Как использовать Apache Spark (на базе Azure Synapse Analytics) в конвейере машинного обучения (не рекомендуется)
ОБЛАСТЬ ПРИМЕНЕНИЯ: Пакет SDK для Python для ML Azure версии 1
Пакет SDK для Python для ML Azure версии 1
Предупреждение
Интеграция Azure Synapse Analytics с Машинное обучение Azure, доступная в пакете SDK для Python версии 1, устарела. Пользователи по-прежнему могут использовать рабочую область Synapse, зарегистрированную в Машинное обучение Azure, в качестве связанной службы. Однако новую рабочую область Synapse больше нельзя зарегистрировать в Машинном обучении Azure в качестве связанной службы. Мы рекомендуем использовать бессерверные вычислительные ресурсы Spark и подключенные пулы Synapse Spark, доступные в CLI версии 2 и пакете SDK Для Python версии 2. Дополнительные сведения см. на странице https://aka.ms/aml-spark.
В этой статье вы узнаете, как использовать пулы Apache Spark, управляемые Azure Synapse Analytics, в качестве целевого объекта вычислений для этапа подготовки данных в конвейере Машинное обучение Azure. Вы узнаете, как один конвейер может использовать вычислительные ресурсы, подходящие для конкретного шага, например подготовку данных или обучение. Вы также узнаете, как данные подготовлены к шагу Spark и как он передается на следующий шаг.
Необходимые компоненты
Создайте рабочую область Машинного обучения Azure для хранения всех ресурсов конвейера.
Подготовьте среду разработки к установке пакета SDK для Машинного обучения Azure или используйте вычислительный экземпляр Машинного обучения Azure с уже установленным пакетом SDK.
Создайте рабочую область Azure Synapse Analytics и пул Apache Spark. Дополнительные сведения см . в кратком руководстве. Создание бессерверного пула Apache Spark с помощью Synapse Studio
Связывание рабочей области Azure Synapse Analytics с рабочей областью машинного обучения Azure
Вы создаете и администрируете пулы Apache Spark в рабочей области Azure Synapse Analytics. Чтобы интегрировать пул Apache Spark с рабочей областью Машинного обучения Azure, необходимо установить связь с рабочей областью Azure Synapse Analytics. Связав рабочую область Машинное обучение Azure и рабочие области Azure Synapse Analytics, вы можете подключить пул Apache Spark с помощью
Пакет SDK для Python, как описано далее
Шаблон Azure Resource Manager (ARM). Дополнительные сведения см . в примере шаблона ARM
- Командную строку можно использовать для выполнения шаблона ARM, добавления связанной службы и присоединения пула Apache Spark к этому примеру кода:
az deployment group create --name --resource-group <rg_name> --template-file "azuredeploy.json" --parameters @"azuredeploy.parameters.json"
Внимание
Чтобы успешно связаться с рабочей областью Synapse, необходимо предоставить роль владельца рабочей области Synapse. Проверьте доступ на портале Azure.
Связанная служба получит управляемое удостоверение, назначаемое системой (SAI), во время создания. Необходимо назначить эту службу ссылок SAI роли администратора Synapse Apache Spark из Synapse Studio, чтобы отправить задание Spark (см. инструкции по управлению назначениями ролей Synapse RBAC в Synapse Studio).
Необходимо также предоставить пользователю рабочей области Машинное обучение Azure роль "Участник" из портал Azure управления ресурсами.
Получение связи между рабочей областью Azure Synapse Analytics и рабочей областью Машинного обучения Azure
В этом коде показано, как получить связанные службы в рабочей области:
from azureml.core import Workspace, LinkedService, SynapseWorkspaceLinkedServiceConfiguration
ws = Workspace.from_config()
for service in LinkedService.list(ws) :
print(f"Service: {service}")
# Retrieve a known linked service
linked_service = LinkedService.get(ws, 'synapselink1')
Во-первых, Workspace.from_config() обращается к рабочей области Машинное обучение Azure с конфигурацией в config.json файле. (Дополнительные сведения см. в разделе Создайте файл конфигурации рабочей области). Затем код выводит все связанные службы, доступные в рабочей области. Наконец, LinkedService.get() извлекает связанную службу с именем 'synapselink1'.
