Настройка среды разработки с Azure Databricks и AutoML в Машинном обучении Azure
Узнайте, как настроить среду разработки в Машинном обучении Azure, которая использует Azure Databricks и автоматизированное ML.
Решение Azure Databricks идеально подходит для выполнения крупномасштабных ресурсоемких рабочих процессов машинного обучения на масштабируемой платформе Apache Spark в облаке Azure. Azure Databricks предоставляет среду для совместной работы на основе записных книжек с вычислительным кластером на основе ЦП или GPU.
Сведения о других средах разработки машинного обучения см. в разделе Настройка среды разработки Python для Машинного обучения Azure.
Предварительное требование
Рабочая область Машинного обучения Azure. Чтобы создать ее, выполните действия, описанные в статье Создание ресурсов рабочей области.
Azure Databricks с Машинным обучением Azure и AutoML
Azure Databricks интегрируется с Машинным обучением Azure и его компонентом AutoML.
Azure Databricks можно использовать:
- для обучения модели с помощью Spark MLlib и ее развертывания ее в ACI или AKS;
- С возможностями автоматизированного машинного обучения с помощью пакета SDK для Машинного обучения Azure.
- в качестве цели вычислений для конвейера Машинного обучения Azure.
Настройка кластера Databricks
Создайте кластер Databricks. Некоторые параметры применяются только в том случае, если вы устанавливаете пакет SDK для автоматизированного машинного обучения в Databricks.
Создание кластера занимает несколько минут.
Используйте следующие параметры.
| Параметр | Область применения | Значение |
|---|---|---|
| Имя кластера, | always | yourclustername |
| Версия среды выполнения Databricks | always | 9.1 LTS |
| Версия Python | always | 3 |
| Тип рабочей роли (определяет максимальное число одновременных итераций) |
Автоматическое Машинное обучение только |
Предпочитается виртуальная машина, оптимизированная для операций в памяти |
| Рабочие роли | always | 2 или больше |
| Включение автомасштабирования | Автоматическое Машинное обучение только |
Снять пометку |
Дождитесь запуска кластера, прежде чем продолжать.
Добавление пакета SDK машинного обучения Azure в Databricks
После запуска кластера создайте библиотеку, чтобы подключить к кластеру соответствующий пакет SDK для Машинного обучения Azure.
Чтобы использовать автоматизированное машинное обучение, перейдите к разделу Добавление пакета SDK для Машинного обучения Azure с помощью AutoML.
Щелкните правой кнопкой мыши текущую папку рабочей области, в которой нужно сохранить библиотеку. Выберите Создать>Библиотеку.
Совет
Если у вас есть более старая версия пакета SDK, отмените его выбор среди установленных библиотек кластера и переместите в корзину. Установите новую версию пакета SDK и перезапустите кластер. Если после этого возникнет проблема, отключите и заново подключите кластер.
Выберите приведенный ниже параметр (установка других пакетов SDK не поддерживается).
Дополнительные возможности пакета SDK Источник Имя PyPi Для Databricks Отправка Python Egg или PyPI azureml-sdk[databricks] Предупреждение
Другие дополнительные компоненты пакета SDK установить невозможно. Выберите только параметр [
databricks].- Не выбирайте параметр Attach automatically to all clusters (Подключить автоматически ко всем кластерам).
- Выберите Присоединить рядом с именем кластера.
Отслеживайте ошибки, пока состояние не изменится на Присоединено, что может занять несколько минут. Если на этом шаге произошел сбой, сделайте следующее.
Попробуйте перезапустить кластер следующим образом.
- В левой области щелкните Кластеры.
- Выберите имя кластера в таблице.
- На вкладке Библиотеки щелкните Перезапустить.
Успешная установка выглядит следующим образом.
