Использование Машинного обучения Azure с пакетом Fairlearn с открытым кодом для оценки справедливости моделей машинного обучения (предварительная версия)
ОБЛАСТЬ ПРИМЕНЕНИЯ: Пакет SDK для Python для ML Azure версии 1
Пакет SDK для Python для ML Azure версии 1
В этом руководство вы узнаете, как использовать пакет Python Fairlearn с открытым кодом вместе с Машинным обучением Azure для выполнения следующих задач.
- Оценка справедливости прогнозов модели. Дополнительные сведения о справедливости в машинном обучении см. в статье о справедливости в машинном обучении.
- Отправка, перечисление и загрузка аналитических сведений об оценке справедливости в Студию машинного обучения Azure и из нее.
- Просмотр панели мониторинга оценки справедливости в Студии машинного обучения Azure для работы с аналитическими сведениями о справедливости моделей.
Примечание
Оценка справедливости не является чисто технической задачей. Этот пакет поможет вам оценивать справедливость модели машинного обучения, но только вы можете настраивать работу модели и принимать решения о ее работе. Хотя этот пакет помогает определить количественные метрики для оценки справедливости, разработчики моделей машинного обучения должны также выполнять качественный анализ, чтобы оценить справедливость собственных моделей.
Важно!
Эта функция сейчас доступна в виде общедоступной предварительной версии. Эта предварительная версия предоставляется без соглашения об уровне обслуживания. Ее не следует использовать для производственных рабочих нагрузок. Некоторые функции могут не поддерживаться или их возможности могут быть ограничены.
Дополнительные сведения см. в статье Дополнительные условия использования предварительных выпусков Microsoft Azure.
Пакет SDK для оценки справедливости Машинного обучения Azure
Пакет SDK для оценки справедливости Машинного обучения Azure azureml-contrib-fairness интегрирует пакет Python Fairlearn с открытым кодом с Машинным обучением Azure. Чтобы узнать больше об интеграции Fairlearn с Машинным обучением Azure, ознакомьтесь с этими примерами записных книжек. Дополнительные сведения о Fairlearn см. в руководстве по примерам и в примерах записных книжек.
Для установки пакетов azureml-contrib-fairness и fairlearn используйте следующие команды:
pip install azureml-contrib-fairness
pip install fairlearn==0.4.6
Более поздние версии Fairlearn также должны работать в следующем примере кода.
Отправка аналитических сведений о справедливости для одной модели
В следующем примере показано, как использовать пакет для оценки справедливости. Мы отправим аналитические сведения о справедливости модели в Машинное обучение Azure и просмотрим панель мониторинга оценки справедливости в Студии машинного обучения Azure.
Обучите пример модели в локальной записной книжке Jupyter Notebook.
В качестве набора данных используется известный набор данных переписи взрослых, который мы получаем из OpenML. Мы разыгрываем ситуацию принятия решения о кредите, в которой есть проблема с меткой, указывающей, погасил ли претендент предыдущий кредит. Мы обучим модель предсказывать, выплатят ли кредит люди, ранее не попадавшие в поле зрения. Такую модель можно использовать для принятия решений о кредитах.
import copy import numpy as np import pandas as pd from sklearn.compose import ColumnTransformer from sklearn.datasets import fetch_openml from sklearn.impute import SimpleImputer from sklearn.linear_model import LogisticRegression from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler, OneHotEncoder from sklearn.compose import make_column_selector as selector from sklearn.pipeline import Pipeline from raiwidgets import FairnessDashboard # Load the census dataset data = fetch_openml(data_id=1590, as_frame=True) X_raw = data.data y = (data.target == ">50K") * 1 # (Optional) Separate the "sex" and "race" sensitive features out and drop them from the main data prior to training your model X_raw = data.data y = (data.target == ">50K") * 1 A = X_raw[["race", "sex"]] X = X_raw.drop(labels=['sex', 'race'],axis = 1) # Split the data in "train" and "test" sets (X_train, X_test, y_train, y_test, A_train, A_test) = train_test_split( X_raw, y, A, test_size=0.3, random_state=12345, stratify=y ) # Ensure indices are aligned between X, y and A, # after all the slicing and splitting of DataFrames # and Series X_train = X_train.reset_index(drop=True) X_test = X_test.reset_index(drop=True) y_train = y_train.reset_index(drop=True) y_test = y_test.reset_index(drop=True) A_train = A_train.reset_index(drop=True) A_test = A_test.reset_index(drop=True) # Define a processing pipeline. This happens after the split to avoid data leakage numeric_transformer = Pipeline( steps=[ ("impute", SimpleImputer()), ("scaler", StandardScaler()), ] ) categorical_transformer = Pipeline( [ ("impute", SimpleImputer(strategy="most_frequent")), ("ohe", OneHotEncoder(handle_unknown="ignore")), ] ) preprocessor = ColumnTransformer( transformers=[ ("num", numeric_transformer, selector(dtype_exclude="category")), ("cat", categorical_transformer, selector(dtype_include="category")), ] ) # Put an estimator onto the end of the pipeline lr_predictor = Pipeline( steps=[ ("preprocessor", copy.deepcopy(preprocessor)), ( "classifier", LogisticRegression(solver="liblinear", fit_intercept=True), ), ] ) # Train the model on the test data lr_predictor.fit(X_train, y_train) # (Optional) View this model in the fairness dashboard, and see the disparities which appear: from raiwidgets import FairnessDashboard FairnessDashboard(sensitive_features=A_test, y_true=y_test, y_pred={"lr_model": lr_predictor.predict(X_test)})Войдите в Машинное обучение Azure и зарегистрируйте модель.