Подключение пула Apache Spark в качестве целевого объекта вычислений для Машинного обучения Azure
Чтобы использовать пул Apache Spark для питания шага в конвейере машинного обучения, необходимо подключить его в качестве ComputeTarget шага конвейера, как показано в этом примере кода:
from azureml.core.compute import SynapseCompute, ComputeTarget
attach_config = SynapseCompute.attach_configuration(
linked_service = linked_service,
type="SynapseSpark",
pool_name="spark01") # This name comes from your Synapse workspace
synapse_compute=ComputeTarget.attach(
workspace=ws,
name='link1-spark01',
attach_configuration=attach_config)
synapse_compute.wait_for_completion()
Код сначала настраивает SynapseCompute. Аргумент linked_service — это объект LinkedService, созданный или полученный на предыдущем шаге. Аргумент type должен представлять собой SynapseSpark. Аргумент pool_name в SynapseCompute.attach_configuration() должен соответствовать существующему пулу в рабочей области Azure Synapse Analytics. Дополнительные сведения о создании пула Apache Spark в рабочей области Azure Synapse Analytics см . в кратком руководстве по созданию бессерверного пула Apache Spark с помощью Synapse Studio. attach_config имеет тип ComputeTargetAttachConfiguration;
После создания конфигурации создайте машинное обучение ComputeTarget , передавая значения Workspace и ComputeTargetAttachConfiguration имена, по которым вы хотите ссылаться на вычисления в рабочей области машинного обучения. ComputeTarget.attach() Вызов является асинхронным, поэтому пример блокируется до завершения вызова.
Создание SynapseSparkStep, использующего связанный пул Apache Spark
Пример записной книжки Задание Spark в пуле Apache Spark определяет простой конвейер машинного обучения. Во-первых, записная книжка определяет этап подготовки данных, на базе определенного synapse_compute на предыдущем шаге. Затем записная книжка определяет шаг обучения, управляемый целевым объектом вычислений, более подходящим для обучения. В примере записной книжки используется база данных выживания Titanic для отображения входных и выходных данных. Он фактически не очищает данные или делает прогнозную модель. Так как этот пример на самом деле не включает обучение, шаг обучения использует недорогой вычислительный ресурс на основе ЦП.
Данные передаются в конвейер машинного обучения через DatasetConsumptionConfig объекты, которые могут содержать табличные данные или наборы файлов. Данные часто приходят из файлов в хранилище BLOB-объектов в хранилище данных рабочей области. В этом примере кода показан типичный код, который создает входные данные для конвейера машинного обучения:
from azureml.core import Dataset
datastore = ws.get_default_datastore()
file_name = 'Titanic.csv'
titanic_tabular_dataset = Dataset.Tabular.from_delimited_files(path=[(datastore, file_name)])
step1_input1 = titanic_tabular_dataset.as_named_input("tabular_input")
# Example only: it wouldn't make sense to duplicate input data, especially one as tabular and the other as files
titanic_file_dataset = Dataset.File.from_files(path=[(datastore, file_name)])
step1_input2 = titanic_file_dataset.as_named_input("file_input").as_hdfs()
В примере кода предполагается, что файл Titanic.csv находится в хранилище BLOB-объектов. В коде показано, как считывать файл как в виде, TabularDataset так и в виде FileDataset. Этот код предназначен только для демонстрационных целей, так как он запутается в дублировании входных данных или интерпретирует один источник данных как ресурс, содержащий таблицу, так и строго как файл.
Внимание
Для использования FileDataset в качестве входных данных требуется azureml-core по крайней мере 1.20.0версия. Это можно указать с Environment помощью класса, как описано далее. По завершении шага можно хранить выходные данные, как показано в этом примере кода:
from azureml.data import HDFSOutputDatasetConfig
step1_output = HDFSOutputDatasetConfig(destination=(datastore,"test")).register_on_complete(name="registered_dataset")
В этом примере datastore кода данные будут храниться в файле с именем test. Данные будут доступны в рабочей области машинного обучения как Datasetимя registered_dataset.
Помимо данных, шаг конвейера может иметь зависимости Python на шаге. Кроме того, отдельные SynapseSparkStep объекты могут указывать точную конфигурацию Azure Synapse Apache Spark. Чтобы показать это, в следующем примере кода указывается, что azureml-core версия пакета должна быть по крайней мере 1.20.0. Как упоминание ранее, это требование для azureml-core пакета необходимо использовать FileDataset в качестве входных данных.
from azureml.core.environment import Environment
from azureml.pipeline.steps import SynapseSparkStep
env = Environment(name="myenv")
env.python.conda_dependencies.add_pip_package("azureml-core>=1.20.0")
step_1 = SynapseSparkStep(name = 'synapse-spark',
file = 'dataprep.py',
source_directory="./code",
inputs=[step1_input1, step1_input2],
outputs=[step1_output],
arguments = ["--tabular_input", step1_input1,
"--file_input", step1_input2,
"--output_dir", step1_output],
compute_target = 'link1-spark01',
driver_memory = "7g",
driver_cores = 4,
executor_memory = "7g",
executor_cores = 2,
num_executors = 1,
environment = env)
Этот код задает один шаг в конвейере Машинное обучение Azure. Значение environment этого кода задает определенную azureml-core версию, и код может добавлять другие зависимости conda или pip по мере необходимости.
