Просмотр кода обучения для модели автоматизированного машинного обучения
В этой статье вы узнаете, как просмотреть созданный код обучения из любой модели автоматизированного машинного обучения.
Создание кода для моделей, обученных посредством автоматизированного ML, позволяет просматривать следующие сведения, которые использует автоматизированное ML для обучения и построения модели для конкретного запуска.
- Предварительная обработка данных
- Выбор алгоритма
- Конструирование признаков
- Гиперпараметры
Можно выбрать любую модель, обученную посредством автоматизированного ML, рекомендованный или дочерний запуск, и просмотреть созданный код обучения Python, который создал эту конкретную модель.
Используя обучающий код созданной модели, можно
- Узнать о процессе и гиперпараметрах конструирования признаков, используемых алгоритмом модели.
- Отслеживать/создавать версии/проводить аудит обученных моделей. Храните версии кода для отслеживания использования конкретного обучающего кода с моделью, которая должна быть развернута в рабочей среде.
- Настройте обучающий код, изменяя гиперпараметры или применяя навыки и опыт работы с ML и алгоритмами, а также переобучите новую модель с помощью настраиваемого кода.
На следующей схеме показано, что создать код для экспериментов автоматизированного машинного обучения со всеми типами задач. Сначала выберите модель. Выбранная модель будет выделена. Затем Машинное обучение Azure скопирует файлы кода, используемые для создания модели, и отобразит их в общей папке записных книжек. Здесь можно просмотреть и настроить код по мере необходимости.
Необходимые компоненты
Рабочая область Машинного обучения Azure. Сведения о создании рабочей области см. в разделе Создание ресурсов рабочей области.
В этой статье предполагается, что вам известны основные принципы настройки эксперимента автоматизированного машинного обучения. Следуйте инструкциям учебника или практического руководства, чтобы ознакомиться с основными конструктивными шаблонами экспериментов автоматизированного машинного обучения.
Автоматическое создание кода машинного обучения доступно только для экспериментов, выполняемых в удаленных целевых объектах вычислений Машинное обучение Azure. Создание кода не поддерживается для локальных запусков.
Все автоматизированные запуски машинного обучения, запущенные через Студия машинного обучения Azure, SDKv2 или CLIv2, будут включать создание кода.
Получение созданного кода и артефактов модели
По умолчанию каждая модель, обученная посредством автоматизированного ML, создает свой код обучения после завершения обучения. Автоматизированное ML сохраняет этот код в outputs/generated_code эксперимента для этой конкретной модели. Их можно просмотреть в пользовательском интерфейсе Студия машинного обучения Azure на вкладке "Выходные данные и журналы" выбранной модели.
script.py Это код обучения модели, который, скорее всего, потребуется проанализировать посредством шагов по конструированию признаков, используемого алгоритма и гиперпараметров.
script_run_notebook.ipynb Notebook с кодом плиты для запуска кода обучения модели (script.py) в Машинное обучение Azure вычислений через Машинное обучение Azure SDKv2.
После завершения автоматического обучения машинного обучения вы можете получить доступ к script.py файлам с script_run_notebook.ipynb помощью пользовательского интерфейса Студия машинного обучения Azure.
