LLMOps с потоком запросов и Azure DevOps
Крупные языковые операции или LLMOps стали краеугольным камнем эффективной разработки запросов и разработки и развертывания приложений LLM. По мере роста спроса на приложения LLM, которые по-прежнему требуются, организации нуждаются в согласованном и упрощенном процессе для управления их комплексным жизненным циклом.
Машинное обучение Azure позволяет интегрироваться с Azure DevOps для автоматизации жизненного цикла разработки приложений с поддержкой LLM с помощью потока запроса.
Машинное обучение Azure поток запросов обеспечивает упрощенный и структурированный подход к разработке приложений, вложенных в LLM. Его четко определенный процесс и жизненный цикл помогут вам создать, протестировать, оптимизировать и развернуть потоки, завершив создание полностью функциональных решений llM-infused.
Функции потока запросов LLMOps
LLMOps с потоком запроса — это шаблон LLMOps и рекомендации, помогающие создавать приложения с поддержкой LLM с помощью потока запросов. Она предоставляет следующие возможности.
Централизованное размещение кода: этот репозиторий поддерживает размещение кода для нескольких потоков на основе потока запроса, предоставляя один репозиторий для всех потоков. Подумайте об этой платформе как об одном репозитории, где находится весь код потока запроса. Это как библиотека для потоков, что упрощает поиск, доступ и совместную работу над различными проектами.
Управление жизненным циклом. Каждый поток пользуется собственным жизненным циклом, что позволяет плавно переходить от локального эксперимента к рабочему развертыванию.
Вариант и гиперпараметр экспериментирование. Экспериментирование с несколькими вариантами и гиперпараметрами, вычисление вариантов потока с легкостью. Варианты и гиперпараметры похожи на ингредиенты в рецепте. Эта платформа позволяет экспериментировать с различными сочетаниями вариантов между несколькими узлами в потоке.
Несколько целевых объектов развертывания: репозиторий поддерживает развертывание потоков в службах приложение Azure, Kubernetes, управляемых Azure вычислительных ресурсах, управляемых с помощью конфигурации, гарантируя, что потоки могут масштабироваться по мере необходимости. Он также создает образы Docker, вложенные в сеанс вычислений Flow, и потоки для развертывания на любой целевой платформе и операционной системе, поддерживающей Docker.
Развертывание A/B: просто реализуйте развертывания A/B, что позволяет легко сравнивать различные версии потока. Как и в традиционном тестировании A/B для веб-сайтов, эта платформа упрощает развертывание A/B для потока запроса. Это означает, что вы можете легко сравнить различные версии потока в реальном мире, чтобы определить, какие результаты лучше всего выполнять.

Связи "многие ко многим" и "многие": вместите несколько наборов данных для каждого стандартного и оценочного потока, обеспечивая гибкость в тестировании и оценке потока. Платформа предназначена для размещения нескольких наборов данных для каждого потока.
Регистрация условных данных и моделей. Платформа создает новую версию для набора данных в Машинное обучение Azure ресурс данных и потоки в реестре моделей, только если в них есть изменения, а не в противном случае.
Комплексные отчеты: создание подробных отчетов для каждой конфигурации варианта, что позволяет принимать обоснованные решения. Предоставляет подробную коллекцию метрик, эксперименты и вариантные массовые запуски для всех запусков и экспериментов, позволяя принимать решения на основе данных в csv-файле, а также HTML-файлы.







Другие функции для настройки:
Предложения BYOF (перенос собственных потоков). Полная платформа для разработки нескольких вариантов использования, связанных с приложениями llM-infused.
Предлагает разработку на основе конфигурации. Нет необходимости писать обширный код плиты.
Обеспечивает выполнение экспериментов и вычислений запросов локально, а также в облаке.
Предоставляет записные книжки для локальной оценки запросов. Предоставляет библиотеку функций для локального эксперимента.
Тестирование конечных точек в конвейере после развертывания для проверка его доступности и готовности.
Предоставляет необязательный цикл "Человек в цикле" для проверки метрик запроса перед развертыванием.
LLMOps с потоком запроса предоставляет возможности для простых, а также сложных приложений LLM-infused. Он полностью настраивается в соответствии с потребностями приложения.
Этапы LLMOps
Жизненный цикл состоит из четырех отдельных этапов:
Инициализация: четко определите бизнес-цель, соберите соответствующие образцы данных, создайте базовую структуру запроса и создайте поток, который улучшает его возможности.
