Использование пакета интерпретации Python для объяснения моделей машинного обучения и прогнозов (предварительная версия)
ОБЛАСТЬ ПРИМЕНЕНИЯ: Пакет SDK для Python версии 1
Пакет SDK для Python версии 1
Из этого пошагового руководства вы узнаете, как использовать пакет интерпретации SDK на Python для службы "Машинное обучение Azure" для выполнения следующих задач:
Пояснение принципов работы всей модели и отдельных прогнозов на локальном персональном компьютере.
Задействование приемов интерпретации для сконструированных признаков.
Пояснение принципов работы всей модели и отдельных прогнозов в Azure.
Отправка объяснений в журнал выполнения Машинного обучения Azure.
Использование панели мониторинга визуализации для взаимодействия с объяснениями модели как в записной Jupyter Notebook, так и в Студии машинного обучения Azure.
Развертывание блока пояснения оценки вместе с моделью для отслеживания пояснений во время ее работы.
Внимание
Эта функция сейчас доступна в виде общедоступной предварительной версии. Эта предварительная версия предоставляется без соглашения об уровне обслуживания. Ее не следует использовать для производственных рабочих нагрузок. Некоторые функции могут не поддерживаться или их возможности могут быть ограничены.
Дополнительные сведения см. в статье Дополнительные условия использования Предварительных версий Microsoft Azure.
Дополнительные сведения о поддерживаемых методиках интерпретации и моделях машинного обучения см. в статье Интерпретируемость моделей в Машинном обучении Azure и в примерах записных книжек.
Инструкции по включению интерпретируемости моделей, обученных с применением автоматизированного машинного обучения, см. в статье Интерпретируемость: пояснения к моделям автоматизированного машинного обучения (предварительная версия).
Создание значения важности признака на собственном компьютере
В примере ниже показано, как использовать пакет интерпретации на собственном компьютере без обращения к службам Azure.
Установите пакет
azureml-interpret.pip install azureml-interpretОбучите образец модели в локальной записной книжке Jupyter Notebook.
# load breast cancer dataset, a well-known small dataset that comes with scikit-learn from sklearn.datasets import load_breast_cancer from sklearn import svm from sklearn.model_selection import train_test_split breast_cancer_data = load_breast_cancer() classes = breast_cancer_data.target_names.tolist() # split data into train and test from sklearn.model_selection import train_test_split x_train, x_test, y_train, y_test = train_test_split(breast_cancer_data.data, breast_cancer_data.target, test_size=0.2, random_state=0) clf = svm.SVC(gamma=0.001, C=100., probability=True) model = clf.fit(x_train, y_train)Вызовите блок пояснения в локальной среде.
- Чтобы инициализировать объект блока пояснения, передайте модель и определенный объем обучающих данных в конструктор блока пояснения.
- Чтобы сделать пояснения и визуализации более информативными, можно передать имена признаков и выходных классов, если у вас выполняется классификация.
В следующих блоках кода показано, как локально создать экземпляр объекта блока пояснения с помощью
TabularExplainer,MimicExplainerиPFIExplainer.TabularExplainerвызывает один из трех блоков пояснения нижнего уровня (TreeExplainer,DeepExplainerилиKernelExplainer).TabularExplainerавтоматически выбирает наиболее подходящий вариант для вашего варианта использования, но можно вызывать любой из трех базовых блоков пояснения напрямую.
from interpret.ext.blackbox import TabularExplainer # "features" and "classes" fields are optional explainer = TabularExplainer(model, x_train, features=breast_cancer_data.feature_names, classes=classes)or
from interpret.ext.blackbox import MimicExplainer # you can use one of the following four interpretable models as a global surrogate to the black box model from interpret.ext.glassbox import LGBMExplainableModel from interpret.ext.glassbox import LinearExplainableModel from interpret.ext.glassbox import SGDExplainableModel from interpret.ext.glassbox import DecisionTreeExplainableModel # "features" and "classes" fields are optional # augment_data is optional and if true, oversamples the initialization examples to improve surrogate model accuracy to fit original model. Useful for high-dimensional data where the number of rows is less than the number of columns. # max_num_of_augmentations is optional and defines max number of times we can increase the input data size. # LGBMExplainableModel can be replaced with LinearExplainableModel, SGDExplainableModel, or DecisionTreeExplainableModel explainer = MimicExplainer(model, x_train, LGBMExplainableModel, augment_data=True, max_num_of_augmentations=10, features=breast_cancer_data.feature_names, classes=classes)or
from interpret.ext.blackbox import PFIExplainer # "features" and "classes" fields are optional explainer = PFIExplainer(model, features=breast_cancer_data.feature_names, classes=classes)
Пояснение принципов работы всей модели (глобальное пояснение)
Следующий пример поможет вам получить сводные (глобальные) значения важности признаков.
