Примечание
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
ОБЛАСТЬ ПРИМЕНЕНИЯ: Расширение машинного обучения Azure CLI версии 2 (current)Python SDK azure-ai-ml версии 2 (current)
Расширение машинного обучения Azure CLI версии 2 (current)Python SDK azure-ai-ml версии 2 (current)
Автоматизируйте эффективную настройку гиперпараметров с помощью пакета SDK версии 2 для Машинного обучения Azure и CLI версии 2 с учетом типа SweepJob.
- Определение пространства поиска параметров для пробного задания
- Указание алгоритма выборки для задания очистки
- Указание цели для оптимизации
- Указание политики досрочного завершения для заданий с низкой результативностью
- Определение границ для заданий очистки
- Запуск эксперимента с использованием заданной конфигурации
- Визуализация заданий обучения
- Выбор наилучшей конфигурации для модели
Что такое настройка гиперпараметров?
Гиперпараметры — это настраиваемые параметры, позволяющие управлять процессом обучения модели. Например, в нейронных сетях вы определяете количество скрытых слоев и количество узлов в каждом слое. Производительность модели в значительной степени зависит от гиперпараметров.
Настройка гиперпараметров, также называемая оптимизацией гиперпараметров, — это процесс поиска конфигурации гиперпараметров, приводящей к лучшей производительности. Этот процесс обычно требует значительных вычислительных ресурсов и выполняется вручную.
Машинное обучение Azure позволяет автоматизировать настройку гиперпараметров и запускать эксперименты в параллельном режиме для эффективной оптимизации гиперпараметров.
Определение пространства поиска
Гиперпараметры настраиваются путем исследования диапазона значений, определенных для каждого из гиперпараметров.
Гиперпараметры могут быть дискретными или непрерывными и иметь распределение значений, описываемое выражением параметра.
Дискретные гиперпараметры
Дискретные гиперпараметры определяются как Choice в дискретных значениях.
Choice может принимать следующие значения:
- одно или несколько значений, разделенных запятыми;
- объект
range; - любой произвольный объект
list.
from azure.ai.ml.sweep import Choice
command_job_for_sweep = command_job(
batch_size=Choice(values=[16, 32, 64, 128]),
number_of_hidden_layers=Choice(values=range(1,5)),
)
В этом случае batch_size принимает значение из списка [16, 32, 64, 128], а number_of_hidden_layers — из списка [1, 2, 3, 4].
Следующие расширенные дискретные гиперпараметры также могут быть заданы с использованием распределения.
-
QUniform(min_value, max_value, q)— возвращает значение типа round(Uniform(min_value, max_value) / q) * q. -
QLogUniform(min_value, max_value, q)— возвращает значение типа round(exp(Uniform(min_value, max_value)) / q) * q. -
QNormal(mu, sigma, q)— возвращает значение типа round(normal(mu, sigma) / q) * q. -
QLogNormal(mu, sigma, q)— возвращает значение типа round(exp(normal(mu, sigma)) / q) * q.
Непрерывные гиперпараметры
Непрерывные гиперпараметры определяются как распределение по непрерывному диапазону значений.
-
Uniform(min_value, max_value)— возвращает значение, равномерно распределенное между min_value и max_value. -
LogUniform(min_value, max_value)— возвращает значение, полученное в соответствии с exp(uniform(min_value, max_value)), так что логарифм возвращаемого значения распределен равномерно. -
Normal(mu, sigma)— возвращает реальное значение, которое обычно распределяется со средним значением mu и стандартным отклонением sigma. -
LogNormal(mu, sigma)— возвращает значение, полученное в соответствии с exp(normal(mu, sigma)), так что логарифм возвращаемого значения нормально распределен.
Ниже приведен пример определения пространства параметров:
from azure.ai.ml.sweep import Normal, Uniform
command_job_for_sweep = command_job(
learning_rate=Normal(mu=10, sigma=3),
keep_probability=Uniform(min_value=0.05, max_value=0.1),
)
Этот код определяет пространство поиска с двумя параметрами: learning_rate и keep_probability.
learning_rate имеет нормальное распределение со средним значением 10 и стандартным отклонением 3.
keep_probability имеет равномерное распределение с минимальным значением 0,05 и максимальным значением 0,1.
