Устранение неполадок с конвейерами машинного обучения
ОБЛАСТЬ ПРИМЕНЕНИЯ: Пакет SDK для Python версии 1
Пакет SDK для Python версии 1
Из этой статьи вы узнаете, как устранять неполадки, связанные с запуском конвейера машинного обучения в пакете SDK Машинного обучения Azure и конструкторе Машинного обучения Azure.
Советы по устранению неполадок
В следующей таблице приведены распространенные проблемы, возникающие во время разработки конвейера, а также возможные решения.
| Проблема | Возможное решение |
|---|---|
Не удалось передать данные в каталог PipelineData |
Убедитесь, что в скрипте создан каталог, который соответствует ожидаемому конвейером расположению вывода данных на шаге. В большинстве случаев входной аргумент определяет выходной каталог, а затем создаете каталог явным образом. Используйте os.makedirs(args.output_dir, exist_ok=True) для создания выходного каталога. См. руководство по примеру сценария оценки, в котором описан этот конструктивный шаблон. |
| Ошибки зависимостей | Если в удаленном конвейере возникают ошибки зависимостей, которые не произошли при локальном тестировании, убедитесь, что зависимости удаленной среды и версии соответствуют их в тестовой среде. (См. статью Создание среды, кэширование и повторное использование.) |
| Неоднозначные ошибки с целевыми объектами вычислений | Попробуйте удалить и повторно создать целевые объекты вычислений. Повторное создание целевых объектов вычислений позволяет быстро устранить некоторые временные проблемы. |
| Конвейер не использует этапы повторно | Повторное использование этапов включено по умолчанию, но убедитесь, что вы не отключили его на этапе конвейера. Если повторное использование отключено, allow_reuse параметр на шаге имеет значение False. |
| Конвейер перезапускается без необходимости | Чтобы обеспечить повторное выполнение этапов только при изменении базовых данных или сценариев, следует разделить каталоги исходного кода для каждого этапа. Если один и тот же исходный каталог используется для нескольких этапов, может возникнуть ненужное повторное использование. Используйте параметр source_directory для объекта этапа конвейера, чтобы указать на изолированный каталог для этого этапа. Убедитесь, что вы не используете один и тот же путь source_directory для нескольких этапов. |
| Этап замедляется во время эпох обучения или возникает другое циклическое поведение | Попробуйте переключить операции записи файлов, в том числе ведение журнала, с as_mount() на as_upload(). В режиме mount используется удаленная виртуальная файловая система и загружается весь файл каждый раз, когда он добавляется. |
| Целевой объект вычислений долго запускается | Образы Docker для целевых объектов вычислений загружаются из Реестра контейнеров Azure (ACR). По умолчанию служба Машинного обучения Azure создает реестр ACR, который использует уровень обслуживания Basic. Изменение ACR для рабочей области на уровень "Стандарт" или "Премиум" может сократить время, затрачиваемое на сборку и загрузку образов. Дополнительные сведения см в статье Уровни службы Реестра контейнеров Azure. |
Ошибки проверки подлинности
При выполнении операции управления на целевом объекте вычислений из удаленного задания возникает одна из следующих ошибок:
{"code":"Unauthorized","statusCode":401,"message":"Unauthorized","details":[{"code":"InvalidOrExpiredToken","message":"The request token was either invalid or expired. Please try again with a valid token."}]}
{"error":{"code":"AuthenticationFailed","message":"Authentication failed."}}
Например, при попытке создать или подключить целевой объект вычислений из конвейера машинного обучения, отправленного для удаленного выполнения, возникает ошибка.
Устранение неполадок ParallelRunStep
Сценарий для ParallelRunStep должен содержать две функции:
init(): используйте эту функцию для любой дорогостоящих или распространенных подготовки к последующему выводу. Например, в ней можно загружать модель в глобальный объект. Эта функция вызывается только один раз в начале процесса.run(mini_batch): функция выполняется для каждогоmini_batchэкземпляра.mini_batch:ParallelRunStepвызывает метод выполнения и передает список или pandasDataFrameв качестве аргумента методу. Каждая запись в mini_batch — это путь к файлу, если входные данные являютсяFileDatasetвходными или пандами, если входные данные являются входными даннымиDataFrameTabularDataset.response: метод run() должен возвращать PandasDataFrameили массив. Для append_row output_action эти возвращаемые элементы добавляются в общий выходной файл. Для summary_only содержимое элементов игнорируется. Для всех выходных действий каждый возвращаемый элемент обозначает один успешный запуск входного элемента во входном мини-пакете. Убедитесь в том, что в результат выполнения включено достаточно данных, чтобы сопоставить входные данные с результатом вывода. Выходные данные запуска записываются в выходной файл и не гарантируется, что они должны быть упорядочены, используйте ключ в выходных данных, чтобы сопоставить его с входным.