# you can use the training data or the test data here, but test data would allow you to use Explanation Exploration
global_explanation = explainer.explain_global(x_test)
# if you used the PFIExplainer in the previous step, use the next line of code instead
# global_explanation = explainer.explain_global(x_train, true_labels=y_train)
# sorted feature importance values and feature names
sorted_global_importance_values = global_explanation.get_ranked_global_values()
sorted_global_importance_names = global_explanation.get_ranked_global_names()
dict(zip(sorted_global_importance_names, sorted_global_importance_values))
# alternatively, you can print out a dictionary that holds the top K feature names and values
global_explanation.get_feature_importance_dict()
Пояснение отдельного прогноза (локальное пояснение)
Получение значений важности отдельных признаков для различных точек данных путем вызова пояснений для отдельного экземпляра или группы экземпляров.
Примечание.
PFIExplainer не поддерживает локальные пояснения.
# get explanation for the first data point in the test set
local_explanation = explainer.explain_local(x_test[0:5])
# sorted feature importance values and feature names
sorted_local_importance_names = local_explanation.get_ranked_local_names()
sorted_local_importance_values = local_explanation.get_ranked_local_values()
Преобразования исходных признаков
Вы можете просматривать пояснения в аспекте исходных (не подвергшихся преобразованию), а не сконструированных признаков. В этом случае конвейер преобразования признаков передается в блок пояснения в train_explain.py. В противном случае блок пояснения выдает пояснения для сконструированных признаков.
Формат поддерживаемых преобразований соответствует описанному для sklearn-pandas. В целом поддерживаются все преобразования при условии, что они работают с одним столбцом (т. е. обеспечивают соответствие "один ко многим").
Чтобы получить описание исходных признаков, используйте sklearn.compose.ColumnTransformer или список подобранных кортежей преобразователя. В следующем примере используется sklearn.compose.ColumnTransformer.
from sklearn.compose import ColumnTransformer
numeric_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='median')),
('scaler', StandardScaler())])
categorical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='constant', fill_value='missing')),
('onehot', OneHotEncoder(handle_unknown='ignore'))])
preprocessor = ColumnTransformer(
transformers=[
('num', numeric_transformer, numeric_features),
('cat', categorical_transformer, categorical_features)])
# append classifier to preprocessing pipeline.
# now we have a full prediction pipeline.
clf = Pipeline(steps=[('preprocessor', preprocessor),
('classifier', LogisticRegression(solver='lbfgs'))])
# clf.steps[-1][1] returns the trained classification model
# pass transformation as an input to create the explanation object
# "features" and "classes" fields are optional
tabular_explainer = TabularExplainer(clf.steps[-1][1],
initialization_examples=x_train,
features=dataset_feature_names,
classes=dataset_classes,
transformations=preprocessor)
Если вы хотите выполнить пример со списком подобранных кортежей преобразователя, используйте следующий код:
from sklearn.pipeline import Pipeline
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.linear_model import LogisticRegression
from sklearn_pandas import DataFrameMapper
# assume that we have created two arrays, numerical and categorical, which holds the numerical and categorical feature names
numeric_transformations = [([f], Pipeline(steps=[('imputer', SimpleImputer(
strategy='median')), ('scaler', StandardScaler())])) for f in numerical]
categorical_transformations = [([f], OneHotEncoder(
handle_unknown='ignore', sparse=False)) for f in categorical]
transformations = numeric_transformations + categorical_transformations
# append model to preprocessing pipeline.
# now we have a full prediction pipeline.
clf = Pipeline(steps=[('preprocessor', DataFrameMapper(transformations)),
('classifier', LogisticRegression(solver='lbfgs'))])
# clf.steps[-1][1] returns the trained classification model
# pass transformation as an input to create the explanation object
# "features" and "classes" fields are optional
tabular_explainer = TabularExplainer(clf.steps[-1][1],
initialization_examples=x_train,
features=dataset_feature_names,
classes=dataset_classes,
transformations=transformations)
Генерация значений важности признаков с помощью удаленных сеансов
В следующем примере показано, как с помощью класса ExplanationClient обеспечить интерпретируемость модели для удаленных сеансов. Это принципиально аналогично локальному процессу за исключением следующих моментов:
- При удаленном сеансе для передачи контекста интерпретации используется
ExplanationClient. - Впоследствии контекст загружается в локальную среду.