Для интерфейса командной строки можно использовать схему YAML задания очистки, чтобы определить пространство поиска в YAML:
search_space:
conv_size:
type: choice
values: [2, 5, 7]
dropout_rate:
type: uniform
min_value: 0.1
max_value: 0.2
Выборка пространства гиперпараметров
Укажите метод выборки параметров для использования в пространстве гиперпараметров. Машинное обучение Azure поддерживает следующие методы.
- Случайная выборка
- Решетчатая выборка
- Байесовская выборка
Случайная выборка
Случайная выборка поддерживает дискретные и непрерывные гиперпараметры. Она поддерживает досрочное завершение заданий с низкой результативностью. Некоторые пользователи выполняют первоначальный поиск с помощью случайной выборки, а затем уточняют область поиска для улучшения результатов.
При случайной выборке значения гиперпараметров выбираются случайным образом из определенного пространства поиска. После создания задания команды можно использовать параметр очистки, чтобы определить алгоритм выборки.
from azure.ai.ml.sweep import Normal, Uniform, RandomParameterSampling
command_job_for_sweep = command_job(
learning_rate=Normal(mu=10, sigma=3),
keep_probability=Uniform(min_value=0.05, max_value=0.1),
batch_size=Choice(values=[16, 32, 64, 128]),
)
sweep_job = command_job_for_sweep.sweep(
compute="cpu-cluster",
sampling_algorithm = "random",
...
)
Соболь
Sobol — это тип случайной выборки, поддерживаемой типами заданий очистки. Вы можете использовать sobol для воспроизведения результатов с помощью начального значения и более равномерного охвата распределения пространства поиска.
Чтобы использовать sobol, воспользуйтесь классом RandomParameterSampling, чтобы добавить начальное значение и правило, как показано в примере ниже.
from azure.ai.ml.sweep import RandomParameterSampling
sweep_job = command_job_for_sweep.sweep(
compute="cpu-cluster",
sampling_algorithm = RandomParameterSampling(seed=123, rule="sobol"),
...
)
Решетчатая выборка
Решетчатая выборка поддерживает дискретные гиперпараметры. Используйте решетчатую выборку, если у вас есть бюджет на исчерпывающий поиск в пространстве поиска. Она поддерживает досрочное завершение заданий с низкой результативностью.
Решетчатая выборка выполняет простой сеточный поиск по всем возможным значениям. Решетчатая выборка может использоваться только с гиперпараметрами choice. Например, следующее пространство имеет шесть выборок:
from azure.ai.ml.sweep import Choice
command_job_for_sweep = command_job(
batch_size=Choice(values=[16, 32]),
number_of_hidden_layers=Choice(values=[1,2,3]),
)
sweep_job = command_job_for_sweep.sweep(
compute="cpu-cluster",
sampling_algorithm = "grid",
...
)
Байесовская выборка
Байесовская выборка строится на байесовском алгоритме оптимизации. Выборка делается на основе того, как работали предыдущие выборки, так что новые выборки улучшают первичную метрику.
Байесовская выборка рекомендуется при наличии достаточного бюджета для изучения пространства гиперпараметров. Для получения наилучших результатов рекомендуется, чтобы максимальное количество заданий было не меньше 20-кратного количества настраиваемых гиперпараметров.
Количество параллельных заданий влияет на эффективность процесса настройки. Меньшее количество параллельных заданий может улучшить сходимость выборки, так как меньшая степень параллелизма увеличивает число заданий, оптимизированных по результатам прошлых заданий.
Байесовская выборка поддерживает в пространстве поиска только распределения choice, uniform и quniform.
from azure.ai.ml.sweep import Uniform, Choice
command_job_for_sweep = command_job(
learning_rate=Uniform(min_value=0.05, max_value=0.1),
batch_size=Choice(values=[16, 32, 64, 128]),
)
sweep_job = command_job_for_sweep.sweep(
compute="cpu-cluster",
sampling_algorithm = "bayesian",
...
)
Указание цели очистки
Определите цель задания очистки, указав основную метрику и цель, которые требуется оптимизировать с помощью настройки гиперпараметров. Для основной метрики оценивается каждое задание обучения. Политика досрочного завершения использует основную метрику для обнаружения заданий с низкой результативностью.