Экспериментирование. Применение потока к образцам данных, оценка производительности запроса и уточнение потока по мере необходимости. Непрерывно итерировать до тех пор, пока не удовлетворены результатами.
Оценка и уточнение: оценка производительности потока с помощью более крупного набора данных, оценка эффективности запроса и соответствующие уточнения. Ход выполнения до следующего этапа, если результаты соответствуют требуемым стандартам.
Развертывание. Оптимизация потока для повышения эффективности и эффективности, развертывание в рабочей среде, включая развертывание A/B, мониторинг производительности, сбор отзывов пользователей и использование этой информации для дальнейшего улучшения потока.
Следуя этой структурированной методологии, поток запросов позволяет уверенно разрабатывать, тщательно тестировать, настраивать и развертывать потоки, что приводит к созданию надежных и сложных приложений ИИ.
Шаблон потока запросов LLMOps формализует эту структурированную методологию с помощью подхода, который позволяет создавать приложения с запросами LLM, используя средства и процессы, относящиеся к потоку запросов. Он предлагает ряд функций, включая централизованное размещение кода, управление жизненным циклом, экспериментирование вариантов и гиперпараметров, развертывание A/B, отчеты обо всех запусках и экспериментах и многое другое.
Репозиторий для этой статьи доступен в LLMOps с шаблоном потока запроса
Поток процессов LLMOps

- Это этап инициализации. Здесь создаются потоки, подготавливаются и курируются данные, а связанные с LLMOps файлы конфигурации обновляются.
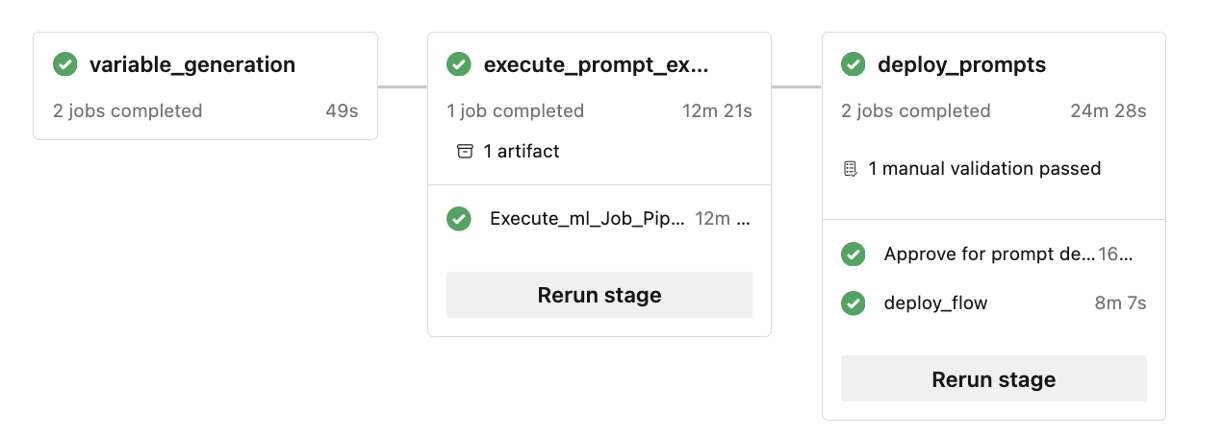
- После локальной разработки с помощью Visual Studio Code вместе с расширением потока запросов запрос на вытягивание создается из ветвь компонента в ветвь разработки. Это приводит к выполнению конвейера проверки сборки. Он также выполняет потоки экспериментирования.
- Pr-запрос утвержден вручную, и код объединяется с ветвью разработки
- После объединения pr в ветвь разработки конвейер CI для среды разработки выполняется. Он выполняет потоки экспериментов и вычислений в последовательности и регистрирует потоки в реестре Машинное обучение Azure отдельно от других шагов в конвейере.
- После завершения выполнения конвейера CI триггер CD обеспечивает выполнение конвейера CD, который развертывает стандартный поток из реестра Машинное обучение Azure в качестве Машинное обучение Azure онлайн-конечной точки и выполняет тесты интеграции и дыма в развернутом потоке.
- Ветвь выпуска создается из ветви разработки или запрос на вытягивание создается из ветви разработки до выпуска ветви.
- Pr-запрос утвержден вручную, и код объединяется с ветвью выпуска. После объединения pr в ветвь выпуска конвейер CI для среды prod выполняется. Он выполняет потоки экспериментов и вычислений в последовательности и регистрирует потоки в реестре Машинное обучение Azure отдельно от других шагов в конвейере.