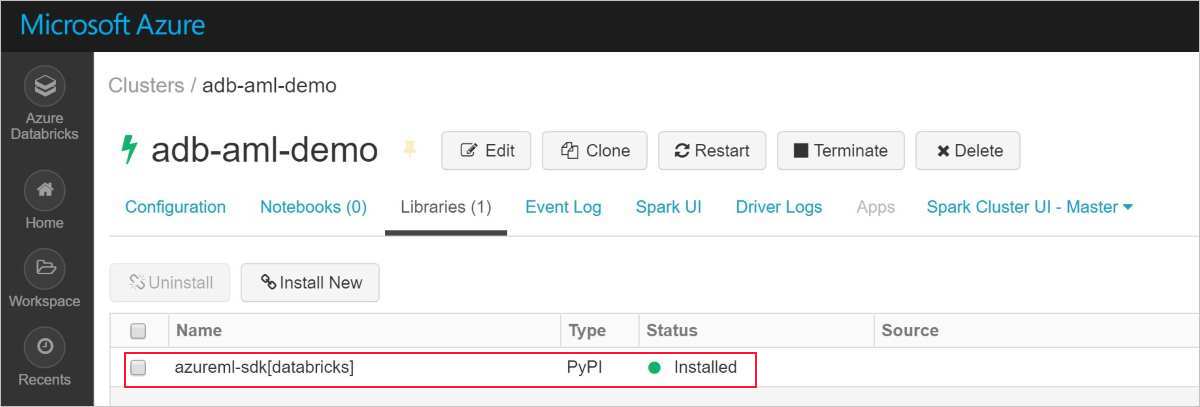
Добавление пакета SDK машинного обучения Azure с AutoML в Databricks
Если кластер был создан с помощью Databricks Runtime 7.3 LTS (не ML), выполните следующую команду в первой ячейке записной книжки, чтобы установить пакет SDK машинного обучения Azure.
%pip install --upgrade --force-reinstall -r https://aka.ms/automl_linux_requirements.txt
Параметры конфигурации AutoML
Добавьте приведенные ниже параметры в конфигурацию AutoML, если используете Azure Databricks:
- значение
max_concurrent_iterationsсоответствует количеству рабочих узлов в кластере; - значение
spark_context=scсоответствует контексту Spark по умолчанию.
Записные книжки ML, работающие с Azure Databricks
Попробуйте продукт:
Хотя доступны многие примеры записных книжек, с Azure Databricks работают только эти примеры записных книжек.
Импортируйте эти примеры напрямую из рабочей области. См. ниже:
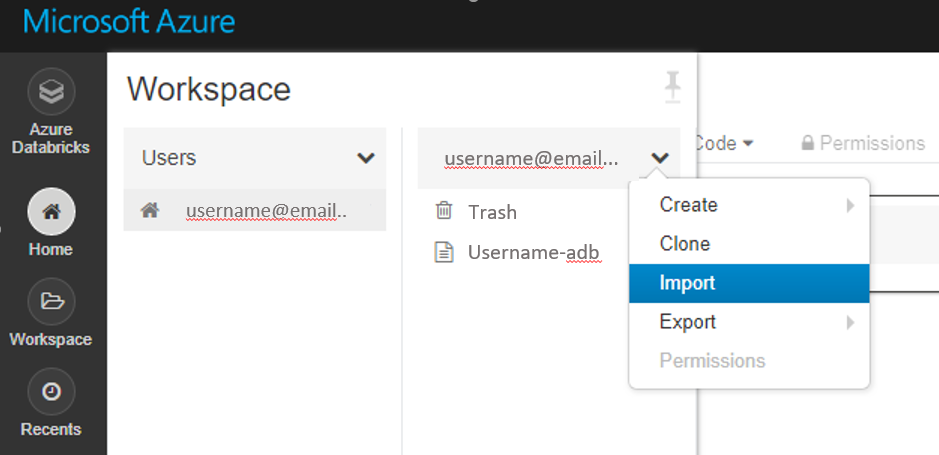
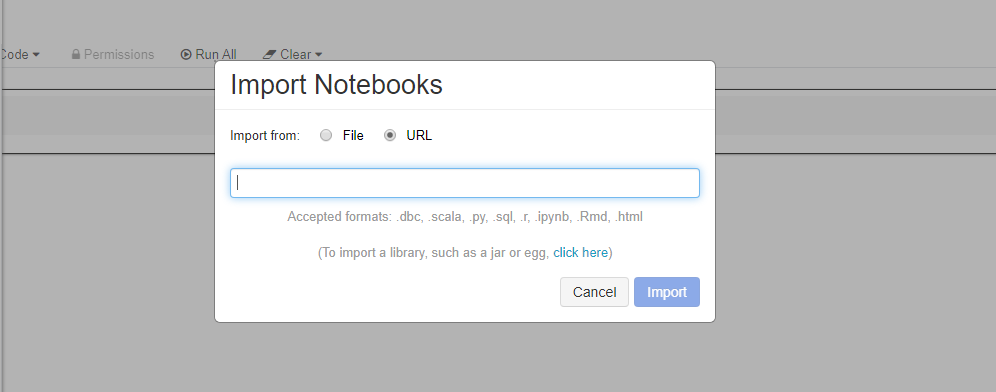
Узнайте, как создать конвейер с Databricks в качестве обучающей вычислительной среды.