-
primary_metric: имя основной метрики должно точно соответствовать имени метрики, зарегистрированной сценарием обучения. -
goal: это может бытьMaximizeилиMinimize. Это свойство определяет, что будет выполняться при оценке заданий — максимизация или минимизация основной метрики.
from azure.ai.ml.sweep import Uniform, Choice
command_job_for_sweep = command_job(
learning_rate=Uniform(min_value=0.05, max_value=0.1),
batch_size=Choice(values=[16, 32, 64, 128]),
)
sweep_job = command_job_for_sweep.sweep(
compute="cpu-cluster",
sampling_algorithm = "bayesian",
primary_metric="accuracy",
goal="Maximize",
)
Эта выборка увеличивает метрику "accuracy".
Ведение журнала метрик для настройки гиперпараметров
Сценарий обучения для вашей модели должен регистрировать основную метрику во время обучения модели с использованием такого же соответствующего имени метрики, чтобы SweepJob мог получать к ней доступ для настройки гиперпараметров.
Зарегистрируйте основную метрику в сценарии обучения, используя следующий фрагмент кода:
import mlflow
mlflow.log_metric("accuracy", float(val_accuracy))
Сценарий обучения вычисляет val_accuracy и регистрирует его как значение основной метрики "accuracy". Каждый раз при регистрации метрики значение метрики поступает на обработку в службу настройки гиперпараметров. Вы можете определить частоту создания отчетов.
Дополнительные сведения о значениях ведения журнала для заданий обучения см. в разделе "Включение входа в Машинное обучение Azure задания обучения".
Настройка политики досрочного завершения
Автоматически завершайте задания с низкой производительностью с помощью политики досрочного завершения. Досрочное завершение улучшает эффективность вычислений.
Чтобы определить, когда должна применяться политика, можно настроить следующие параметры.
-
evaluation_interval: частота применения политики. Каждый раз, когда сценарий обучения регистрирует основную метрику, это считается одним интервалом. Если дляevaluation_intervalзадано значение 1, политика будет применяться каждый раз, когда сценарий обучения сообщает основную метрику. Еслиevaluation_intervalимеет значение 2, политика будет применяться через раз. Если значение дляevaluation_intervalне указано, по умолчанию используется 0. -
delay_evaluation: задерживает первую оценку политики для определенного количества интервалов. Это необязательный параметр, разрешающий запускать все конфигурации с минимальным количеством интервалов, что позволяет избежать преждевременного завершения заданий обучения. Если этот параметр указан, политика применяет каждое кратное значение evaluation_interval, которое больше или равно delay_evaluation. Если значение дляdelay_evaluationне указано, по умолчанию используется 0.
Машинное обучение Azure поддерживает следующие политики досрочного завершения.
- Политика бандитов
- Политика остановки медиана
- Политика выбора усечения
- Политика прекращения не была завершена
Политика бандитов
Политика Bandit основывается на коэффициенте или величине резервирования и интервале оценки. Политика Bandit завершает задания, когда основная метрика выходит за пределы указанного коэффициента или величины резерва времени для самого успешного задания.
Укажите следующие параметры конфигурации.
slack_factorилиslack_amount— резерв времени, допустимый в отношении задания обучения с лучшими результатами.slack_factorзадает допустимый резерв времени как коэффициент.slack_amountуказывает допустимый резерв времени как абсолютную величину, а не коэффициент.Например, рассмотрим политику Bandit, применяемую с интервалом 10. Предположим, что задание с лучшими результатами с интервалом 10 сообщило основную метрику 0,8 с целью ее максимизации. Если в политике задано значение
slack_factor, равное 0,2, все задания обучения, лучшая метрика которых в интервале 10 меньше 0,66 (0,8/(1+slack_factor)), будут завершены.evaluation_interval(необязательно): частота применения политики.delay_evaluation(необязательно): задерживает первую оценку политики для определенного количества интервалов.
from azure.ai.ml.sweep import BanditPolicy
sweep_job.early_termination = BanditPolicy(slack_factor = 0.1, delay_evaluation = 5, evaluation_interval = 1)
В этом примере политика раннего завершения применяется в каждом интервале, когда указываются метрики, начиная с оценочного интервала 5. Все задания, лучшая метрика которых меньше (1/(1+0,1)) или соответствует 91 % от заданий с лучшими результатами, будут завершены.
Политика остановки медиана
Политика медианной остановки — это политика досрочного завершения, использующая средние показатели основных метрик по всем заданиям. Эта политика вычисляет средние значения среди всех заданий обучения и останавливает задания, значение основной метрики которых хуже медианы средних показателей.
