Создание скриптов оценки для пакетных развертываний
ОБЛАСТЬ ПРИМЕНЕНИЯ: Расширение машинного обучения Azure CLI версии 2 (current)Python SDK azure-ai-ml версии 2 (current)
Расширение машинного обучения Azure CLI версии 2 (current)Python SDK azure-ai-ml версии 2 (current)
Конечные точки пакетной службы позволяют развертывать модели, выполняющие долгосрочное вывод в масштабе. При развертывании моделей необходимо создать и указать скрипт оценки (также известный как скрипт пакетного драйвера), чтобы указать, как использовать его над входными данными для создания прогнозов. В этой статье вы узнаете, как использовать сценарии оценки в развертываниях моделей для различных сценариев. Вы также узнаете о рекомендациях по пакетной конечной точке.
Совет
Модели MLflow не требуют скрипта оценки. Он автоматически создается для вас. Дополнительные сведения о работе конечных точек пакетной службы с моделями MLflow см . в руководстве по использованию моделей MLflow в выделенном руководстве по пакетным развертываниям .
Предупреждение
Чтобы развернуть модель автоматизированного машинного обучения в конечной точке пакетной службы, обратите внимание, что автоматизированное машинное обучение предоставляет скрипт оценки, который работает только для сетевых конечных точек. Этот скрипт оценки не предназначен для пакетного выполнения. Следуйте этим рекомендациям для получения дополнительных сведений о том, как создать скрипт оценки, настроенный для вашей модели.
Основные сведения об скрипте оценки
Скрипт оценки — это файл Python (.py), который указывает, как запустить модель, и считывать входные данные, которые отправляет исполнитель пакетного развертывания. Каждое развертывание модели предоставляет скрипт оценки (а также все остальные необходимые зависимости) во время создания. Скрипт оценки обычно выглядит следующим образом:
deployment.yml
code_configuration:
code: code
scoring_script: batch_driver.py
Скрипт оценки должен содержать два метода:
Метод init
init() Используйте метод для любой дорогостоящей или распространенной подготовки. Например, используйте его для загрузки модели в память. Начало всего пакетного задания вызывает эту функцию один раз. Файлы модели доступны в пути, определяемом переменной AZUREML_MODEL_DIRсреды. В зависимости от того, как была зарегистрирована модель, его файлы могут содержаться в папке. В следующем примере модель содержит несколько файлов в папке с именем model. Дополнительные сведения см . в статье о том, как определить папку, которую использует модель.
def init():
global model
# AZUREML_MODEL_DIR is an environment variable created during deployment
# The path "model" is the name of the registered model's folder
model_path = os.path.join(os.environ["AZUREML_MODEL_DIR"], "model")
# load the model
model = load_model(model_path)
В этом примере модель помещаем в глобальную переменную model. Чтобы сделать доступными ресурсы, необходимые для вывода функции оценки, используйте глобальные переменные.
Метод run
run(mini_batch: List[str]) -> Union[List[Any], pandas.DataFrame] Используйте метод для обработки оценки каждого мини-пакета, который создает пакетное развертывание. Этот метод вызывается один раз для каждого mini_batch созданного для входных данных. Пакетные развертывания считывают данные в пакетах в соответствии с конфигурацией развертывания.
import pandas as pd
from typing import List, Any, Union
def run(mini_batch: List[str]) -> Union[List[Any], pd.DataFrame]:
results = []
for file in mini_batch:
(...)
return pd.DataFrame(results)
Метод получает список путей к файлам в качестве параметра (mini_batch). Этот список можно использовать для итерации и отдельной обработки каждого файла или для чтения всего пакета и обработки его одновременно. Оптимальный вариант зависит от вычислительной памяти и требуемой пропускной способности. Пример, описывающий, как одновременно считывать целые пакеты данных, посетите развертывания высокой пропускной способности.
Примечание.
Как работает распределена?
Пакетные развертывания распределяют работу на уровне файлов, что означает, что папка, содержащая 100 файлов, с мини-пакетами из 10 файлов, создает 10 пакетов из 10 файлов. Обратите внимание, что размеры соответствующих файлов не имеют релевантности. Для слишком больших файлов для обработки в больших мини-пакетах рекомендуется разделить файлы на небольшие файлы, чтобы обеспечить более высокий уровень параллелизма или уменьшить количество файлов на мини-пакет. В настоящее время пакетное развертывание не может учитывать отклонения в распределении размера файла.
