ОБЛАСТЬ ПРИМЕНЕНИЯ: Расширение машинного обучения Azure CLI версии 2 (current)Python SDK azure-ai-ml версии 2 (current)
Расширение машинного обучения Azure CLI версии 2 (current)Python SDK azure-ai-ml версии 2 (current)
В этой статье описано, как управлять использованием ресурсов в развертывании путем настройки автомасштабирования на основе метрик и расписаний. Процесс автомасштабирования позволяет автоматически запускать нужный объем ресурсов для обработки нагрузки в приложении.
Сетевые конечные точки в Машинное обучение Azure поддерживают автомасштабирование путем интеграции с функцией автомасштабирования в Azure Monitor.
Автомасштабирование Azure Monitor позволяет задавать правила, которые активируют одно или несколько действий автомасштабирования при выполнении условий правил. Вы можете настроить масштабирование на основе метрик (например, использование ЦП больше 70%), масштабирование на основе расписания (например, правила масштабирования для пиковых рабочих часов) или сочетание двух. Дополнительные сведения см. в разделе Общие сведения об автомасштабировании в Microsoft Azure.

В настоящее время можно управлять автомасштабированием с помощью Azure CLI, REST API, Azure Resource Manager, пакета SDK Python или портал Azure на основе браузера.
Необходимые компоненты
Развернутая конечная точка. Дополнительные сведения см. в статье "Развертывание и оценка модели машинного обучения с помощью сетевой конечной точки".
Чтобы использовать автомасштабирование, роль microsoft.insights/autoscalesettings/write должна быть назначена удостоверению, которое управляет автомасштабированием. Вы можете использовать все встроенные или пользовательские роли, которые позволяют этому действию. Общие рекомендации по управлению ролями для Машинное обучение Azure см. в разделе "Управление пользователями и ролями". Дополнительные сведения о параметрах автомасштабирования из Azure Monitor см. в разделе автомасштабирование Microsoft.Insights.
Чтобы использовать пакет SDK Python для управления службой Azure Monitor, установите azure-mgmt-monitor пакет с помощью следующей команды:
pip install azure-mgmt-monitor
Определение профиля автомасштабирования
Чтобы включить автомасштабирование для сетевой конечной точки, сначала определите профиль автомасштабирования. Профиль задает емкость набора по умолчанию, минимальному и максимальному масштабируемости. В следующем примере показано, как задать количество экземпляров виртуальной машины по умолчанию, минимальной и максимальной емкости масштабирования.
ОБЛАСТЬ ПРИМЕНЕНИЯ: расширение машинного обучения Azure CLI версии 2 (текущее)
Если вы еще не задали параметры по умолчанию для Azure CLI, сохраните их. Чтобы не указывать параметры для подписки, рабочей области и группы ресурсов несколько раз, используйте следующий код:
az account set --subscription <subscription ID>
az configure --defaults workspace=<Azure Machine Learning workspace name> group=<resource group>
Задайте имена конечных точек и развертываний:
# set your existing endpoint name
ENDPOINT_NAME=your-endpoint-name
DEPLOYMENT_NAME=blue
Получите идентификатор Azure Resource Manager для развертывания и конечной точки:
# ARM id of the deployment
DEPLOYMENT_RESOURCE_ID=$(az ml online-deployment show -e $ENDPOINT_NAME -n $DEPLOYMENT_NAME -o tsv --query "id")
# ARM id of the deployment. todo: change to --query "id"
ENDPOINT_RESOURCE_ID=$(az ml online-endpoint show -n $ENDPOINT_NAME -o tsv --query "properties.\"azureml.onlineendpointid\"")
# set a unique name for autoscale settings for this deployment. The below will append a random number to make the name unique.