- После завершения выполнения конвейера CI триггер CD обеспечивает выполнение конвейера CD, который развертывает стандартный поток из реестра Машинное обучение Azure в качестве Машинное обучение Azure онлайн-конечной точки и выполняет тесты интеграции и дыма в развернутом потоке.
Здесь вы можете узнать LLMOps с потоком запроса, следуя приведенным ниже комплексным примерам, которые помогут вам создать приложения с поддержкой LLM с помощью потока запросов и Azure DevOps. Ее основная цель — обеспечить помощь в разработке таких приложений, используя возможности потока запросов и LLMOps.
Совет
Мы рекомендуем понять, как интегрировать LLMOps с потоком запроса.
Внимание
Поток запросов в настоящее время находится в общедоступной предварительной версии. Эта предварительная версия предоставляется без соглашения об уровне обслуживания и не рекомендуется для рабочих нагрузок. Некоторые функции могут не поддерживаться или их возможности могут быть ограничены. Дополнительные сведения см. в статье Дополнительные условия использования Предварительных версий Microsoft Azure.
Необходимые компоненты
- Подписка Azure. Если у вас еще нет подписки Azure, создайте бесплатную учетную запись, прежде чем начинать работу. Попробуйте бесплатную или платную версию Машинного обучения Azure.
- Рабочая область Машинного обучения Azure.
- Git, запущенный на локальном компьютере.
- Организация в Azure DevOps. Организация в Azure DevOps помогает совместно работать, планировать и отслеживать дефекты работы и кода, проблемы и настраивать непрерывную интеграцию и развертывание.
- Расширение Terraform для Azure DevOps , если вы используете Azure DevOps + Terraform для создания инфраструктуры
Примечание.
Требуется Git версии 2.27 или более поздней. Дополнительные сведения об установке команды Git см. в статье https://git-scm.com/downloads и выборе операционной системы.
Внимание
Команды CLI в этой статье были протестированы с помощью Bash. При использовании другой оболочки могут возникнуть ошибки.
Настройка потока запросов
Поток запросов использует ресурс подключений для подключения к конечным точкам, таким как Azure OpenAI, OpenAI или Поиск ИИ Azure, и использует сеанс вычислений для выполнения потоков. Эти ресурсы необходимо создать перед выполнением потоков в потоке запроса.
Настройка подключений для потока запроса
Подключение можно создавать с помощью пользовательского интерфейса портала потока запросов или с помощью REST API. Следуйте рекомендациям по созданию подключений для потока запроса.
Щелкните ссылку, чтобы узнать больше о подключениях.
Примечание.
В примерах потоков для их выполнения необходимо создать подключение "aoai" и подключение с именем aoai.
Настройка субъекта-службы Azure
Субъект-служба Azure — это удостоверение безопасности, которое используются приложениями, службами и средствами автоматизации для доступа к ресурсам Azure. Он представляет приложение или службу, которая должна пройти проверку подлинности с помощью Azure и получить доступ к ресурсам от вашего имени. Следуйте инструкциям по созданию субъекта-службы в Azure.
Этот субъект-служба позже используется для настройки подключения к Службе Azure DevOps и Azure DevOps для проверки подлинности и подключения к службам Azure. Задания, выполняемые в потоке запроса для обоих experiment and evaluation runs , находятся под удостоверением этого субъекта-службы.
Совет
Настройка предоставляет owner разрешения субъекту-службе.
- Это связано с тем, что конвейер CD автоматически предоставляет доступ к недавно подготовленному Машинное обучение Azure доступ к конечной точке Машинное обучение Azure рабочей области для чтения сведений о подключениях.
- Он также добавляет его в Машинное обучение Azure рабочей области, связанной с
getполитикой хранилища ключей иlistразрешениями секрета.
Разрешение владельца можно изменить на contributor уровень разрешений, изменив код YAML конвейера и удалив шаг, связанный с разрешениями.
Настройка Azure DevOps
Существует несколько шагов, которые необходимо предпринять для настройки процесса LLMOps с помощью Azure DevOps.
Создание проекта Azure DevOps
Следуйте рекомендациям по созданию проекта Azure DevOps с помощью пользовательского интерфейса Azure DevOps.
Настройка проверки подлинности между Azure DevOps и Azure
Следуйте инструкциям , чтобы использовать ранее созданный субъект-службу и настроить проверку подлинности между Azure DevOps и Службами Azure.