Она принимает следующие параметры конфигурации:
-
evaluation_interval: частота применения политики (необязательный параметр). -
delay_evaluation: задерживает первую оценку политики для определенного количества интервалов (необязательный параметр).
from azure.ai.ml.sweep import MedianStoppingPolicy
sweep_job.early_termination = MedianStoppingPolicy(delay_evaluation = 5, evaluation_interval = 1)
В этом примере политика раннего завершения применяется в каждом интервале, начиная с оценочного интервала 5. Задание останавливается на интервале 5, если его лучшая основная метрика хуже, чем медиана средних показателей за интервалы 1:5 во всех заданиях обучения.
Политика выбора усечения
Политика выбора усечения отменяет в каждом интервале оценки долю заданий (в процентах от общего количества) с наихудшей результативностью. Задания сравниваются с помощью первичной метрики.
Она принимает следующие параметры конфигурации:
-
truncation_percentage— процент заданий с самой низкой результативностью, которые будут завершены в каждом интервале оценки. Укажите целое число от 1 до 99. -
evaluation_interval(необязательно): частота применения политики. -
delay_evaluation(необязательно): задерживает первую оценку политики для определенного количества интервалов. -
exclude_finished_jobs: указывает, следует ли исключать завершенные задания при применении политики.
from azure.ai.ml.sweep import TruncationSelectionPolicy
sweep_job.early_termination = TruncationSelectionPolicy(evaluation_interval=1, truncation_percentage=20, delay_evaluation=5, exclude_finished_jobs=true)
В этом примере политика раннего завершения применяется в каждом интервале, начиная с оценочного интервала 5. Задание завершается в интервале 5, если по результативности в этом интервале оно входит в число 20 % заданий с самой худшей результативностью в интервале 5 и исключены завершенные задания при применении политики.
Без политики завершения (по умолчанию)
Если политика не указана, служба настройки гиперпараметра позволяет выполнять все задания обучения до завершения.
sweep_job.early_termination = None
Выбор политики досрочного завершения
- Если требуется консервативная политика, которая обеспечит экономию без прерывания запланированных заданий, рассмотрите политику медианной остановки со значениями
evaluation_interval1 иdelay_evaluation5. Это консервативные параметры, которые могут обеспечить приблизительно 25%-35 % экономии без потери на первичной метрии (на основе наших данных оценки). - Для более агрессивной экономии используйте политику Bandit с меньшим допустимым резервом времени или политику выбора усечения с большим процентом усечения.
Настройка границ для задания очистки
Обеспечьте управление бюджетом ресурсов, задав границы для задания очистки.
-
max_total_trials— максимальное число пробных заданий. Требуется целое число от 1 до 1000. -
max_concurrent_trials(необязательно) — максимальное количество пробных запусков, которые могут выполняться параллельно. Если это не указано, max_total_trials число заданий запускалось параллельно. Если задано, должно быть целым числом от 1 до 1000. -
timeout: максимальное время в секундах для выполнения всего задания очистки. После достижения этого ограничения система отменяет задание очистки, включая все его пробные версии. -
trial_timeout— максимальное время в секундах, в течение которого разрешено выполнение пробного задания. После достижения этого ограничения система отменяет пробную версию.
Примечание.
Если заданы оба max_total_trials и тайм-аут, эксперимент настройки гиперпараметра завершается при достижении первого из этих двух пороговых значений.
Примечание.
Количество параллельных пробных заданий зависит от ресурсов, доступных в заданном целевом объекте вычисления. Убедитесь, что целевой объект вычислений имеет доступные ресурсы для требуемого уровня параллелизма.
sweep_job.set_limits(max_total_trials=20, max_concurrent_trials=4, timeout=1200)
Этот код настраивает эксперимент по настройке гиперпараметра для использования не более 20 общих заданий пробной версии, выполняя четыре задания пробной версии одновременно с тайм-аутом 1200 секунд для всего задания очистки.
Конфигурация эксперимента по настройке гиперпараметров
Чтобы задать конфигурацию для эксперимента по настройке гиперпараметров, укажите следующее:
- заданное пространство поиска гиперпараметров;
- Ваш алгоритм выборки
- политику досрочного завершения;
- Ваша цель
- Ограничения ресурсов
- CommandJob или CommandComponent
- SweepJob
SweepJob может выполнять очистку гиперпараметров для Command или Command Component.