AUTOSCALE_SETTINGS_NAME=autoscale-$ENDPOINT_NAME-$DEPLOYMENT_NAME-`echo $RANDOM`
Создайте профиль автомасштабирования:
az monitor autoscale create \
--name $AUTOSCALE_SETTINGS_NAME \
--resource $DEPLOYMENT_RESOURCE_ID \
--min-count 2 --max-count 5 --count 2
ОБЛАСТЬ ПРИМЕНЕНИЯ: Пакет SDK для Python azure-ai-ml версии 2 (current)
Импортируйте необходимые модули:
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
from azure.mgmt.monitor import MonitorManagementClient
from azure.mgmt.monitor.models import AutoscaleProfile, ScaleRule, MetricTrigger, ScaleAction, Recurrence, RecurrentSchedule
import random
import datetime
Определите переменные для рабочей области, конечной точки и развертывания:
subscription_id = "<YOUR-SUBSCRIPTION-ID>"
resource_group = "<YOUR-RESOURCE-GROUP>"
workspace = "<YOUR-WORKSPACE>"
endpoint_name = "<YOUR-ENDPOINT-NAME>"
deployment_name = "blue"
Получение клиентов Машинное обучение Azure и Azure Monitor:
credential = DefaultAzureCredential()
ml_client = MLClient(
credential, subscription_id, resource_group, workspace
)
mon_client = MonitorManagementClient(
credential, subscription_id
)
Получение конечной точки и объектов развертывания:
deployment = ml_client.online_deployments.get(
deployment_name, endpoint_name
)
endpoint = ml_client.online_endpoints.get(
endpoint_name
)
Создание профиля автомасштабирования:
# Set a unique name for autoscale settings for this deployment. The following code appends a random number to create a unique name.
autoscale_settings_name = f"autoscale-{endpoint_name}-{deployment_name}-{random.randint(0,1000)}"
mon_client.autoscale_settings.create_or_update(
resource_group,
autoscale_settings_name,
parameters = {
"location" : endpoint.location,
"target_resource_uri" : deployment.id,
"profiles" : [
AutoscaleProfile(
name="my-scale-settings",
capacity={
"minimum" : 2,
"maximum" : 5,
"default" : 2
},
rules = []
)
]
}
)
В Студия машинного обучения Azure перейдите в рабочую область и выберите конечные точки в меню слева.
В списке доступных конечных точек выберите конечную точку для настройки:
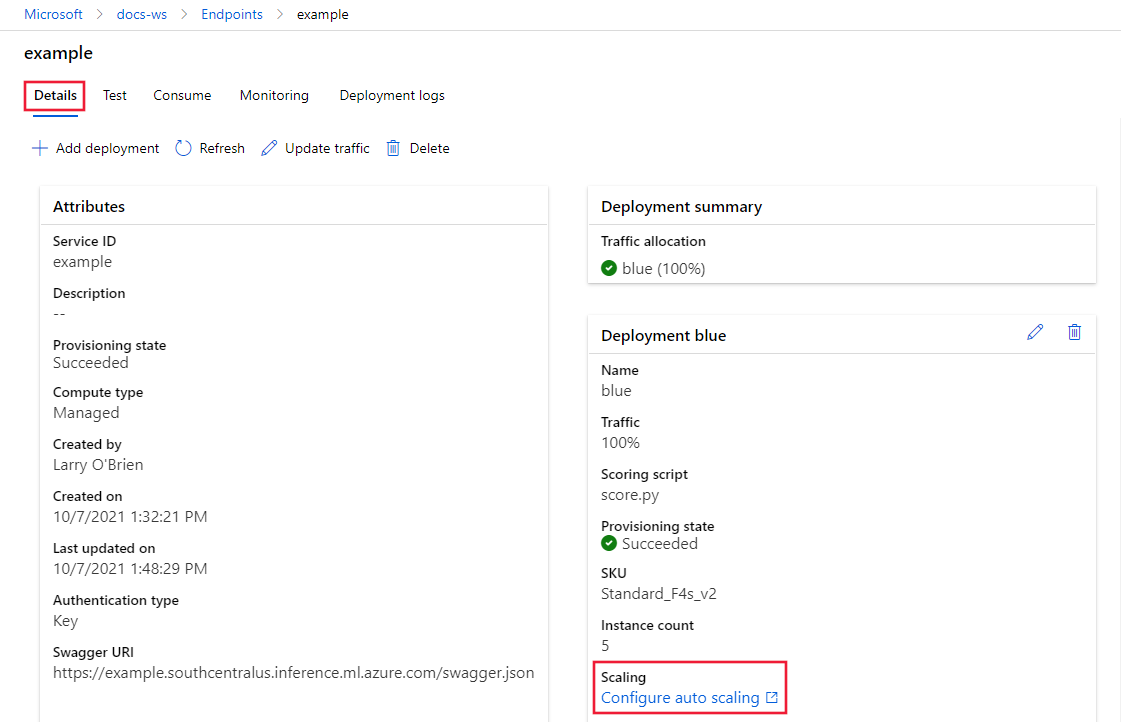
На вкладке "Сведения" для выбранной конечной точки выберите "Настроить автоматическое масштабирование".