%%writefile digit_identification.py
# Snippets from a sample script.
# Refer to the accompanying digit_identification.py
# (https://github.com/Azure/MachineLearningNotebooks/tree/master/how-to-use-azureml/machine-learning-pipelines/parallel-run)
# for the implementation script.
import os
import numpy as np
import tensorflow as tf
from PIL import Image
from azureml.core import Model
def init():
global g_tf_sess
# Pull down the model from the workspace
model_path = Model.get_model_path("mnist")
# Construct a graph to execute
tf.reset_default_graph()
saver = tf.train.import_meta_graph(os.path.join(model_path, 'mnist-tf.model.meta'))
g_tf_sess = tf.Session()
saver.restore(g_tf_sess, os.path.join(model_path, 'mnist-tf.model'))
def run(mini_batch):
print(f'run method start: {__file__}, run({mini_batch})')
resultList = []
in_tensor = g_tf_sess.graph.get_tensor_by_name("network/X:0")
output = g_tf_sess.graph.get_tensor_by_name("network/output/MatMul:0")
for image in mini_batch:
# Prepare each image
data = Image.open(image)
np_im = np.array(data).reshape((1, 784))
# Perform inference
inference_result = output.eval(feed_dict={in_tensor: np_im}, session=g_tf_sess)
# Find the best probability, and add it to the result list
best_result = np.argmax(inference_result)
resultList.append("{}: {}".format(os.path.basename(image), best_result))
return resultList
Если у вас есть другой файл или папка в том же каталоге, что и скрипт вывода, можно сослаться на него, найдя текущий рабочий каталог.
script_dir = os.path.realpath(os.path.join(__file__, '..',))
file_path = os.path.join(script_dir, "<file_name>")
Параметры для ParallelRunConfig
ParallelRunConfig — это основная конфигурация для экземпляра ParallelRunStep в конвейере Машинного обучения Azure. Он пригодится вам как оболочка скрипта для настройки необходимых параметров, включая перечисленные ниже записи:
entry_script: пользовательский скрипт в качестве локального пути к файлу, который выполняется параллельно на нескольких узлах. Если присутствуетsource_directory, используйте относительный путь. В противном случае используйте любой путь, доступный на компьютере.mini_batch_size: размер мини-пакета, переданного одномуrun()вызову. (необязательно; значение по умолчанию —10это файлы дляFileDatasetи1MBдляTabularDataset.)- Для
FileDatasetздесь указывается количество файлов; минимальное допустимое значение —1. Несколько файлов можно объединить в один мини-пакет. - Для
TabularDatasetздесь указывается размер данных. Примеры допустимых значений:1024,1024KB,10MBи1GB. Мы рекомендуем использовать значение1MB. Мини-пакет изTabularDatasetникогда не пересекает границы файлов. Предположим, что у вас есть CSV-файлы с разными размерами в пределах от 100 КБ до 10 МБ. Если заданоmini_batch_size = 1MB, файлы размером меньше 1 МБ обрабатываются как один мини-пакет. Файлы с размером размером более 1 МБ делятся на несколько мини-пакетов.