Примечание.
Целевой объект вычислений, используемый в sweep_job, должен иметь достаточно ресурсов для соответствия вашему уровню параллелизма. Дополнительные сведения о целевых объектах вычислений см. в этой статье.
Конфигурация эксперимента по настройке гиперпараметров:
from azure.ai.ml import MLClient
from azure.ai.ml import command, Input
from azure.ai.ml.sweep import Choice, Uniform, MedianStoppingPolicy
from azure.identity import DefaultAzureCredential
# Create your base command job
command_job = command(
code="./src",
command="python main.py --iris-csv ${{inputs.iris_csv}} --learning-rate ${{inputs.learning_rate}} --boosting ${{inputs.boosting}}",
environment="AzureML-lightgbm-3.2-ubuntu18.04-py37-cpu@latest",
inputs={
"iris_csv": Input(
type="uri_file",
path="https://azuremlexamples.blob.core.windows.net/datasets/iris.csv",
),
"learning_rate": 0.9,
"boosting": "gbdt",
},
compute="cpu-cluster",
)
# Override your inputs with parameter expressions
command_job_for_sweep = command_job(
learning_rate=Uniform(min_value=0.01, max_value=0.9),
boosting=Choice(values=["gbdt", "dart"]),
)
# Call sweep() on your command job to sweep over your parameter expressions
sweep_job = command_job_for_sweep.sweep(
compute="cpu-cluster",
sampling_algorithm="random",
primary_metric="test-multi_logloss",
goal="Minimize",
)
# Specify your experiment details
sweep_job.display_name = "lightgbm-iris-sweep-example"
sweep_job.experiment_name = "lightgbm-iris-sweep-example"
sweep_job.description = "Run a hyperparameter sweep job for LightGBM on Iris dataset."
# Define the limits for this sweep
sweep_job.set_limits(max_total_trials=20, max_concurrent_trials=10, timeout=7200)
# Set early stopping on this one
sweep_job.early_termination = MedianStoppingPolicy(
delay_evaluation=5, evaluation_interval=2
)
command_job вызывается в виде функции, поэтому мы можем применить выражения параметров к входным данным очистки. Функция sweep затем настраивается с trial, sampling-algorithm, objective, limits и compute. Приведенный выше фрагмент кода взят из примера записной книжки Выполнение очистки гиперпараметров для Command или CommandComponent. В этом примере learning_rate настраиваются параметры и boosting параметры. Раннее завершение заданий определяется путем MedianStoppingPolicyостановки задания, основное значение метрики которого хуже медианы средних по всем заданиям обучения.( См . справочник по классу MedianStoppingPolicy).
Сведения о получении, анализе и передаче значений параметров в скрипт обучения для настройки см. в этом примере кода.
Внимание
Каждое задание очистки гиперпараметров перезапускает обучение с нуля, включая перестроение модели и все загрузчики данных. Вы можете сократить эти затраты, используя конвейер Машинного обучения Azure или ручной процесс для максимальной подготовки данных до заданий обучения.
Отправка эксперимента по настройке параметров
После определения конфигурации настройки гиперпараметров отправьте задание:
# submit the sweep
returned_sweep_job = ml_client.create_or_update(sweep_job)
# get a URL for the status of the job
returned_sweep_job.services["Studio"].endpoint
Визуализация заданий настройки гиперпараметров
Вы можете визуализировать все задания настройки гиперпараметров в Студии машинного обучения Azure. Дополнительные сведения о просмотре эксперимента на портале см. в разделе Просмотр записей заданий в студии.
Диаграмма метрик. Эта визуализация отслеживает метрики, зарегистрированные для каждого дочернего задания HyperDrive в ходе настройки гиперпараметров. Каждая линия представляет собой дочернее основной метрики в этой итерации среды выполнения.