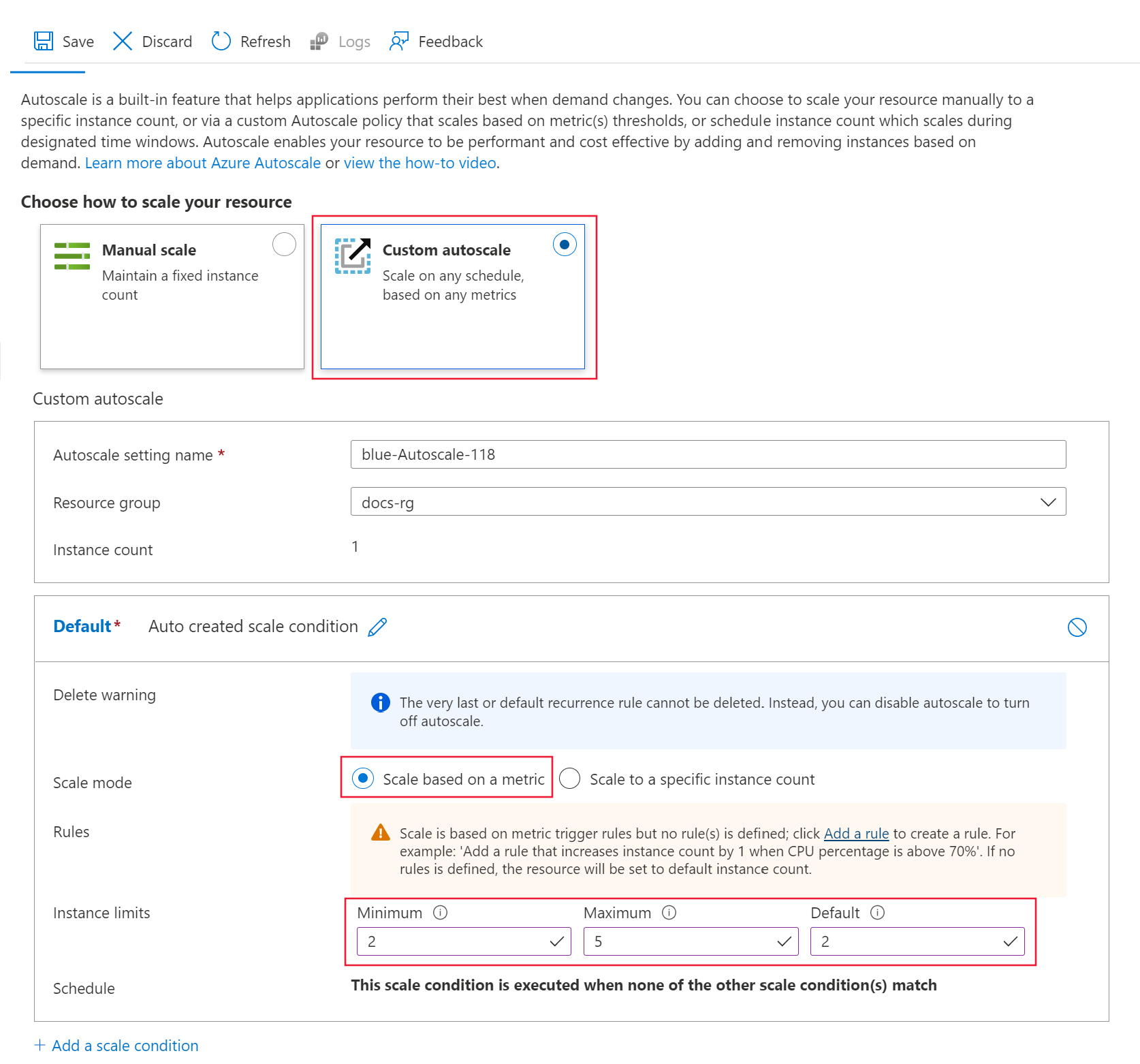
Для параметра "Выбор масштабирования ресурсов" выберите "Настраиваемый автомасштабирование", чтобы начать настройку.