- Для
error_threshold: количество сбоев записей иTabularDatasetсбоев файлов дляFileDatasetэтого следует игнорировать во время обработки. Если количество ошибок для всего входного значения превышает это значение, задание прервано. Пороговое количество ошибок применяется к общему объему входных данных, а не к отдельному мини-пакету, которые передаются в методrun(). Используется диапазон[-1, int.max]. Часть-1указывает на то, что следует игнорировать все сбои во время обработки.output_action: одно из следующих значений указывает, как упорядочены выходные данные:summary_only: скрипт пользователя сохраняет выходные данные.ParallelRunStepиспользует выходные данные только для вычисления порогового значения ошибки.append_row: для всех входных данных создается только один файл в выходной папке, чтобы добавить все выходные данные, разделенные строкой.
append_row_file_name: чтобы настроить имя выходного файла для append_row output_action (необязательно; значениеparallel_run_step.txtпо умолчанию — ).source_directory: пути к папкам, содержащим все файлы для выполнения на целевом объекте вычислений (необязательно).compute_target: поддерживается толькоAmlCompute.node_count: количество вычислительных узлов, используемых для выполнения пользовательского скрипта.process_count_per_node: количество процессов на узел. Рекомендуется устанавливать в значение, равное количеству GPU или ЦП на одном узле (необязательно; значение по умолчанию —1).environment: определение среды Python. Вы можете настроить использование существующей среды Python или временной среды. Также это определение может задавать необходимые зависимости приложения (необязательно).logging_level: детализация журнала. Значения уровня детализации в порядке увеличения:WARNING,INFOиDEBUG. (необязательный параметр; по умолчанию используется значениеINFO.)run_invocation_timeoutrun(): время ожидания вызова метода в секундах. (необязательный параметр, значение по умолчанию —60)run_max_try: максимальное количествоrun()попыток для мини-пакета. Сбойrun()при возникновении исключения или если при достиженииrun_invocation_timeoutничего не возвращается (необязательно; значение по умолчанию —3).
Можно указать mini_batch_size, node_count, process_count_per_node, logging_level, run_invocation_timeout и run_max_try как PipelineParameter, чтобы при повторной отправке запуска конвейера можно было точно настроить значения параметров. В этом примере вы используете PipelineParameter mini_batch_size и Process_count_per_node изменяете эти значения при повторной отправке запуска позже.
Параметры для создания ParallelRunStep
Создайте ParallelRunStep, используя скрипт, конфигурацию среды и параметры. Укажите целевой объект вычислений, который уже подключен к рабочей области, в качестве целевого объекта для выполнения скрипта вывода. Используйте ParallelRunStep, чтобы создать шаг конвейера пакетного вывода, который принимает все следующие параметры.
name: Имя шага со следующими ограничениями на именование: уникальность, от 3 до 32 символов, соответствие регулярному выражению ^[a-z]([-a-z0-9]*[a-z0-9])?$.parallel_run_configParallelRunConfig: объект, как определено ранее.inputs: один или несколько однотипных Машинное обучение Azure наборов данных, которые следует секционировать для параллельной обработки.side_inputs: один или несколько ссылочных данных или наборов данных, используемых в качестве побочных входных данных без необходимости секционироваться.output: объектOutputFileDatasetConfig, который соответствует каталогу для выходных данных.arguments: список аргументов, переданных в скрипт пользователя. Используйте unknown_args, чтобы получить их в начальном сценарии (необязательно).allow_reuse: следует ли шаг повторно использовать предыдущие результаты при выполнении с теми же параметрами и входными данными. Если этот параметр имеет значениеFalse, для этого шага создается новый запуск во время выполнения конвейера. (необязательный параметр; по умолчанию используется значениеTrue.)
from azureml.pipeline.steps import ParallelRunStep
parallelrun_step = ParallelRunStep(
name="predict-digits-mnist",
parallel_run_config=parallel_run_config,
inputs=[input_mnist_ds_consumption],
output=output_dir,
allow_reuse=True
)
Методы отладки
Существует три основных метода отладки конвейеров:
- Отладка отдельных шагов конвейера на локальном компьютере
- Использование ведения журналов и Application Insights для изоляции и диагностики источника проблемы.
- Подключение удаленного отладчика к конвейеру, выполняющемуся в Azure.
Локальная отладка сценариев.
Одним из наиболее распространенных сбоев в конвейере является то, что скрипт домена не выполняется как предполагаемое или содержит ошибки среды выполнения в удаленном контексте вычислений, которые трудно выполнить отладку.
Сами конвейеры не могут выполняться локально. Но выполнение скриптов в изоляции на локальном компьютере позволяет выполнять отладку быстрее, так как вам не нужно ждать процесса сборки вычислений и среды. Для этого требуется выполнить некоторые действия по разработке.