Метод run() должен возвращать Pandas DataFrame или массив или список. Каждый возвращаемый выходной элемент обозначает один успешный запуск входного элемента во входном mini_batch. Для ресурсов данных файлов или папок каждая возвращаемая строка или элемент представляет один обработанный файл. Для ресурса табличных данных каждая возвращаемая строка или элемент представляет строку в обработанном файле.
Внимание
Как писать прогнозы?
Все, что run() возвращает функция, будет добавлено в файл выходных прогнозов, создаваемый пакетным заданием. Важно вернуть правильный тип данных из этой функции. Возвращает массивы , когда необходимо вывести один прогноз. Верните кадры данных pandas , когда необходимо вернуть несколько фрагментов информации. Например, для табличных данных может потребоваться добавить прогнозы к исходной записи. Для этого используйте кадр данных pandas. Хотя кадр данных Pandas может содержать имена столбцов, выходной файл не включает эти имена.
для записи прогнозов по-другому можно настроить выходные данные в пакетных развертываниях.
Предупреждение
run В функции не выводите сложные типы данных (или списки сложных типов данных) вместо pandas.DataFrame. Эти выходные данные будут преобразованы в строки, и они будут трудно читать.
Результирующий кадр данных или массив добавляется в указанный выходной файл. Нет никаких требований к карта inality результатов. Один файл может создать 1 или много строк или элементов в выходных данных. Все элементы в результирующем кадре данных или массиве записываются в выходной файл как есть (учитывая output_action , что это не summary_onlyтак).
Пакеты Python для оценки
Необходимо указать любую библиотеку, которую требуется запустить скрипт оценки в среде, в которой выполняется пакетное развертывание. Для сценариев оценки среды указываются на каждое развертывание. Как правило, вы указываете требования с помощью conda.yml файла зависимостей, который может выглядеть следующим образом:
mnist/environment/conda.yaml
name: mnist-env
channels:
- conda-forge
dependencies:
- python=3.8.5
- pip<22.0
- pip:
- torch==1.13.0
- torchvision==0.14.0
- pytorch-lightning
- pandas
- azureml-core
- azureml-dataset-runtime[fuse]
Дополнительные сведения о том, как указать среду для модели, см. в статье "Создание пакетного развертывания ".
Написание прогнозов по-другому
По умолчанию пакетное развертывание записывает прогнозы модели в один файл, как указано в развертывании. Однако в некоторых случаях необходимо записать прогнозы в нескольких файлах. Например, для секционированных входных данных, скорее всего, потребуется создать секционированные выходные данные. В таких случаях можно настроить выходные данные в пакетных развертываниях , чтобы указать:
- Формат файла (CSV, parquet, json и т. д.), используемый для записи прогнозов
- Способ секционирования данных в выходных данных
Дополнительные сведения о том, как его достичь, см . в разделе "Настройка выходных данных в пакетных развертываниях ".
Управление версиями скриптов оценки
Настоятельно рекомендуется разместить скрипты оценки в системе управления версиями.
Рекомендации по написанию скриптов оценки
При написании скриптов оценки, обрабатывающих большие объемы данных, необходимо учитывать несколько факторов, включая
- Размер каждого файла
- Объем данных в каждом файле
- Объем памяти, необходимый для чтения каждого файла
- Объем памяти, необходимый для чтения всего пакета файлов
- Объем памяти модели
- Объем памяти модели при выполнении входных данных
- Доступная память в вычислительных ресурсах
Пакетные развертывания распределяют работу на уровне файла. Это означает, что папка, содержащая 100 файлов, в мини-пакетах из 10 файлов, создает 10 пакетов из 10 файлов каждый (независимо от размера участвующих файлов). Для слишком больших файлов для обработки в больших мини-пакетах рекомендуется разделить файлы на небольшие файлы, достичь более высокого уровня параллелизма или уменьшить количество файлов на мини-пакет. В настоящее время пакетное развертывание не может учитывать отклонения в распределении размера файла.
Связь между степенью параллелизма и скриптом оценки
Конфигурация развертывания определяет размер каждого мини-пакета и количество рабочих ролей на каждом узле. Это важно при выборе того, следует ли считывать весь мини-пакет для выполнения вывода, запускать файл вывода по файлу или запускать строку вывода по строке (для табличных). Дополнительные сведения см . в разделе "Выполнение вывода" на мини-пакете, файле или на уровне строки.
При запуске нескольких рабочих ролей в одном экземпляре следует учитывать тот факт, что память совместно используется для всех рабочих ролей. Увеличение числа рабочих ролей на узле обычно должно сопровождать снижение размера мини-пакета или изменение стратегии оценки, если размер данных и номер SKU вычислений остается неизменным.