Для параметра условия масштабирования по умолчанию настройте следующие значения:
-
Режим масштабирования: выбор шкалы на основе метрики.
-
Минимальное ограничение>экземпляра: задайте значение 2.
-
Максимальное ограничение> экземпляра: задайте значение 5.
-
Ограничения экземпляра>по умолчанию: задайте значение 2.
Оставьте область конфигурации открытой. В следующем разделе описана настройка параметров правил .
Создание правила горизонтального масштабирования на основе метрик развертывания
Обычное правило горизонтального масштабирования заключается в увеличении числа экземпляров виртуальных машин, когда средняя загрузка ЦП высока. В следующем примере показано, как выделить два дополнительных узла (до максимального), если средняя загрузка ЦП превышает 70 % в течение 5 минут:
ОБЛАСТЬ ПРИМЕНЕНИЯ: расширение машинного обучения Azure CLI версии 2 (текущее)
az monitor autoscale rule create \
--autoscale-name $AUTOSCALE_SETTINGS_NAME \
--condition "CpuUtilizationPercentage > 70 avg 5m" \
--scale out 2
Правило является частью my-scale-settings профиля, где autoscale-name соответствует name части профиля. Значение аргумента правила condition указывает, что правило активируется, когда среднее потребление ЦП среди экземпляров виртуальной машины превышает 70 % в течение 5 минут. При выполнении условия выделяется еще два экземпляра виртуальной машины.
ОБЛАСТЬ ПРИМЕНЕНИЯ: Пакет SDK для Python azure-ai-ml версии 2 (current)
Создайте определение правила:
rule_scale_out = ScaleRule(
metric_trigger = MetricTrigger(
metric_name="CpuUtilizationPercentage",
metric_resource_uri = deployment.id,
time_grain = datetime.timedelta(minutes = 1),
statistic = "Average",
operator = "GreaterThan",
time_aggregation = "Last",
time_window = datetime.timedelta(minutes = 5),
threshold = 70
),
scale_action = ScaleAction(
direction = "Increase",
type = "ChangeCount",
value = 2,
cooldown = datetime.timedelta(hours = 1)
)
)
Это правило относится к последнему 5-минутном среднему CPUUtilizationpercentage значению из аргументов metric_nameи time_windowtime_aggregation. Если значение метрики больше threshold 70, развертывание выделяет два дополнительных экземпляра виртуальной машины.
Обновите профиль my-scale-settings, чтобы включить это правило:
mon_client.autoscale_settings.create_or_update(
resource_group,
autoscale_settings_name,
parameters = {
"location" : endpoint.location,
"target_resource_uri" : deployment.id,
"profiles" : [
AutoscaleProfile(
name="my-scale-settings",
capacity={
"minimum" : 2,
"maximum" : 5,
"default" : 2
},
rules = [
rule_scale_out
]
)
]
}
)
Следующие действия продолжаются с конфигурацией автомасштабирования.