Установите пакет
azureml-interpret.pip install azureml-interpretСоздайте сценарий обучения в локальной записной книжке Jupyter. Например,
train_explain.py.from azureml.interpret import ExplanationClient from azureml.core.run import Run from interpret.ext.blackbox import TabularExplainer run = Run.get_context() client = ExplanationClient.from_run(run) # write code to get and split your data into train and test sets here # write code to train your model here # explain predictions on your local machine # "features" and "classes" fields are optional explainer = TabularExplainer(model, x_train, features=feature_names, classes=classes) # explain overall model predictions (global explanation) global_explanation = explainer.explain_global(x_test) # uploading global model explanation data for storage or visualization in webUX # the explanation can then be downloaded on any compute # multiple explanations can be uploaded client.upload_model_explanation(global_explanation, comment='global explanation: all features') # or you can only upload the explanation object with the top k feature info #client.upload_model_explanation(global_explanation, top_k=2, comment='global explanation: Only top 2 features')Настройте Вычислительную среду Машинного обучения Azure в качестве целевого объекта вычислений и отправьте обучающий сеанс. Инструкции см. в статье Создание вычислительных кластеров для Машинного обучения Azure и управление ими. Также рекомендуем ознакомиться с примерами записных книжек.
Скачайте пояснение в локальную записную книжку Jupyter Notebook.
from azureml.interpret import ExplanationClient client = ExplanationClient.from_run(run) # get model explanation data explanation = client.download_model_explanation() # or only get the top k (e.g., 4) most important features with their importance values explanation = client.download_model_explanation(top_k=4) global_importance_values = explanation.get_ranked_global_values() global_importance_names = explanation.get_ranked_global_names() print('global importance values: {}'.format(global_importance_values)) print('global importance names: {}'.format(global_importance_names))
Визуализации
После скачивания пояснений в локальную записную книжку Jupyter Notebook для анализа и интерпретации модели можно использовать визуализации на панели мониторинга пояснений. Чтобы загрузить мини-приложение панели мониторинга пояснений в записную книжку Jupyter Notebook, используйте следующий код.
from raiwidgets import ExplanationDashboard
ExplanationDashboard(global_explanation, model, datasetX=x_test)
Визуализация поддерживает пояснения как для сконструированных, так и для исходных признаков. Пояснения исходных признаков основаны на признаках исходного набора данных, а сконструированных признаков — на признаках набора данных, к которому применены функции конструирования признаков.
При попытке интерпретировать модель для исходного набора данных рекомендуется использовать исходные объяснения, так как важность каждого признака будет соответствовать столбцу из исходного набора. Один из сценариев, в котором могут быть полезны пояснения сконструированных признаков, — анализ влияния категориального признака на отдельные категории. Если к категориальному признаку применяется прямое кодирование, то в итоговых сконструированных пояснениях будет использоваться другое значение важности для каждой категории (по одному на сконструированный признак с прямым кодированием). Это кодирование может быть полезно при выборе той части набора данных, которая является наиболее информативной для модели.
Примечание.
Сконструированные и исходные пояснения вычисляются последовательно. Сначала создается сконструированное пояснение на основе модели и конвейера конструирования признаков. Затем на основе этого сконструированного пояснения создается исходное пояснение путем агрегирования важности сконструированных признаков, в основе которых — один исходный признак.
Создание, изменение и просмотр когорт набора данных
На верхней ленте показана общая статистика по модели и данным. Содержимое набора данных можно выделять и группировать в когорты (подгруппы) для исследования и сравнения результативности модели и пояснений по этим подгруппам. Сравнивая статистику набора данных и пояснения по подгруппам, можно получить представление о причинах возникновения ошибок в разных группах.

Анализ принципов работы всей модели (глобальное пояснение)
Первые три вкладки панели мониторинга пояснений предназначены для общего анализа обученной модели, а также ее прогнозов и пояснений.