Панель мониторинга справедливости может интегрироваться с зарегистрированными или незарегистрированными моделями. Зарегистрируйте свою модель в Машинном обучении Azure с помощью следующих действий:
from azureml.core import Workspace, Experiment, Model import joblib import os ws = Workspace.from_config() ws.get_details() os.makedirs('models', exist_ok=True) # Function to register models into Azure Machine Learning def register_model(name, model): print("Registering ", name) model_path = "models/{0}.pkl".format(name) joblib.dump(value=model, filename=model_path) registered_model = Model.register(model_path=model_path, model_name=name, workspace=ws) print("Registered ", registered_model.id) return registered_model.id # Call the register_model function lr_reg_id = register_model("fairness_logistic_regression", lr_predictor)Выполните предварительное вычисление метрик справедливости.
Создайте словарь панели мониторинга с помощью пакета
metricsFairlearn. Метод_create_group_metric_setимеет аргументы, аналогичные конструктору панели мониторинга, за исключением того, что конфиденциальные функции передаются в виде словаря (чтобы обеспечить доступность имен). При вызове этого метода необходимо также указать тип прогноза (в данном случае это двоичная классификация).# Create a dictionary of model(s) you want to assess for fairness sf = { 'Race': A_test.race, 'Sex': A_test.sex} ys_pred = { lr_reg_id:lr_predictor.predict(X_test) } from fairlearn.metrics._group_metric_set import _create_group_metric_set dash_dict = _create_group_metric_set(y_true=y_test, predictions=ys_pred, sensitive_features=sf, prediction_type='binary_classification')Отправьте предварительно вычисленные метрики справедливости.
Теперь импортируйте пакет
azureml.contrib.fairness, чтобы выполнить отправку:from azureml.contrib.fairness import upload_dashboard_dictionary, download_dashboard_by_upload_idСоздайте эксперимент, затем запуск, и отправьте панель мониторинга:
exp = Experiment(ws, "Test_Fairness_Census_Demo") print(exp) run = exp.start_logging() # Upload the dashboard to Azure Machine Learning try: dashboard_title = "Fairness insights of Logistic Regression Classifier" # Set validate_model_ids parameter of upload_dashboard_dictionary to False if you have not registered your model(s) upload_id = upload_dashboard_dictionary(run, dash_dict, dashboard_name=dashboard_title) print("\nUploaded to id: {0}\n".format(upload_id)) # To test the dashboard, you can download it back and ensure it contains the right information downloaded_dict = download_dashboard_by_upload_id(run, upload_id) finally: run.complete()Проверка панели мониторинга справедливости в Студии машинного обучения Azure
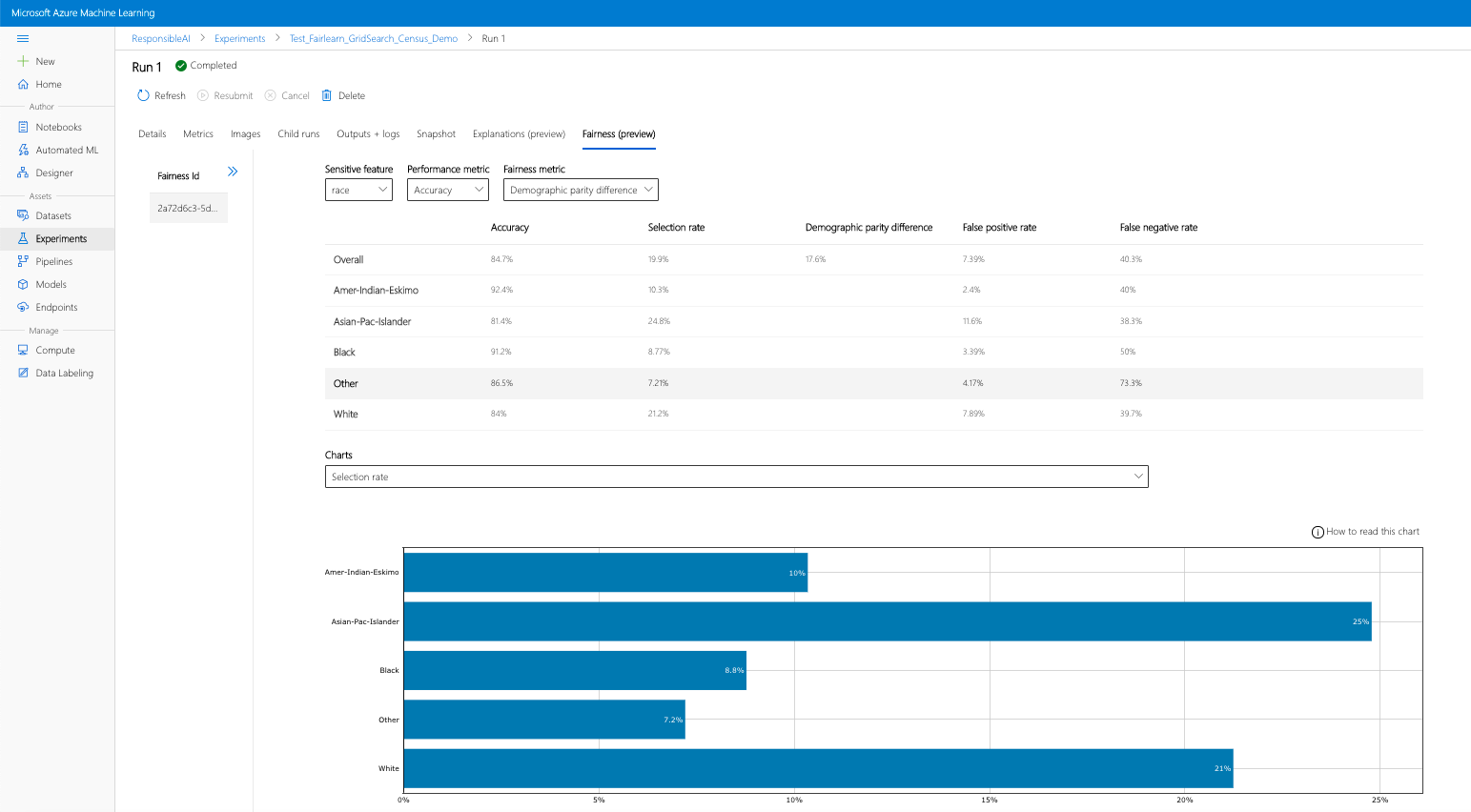
Если вы выполните предыдущие действия (отправку созданной аналитики справедливости в Машинное обучение Azure), то сможете просматривать панель мониторинга справедливости в Студии машинного обучения Azure. Эта панель мониторинга — та же панель визуализации, предоставляемая в Fairlearn, которая позволяет анализировать различия между подгруппами признаков, требующих особого обращения (например, между мужчинами и женщинами). Для доступа к панели мониторинга визуализации в Студии машинного обучения Azure используйте один из указанных ниже путей.
- Панель заданий (предварительная версия)
- Выберите Задания на панели слева, чтобы просмотреть список экспериментов, которые были выполнены в Машинном обучении Azure.
- Выберите конкретный эксперимент, чтобы просмотреть все запуски в этом эксперименте.
- Выберите запуск, а затем перейдите на вкладку Fairness (Справедливость), чтобы открыть панель мониторинга визуализации пояснения.
- После перехода на вкладку Fairness (Справедливость) щелкните идентификатор справедливости в меню справа.
- Настройте панель мониторинга, выбрав атрибут конфиденциальности, метрику производительности и метрику справедливости, чтобы попасть на страницу оценки справедливости.
- Переключайтесь с одного типа диаграммы на другой, чтобы наблюдать за негативными эффектами распределения и негативными эффектами качества обслуживания.

- Панель моделей
- Если вы зарегистрировали исходную модель, выполнив предыдущие действия, то можете выбрать пункт Models в левой области, чтобы просмотреть свою модель.
- Выберите модель, а затем откройте вкладку Fairness (Справедливость), чтобы просмотреть панель мониторинга визуализации пояснения.