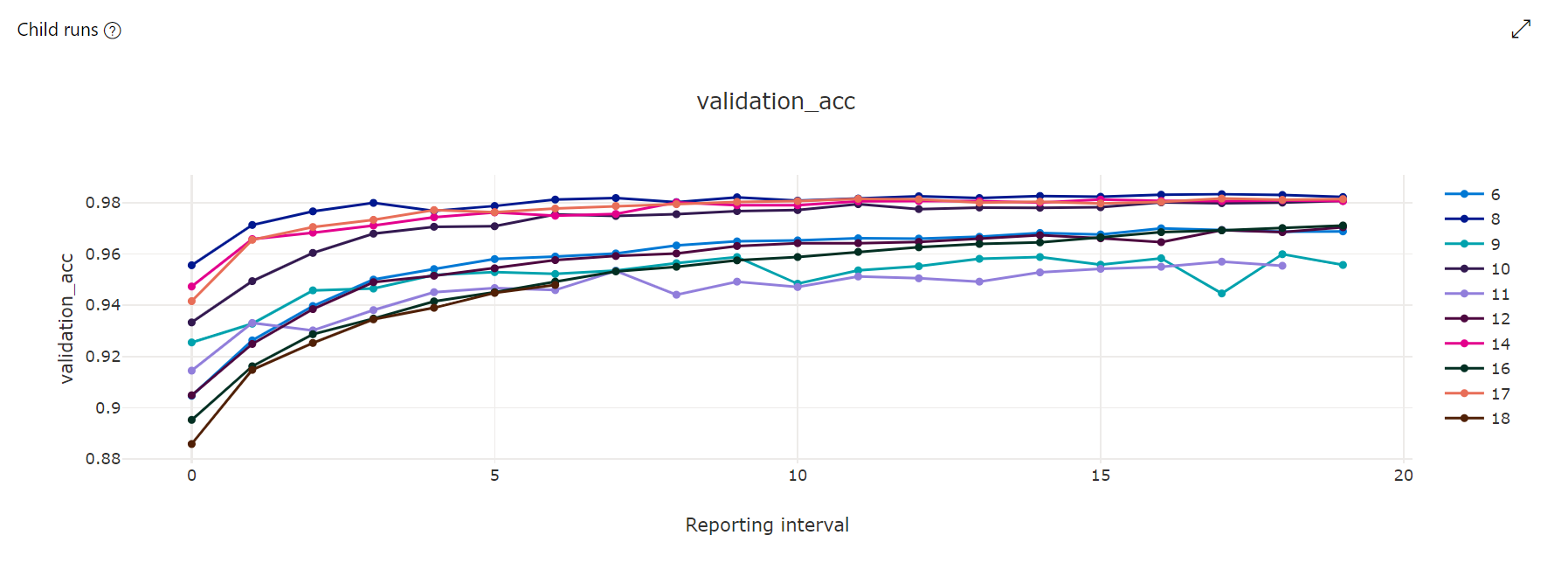
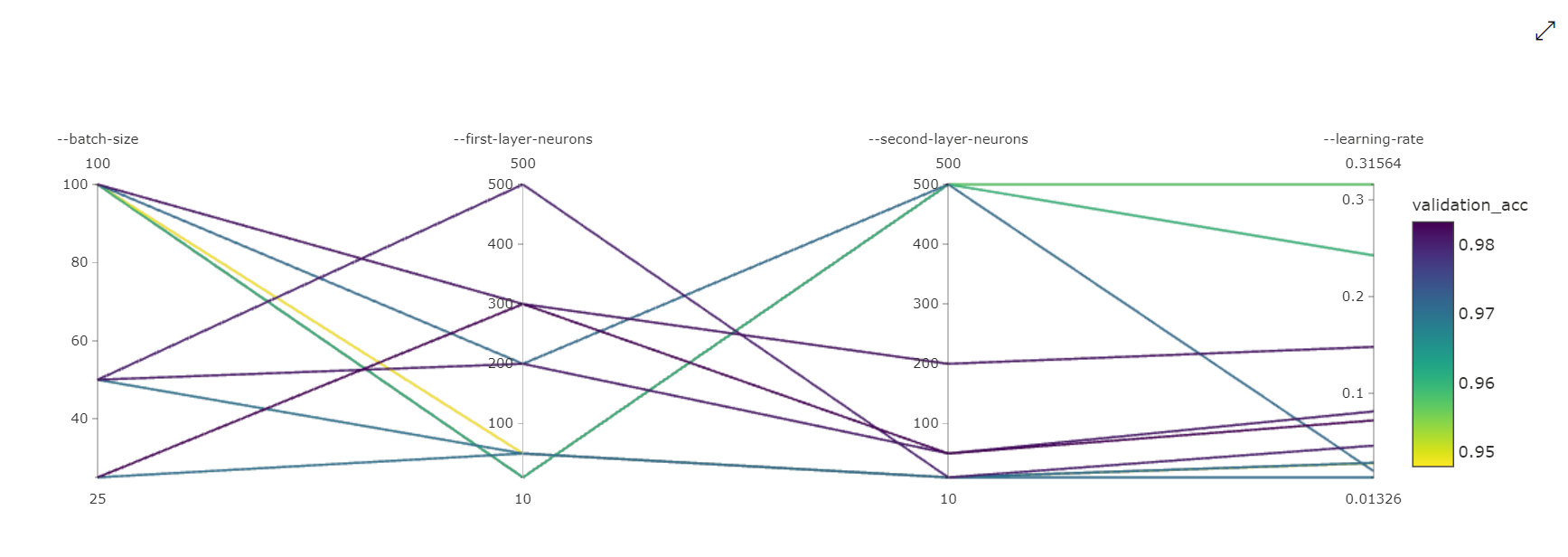
Диаграмма с параллельными координатами. Эта визуализация показывает корреляцию между производительностью основной метрики и значениями отдельных гиперпараметров. Диаграмма является интерактивной с помощью перемещения осей (выбор и перетаскивание меткой оси), а также выделение значений по одной оси (выделение и перетаскивание по вертикали по одной оси для выделения диапазона требуемых значений). Диаграмма параллельных