Эффективность модели
Чтобы оценить результативность модели, изучите распределение прогнозируемых значений и значения метрик производительности. Для более глубокого исследования модели можно рассмотреть сравнительный анализ ее результативности по разным когортам и подгруппах набора данных. Чтобы получить срезы данных по разным измерениям, используйте фильтры значений по осям x и y. Просматривайте такие метрики, таких как правильность, точность, полнота, коэффициент ложноположительных и ложноотрицательных результатов.

Обозреватель данных
Для изучения статистики набора данных можно настраивать фильтры по осям X, Y и цветовым осям, позволяющие создавать срез по разным измерениям. Описанные выше когорты набора данных позволяют анализировать статистику набора с помощью фильтров, таких как прогнозируемый результат, признаки набора данных и группы ошибок. С помощью значка шестеренки в правом верхнем углу графика можно изменить его тип.

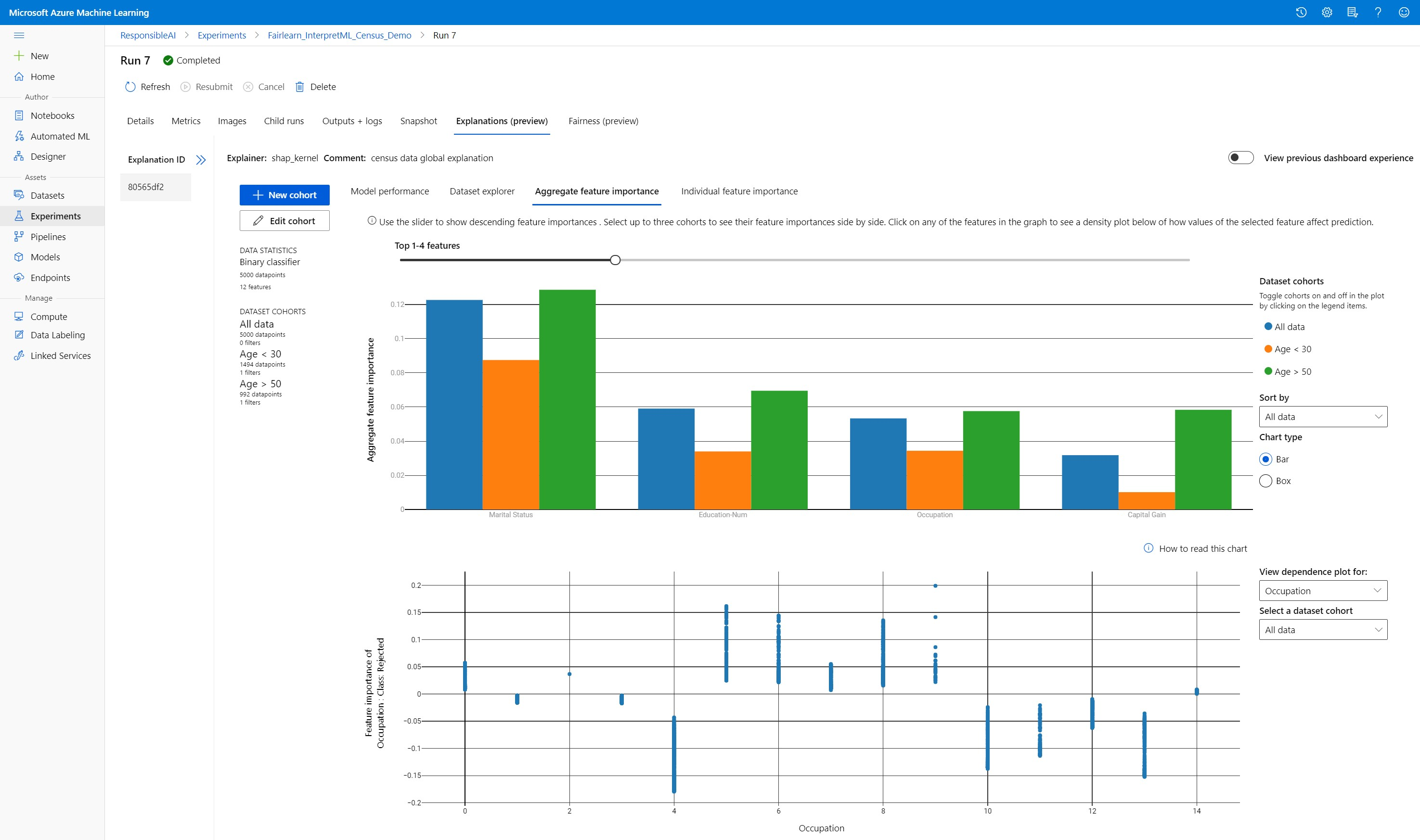
Совокупная важность признаков
Изучите первые k важных признаков, влияющих на общие прогнозы по вашей модели (это также называется "глобальным пояснением"). Используйте ползунок для отображения важности признаков в порядке убывания. Выберите когорты (не более трех), чтобы просмотреть важность их признаков одновременно. Выберите столбец с любым из признаков на графике, чтобы увидеть, как значения выбранного признака влияют на прогноз модели на графике зависимостей ниже.