Выполнение вывода на мини-пакете, файле или на уровне строки
Конечные точки пакетной службы вызывают run() функцию в скрипте оценки один раз на мини-пакет. Однако вы можете решить, нужно ли выполнять вывод по всему пакету, по одному файлу или по одной строке одновременно для табличных данных.
Мини-пакетный уровень
Обычно вы хотите выполнить вывод по пакету одновременно, чтобы обеспечить высокую пропускную способность в процессе оценки пакетной службы. Это происходит, если вы выполняете вывод по GPU, где требуется достичь насыщенности устройства вывода. Вы также можете полагаться на загрузчик данных, который может обрабатывать пакетную обработку, если данные не помещаются в память, например TensorFlow или PyTorch загрузчики данных. В таких случаях может потребоваться выполнить вывод по всему пакету.
Предупреждение
При выполнении вывода на уровне пакетной службы может потребоваться тесный контроль над размером входных данных, правильно учитывать требования к памяти и избегать исключений из памяти. Независимо от того, можно ли загрузить весь мини-пакет в памяти, зависит от размера мини-пакета, размера экземпляров в кластере, количества рабочих ролей на каждом узле и размера мини-пакета.
Ознакомьтесь с развертываниями с высокой пропускной способностью, чтобы узнать, как это сделать. В этом примере выполняется обработка всего пакета файлов за раз.
Уровень файла
Одним из самых простых способов вывода является итерация по всем файлам в мини-пакете, а затем запустить модель над ней. В некоторых случаях, например обработка изображений, это может быть хорошей идеей. Для табличных данных может потребоваться сделать хорошую оценку количества строк в каждом файле. Эта оценка может показать, может ли ваша модель обрабатывать требования к памяти, чтобы загружать все данные в память и выполнять вывод над ним. Некоторые модели (особенно эти модели на основе периодических нейронных сетей) разворачиваются и представляют объем памяти с потенциально нелинейным числом строк. Для модели с высоким объемом памяти рекомендуется выполнить вывод на уровне строки.
Совет
Рассмотрите возможность разбиения слишком больших файлов для одновременного чтения в несколько небольших файлов, чтобы обеспечить более эффективную параллелизацию.
Посетите обработку изображений с помощью пакетных развертываний , чтобы узнать, как это сделать. В этом примере файл обрабатывается одновременно.
Уровень строки (табличный)
Для моделей, которые представляют проблемы с их размерами входных данных, может потребоваться выполнить вывод на уровне строки. Пакетное развертывание по-прежнему предоставляет скрипт оценки с мини-пакетом файлов. Тем не менее, вы будете читать один файл, по одной строке одновременно. Это может показаться неэффективным, но для некоторых моделей глубокого обучения это может быть единственным способом вывода без увеличения масштаба аппаратных ресурсов.
Чтобы узнать, как это сделать, посетите обработку текста с помощью пакетных развертываний . В этом примере выполняется обработка строки за раз.
Использование моделей, которые являются папками
Переменная AZUREML_MODEL_DIR среды содержит путь к выбранному расположению модели, а init() функция обычно использует ее для загрузки модели в память. Однако некоторые модели могут содержать их файлы в папке, и может потребоваться учесть это при загрузке. Вы можете определить структуру папок модели, как показано здесь:
Перейдите на портал Машинное обучение Azure.
Перейдите к разделу "Модели".
Выберите модель, которую вы хотите развернуть, и перейдите на вкладку "Артефакты ".
Обратите внимание на отображаемую папку. Эта папка была указана при регистрации модели.
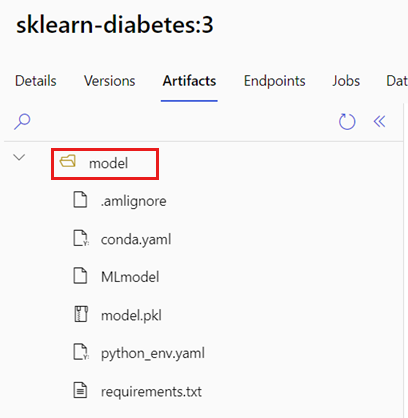

Используйте этот путь для загрузки модели:
def init():
global model
# AZUREML_MODEL_DIR is an environment variable created during deployment
# The path "model" is the name of the registered model's folder
model_path = os.path.join(os.environ["AZUREML_MODEL_DIR"], "model")
model = load_model(model_path)