Устранение неполадок
Databricks отменяет выполнение автоматизированного машинного обучения. Чтобы отменить выполнение эксперимента и запустить новый эксперимент при использовании возможностей автоматизированного машинного обучения в Azure Databricks, перезапустите кластер Azure Databricks.
Databricks> выполняет больше 10 итераций для автоматизированного машинного обучения: если выполняется больше 10 итераций, то в параметрах автоматизированного машинного обучения задайте для параметра
show_outputзначениеFalseпри отправке выполнения.Мини-приложение Databricks для пакета SDK для Машинного обучения Azure и автоматизированного машинного обучения. В записной книжке Databricks не поддерживается мини-приложение пакета SDK для Машинного обучения Azure, так как записные книжки не могут анализировать мини-приложения HTML. Вы можете просмотреть мини-приложение на портале с помощью приведенного ниже кода Python в записной книжке Azure Databricks.
displayHTML("<a href={} target='_blank'>Azure Portal: {}</a>".format(local_run.get_portal_url(), local_run.id))Сбой при установке пакетов
Сбой установки пакета SDK для Машинного обучения Azure в Databricks происходит, если устанавливаются дополнительные пакеты. Некоторые пакеты, такие как
psutil, могут приводить к конфликтам. Чтобы избежать ошибок установки, установите пакеты, заморозив версию библиотеки. Эта проблема связана с Databricks и не связана с пакетом SDK для Машинного обучения Azure. Вы можете столкнуться с ней и при использовании других библиотек. Пример.psutil cryptography==1.5 pyopenssl==16.0.0 ipython==2.2.0В качестве альтернативы можно использовать сценарии инициализации, если проблемы при установке библиотек Python не исчезли. Этот подход официально не поддерживается. Дополнительные сведения см. в разделе Скрипты инициализации в области кластера.
Ошибка импорта: не удается импортировать
Timedeltaимени изpandas._libs.tslibs. Если вы видите эту ошибку при использовании автоматизированного машинного обучения, выполните в записной книжке две следующие строки.%sh rm -rf /databricks/python/lib/python3.7/site-packages/pandas-0.23.4.dist-info /databricks/python/lib/python3.7/site-packages/pandas %sh /databricks/python/bin/pip install pandas==0.23.4Ошибка импорта: не найден модуль с именем "pandas.core.indexes". Если вы видите эту ошибку при использовании автоматизированного машинного обучения, выполните следующие действия.
Выполните следующую команду, чтобы установить два пакета в кластер Azure Databricks:
scikit-learn==0.19.1 pandas==0.22.0Отключите и снова подключите кластер к записной книжке.
Если эти действия не устранили проблему, попробуйте перезапустить кластер.
FailToSendFeather. Если при чтении данных в кластере Azure Databricks возникает ошибка
FailToSendFeather, воспользуйтесь следующими решениями:- Обновите пакет
azureml-sdk[automl]до последней версии. - Добавьте
azureml-dataprep1.1.8 или более поздней версии. - Добавьте
pyarrow0.11 или более поздней версии.
- Обновите пакет
Дальнейшие действия
- Обучите и разверните модель в Машинном обучении Azure с помощью набора данных MNIST.
- Ознакомьтесь со статьей Что собой представляет пакет SDK службы "Машинное обучение Azure"для Python?
Обратная связь
Ожидается в ближайшее время: в течение 2024 года мы постепенно откажемся от GitHub Issues как механизма обратной связи для контента и заменим его новой системой обратной связи. Дополнительные сведения см. в разделе https://aka.ms/ContentUserFeedback.
Отправить и просмотреть отзыв по