Общие сведения о конкретных прогнозах (локальное пояснение)
Четвертая вкладка вкладки пояснения позволяет детализировать отдельные точки данных и их индивидуальные характеристики. Вы можете загрузить график важности отдельных признаков для любой точки данных, щелкнув любую из отдельных точек на главной точечной диаграмме или выбрав определенную точку в мастере панели справа.
| Графическое представления | Description |
|---|---|
| Важность отдельных признаков | Показывает первые k важных признаков для определенного прогноза. Помогает проиллюстрировать локальное поведение базовой модели в определенной точке данных. |
| Анализ "что если" | Позволяет изменять значения признаков выбранной реальной точки данных и отслеживать итоговые изменения в прогнозируемых значениях, создавая гипотетическую точку данных с новыми значениями признаков. |
| Индивидуальное условное ожидание (ICE) | Позволяет менять значение признака с минимального уровня до максимального. Помогает проиллюстрировать изменение прогноза для точки данных при изменении признака. |

Примечание.
Приведенные здесь пояснения основаны на многочисленных аппроксимациях и не являются "причиной" прогнозов. Этот инструмент не позволяет сделать математически обоснованный причинно-следственный вывод, поэтому мы не рекомендуем пользователям принимать на его основе решения в реальных ситуациях. Это средство в основном предназначено для понимания модели и ее отладки.
Визуализация в Студии машинного обучения Azure
Выполнив инструкции по удаленной интерпретации (отправив созданное пояснение в журнал выполнения службы "Машинное обучение Azure"), вы можете просмотреть визуализации на панели мониторинга пояснений в студии Машинного обучения Azure. Эта панель мониторинга представляет собой более простую версию мини-приложения панели мониторинга, созданную в Jupyter Notebook. Создание точек данных для анализа "что если" и графики ICE отключены, так как в Студии машинного обучения Azure нет службы активных вычислений, которая может выполнять соответствующие расчеты в реальном времени.
Если доступны набор данных, глобальное и локальное пояснения, данные подставляются на все вкладки. Однако, если доступно только глобальное пояснение, вкладка "Важность отдельных признаков" отключена.
Используйте один из следующих путей, чтобы получить доступ к панели мониторинга пояснений в студии Машинного обучения Azure.
Панель Эксперименты (предварительная версия)
- Выберите Experiments (Эксперименты) в панели слева, чтобы просмотреть список экспериментов, которые были выполнены в Машинном обучении Azure.
- Выберите конкретный эксперимент, чтобы просмотреть все сеансы выполнения в этом эксперименте.
- Выберите сеанс выполнения, а затем перейдите на вкладку Пояснения, чтобы открыть панель мониторинга визуализации пояснения.
Панель моделей
- Если вы зарегистрировали исходную модель, выполнив действия, описанные в разделе Развертывание моделей с помощью Машинного обучения Azure, вы можете выбрать модели на левой панели, чтобы просмотреть их.
- Выберите модель, а затем откройте вкладку Пояснения, чтобы просмотреть панель мониторинга пояснений.

Интерпретация во время вывода
Вы можете развернуть блок пояснения вместе с исходной моделью и использовать его во время вывода для получения значений важности отдельных признаков (локального пояснения) для любой новой точки. Мы также предлагаем упрощенные блоки пояснения оценки для повышения качества интерпретации во время вывода (в настоящее время они поддерживаются только в SDK службы "Машинное обучение Azure"). Процесс развертывания упрощенного блока пояснения оценки аналогичен развертыванию модели и состоит из перечисленных ниже этапов.