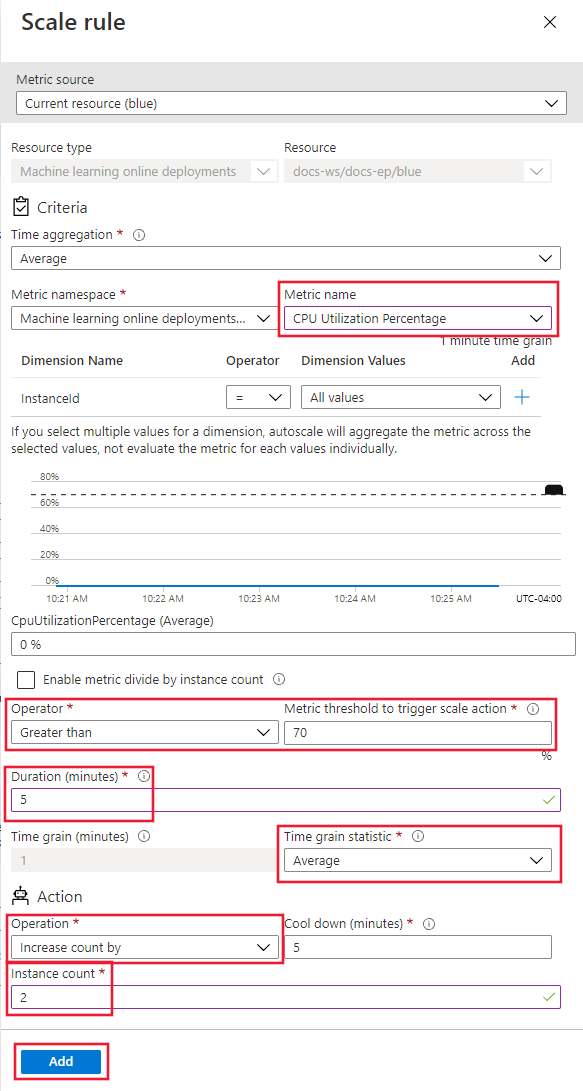
Для параметра "Правила" выберите ссылку "Добавить правило". Откроется страница правила масштабирования.
На странице правила масштабирования настройте следующие значения:
-
Имя метрик: выберите процент использования ЦП.
-
Оператор: задано значение "Больше".
-
Пороговое значение метрики: задайте значение 70.
-
Длительность (минуты): задайте значение 5.
-
Статистика по зерню времени: выберите среднее значение.
-
Операция: выберите "Увеличить число на".
-
Число экземпляров: задайте значение 2.
Нажмите кнопку "Добавить ", чтобы создать правило:
Оставьте область конфигурации открытой. В следующем разделе описана настройка параметров правил .
Создание правила масштабирования на основе метрик развертывания
Если средняя загрузка ЦП светлая, правило масштабирования может уменьшить количество экземпляров виртуальных машин. В следующем примере показано, как освободить один узел до минимума двух, если загрузка ЦП меньше 30 % в течение 5 минут.
ОБЛАСТЬ ПРИМЕНЕНИЯ: Пакет SDK для Python azure-ai-ml версии 2 (current)
Создайте определение правила:
rule_scale_in = ScaleRule(
metric_trigger = MetricTrigger(
metric_name="CpuUtilizationPercentage",
metric_resource_uri = deployment.id,
time_grain = datetime.timedelta(minutes = 1),
statistic = "Average",
operator = "LessThan",
time_aggregation = "Last",
time_window = datetime.timedelta(minutes = 5),
threshold = 30
),
scale_action = ScaleAction(
direction = "Increase",
type = "ChangeCount",
value = 1,
cooldown = datetime.timedelta(hours = 1)
)
)
Обновите профиль my-scale-settings, чтобы включить это правило:
mon_client.autoscale_settings.create_or_update(
resource_group,
autoscale_settings_name,
parameters = {
"location" : endpoint.location,
"target_resource_uri" : deployment.id,
"profiles" : [
AutoscaleProfile(
name="my-scale-settings",
capacity={
"minimum" : 2,
"maximum" : 5,
"default" : 2
},
rules = [
rule_scale_out,
rule_scale_in
]
)
]
}
)
Ниже описана настройка конфигурации правил для поддержки масштабирования правила.