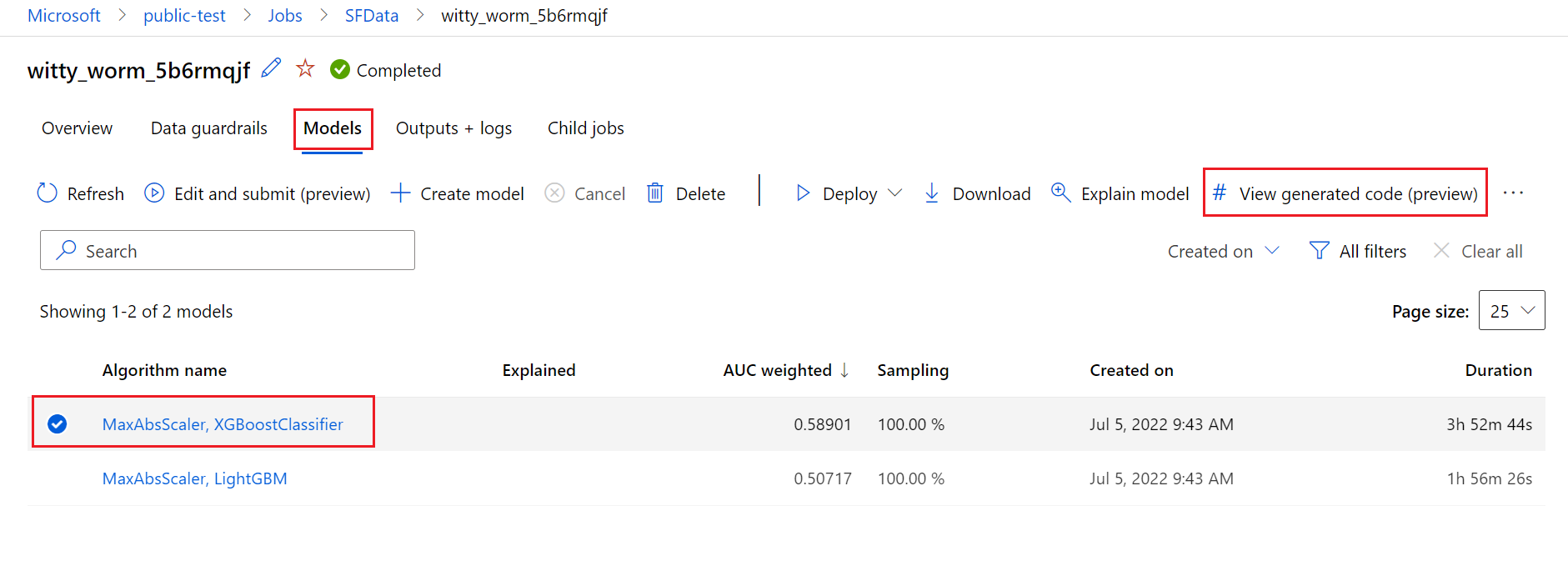
Для этого перейдите на вкладку "Модели" страницы родительского запуска эксперимента автоматизированного машинного обучения. Выбрав одну из обученных моделей, нажмите кнопку "Вид созданного кода ". Эта кнопка перенаправит вас на расширение портала Записные книжки, где можно просмотреть, изменить и запустить созданный код для конкретной выбранной модели.
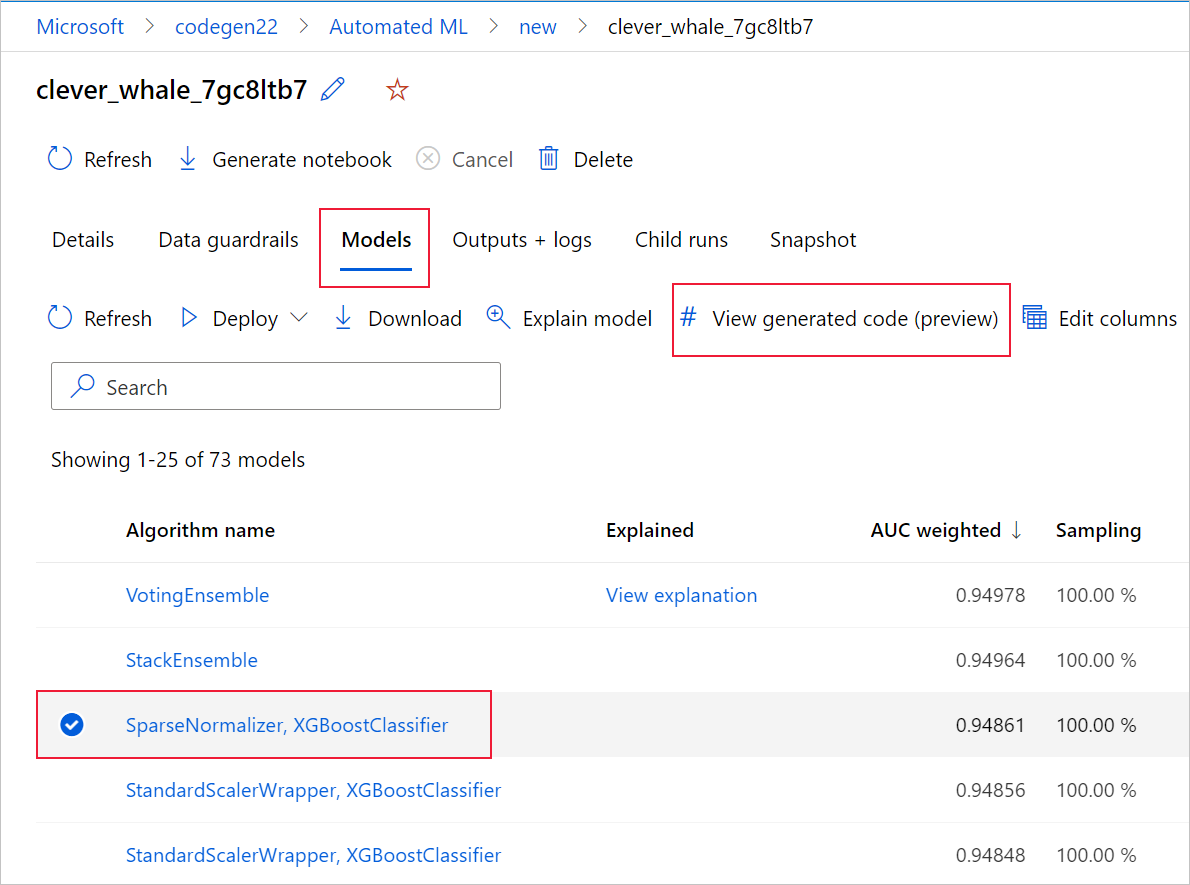
Вы также можете получить доступ к созданному коду модели в верхней части страницы дочернего запуска после перехода на страницу этого дочернего запуска определенной модели.
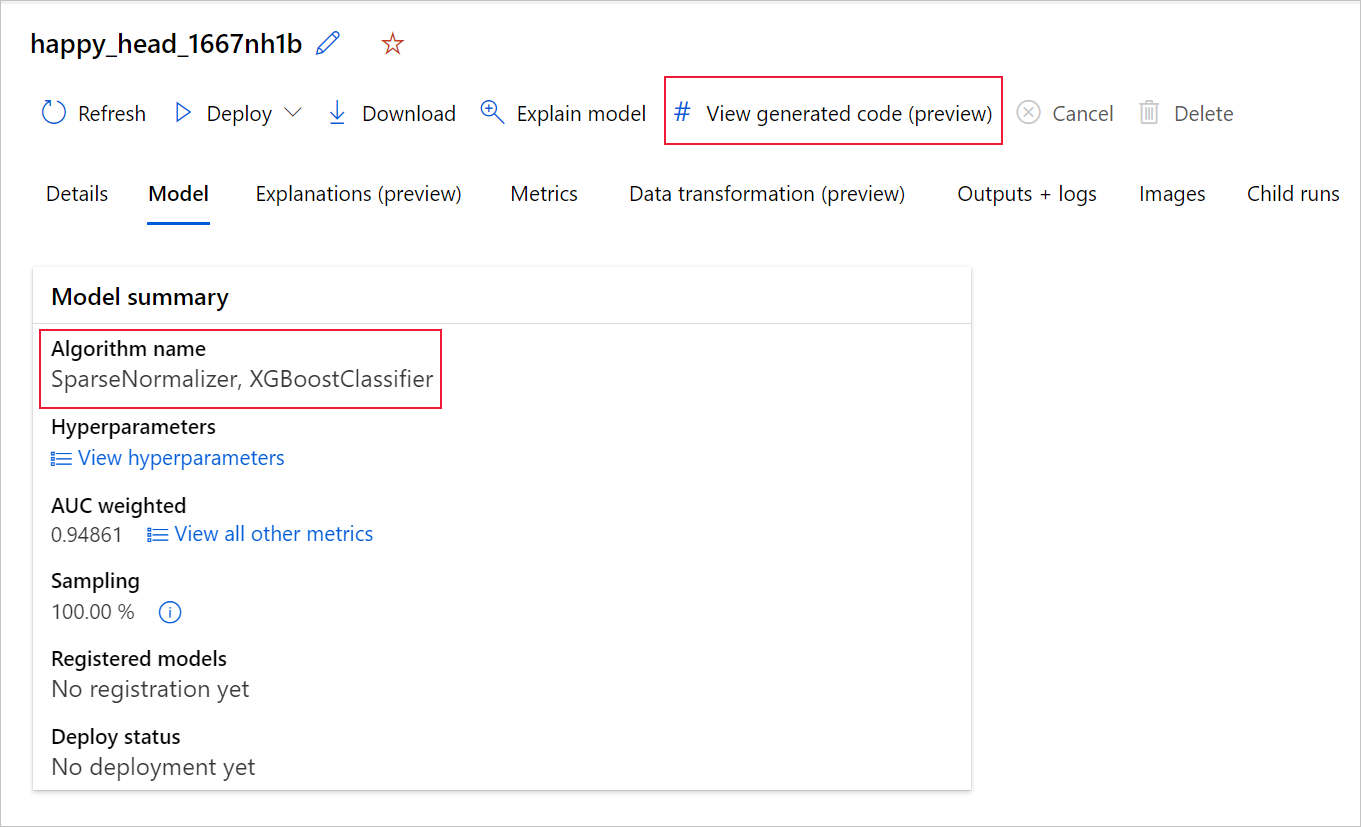
Если вы используете SDKv2 для Python, вы также можете скачать "script.py" и "script_run_notebook.ipynb", получив лучший запуск через MLFlow и скачать полученные артефакты.
Ограничения
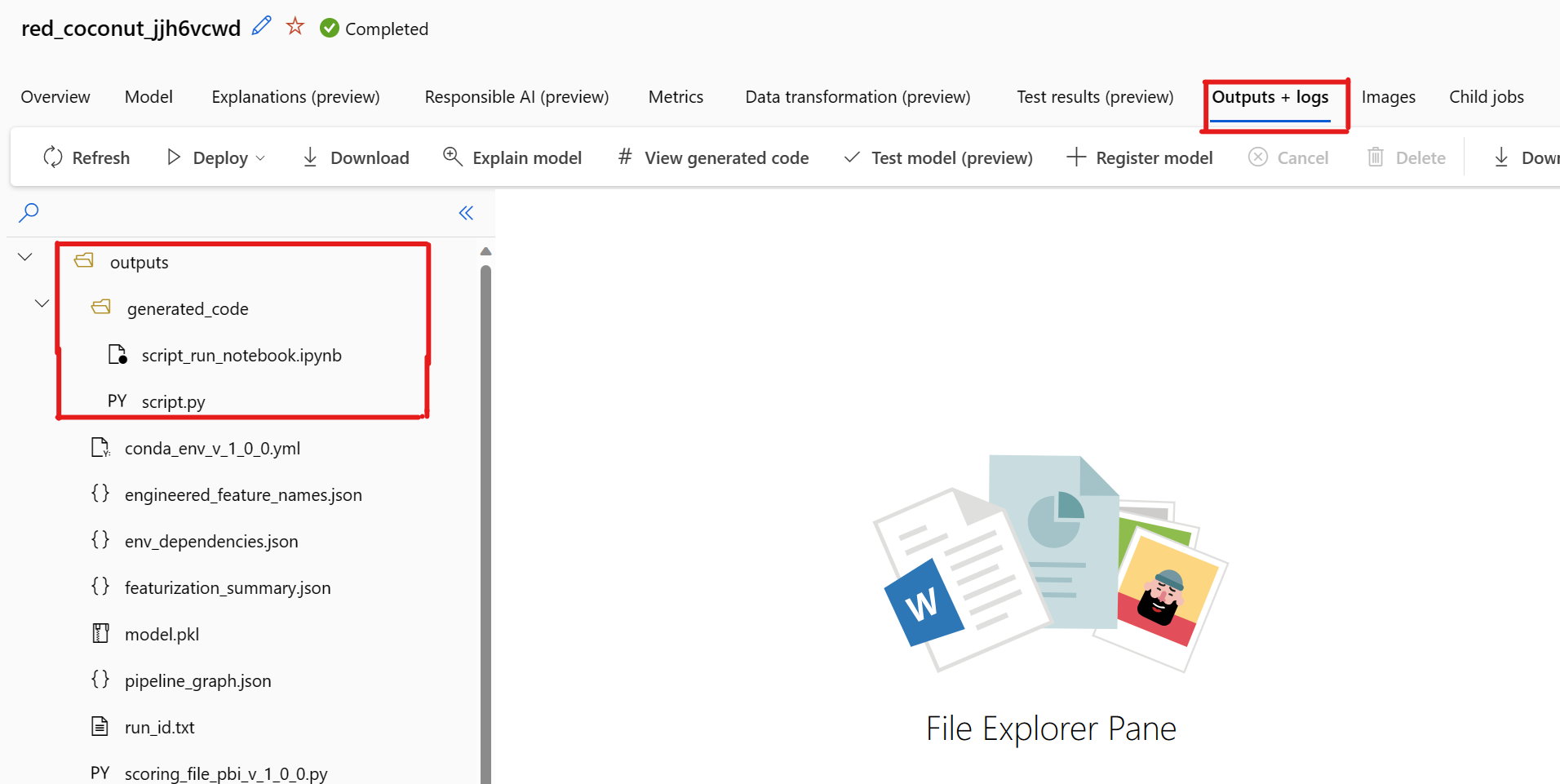