Создайте объект пояснения. Например, можно использовать
TabularExplainer.from interpret.ext.blackbox import TabularExplainer explainer = TabularExplainer(model, initialization_examples=x_train, features=dataset_feature_names, classes=dataset_classes, transformations=transformations)Создайте блок пояснения оценки с помощью объекта пояснения.
from azureml.interpret.scoring.scoring_explainer import KernelScoringExplainer, save # create a lightweight explainer at scoring time scoring_explainer = KernelScoringExplainer(explainer) # pickle scoring explainer # pickle scoring explainer locally OUTPUT_DIR = 'my_directory' save(scoring_explainer, directory=OUTPUT_DIR, exist_ok=True)Создайте и зарегистрируйте образ, использующий модель блока пояснения оценки.
# register explainer model using the path from ScoringExplainer.save - could be done on remote compute # scoring_explainer.pkl is the filename on disk, while my_scoring_explainer.pkl will be the filename in cloud storage run.upload_file('my_scoring_explainer.pkl', os.path.join(OUTPUT_DIR, 'scoring_explainer.pkl')) scoring_explainer_model = run.register_model(model_name='my_scoring_explainer', model_path='my_scoring_explainer.pkl') print(scoring_explainer_model.name, scoring_explainer_model.id, scoring_explainer_model.version, sep = '\t')В качестве дополнительного шага можно получить блок пояснения оценки из облака и протестировать пояснения.
from azureml.interpret.scoring.scoring_explainer import load # retrieve the scoring explainer model from cloud" scoring_explainer_model = Model(ws, 'my_scoring_explainer') scoring_explainer_model_path = scoring_explainer_model.download(target_dir=os.getcwd(), exist_ok=True) # load scoring explainer from disk scoring_explainer = load(scoring_explainer_model_path) # test scoring explainer locally preds = scoring_explainer.explain(x_test) print(preds)Разверните образ на целевом объекте вычислений, выполнив указанные ниже действия.
При необходимости зарегистрируйте исходную модель прогнозирования, выполнив действия, которые описаны в статье Развертывание моделей с помощью Машинного обучения Azure.
Создайте файл оценки.
%%writefile score.py import json import numpy as np import pandas as pd import os import pickle from sklearn.externals import joblib from sklearn.linear_model import LogisticRegression from azureml.core.model import Model def init(): global original_model global scoring_model # retrieve the path to the model file using the model name # assume original model is named original_prediction_model original_model_path = Model.get_model_path('original_prediction_model') scoring_explainer_path = Model.get_model_path('my_scoring_explainer') original_model = joblib.load(original_model_path) scoring_explainer = joblib.load(scoring_explainer_path) def run(raw_data): # get predictions and explanations for each data point data = pd.read_json(raw_data) # make prediction predictions = original_model.predict(data) # retrieve model explanations local_importance_values = scoring_explainer.explain(data) # you can return any data type as long as it is JSON-serializable return {'predictions': predictions.tolist(), 'local_importance_values': local_importance_values}Определите конфигурацию развертывания.
Эта конфигурация зависит от требований модели. В следующем примере определяется конфигурация c одним ядром ЦП и 1 ГБ памяти.
from azureml.core.webservice import AciWebservice aciconfig = AciWebservice.deploy_configuration(cpu_cores=1, memory_gb=1, tags={"data": "NAME_OF_THE_DATASET", "method" : "local_explanation"}, description='Get local explanations for NAME_OF_THE_PROBLEM')Создайте файл с зависимостями среды.
from azureml.core.conda_dependencies import CondaDependencies # WARNING: to install this, g++ needs to be available on the Docker image and is not by default (look at the next cell) azureml_pip_packages = ['azureml-defaults', 'azureml-core', 'azureml-telemetry', 'azureml-interpret'] # specify CondaDependencies obj myenv = CondaDependencies.create(conda_packages=['scikit-learn', 'pandas'], pip_packages=['sklearn-pandas'] + azureml_pip_packages, pin_sdk_version=False) with open("myenv.yml","w") as f: f.write(myenv.serialize_to_string()) with open("myenv.yml","r") as f: print(f.read())Создайте пользовательский Dockerfile с установленным g++.
%%writefile dockerfile RUN apt-get update && apt-get install -y g++Разверните созданный образ.