Для параметра "Правила" выберите ссылку "Добавить правило". Откроется страница правила масштабирования.
На странице правила масштабирования настройте следующие значения:
-
Имя метрик: выберите процент использования ЦП.
-
Оператор: задано значение "Меньше".
-
Пороговое значение метрики: задайте значение 30.
-
Длительность (минуты): задайте значение 5.
-
Статистика по зерню времени: выберите среднее значение.
-
Операция: выберите "Уменьшить число" на.
-
Число экземпляров: задайте значение 1.
Нажмите кнопку "Добавить ", чтобы создать правило:
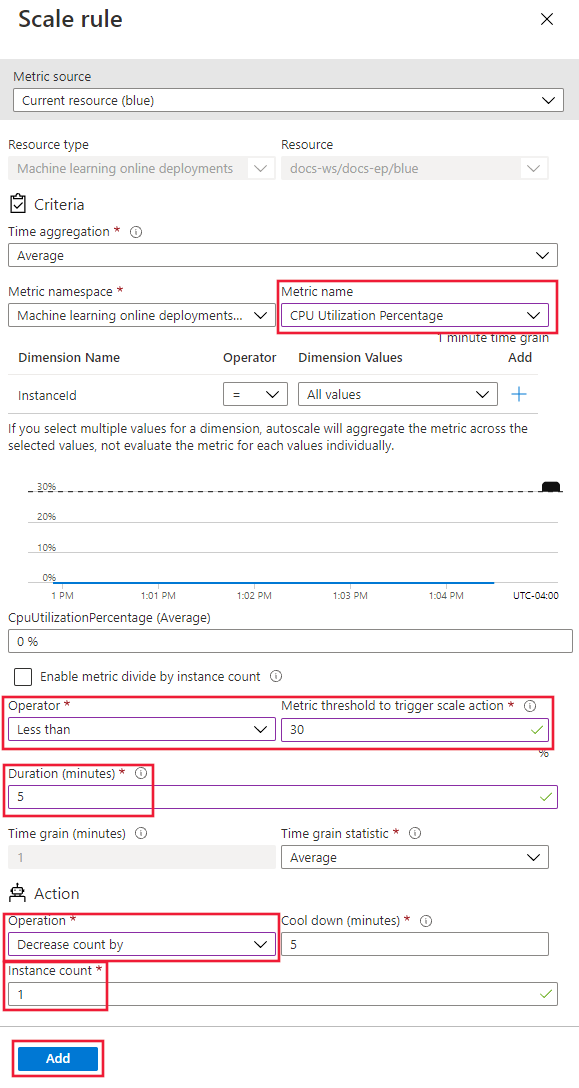
Если вы настраиваете правила горизонтального масштабирования и масштабирования, правила выглядят примерно так, как на следующем снимке экрана. Правила указывают, что если средняя загрузка ЦП превышает 70% в течение 5 минут, необходимо выделить еще два узла до пяти. Если загрузка ЦП составляет менее 30 % в течение 5 минут, один узел должен быть освобожден до минимума двух.
Оставьте область конфигурации открытой. В следующем разделе описаны другие параметры масштабирования.
Создание правила масштабирования на основе метрик конечных точек
В предыдущих разделах вы создали правила для масштабирования в зависимости от метрик развертывания. Вы также можете создать правило, которое применяется к конечной точке развертывания. В этом разделе вы узнаете, как выделить другой узел, если задержка запроса больше 70 миллисекунда в течение 5 минут.