Дополнительные сведения о панели мониторинга визуализации и содержащихся в ней элементах см. в руководстве пользователя Fairlearn.


Отправка аналитических сведений о справедливости для нескольких моделей
Чтобы сравнить несколько моделей и увидеть, как различаются их оценки справедливости, можно передать на панель мониторинга визуализации несколько моделей и сравнить их компромиссы между эффективностью и справедливостью.
Обучите свои модели.
Теперь мы создадим второй классификатор на основе оценщика, использующего метод опорных векторов, и отправим словарь панели мониторинга справедливости с помощью пакета
metricsFairlearn. Предполагается, что ранее обученная модель по-прежнему доступна.# Put an SVM predictor onto the preprocessing pipeline from sklearn import svm svm_predictor = Pipeline( steps=[ ("preprocessor", copy.deepcopy(preprocessor)), ( "classifier", svm.SVC(), ), ] ) # Train your second classification model svm_predictor.fit(X_train, y_train)Зарегистрируйте модели
Теперь зарегистрируйте обе модели в Машинном обучении Azure. Для удобства сохраните результаты в словаре, который сопоставляет
idзарегистрированной модели (строку в форматеname:version) с самим прогнозом:model_dict = {} lr_reg_id = register_model("fairness_logistic_regression", lr_predictor) model_dict[lr_reg_id] = lr_predictor svm_reg_id = register_model("fairness_svm", svm_predictor) model_dict[svm_reg_id] = svm_predictorЛокальная загрузка панели мониторинга Fairness
Перед отправкой аналитических сведений о справедливости в Машинное обучение Azure можно проверить эти прогнозы в панели мониторинга Fairness, вызванной локально.
# Generate models' predictions and load the fairness dashboard locally ys_pred = {} for n, p in model_dict.items(): ys_pred[n] = p.predict(X_test) from raiwidgets import FairnessDashboard FairnessDashboard(sensitive_features=A_test, y_true=y_test.tolist(), y_pred=ys_pred)Выполните предварительное вычисление метрик справедливости.
Создайте словарь панели мониторинга с помощью пакета
metricsFairlearn.sf = { 'Race': A_test.race, 'Sex': A_test.sex } from fairlearn.metrics._group_metric_set import _create_group_metric_set dash_dict = _create_group_metric_set(y_true=Y_test, predictions=ys_pred, sensitive_features=sf, prediction_type='binary_classification')Отправьте предварительно вычисленные метрики справедливости.
Теперь импортируйте пакет
azureml.contrib.fairness, чтобы выполнить отправку:from azureml.contrib.fairness import upload_dashboard_dictionary, download_dashboard_by_upload_idСоздайте эксперимент, затем запуск, и отправьте панель мониторинга:
exp = Experiment(ws, "Compare_Two_Models_Fairness_Census_Demo") print(exp) run = exp.start_logging() # Upload the dashboard to Azure Machine Learning try: dashboard_title = "Fairness Assessment of Logistic Regression and SVM Classifiers" # Set validate_model_ids parameter of upload_dashboard_dictionary to False if you have not registered your model(s) upload_id = upload_dashboard_dictionary(run, dash_dict, dashboard_name=dashboard_title) print("\nUploaded to id: {0}\n".format(upload_id)) # To test the dashboard, you can download it back and ensure it contains the right information downloaded_dict = download_dashboard_by_upload_id(run, upload_id) finally: run.complete()Как и в предыдущем разделе, вы можете следовать одному из описанных выше путей (используя эксперименты или модели) в Студии машинного обучения Azure, чтобы получить доступ к панели мониторинга визуализации и сравнить две модели с точки зрения справедливости и эффективности.
Отправка исходных и смягченных аналитических сведений о справедливости
Вы можете использовать алгоритмы смягчения Fairlearn, сравнивать созданные ими смягченные модели с исходной моделью без смягчения и таким образом выбрать компромисс между эффективностью и справедливостью среди сравниваемых моделей.
Пример, демонстрирующий использование алгоритма смягчения Grid Search (поиск по сетке), который создает коллекцию смягчаемых моделей с разными компромиссами между справедливостью и эффективностью, см. в этом примере записной книжки.
Отправка аналитических сведений о справедливости нескольких моделей в один запуск позволяет сравнивать модели с точки зрения справедливости и эффективности. Вы можете щелкнуть любую из моделей, отображаемых на диаграмме сравнения моделей, чтобы просмотреть подробные сведения о справедливости этой конкретной модели.

Дальнейшие действия
Узнайте больше о справедливости моделей
Ознакомьтесь с примерами записных книжек Azure Machine Learning Fairness