Zips SynapseSparkStep и отправляет ./code подкаталог с локального компьютера. Этот каталог создается на вычислительном сервере, а шаг запускает dataprep.py скрипт из этого каталога. На inputs этом outputs этапе рассматриваются step1_input1объекты и step1_input2step1_output объекты, рассмотренные ранее. Самым простым способом доступа к этим значениям в сценарии dataprep.py является их связывание с именованным arguments.
Следующий набор аргументов SynapseSparkStep конструктору управляет Apache Spark. compute_target — это 'link1-spark01', который мы присоединили в качестве целевого объекта вычислений ранее. Другие параметры указывают память и ядра, которые следует использовать.
Пример записной книжки использует этот код для dataprep.py:
import os
import sys
import azureml.core
from pyspark.sql import SparkSession
from azureml.core import Run, Dataset
print(azureml.core.VERSION)
print(os.environ)
import argparse
parser = argparse.ArgumentParser()
parser.add_argument("--tabular_input")
parser.add_argument("--file_input")
parser.add_argument("--output_dir")
args = parser.parse_args()
# use dataset sdk to read tabular dataset
run_context = Run.get_context()
dataset = Dataset.get_by_id(run_context.experiment.workspace,id=args.tabular_input)
sdf = dataset.to_spark_dataframe()
sdf.show()
# use hdfs path to read file dataset
spark= SparkSession.builder.getOrCreate()
sdf = spark.read.option("header", "true").csv(args.file_input)
sdf.show()
sdf.coalesce(1).write\
.option("header", "true")\
.mode("append")\
.csv(args.output_dir)
Этот скрипт подготовки данных не выполняет никаких реальных преобразований данных, но показывает, как извлекать данные, преобразовывать их в кадр данных Spark и как выполнять некоторые основные операции с Apache Spark. Чтобы найти выходные данные в Студия машинного обучения Azure, откройте дочернее задание, выберите вкладку "Выходные данные + журналы" и откройте logs/azureml/driver/stdout файл, как показано на этом снимке экрана:
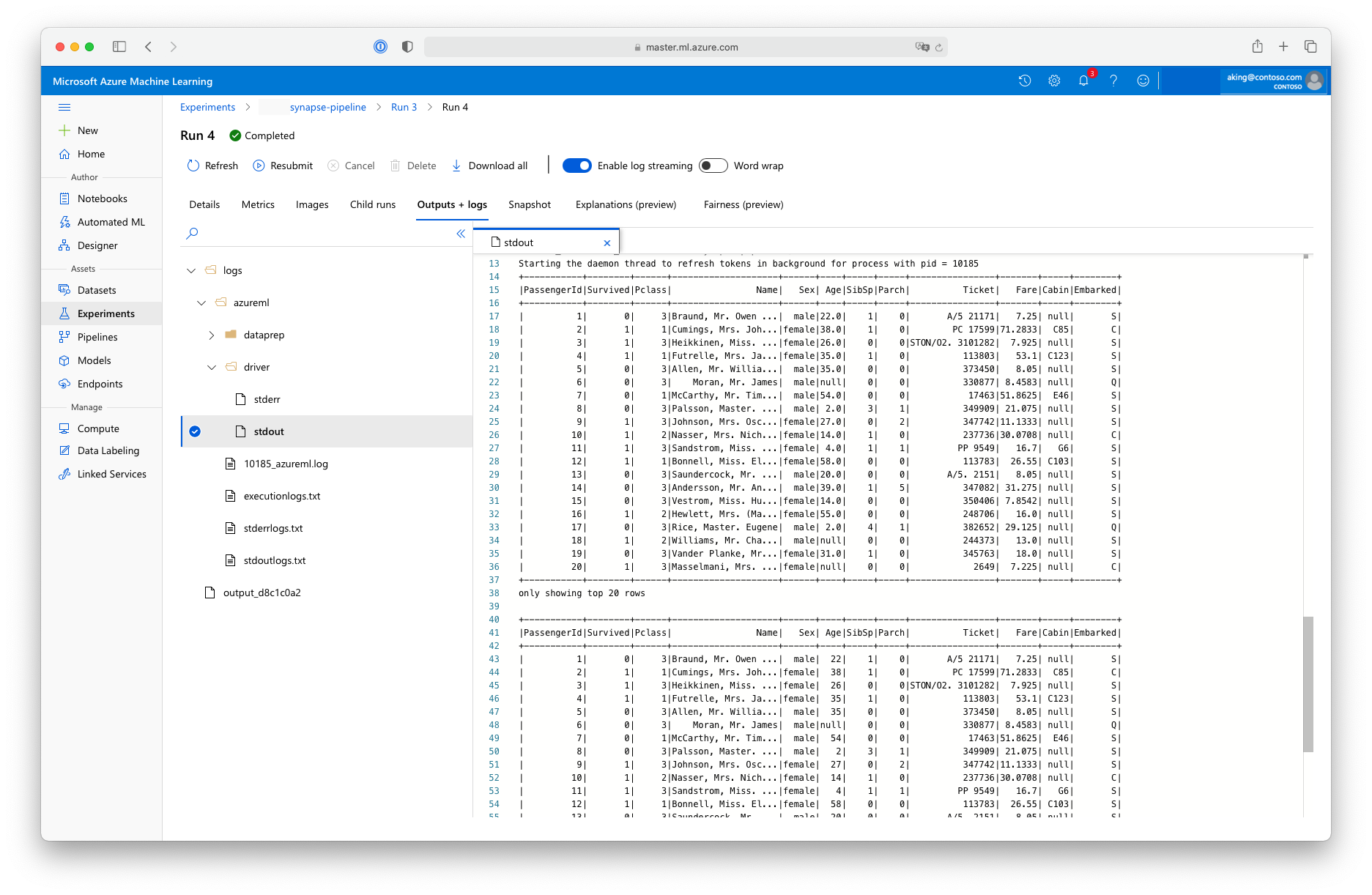
Использование SynapseSparkStep в конвейере
В следующем примере используются выходные данные из созданного SynapseSparkStepв предыдущем разделе. Другие шаги в конвейере могут иметь собственные уникальные среды и могут выполняться на разных вычислительных ресурсах, подходящих для задачи. Пример записной книжки запускает шаг обучения на небольшом кластере ЦП:
from azureml.core.compute import AmlCompute
cpu_cluster_name = "cpucluster"
if cpu_cluster_name in ws.compute_targets:
cpu_cluster = ComputeTarget(workspace=ws, name=cpu_cluster_name)
print('Found existing cluster, use it.')
else:
compute_config = AmlCompute.provisioning_configuration(vm_size='STANDARD_D2_V2', max_nodes=1)
cpu_cluster = ComputeTarget.create(ws, cpu_cluster_name, compute_config)
print('Allocating new CPU compute cluster')
cpu_cluster.wait_for_completion(show_output=True)
step2_input = step1_output.as_input("step2_input").as_download()
step_2 = PythonScriptStep(script_name="train.py",
arguments=[step2_input],
inputs=[step2_input],
compute_target=cpu_cluster_name,
source_directory="./code",
allow_reuse=False)
При необходимости этот код создает новый вычислительный ресурс. Затем он преобразует step1_output результат в входные данные для шага обучения. Этот as_download() параметр означает, что данные перемещаются на вычислительный ресурс, что приводит к более быстрому доступу. Если данные были настолько большими, что они не будут соответствовать локальному жесткому диску вычислений, необходимо использовать as_mount() параметр для потоковой передачи данных с файловой FUSE системой. Параметр compute_target второго шага — 'cpucluster', а не ресурс 'link1-spark01', использованный на этапе подготовки данных. На этом шаге используется простой train.py скрипт, а не dataprep.py скрипт, используемый на предыдущем шаге. Пример записной книжки содержит сведения о скрипте train.py .
После определения всех шагов можно создать и запустить конвейер.
from azureml.pipeline.core import Pipeline
pipeline = Pipeline(workspace=ws, steps=[step_1, step_2])
pipeline_run = pipeline.submit('synapse-pipeline', regenerate_outputs=True)
Этот код создает конвейер, состоящий из этапа подготовки данных в пулах Apache Spark, на основе Azure Synapse Analytics (step_1) и этапа обучения (step_2). Azure проверяет зависимости данных между этапами вычисления графа выполнения. В этом случае существует только одна простая зависимость. step2_input Здесь, обязательно требуетсяstep1_output.
При pipeline.submit необходимости вызов создает именованный synapse-pipelineэксперимент и асинхронно запускает задание в нем. Отдельные шаги в конвейере запускаются в качестве дочерних заданий этого основного задания, а страница "Эксперименты" Студии может отслеживать и просматривать эти действия.