ОБЛАСТЬ ПРИМЕНЕНИЯ: Пакет SDK для Python azure-ai-ml версии 2 (current)
Создайте определение правила:
rule_scale_out_endpoint = ScaleRule(
metric_trigger = MetricTrigger(
metric_name="RequestLatency",
metric_resource_uri = endpoint.id,
time_grain = datetime.timedelta(minutes = 1),
statistic = "Average",
operator = "GreaterThan",
time_aggregation = "Last",
time_window = datetime.timedelta(minutes = 5),
threshold = 70
),
scale_action = ScaleAction(
direction = "Increase",
type = "ChangeCount",
value = 1,
cooldown = datetime.timedelta(hours = 1)
)
)
Поле этого правила metric_resource_uri теперь ссылается на конечную точку, а не на развертывание.
Обновите профиль my-scale-settings, чтобы включить это правило:
mon_client.autoscale_settings.create_or_update(
resource_group,
autoscale_settings_name,
parameters = {
"location" : endpoint.location,
"target_resource_uri" : deployment.id,
"profiles" : [
AutoscaleProfile(
name="my-scale-settings",
capacity={
"minimum" : 2,
"maximum" : 5,
"default" : 2
},
rules = [
rule_scale_out,
rule_scale_in,
rule_scale_out_endpoint
]
)
]
}
)
Следующие шаги продолжают настройку правила на странице настраиваемого автомасштабирования .
В нижней части страницы выберите ссылку "Добавить условие масштабирования".
На странице условий масштабирования выберите "Масштаб" на основе метрик и щелкните ссылку "Добавить правило". Откроется страница правила масштабирования.
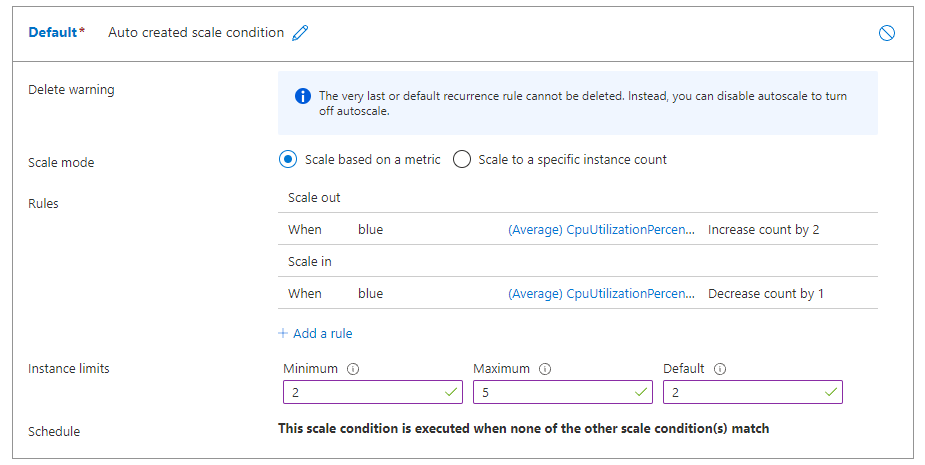
На странице правила масштабирования настройте следующие значения:
-
Источник метрик: выбор другого ресурса.
-
Тип ресурса: выберите Машинное обучение сетевые конечные точки.
-
Ресурс. Выберите конечную точку.
-
Имя метрики: выбор задержки запроса.
-
Оператор: задано значение "Больше".
-
Пороговое значение метрики: задайте значение 70.
-
Длительность (минуты): задайте значение 5.
-
Статистика по зерню времени: выберите среднее значение.
-
Операция: выберите "Увеличить число на".
-
Число экземпляров: задайте значение 1.
Нажмите кнопку "Добавить ", чтобы создать правило:
Поиск идентификаторов для поддерживаемых метрик
При использовании Azure CLI или пакета SDK для настройки правил автомасштабирования можно использовать другие метрики.
Создание правила масштабирования на основе расписания
Кроме прочего можно создавать правила, действующие только в определенные дни или моменты времени. В этом разделе описано, как создать правило, которое задает количество узлов в 2 в выходные дни.