Этот процесс занимает примерно пять минут.
from azureml.core.webservice import Webservice from azureml.core.image import ContainerImage # use the custom scoring, docker, and conda files we created above image_config = ContainerImage.image_configuration(execution_script="score.py", docker_file="dockerfile", runtime="python", conda_file="myenv.yml") # use configs and models generated above service = Webservice.deploy_from_model(workspace=ws, name='model-scoring-service', deployment_config=aciconfig, models=[scoring_explainer_model, original_model], image_config=image_config) service.wait_for_deployment(show_output=True)
Протестируйте развертывание.
import requests # create data to test service with examples = x_list[:4] input_data = examples.to_json() headers = {'Content-Type':'application/json'} # send request to service resp = requests.post(service.scoring_uri, input_data, headers=headers) print("POST to url", service.scoring_uri) # can covert back to Python objects from json string if desired print("prediction:", resp.text)Очистка.
Для удаления развернутой веб-службы используйте
service.delete().
Устранение неполадок
Не поддерживаются разреженные данные: при увеличении числа признаков панель мониторинга с пояснениями модели существенно замедляет или вообще прекращает работу, поэтому мы пока не поддерживаем формат разреженных данных. Кроме того, при работе с большими наборами данных и большим количеством признаков возникают общие проблемы с памятью.
Таблица поддерживаемых объяснений признаков
| Вкладка "Поддерживаемые объяснения" | Необработанные признаки (сжатый формат) | Необработанные признаки (разреженный формат) | Сконструированные признаки (сжатый формат) | Сконструированные признаки (разреженный формат) |
|---|---|---|---|---|
| Эффективность модели | Поддерживается (без прогнозирования) | Поддерживается (без прогнозирования) | Поддерживается | Поддерживается |
| Обозреватель данных | Поддерживается (без прогнозирования) | Не поддерживается. Поскольку разреженные данные не передаются, а в пользовательском интерфейсе возникают проблемы при отображении разреженных данных | Поддерживается | Не поддерживается. Поскольку разреженные данные не передаются, а в пользовательском интерфейсе возникают проблемы при отображении разреженных данных |
| Совокупная важность признаков | Поддерживается | Поддерживаемые | Поддерживаемые | Поддерживается |
| Важность отдельных признаков | Поддерживается (без прогнозирования) | Не поддерживается. Поскольку разреженные данные не передаются, а в пользовательском интерфейсе возникают проблемы при отображении разреженных данных | Поддерживается | Не поддерживается. Поскольку разреженные данные не передаются, а в пользовательском интерфейсе возникают проблемы при отображении разреженных данных |
Не поддерживаются модели прогнозирования в пояснениях моделей: интерпретация (пояснение для лучшей модели) недоступна в экспериментах по прогнозированию в AutoML, где в качестве наилучшей модели рекомендуются алгоритмы TCNForecaster, AutoArima, Prophet, ExponentialSmoothing, Average, Naive, Seasonal Average и Seasonal Naive. Регрессионные модели прогнозирования AutoML поддерживают объяснения. Однако на панели мониторинга объяснений вкладка "Важность отдельных признаков" не поддерживается для прогнозирования из-за сложности конвейеров данных.
Локальное пояснение для индекса данных: панель мониторинга пояснений не поддерживает связывание локальных значений важности с идентификаторами строк из исходного проверяемого набора данных, если этот набор данных содержит более 5000 точек данных, так как панель мониторинга случайным образом уменьшает выборку. Однако на вкладке "Важность отдельных признаков" отображаются значения признаков необработанного набора для каждой точки данных, передаваемой на панель мониторинга. Пользователи могут связывать локальные значения важности с исходным набором данных путем сопоставления значений признаков этого необработанного набора. Если размер набора данных проверки меньше 5000 примеров,
indexфункция в Студия машинного обучения Azure будет соответствовать индексу в наборе данных проверки.В Студии не поддерживаются графики анализа "что если" и ICE: в Студии машинного обучения Azure на вкладке "Пояснения" не поддерживаются графики анализа "что если" и индивидуальных условных ожиданий (ICE), так как для пересчета прогнозов и вероятностей затронутых признаков для отправленного пояснения необходимо активное вычисление. Сейчас эти графики поддерживаются в записных книжках Jupyter Notebook при запуске в качестве мини-приложения с помощью пакета SDK.
Следующие шаги
Методы интерпретации модели в Машинное обучение Azure
Образцы записных книжек интерпретации Машинного обучения Azure