При выборе представления созданного кода возникает известная проблема. Это действие не удается перенаправить на портал записных книжек, когда хранилище находится за виртуальной сетью. В качестве обходного решения пользователь может вручную скачать script.py и файлы script_run_notebook.ipynb, перейдя на вкладку Outputs + Logs в папке выходных>данных generated_code. Эти файлы можно отправить вручную в папку записных книжек, чтобы запустить или изменить их. Перейдите по этой ссылке, чтобы узнать больше о виртуальных сетями в Машинное обучение Azure.
script.py
Файл script.py содержит основную логику, необходимую для обучения модели с помощью ранее использованных гиперпараметров. Хотя он предназначен для выполнения в контексте выполнения скрипта Машинное обучение Azure с некоторыми изменениями, код обучения модели также может быть запущен автономным в локальной среде.
Скрипт можно разделить на несколько следующих частей: загрузка данных, подготовка данных, конструирование признаков данных, спецификация препроцессора и алгоритма, а также обучение.
Загрузка данных
Функция get_training_dataset() загружает ранее использовавшийся набор данных. Предполагается, что скрипт выполняется в скрипте Машинное обучение Azure, выполняемом в той же рабочей области, что и исходный эксперимент.
def get_training_dataset(dataset_id):
from azureml.core.dataset import Dataset
from azureml.core.run import Run
logger.info("Running get_training_dataset")
ws = Run.get_context().experiment.workspace
dataset = Dataset.get_by_id(workspace=ws, id=dataset_id)
return dataset.to_pandas_dataframe()
При запуске в ходе выполнения скрипта Run.get_context().experiment.workspace получает нужную рабочую область. Однако если этот скрипт выполняется внутри другой рабочей области или выполняется локально, необходимо изменить скрипт, чтобы явно указать соответствующую рабочую область.
После получения рабочей области исходный набор данных извлекается по его идентификатору. Другой набор данных с точно такой же структурой также можно указать с помощью идентификатора или имени с get_by_id() или get_by_name(), соответственно. Идентификатор можно найти позже в скрипте, в том же разделе, что и следующий код.
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--training_dataset_id', type=str, default='xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxx', help='Default training dataset id is populated from the parent run')
args = parser.parse_args()
main(args.training_dataset_id)
Вы также можете заменить всю эту функцию собственным механизмом загрузки данных. Единственное ограничение заключается в том, что возвращаемое значение должно быть кадром данных Pandas, а данные должны иметь ту же форму, что и в исходном эксперименте.
Код подготовки данных
Функция prepare_data() очищает данные, разделяет их, выделяет весовые столбцы и подготавливает данные для использования в обучении.
Эта функция может отличаться в зависимости от типа набора данных и типа задачи эксперимента: классификация, регрессия, прогнозирование временных рядов, изображения или задачи NLP.