ОБЛАСТЬ ПРИМЕНЕНИЯ: Пакет SDK для Python azure-ai-ml версии 2 (current)
mon_client.autoscale_settings.create_or_update(
resource_group,
autoscale_settings_name,
parameters = {
"location" : endpoint.location,
"target_resource_uri" : deployment.id,
"profiles" : [
AutoscaleProfile(
name="Default",
capacity={
"minimum" : 2,
"maximum" : 2,
"default" : 2
},
recurrence = Recurrence(
frequency = "Week",
schedule = RecurrentSchedule(
time_zone = "Pacific Standard Time",
days = ["Saturday", "Sunday"],
hours = [],
minutes = []
)
)
)
]
}
)
Следующие действия настраивают правило с параметрами на странице настраиваемого автомасштабирования в студии.
В нижней части страницы выберите ссылку "Добавить условие масштабирования".
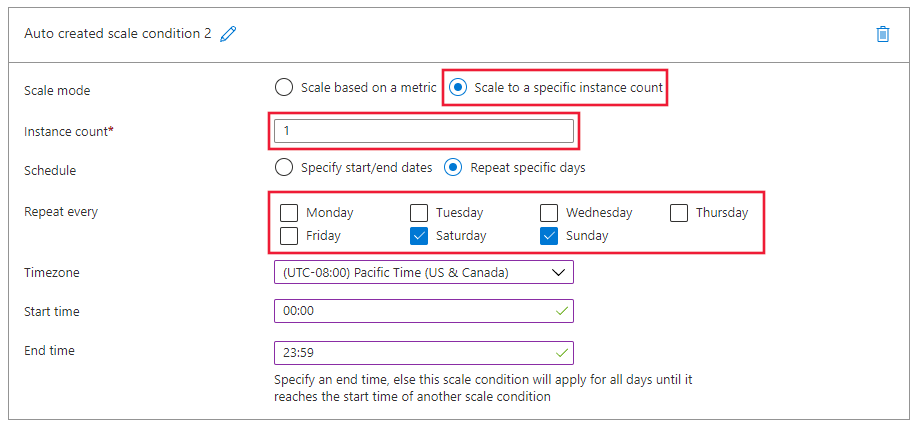
На странице условия масштабирования выберите "Масштабировать до определенного числа экземпляров", а затем щелкните ссылку "Добавить правило". Откроется страница правила масштабирования.
На странице правила масштабирования настройте следующие значения:
-
Число экземпляров: задайте значение 2.
-
Расписание. Выберите "Повторить определенные дни".
- Задайте шаблон расписания: выберите "Повторить" каждую и субботу и воскресенье.
Нажмите кнопку "Добавить ", чтобы создать правило:
Включение или отключение автомасштабирования
Вы можете включить или отключить определенный профиль автомасштабирования.
ОБЛАСТЬ ПРИМЕНЕНИЯ: Пакет SDK для Python azure-ai-ml версии 2 (current)
mon_client.autoscale_settings.create_or_update(
resource_group,
autoscale_settings_name,
parameters = {
"location" : endpoint.location,
"target_resource_uri" : deployment.id,
"enabled" : False
}
)
Чтобы отключить используемый профиль автомасштабирования, выберите "Вручную масштабировать" и нажмите кнопку "Сохранить".
Чтобы включить профиль автомасштабирования, выберите "Настраиваемый автомасштабирование". В студии перечислены все распознанные профили автомасштабирования для рабочей области. Выберите профиль и нажмите кнопку "Сохранить ", чтобы включить.
Удаление ресурсов
Если вы не собираетесь использовать развертывания, удалите ресурсы, выполнив следующие действия.
В Студия машинного обучения Azure перейдите в рабочую область и выберите конечные точки в меню слева.
В списке конечных точек выберите конечную точку для удаления (проверьте круг рядом с именем модели).
Выберите команду Удалить.
Кроме того, управляемую сетевую конечную точку можно удалить непосредственно на странице сведений о ней.
Связанный контент