- Если данные размещены в облачном хранилище данных, необходимо скачать данные и сделать его доступным для скрипта. Использование небольшой выборки данных — хороший способ сократить время выполнения и проанализировать работу сценария.
- Если вы пытаетесь имитировать промежуточный шаг конвейера, может потребоваться вручную создать типы объектов, которые ожидает конкретный скрипт с предыдущего шага.
- Необходимо определить собственную среду и реплицировать зависимости, определенные в удаленной вычислительной среде.
После установки скрипта для запуска в локальной среде проще выполнять такие задачи отладки, как:
- присоединение пользовательской конфигурации отладки;
- приостановка выполнения и проверка состояния объекта;
- перехват типов или логических ошибок, которые не будут предоставляться до времени выполнения.
Совет
Если вы убедились, что сценарий выполняется должным образом, на следующем этап стоит запустить сценарий в одноэтапном конвейере, прежде чем пытаться выполнить его в конвейере из нескольких этапов.
Настройка, запись и проверка журналов конвейера
Тестирование скриптов локально — отличный способ отладки основных фрагментов кода и сложной логики перед началом создания конвейера. В какой-то момент необходимо выполнить отладку скриптов во время собственного запуска конвейера, особенно при диагностике поведения, которое происходит во время взаимодействия между этапами конвейера. Мы рекомендуем свободно использовать инструкции print() в сценариях этапов, чтобы видеть состояние объекта и ожидаемые значения во время удаленного выполнения, как при отладке кода JavaScript.
Параметры и режим ведения журнала
В следующей таблице приведены сведения о различных параметрах отладки для конвейеров. Это не исчерпывающий список, так как другие параметры существуют, кроме Машинное обучение Azure и Python, показанных здесь.
| Библиотека | Тип | Пример | Назначение | Ресурсы |
|---|---|---|---|---|
| пакет SDK для Машинного обучения Azure; | Метрика | run.log(name, val) |
Пользовательский интерфейс обучающего портала Машинного обучения Azure | Отслеживание экспериментов Класс azureml.core.Run |
| Печать и ведение журнала Python | Журнал | print(val)logging.info(message) |
Журналы драйверов, конструктор Машинного обучения Azure | Отслеживание экспериментов Ведение журнала Python |
Пример параметров ведения журнала
import logging
from azureml.core.run import Run
run = Run.get_context()
# Azure Machine Learning Scalar value logging
run.log("scalar_value", 0.95)
# Python print statement
print("I am a python print statement, I will be sent to the driver logs.")
# Initialize Python logger
logger = logging.getLogger(__name__)
logger.setLevel(args.log_level)
# Plain Python logging statements
logger.debug("I am a plain debug statement, I will be sent to the driver logs.")
logger.info("I am a plain info statement, I will be sent to the driver logs.")
handler = AzureLogHandler(connection_string='<connection string>')
logger.addHandler(handler)
Конструктор Машинного обучения Azure
Для конвейеров, созданных в конструкторе файл 70_driver_log можно найти либо на странице создания, либо на странице сведения о выполнении конвейера.
Включение ведения журнала для конечных точек в режиме реального времени
Для устранения неполадок и отладки конечных точек в режиме реального времени в конструкторе необходимо включить ведение журнала Application Insights с помощью пакета SDK. Ведение журнала позволяет устранять неполадки и выполнять отладку развертывания и использования модели. Дополнительные сведения см. в разделе Ведение журнала для развернутых моделей.
Получение журналов на странице создания
Если отправить конвейер на выполнение и остаться на странице создания, вы сможете найти файлы журналов, созданные для каждого компонента после завершения выполнения.
Выберите компонент, который завершил выполнение на холсте разработки.
На правой панели компонента перейдите на вкладку Выходные данные + журналы.
Разверните правую панель и выберите 70_driver_log.txt, чтобы просмотреть файл в браузере. Кроме того, можно загрузить журналы локально.