В следующем примере показано, что в целом передается кадр данных из шага загрузки данных. Извлекаются столбцы меток и выборки веса, если они были изначально указаны, а строки, содержащие NaN, удаляются из входных данных.
def prepare_data(dataframe):
from azureml.training.tabular.preprocessing import data_cleaning
logger.info("Running prepare_data")
label_column_name = 'y'
# extract the features, target and sample weight arrays
y = dataframe[label_column_name].values
X = dataframe.drop([label_column_name], axis=1)
sample_weights = None
X, y, sample_weights = data_cleaning._remove_nan_rows_in_X_y(X, y, sample_weights,
is_timeseries=False, target_column=label_column_name)
return X, y, sample_weights
Если вы хотите выполнить дополнительную подготовку данных, его можно сделать на этом шаге, добавив пользовательский код подготовки данных.
Код конструирования признаков
Функция generate_data_transformation_config() задает шаг конструирования признаков в заключительном конвейере scikit-learn. Конструкторы признаков из исходного эксперимента воспроизводятся здесь вместе с их параметрами.
Например, возможное преобразование данных, которое может произойти в этой функции, может основываться на таких импьютерах, как SimpleImputer() и CatImputer(), или в таких преобразователях, как StringCastTransformer() и LabelEncoderTransformer().
Ниже приведен преобразователь типа StringCastTransformer(), который можно использовать для преобразования набора столбцов. В этом случае набор, указанный параметром column_names.
def get_mapper_0(column_names):
# ... Multiple imports to package dependencies, removed for simplicity ...
definition = gen_features(
columns=column_names,
classes=[
{
'class': StringCastTransformer,
},
{
'class': CountVectorizer,
'analyzer': 'word',
'binary': True,
'decode_error': 'strict',
'dtype': numpy.uint8,
'encoding': 'utf-8',
'input': 'content',
'lowercase': True,
'max_df': 1.0,
'max_features': None,
'min_df': 1,
'ngram_range': (1, 1),
'preprocessor': None,
'stop_words': None,
'strip_accents': None,
'token_pattern': '(?u)\\b\\w\\w+\\b',
'tokenizer': wrap_in_lst,
'vocabulary': None,
},
]
)
mapper = DataFrameMapper(features=definition, input_df=True, sparse=True)
return mapper
Если у вас есть много столбцов, которые должны иметь одинаковые признаки или преобразование (например, 50 столбцов в нескольких группах столбцов), эти столбцы обрабатываются группированием на основе типа.
В следующем примере обратите внимание, что к каждой группе применен уникальный модуль сопоставления. Затем этот модуль сопоставления применяется к каждому из столбцов этой группы.
def generate_data_transformation_config():
from sklearn.pipeline import FeatureUnion
column_group_1 = [['id'], ['ps_reg_01'], ['ps_reg_02'], ['ps_reg_03'], ['ps_car_11_cat'], ['ps_car_12'], ['ps_car_13'], ['ps_car_14'], ['ps_car_15'], ['ps_calc_01'], ['ps_calc_02'], ['ps_calc_03']]
column_group_2 = ['ps_ind_06_bin', 'ps_ind_07_bin', 'ps_ind_08_bin', 'ps_ind_09_bin', 'ps_ind_10_bin', 'ps_ind_11_bin', 'ps_ind_12_bin', 'ps_ind_13_bin', 'ps_ind_16_bin', 'ps_ind_17_bin', 'ps_ind_18_bin', 'ps_car_08_cat', 'ps_calc_15_bin', 'ps_calc_16_bin', 'ps_calc_17_bin', 'ps_calc_18_bin', 'ps_calc_19_bin', 'ps_calc_20_bin']
column_group_3 = ['ps_ind_01', 'ps_ind_02_cat', 'ps_ind_03', 'ps_ind_04_cat', 'ps_ind_05_cat', 'ps_ind_14', 'ps_ind_15', 'ps_car_01_cat', 'ps_car_02_cat', 'ps_car_03_cat', 'ps_car_04_cat', 'ps_car_05_cat', 'ps_car_06_cat', 'ps_car_07_cat', 'ps_car_09_cat', 'ps_car_10_cat', 'ps_car_11', 'ps_calc_04', 'ps_calc_05', 'ps_calc_06', 'ps_calc_07', 'ps_calc_08', 'ps_calc_09', 'ps_calc_10', 'ps_calc_11', 'ps_calc_12', 'ps_calc_13', 'ps_calc_14']
feature_union = FeatureUnion([
('mapper_0', get_mapper_0(column_group_1)),
('mapper_1', get_mapper_1(column_group_3)),
('mapper_2', get_mapper_2(column_group_2)),
])
return feature_union
Такой подход позволяет создавать более рациональный код, не настраивая блок кода преобразователя для каждого столбца, который может быть особенно громоздким даже при наличии десятков или сотен столбцов в наборе данных.