На этом шаге настраивается новая Подключение службы Azure DevOps, в которой хранятся сведения субъекта-службы. Конвейеры в проекте могут считывать сведения о подключении с помощью имени подключения. Это помогает настроить шаги конвейера Azure DevOps для автоматического подключения к Azure.
Создание группы переменных Azure DevOps
Следуйте рекомендациям по созданию новой группы переменных и добавлению переменной, связанной с Подключение Службой Azure DevOps.
Имя субъекта-службы доступно автоматически в качестве переменной среды для конвейеров.
Настройка репозитория и конвейеров Azure DevOps
В этом репозитории используются две ветви— main и development для продвижения кода и выполнения конвейеров вместо изменений кода в них. Следуйте инструкциям, чтобы настроить собственный локальный, а также удаленный репозиторий использовать код из этого репозитория.
Действия включают клонирование как из репозитория, так main и development branches из репозитория и связывание кода для ссылки на новый репозиторий Azure DevOps. Помимо миграции кода конвейеры — конвейеры pr и разработки настраиваются таким образом, чтобы они выполнялись автоматически на основе триггеров создания и слияния.
Политика ветви для разработки также должна быть настроена для выполнения конвейера PR для любой ветви разработки, поднятой в ветви разработки из ветвь компонента. Конвейер "dev" выполняется при слиянии PR с ветвью разработки. Конвейер dev состоит из этапов CI и CD.
В конвейерах также существует человек, реализованный в цикле . После выполнения этапа CI в dev конвейере этап CD следует после утверждения вручную. Утверждение должно произойти из пользовательского интерфейса выполнения сборки конвейера Azure DevOps. Время ожидания по умолчанию — 60 минут, после чего конвейер будет отклонен, а этап CD не будет выполнен. Утверждение выполнения вручную приведет к выполнению шагов CD конвейера. Утверждение вручную настроено для отправки уведомлений в "replace@youremail.com". Его следует заменить соответствующим идентификатором электронной почты.
Тестирование конвейеров
Следуйте инструкциям, упоминание, чтобы протестировать конвейеры.
Вот что нужно сделать:
- Вызов запроса pr(pull) из ветвь компонента в ветвь разработки.
- Конвейер PR должен выполняться автоматически в результате настройки политики ветви.
- Затем PR объединяется с ветвью разработки.
- Выполняется связанный конвейер dev. Это приведет к полному выполнению CI и CD и приведет к подготовке или обновлению существующих конечных точек Машинное обучение Azure.
Выходные данные теста должны быть похожи на те, которые показаны здесь.
Локальное выполнение
Чтобы использовать возможности локального выполнения, выполните следующие действия.
- Клонируйте репозиторий: начните с клонирования репозитория шаблона из своего репозитория GitHub.
git clone https://github.com/microsoft/llmops-promptflow-template.git
- Настройте env-файл: создайте env-файл на верхнем уровне папки и укажите сведения для элементов, упоминание. Добавьте столько имен подключений, сколько нужно. Все примеры потока в этом репозитории используют подключение AzureOpenAI с именем
aoai. Добавьте строкуaoai={"api_key": "","api_base": "","api_type": "azure","api_version": "2023-03-15-preview"}с обновленными значениями для api_key и api_base. Если в потоках используются дополнительные подключения с разными именами, их следует добавить соответствующим образом. В настоящее время поток с AzureOpenAI в качестве поставщика поддерживается.
experiment_name=
connection_name_1={ "api_key": "","api_base": "","api_type": "azure","api_version": "2023-03-15-preview"}
connection_name_2={ "api_key": "","api_base": "","api_type": "azure","api_version": "2023-03-15-preview"}
- Подготовьте локальную среду conda или виртуальную среду для установки зависимостей.
python -m pip install promptflow promptflow-tools promptflow-sdk jinja2 promptflow[azure] openai promptflow-sdk[builtins] python-dotenv
Введите или напишите потоки в шаблон на основе документации.
Напишите скрипты Python, аналогичные приведенным в приведенных примерах в папке local_execution.
Следующие шаги
Обратная связь
Ожидается в ближайшее время: в течение 2024 года мы постепенно откажемся от GitHub Issues как механизма обратной связи для контента и заменим его новой системой обратной связи. Дополнительные сведения см. в разделе https://aka.ms/ContentUserFeedback.
Отправить и просмотреть отзыв по