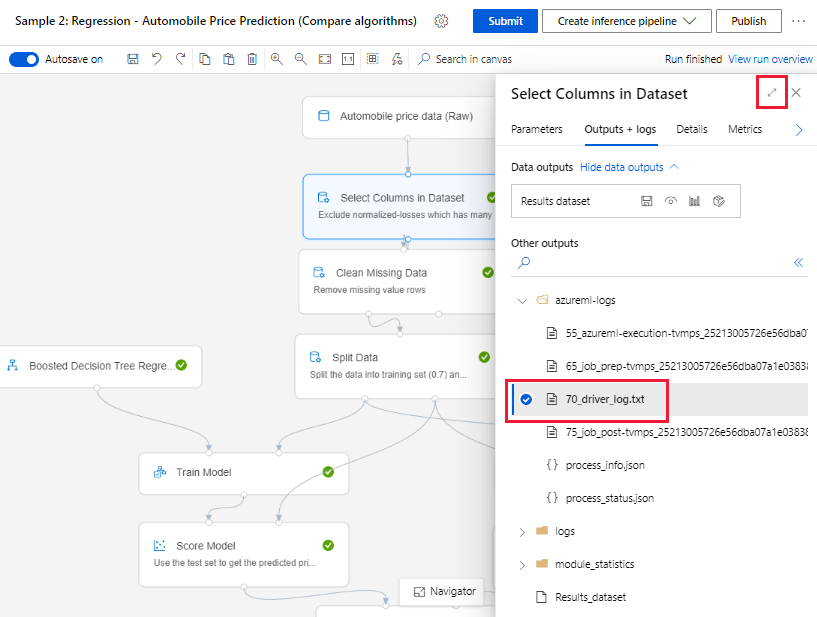
Получение журналов из запусков конвейера
Файлы журналов для конкретных запусков также можно найти на странице сведений о запуске конвейера в разделе Конвейеры или Эксперименты в студии.
Выберите запуск конвейера, созданный в конструкторе.
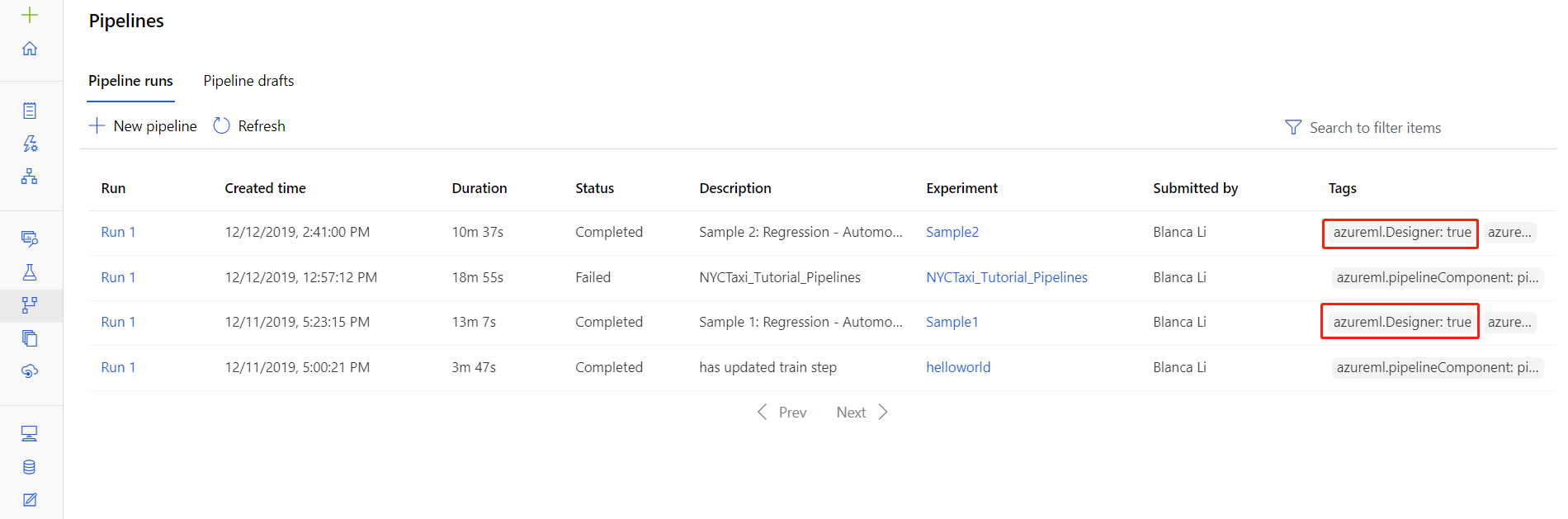
Выберите компонент в области предварительного просмотра.