При использовании задач классификации и регрессии для модулей конструирования признаков используется [FeatureUnion].
Для моделей прогнозирования временных рядов несколько модулей конструирования признаков, учитывающих временные ряды, собираются в конвейер scikit-learn, а затем упаковываются в TimeSeriesTransformer.
Любое предоставленное пользователем конструирование признаков для моделей прогнозирования временных рядов, выполняется перед теми, которые предоставляются автоматизированным ML.
Код спецификации препроцессора
Функция generate_preprocessor_config(), если она есть, указывает шаг предварительной обработки, который будет выполнен после добавление признаков в заключительном конвейере scikit-learn.
Как правило, этот этап предварительной обработки состоит только из стандартизации и нормализации данных, которые выполняются с помощью sklearn.preprocessing.
Автоматизированное машинное обучение задает только этап предварительной обработки для моделей классификации и регрессии.
Ниже приведен пример созданного кода препроцессора:
def generate_preprocessor_config():
from sklearn.preprocessing import MaxAbsScaler
preproc = MaxAbsScaler(
copy=True
)
return preproc
Код спецификации алгоритма и гиперпараметров
Код спецификации алгоритма и гиперпараметров, скорее всего, является тем, в чем наиболее всего заинтересованы специалисты ML.
Функция generate_algorithm_config() задает фактический алгоритм и гиперпараметры для обучения модели как последнего этапа завершающего конвейера scikit-learn.
В следующем примере используется алгоритм XGBoostClassifier с конкретными гиперпараметрами.
def generate_algorithm_config():
from xgboost.sklearn import XGBClassifier
algorithm = XGBClassifier(
base_score=0.5,
booster='gbtree',
colsample_bylevel=1,
colsample_bynode=1,
colsample_bytree=1,
gamma=0,
learning_rate=0.1,
max_delta_step=0,
max_depth=3,
min_child_weight=1,
missing=numpy.nan,
n_estimators=100,
n_jobs=-1,
nthread=None,
objective='binary:logistic',
random_state=0,
reg_alpha=0,
reg_lambda=1,
scale_pos_weight=1,
seed=None,
silent=None,
subsample=1,
verbosity=0,
tree_method='auto',
verbose=-10
)
return algorithm
В большинстве случаев в созданном коде используются классы и пакеты ПО с открытым исходным кодом (OSS). Существуют экземпляры, в которых для упрощения более сложного кода используются промежуточные классы-оболочки. Например, можно применить классификатор XGBoost и другие часто используемые библиотеки, такие как LightGBM или алгоритмы Scikit-Learn.
Как специалист по машинному обучению вы можете настроить код конфигурации этого алгоритма, изменив его гиперпараметры по мере необходимости на основе навыков и опыта для этого алгоритма и конкретной проблемы машинного обучения.
Для объединенных моделей generate_preprocessor_config_N() (при необходимости) и generate_algorithm_config_N() определяются для каждого обучаемого в объединенной модели, где N представляет размещение каждого обучаемого в списке объединенной модели. Для объединенных моделей в стеке определяется мета-обучение generate_algorithm_config_meta().
Сквозной код обучения
Генерация кода создает build_model_pipeline() и train_model() для определения конвейера scikit-learn и для вызова fit() по нему соответственно.
def build_model_pipeline():
from sklearn.pipeline import Pipeline
logger.info("Running build_model_pipeline")
pipeline = Pipeline(
steps=[
('featurization', generate_data_transformation_config()),
('preproc', generate_preprocessor_config()),
('model', generate_algorithm_config()),
]
)
return pipeline
Конвейер scikit-learn включает шаг конструирования признаков, препроцессор (если используется), а также алгоритм или модель.
Для моделей прогнозирования временных рядов конвейер scikit-learn упаковывается в ForecastingPipelineWrapper, который содержит некоторую дополнительную логику, необходимую для правильной обработки данных временных рядов в зависимости от примененного алгоритма.