координат включает ось в самой правой части диаграммы, которая отображает лучшее значение метрик, соответствующее гиперпараметрам, заданным для этого экземпляра задания. Эта ось предоставляется для проецирования условных обозначений градиента диаграммы на данные более удобочитаемым образом.
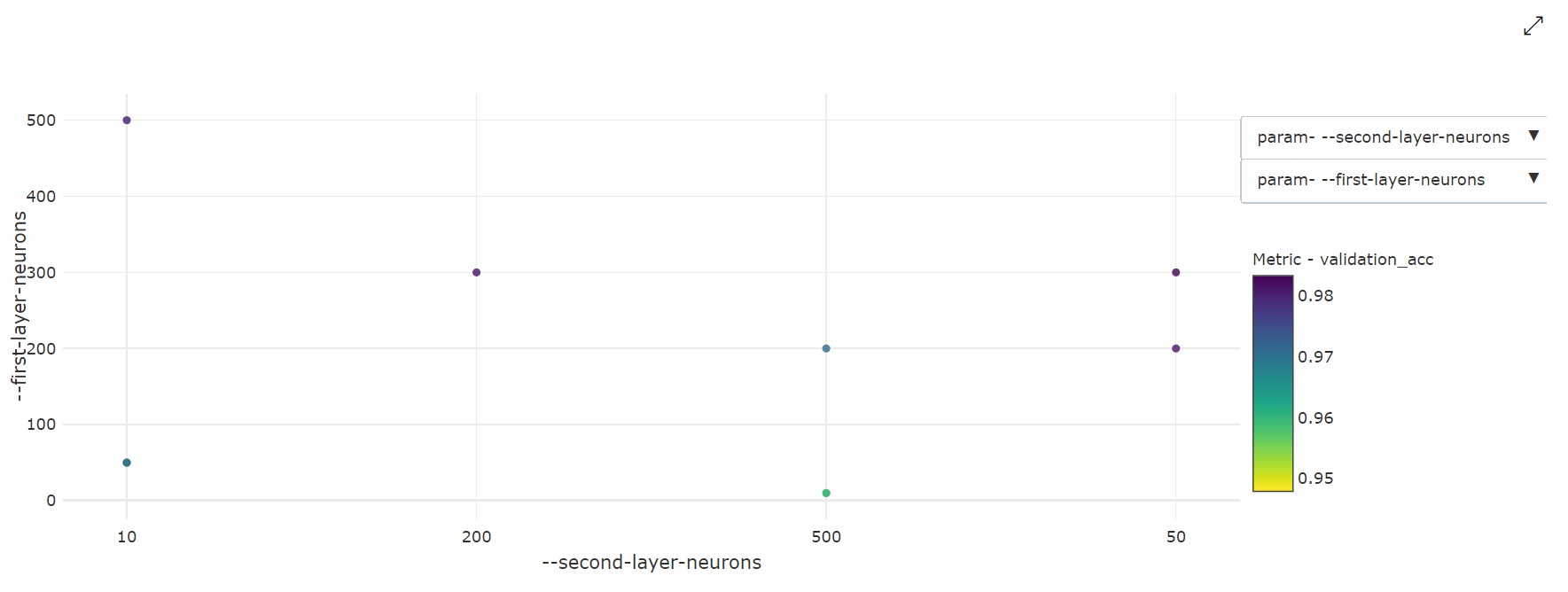
Двумерная точечная диаграмма. Эта визуализация показывает корреляцию между любыми двумя отдельными гиперпараметрами, а также связанное с ними значение первичной метрики.