На правой панели компонента перейдите на вкладку Выходные данные + журналы.
Разверните правую панель, чтобы просмотреть файл std_log.txt в браузере, или выберите файл, чтобы загрузить журналы локально.
Внимание
Чтобы обновить конвейер со страницы сведений о запуске конвейера, необходимо клонировать запуск конвейера в новый черновик конвейера. Запуск конвейера — это моментальный снимок конвейера. Он похож на файл журнала и не может быть изменен.
Интерактивная отладка с помощью Visual Studio Code
В некоторых случаях может потребоваться интерактивная отладка кода Python, используемого в конвейере машинного обучения. С помощью Visual Studio Code (VS Code) и debugpy можно присоединяться к коду, когда он выполняется в среде обучения. Дополнительные сведения см. в руководстве по интерактивной отладке в VS Code.
Сбой HyperdriveStep и AutoMLStep с сетевой изоляцией
После использования HyperdriveStep и AutoMLStep при попытке зарегистрировать модель может появиться ошибка.
Вы используете пакет SDK Машинное обучение Azure версии 1.
Рабочая область Машинное обучение Azure настроена для сетевой изоляции (виртуальная сеть).
Конвейер пытается зарегистрировать модель, созданную на предыдущем шаге. Например, в следующем примере
inputsпараметр является saved_model из HyperdriveStep:register_model_step = PythonScriptStep(script_name='register_model.py', name="register_model_step01", inputs=[saved_model], compute_target=cpu_cluster, arguments=["--saved-model", saved_model], allow_reuse=True, runconfig=rcfg)
Обходное решение
Внимание
Это поведение не происходит при использовании пакета SDK Машинное обучение Azure версии 2.
Чтобы обойти эту ошибку , используйте класс Run , чтобы получить модель, созданную на основе HyperdriveStep или AutoMLStep. Ниже приведен пример скрипта, который получает выходную модель из HyperdriveStep:
%%writefile $script_folder/model_download9.py
import argparse
from azureml.core import Run
from azureml.pipeline.core import PipelineRun
from azureml.core.experiment import Experiment
from azureml.train.hyperdrive import HyperDriveRun
from azureml.pipeline.steps import HyperDriveStepRun
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument(
'--hd_step_name',
type=str, dest='hd_step_name',
help='The name of the step that runs AutoML training within this pipeline')
args = parser.parse_args()
current_run = Run.get_context()
pipeline_run = PipelineRun(current_run.experiment, current_run.experiment.name)
hd_step_run = HyperDriveStepRun((pipeline_run.find_step_run(args.hd_step_name))[0])
hd_best_run = hd_step_run.get_best_run_by_primary_metric()
print(hd_best_run)
hd_best_run.download_file("outputs/model/saved_model.pb", "saved_model.pb")
print("Successfully downloaded model")
Затем файл можно использовать из PythonScriptStep:
from azureml.pipeline.steps import PythonScriptStep
conda_dep = CondaDependencies()
conda_dep.add_pip_package("azureml-sdk")
conda_dep.add_pip_package("azureml-pipeline")
rcfg = RunConfiguration(conda_dependencies=conda_dep)
model_download_step = PythonScriptStep(
name="Download Model 9",
script_name="model_download9.py",
arguments=["--hd_step_name", hd_step_name],
compute_target=compute_target,
source_directory=script_folder,
allow_reuse=False,
runconfig=rcfg
)
Следующие шаги
Полный учебник по использованию
ParallelRunStepсм. в статье Руководство по Создание конвейеров Машинного обучения Azure для пакетной оценки.Полный пример, в котором показано автоматизированное машинное обучение в конвейерах, см. в статье Использование автоматического Машинного обучения в конвейере Машинного обучения Azure в Python.
Изучите справочные материалы по SDK для пакетов azureml-pipelines-core и azureml-pipelines-steps.
См. список исключений и кодов ошибок конструктора.