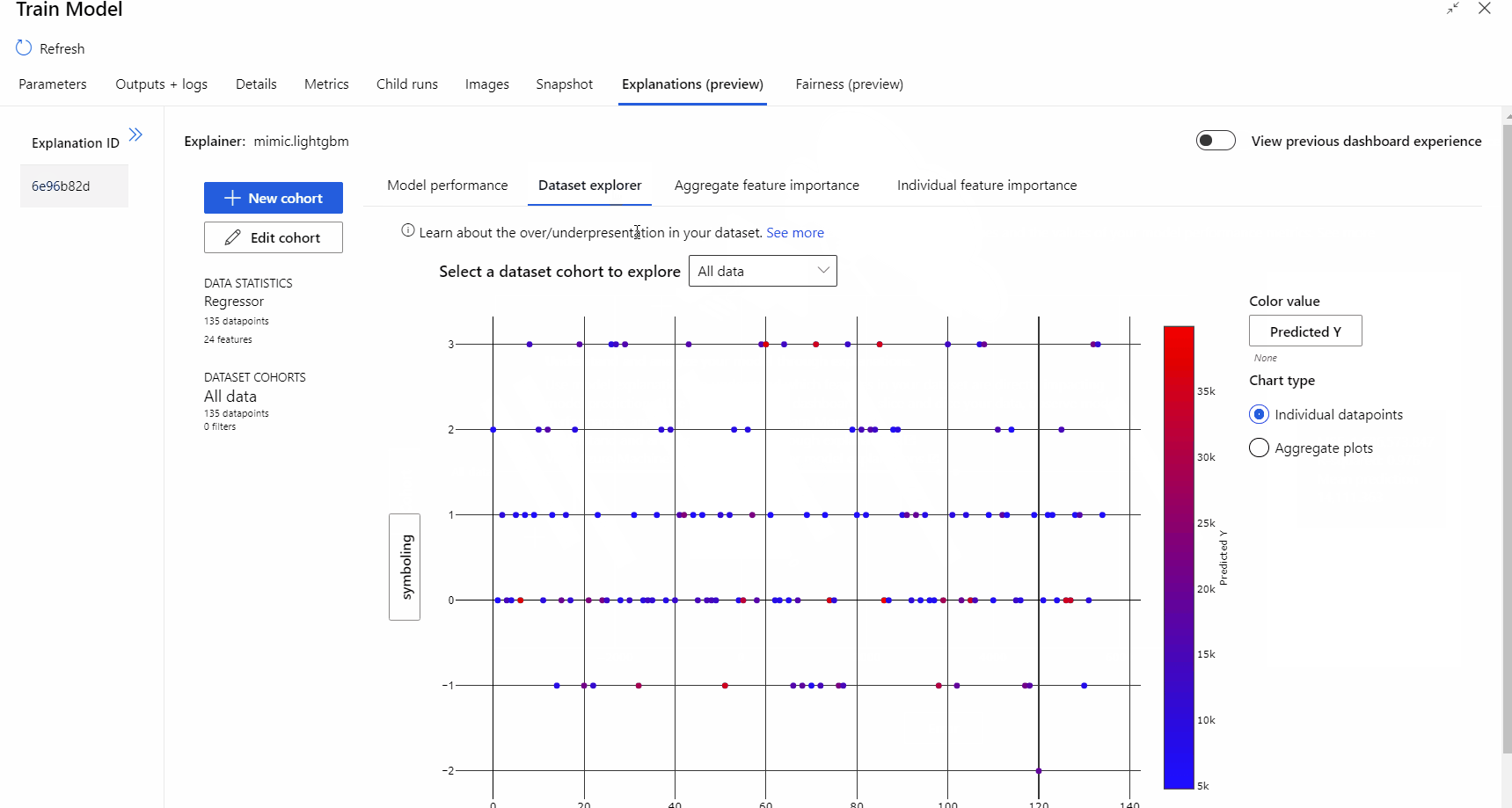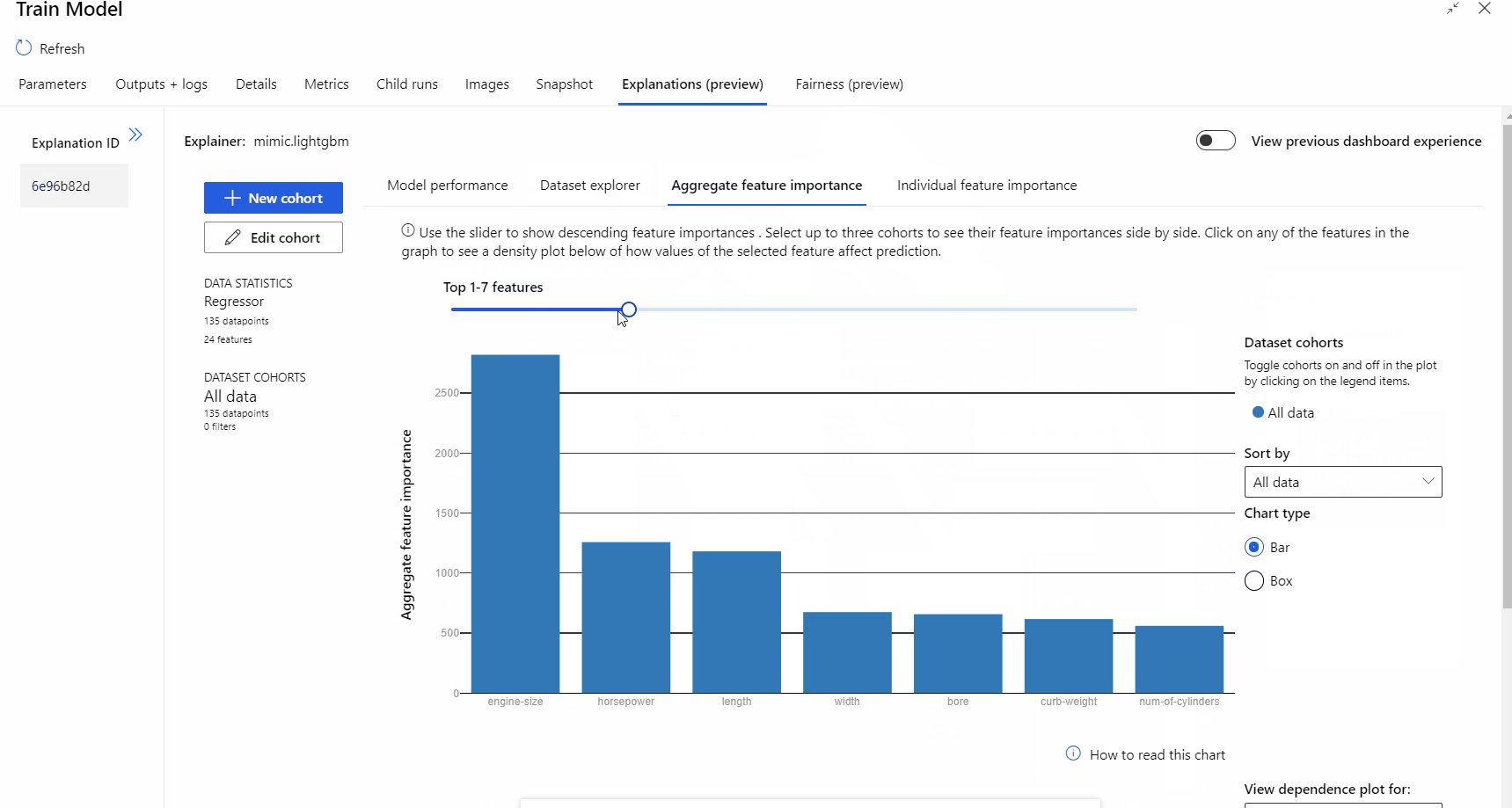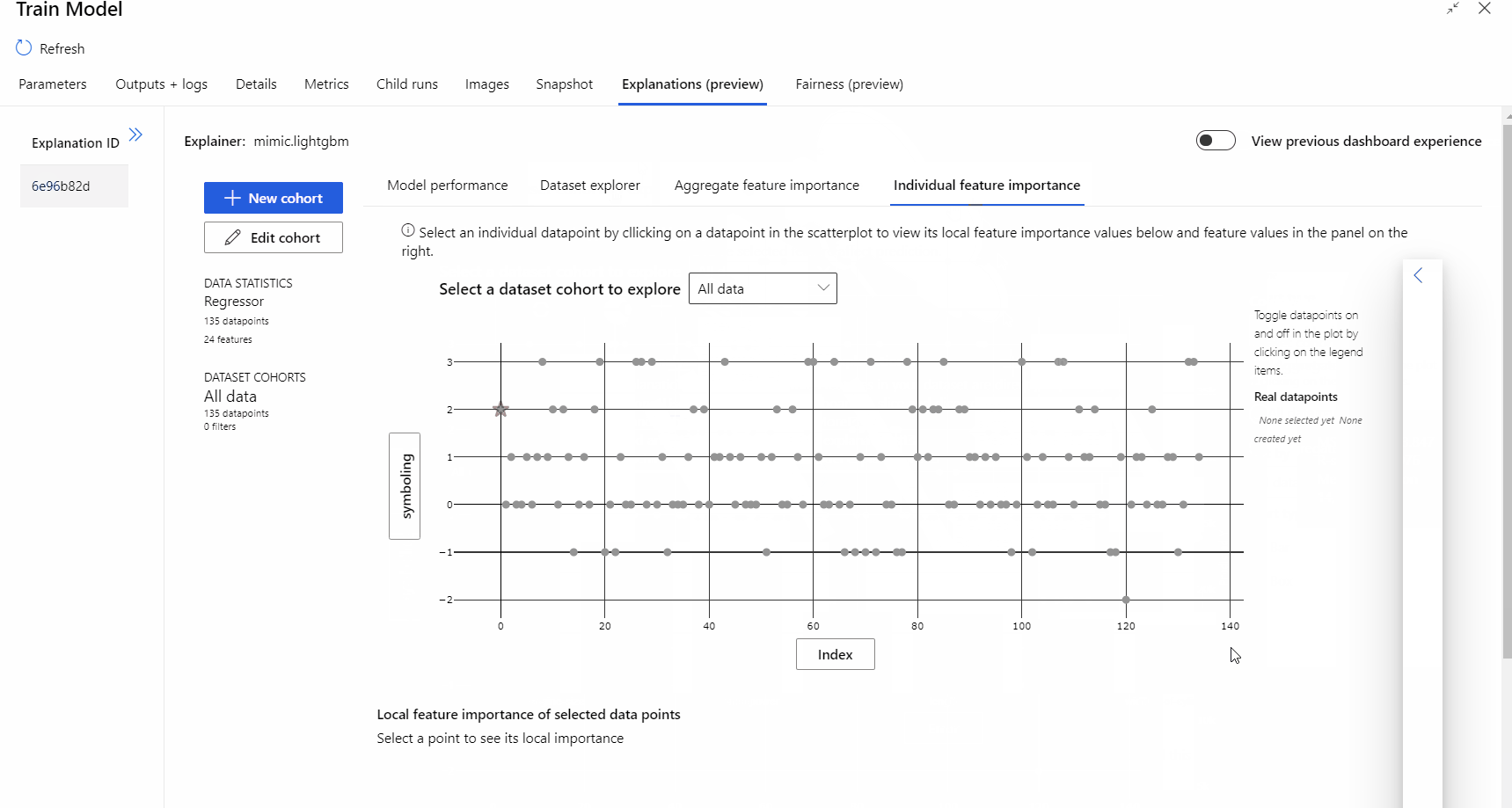
Дополнительные сведения об использовании пояснений к модели в Машинном обучении Azure см. в разделе Интерпретации моделей машинного обучения.
Результаты
После обучения модели выполните следующие действия:
Чтобы использовать модель в других конвейерах, выберите компонент и щелкните значок Register dataset (Регистрация набора данных) на вкладке Выходные данные на правой панели. Доступ к сохраненным моделям можно получить в палитре компонента в разделе Datasets (Наборы данных).
Чтобы использовать модель для прогнозирования новых значений, подключите ее к компоненту Оценка модели вместе с новыми входными данными.
Дальнейшие действия
Ознакомьтесь с набором доступных компонентов для Машинного обучения Azure.