Примеры для Виртуальных машин для обработки и анализа данных Azure
Azure Виртуальная машина для обработки и анализа данных (DSVM) включает полный набор примеров кода. Эти примеры содержат записные книжки и сценарии Jupyter на таких языках, как Python и R.
Примечание.
Дополнительные сведения о запуске записных книжек Jupyter на виртуальных машинах для обработки и анализа данных см. в разделе Access Jupyter .
Необходимые компоненты
Для выполнения этих примеров необходимо иметь подготовленный Виртуальная машина для обработки и анализа данных Ubuntu.
Доступные примеры
| Категории примеров | Description | Ячейки |
|---|---|---|
| Язык Python | Примеры, объясняющие, как подключиться к облачным хранилищам данных Azure и как работать с Машинное обучение Azure сценариями. Язык Python |
~notebooks |
| Язык Julia | Содержит подробное описание построения и глубокого обучения на языке Julia. Объясняет, как вызывать C и Python из Джулии. Язык Julia |
Windows: ~notebooks/Julia_notebooksLinux: ~notebooks/julia |
| Машинное обучение Azure | Показывает, как создавать модели машинного обучения и глубокого обучения с помощью Машинное обучение. Модели можно развертывать в любом расположении. Используйте автоматическое машинное обучение и интеллектуальную настройку гиперпараметров. Используйте управление моделями и распределенное обучение. Машинное обучение |
~notebooks/AzureML |
| Записные книжки PyTorch | Примеры глубокого обучения, использующие нейронные сети на основе PyTorch. Записные книжки есть как для базовых, так и для расширенных сценариев. Записные книжки PyTorch |
~notebooks/Deep_learning_frameworks/pytorch |
| TensorFlow | Различные примеры и методы нейронной сети, реализованные с помощью платформы TensorFlow. TensorFlow |
~notebooks/Deep_learning_frameworks/tensorflow |
| H2O | Примеры на основе Python, в которых используется H2O, для практических сценариев по решению проблем. H2O |
~notebooks/h2o |
| Язык SparkML | Примеры, использующие функции набора средств Apache Spark MLLib с помощью pySpark и MMLSpark: Microsoft Машинное обучение для Apache Spark в Apache Spark 2.x. Язык SparkML |
~notebooks/SparkML/pySpark~notebooks/MMLSpark |
| XGBoost | Стандартные примеры машинного обучения в XGBoost, например классификация и регрессия. XGBoost |
Windows: \dsvm\samples\xgboost\demo |
Доступ к Jupyter
Доступ к Jupyter можно получить, щелкнув значок Jupyter на рабочем столе или в меню приложения. Также можно получить доступ к Jupyter с помощью Linux Edition виртуальной машины для обработки и анализа данных. Для удаленного доступа из веб-браузера посетите https://<Full Domain Name or IP Address of the DSVM>:8000 Ubuntu.
Чтобы добавить исключения и сделать доступ Jupyter доступным через браузер, используйте следующее руководство.
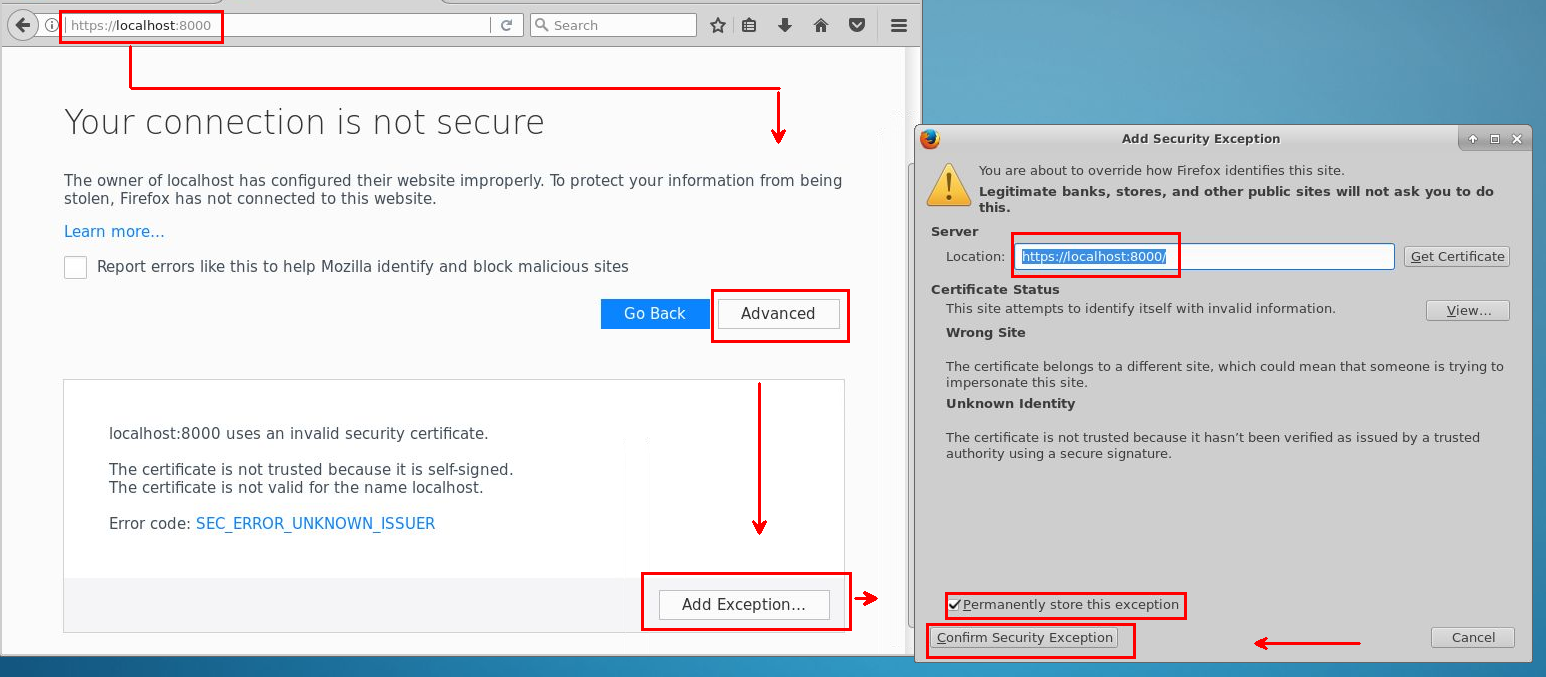
Войдите с тем же паролем, который вы используете для входа Виртуальная машина для обработки и анализа данных.
Домашняя страница Jupyter

Язык R

Язык Python

Язык Julia

Машинное обучение Azure

PyTorch

TensorFlow

H2O

SparkML

XGBoost

Обратная связь
Ожидается в ближайшее время: в течение 2024 года мы постепенно откажемся от GitHub Issues как механизма обратной связи для контента и заменим его новой системой обратной связи. Дополнительные сведения см. в разделе https://aka.ms/ContentUserFeedback.
Отправить и просмотреть отзыв по