Для всех типов задач мы используем PipelineWithYTransformer в тех случаях, когда столбец меток необходимо закодировать.
Когда у вас есть конвейер scikit-learn, все, что осталось вызвать, — это метод fit() для обучения модели:
def train_model(X, y, sample_weights):
logger.info("Running train_model")
model_pipeline = build_model_pipeline()
model = model_pipeline.fit(X, y)
return model
Возвращаемое значение из train_model() — это модель, которая соответствует или обучена входным данным.
Ниже приведен основной код, запускающий все предыдущие функции:
def main(training_dataset_id=None):
from azureml.core.run import Run
# The following code is for when running this code as part of an Azure Machine Learning script run.
run = Run.get_context()
setup_instrumentation(run)
df = get_training_dataset(training_dataset_id)
X, y, sample_weights = prepare_data(df)
split_ratio = 0.1
try:
(X_train, y_train, sample_weights_train), (X_valid, y_valid, sample_weights_valid) = split_dataset(X, y, sample_weights, split_ratio, should_stratify=True)
except Exception:
(X_train, y_train, sample_weights_train), (X_valid, y_valid, sample_weights_valid) = split_dataset(X, y, sample_weights, split_ratio, should_stratify=False)
model = train_model(X_train, y_train, sample_weights_train)
metrics = calculate_metrics(model, X, y, sample_weights, X_test=X_valid, y_test=y_valid)
print(metrics)
for metric in metrics:
run.log(metric, metrics[metric])
После обучения модели ее можно использовать для прогнозирования с помощью метода predict(). Если ваш эксперимент предназначен для модели временных рядов, используйте метод forecast() для прогнозов.
y_pred = model.predict(X)
Наконец, модель сериализуется и сохраняется как файл .pkl с именем "model.pkl":
with open('model.pkl', 'wb') as f:
pickle.dump(model, f)
run.upload_file('outputs/model.pkl', 'model.pkl')
script_run_notebook. ipynb
Записная script_run_notebook.ipynb книжка служит простым способом выполнения script.py в Машинное обучение Azure вычислительных ресурсов.
Эта записная книжка аналогична имеющимся примерам записных книжек автоматизированного машинного обучения, однако, существует несколько ключевых отличий, как описано в следующих разделах.
Среда
Как правило, среда обучения для запуска автоматического ML автоматически задается пакетом SDK. Однако при запуске пользовательского скрипта, например созданного кода, автоматизированное машинное обучение больше не управляет процессом, поэтому для успешного выполнения задания команды необходимо указать среду.
Если возможно, при создании кода используется среда, которая использовалась в исходном эксперименте автоматизированного ML. Это гарантирует, что запуск скрипта обучения не завершится сбоем из-за отсутствия зависимостей, и имеет побочное преимущество в том, что не требует перестроения образа Docker, что экономит время и ресурсы вычислений.
Если вы вносите изменения в script.py это требование дополнительных зависимостей или хотите использовать собственную среду, необходимо соответствующим образом обновить среду.script_run_notebook.ipynb
Отправка эксперимента
Так как созданный код больше не управляется автоматизированным машинным обучением, вместо создания и отправки задания AutoML необходимо создать Command Job и указать созданный код (script.py) для него.
В следующем примере содержатся параметры и регулярные зависимости, необходимые для выполнения задания команды, например вычислений, среды и т. д.
from azure.ai.ml import command, Input
# To test with new training / validation datasets, replace the default dataset id(s) taken from parent run below
training_dataset_id = '<DATASET_ID>'
dataset_arguments = {'training_dataset_id': training_dataset_id}
command_str = 'python script.py --training_dataset_id ${{inputs.training_dataset_id}}'
command_job = command(
code=project_folder,
command=command_str,
environment='AutoML-Non-Prod-DNN:25',
inputs=dataset_arguments,
compute='automl-e2e-cl2',
experiment_name='build_70775722_9249eda8'
)
returned_job = ml_client.create_or_update(command_job)
print(returned_job.studio_url) # link to naviagate to submitted run in Azure Machine Learning Studio
Следующие шаги
- Узнайте больше о том, как и где можно развернуть модель.
- См. порядок включениея функций интерпретации, в частности в экспериментах автоматизированного машинного обучения.