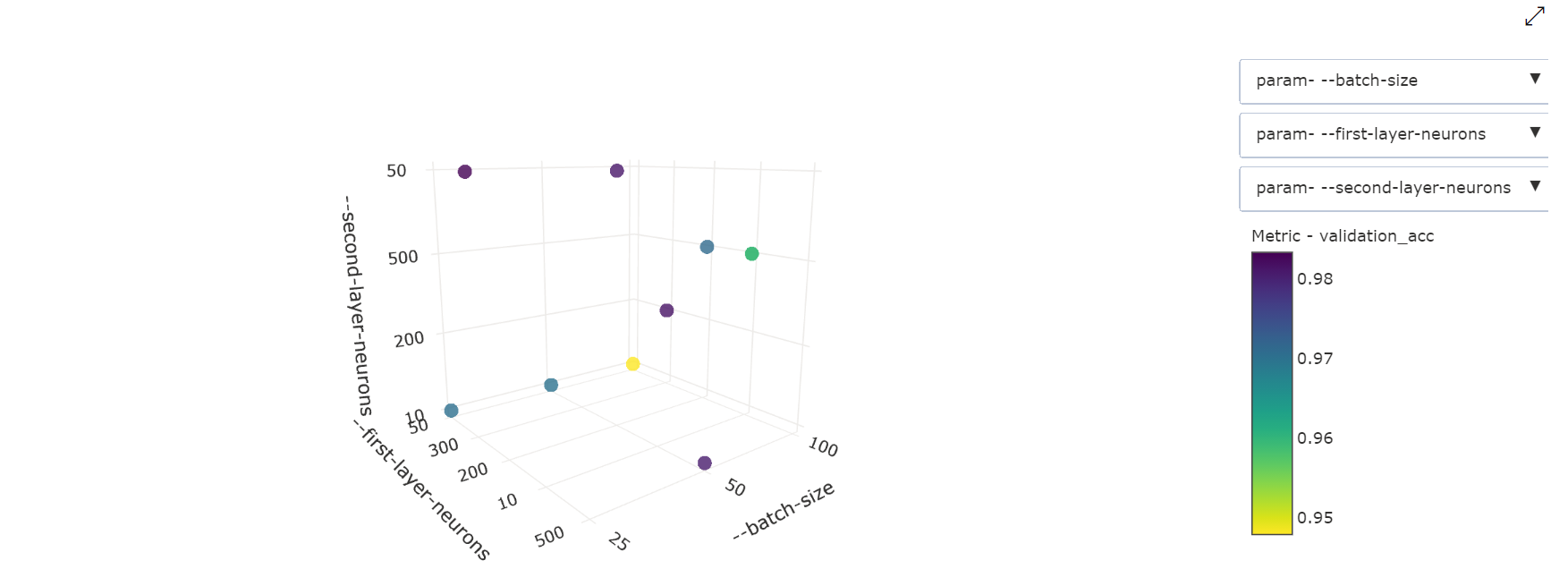
Трехмерная точечная диаграмма. Эта визуализация аналогична двумерной, но на ней можно видеть три измерения корреляции гиперпараметров со значением первичной метрики. Вы также можете выбрать и перетащить диаграмму, чтобы просмотреть различные корреляции в трехмерном пространстве.
Поиск лучшего пробного задания
Завершив все задания настройки гиперпараметров, получите выходные данные лучшего пробного задания:
# Download best trial model output
ml_client.jobs.download(returned_sweep_job.name, output_name="model")
С помощью интерфейса командной строки можно скачать все выходные данные по умолчанию и именованные выходные данные лучшего пробного задания, а также журналы задания очистки.
az ml job download --name <sweep-job> --all
При необходимости можно скачать только выходные данные лучшего пробного задания.
az ml job download --name <sweep-job> --output-name model