Руководство по устранению неполадок
В этой статье рассматриваются часто задаваемые вопросы об использовании потока запроса.
Проблемы, связанные с разработкой потока
Ошибка "Средство пакета не обнаружено" возникает при обновлении потока с моделью code-first
При обновлении потоков для взаимодействия с кодом, если поток использовал подстановку индекса Faiss, векторный индекс поиска, векторный запрос базы данных или средства "Безопасность содержимого" (текст), может возникнуть следующее сообщение об ошибке:
Package tool 'embeddingstore.tool.faiss_index_lookup.search' is not found in the current environment.
Чтобы устранить проблему, у вас есть два варианта:
Вариант 1
Обновите сеанс вычислений до последней версии базового образа.
Выберите режим необработанного файла, чтобы перейти в представление необработанного кода. Затем откройте файл flow.dag.yaml .

Обновите имена инструментов.
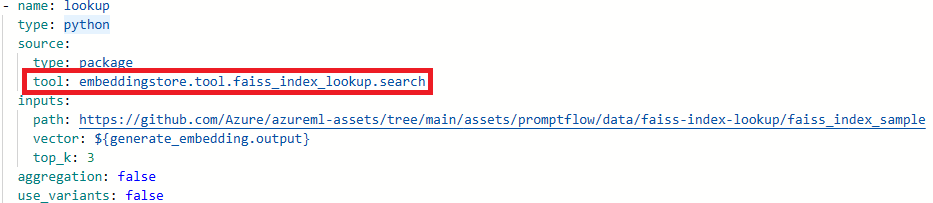
Средство Новое имя средства Поиск индекса Faiss promptflow_vectordb.tool.faiss_index_lookup. FaissIndexLookup.search Поиск векторного индекса promptflow_vectordb.tool.vector_index_lookup. VectorIndexLookup.search Поиск векторной базы данных promptflow_vectordb.tool.vector_db_lookup. VectorDBLookup.search Безопасность контента (текст) content_safety_text.tools.content_safety_text_tool.analyze_text Сохраните файл flow.dag.yaml .
Вариант 2
- Обновление сеанса вычислений до последней версии базового образа
- Удалите старое средство и повторно создайте новое средство.
Ошибка "Нет такого файла или каталога"
Поток запросов использует хранилище общих папок для хранения моментального снимка потока. Если хранилище общей папки имеет проблему, может возникнуть следующая проблема. Ниже приведены некоторые обходные пути, которые можно попробовать:
Если вы используете частную учетную запись хранения, просмотрите поток запросов сетевой изоляции, чтобы убедиться, что рабочая область может получить доступ к учетной записи хранения.
Если учетная запись хранения включена для общедоступного доступа, проверьте, есть ли в рабочей области хранилище
workspaceworkingdirectoryданных. Он должен быть типом общей папки.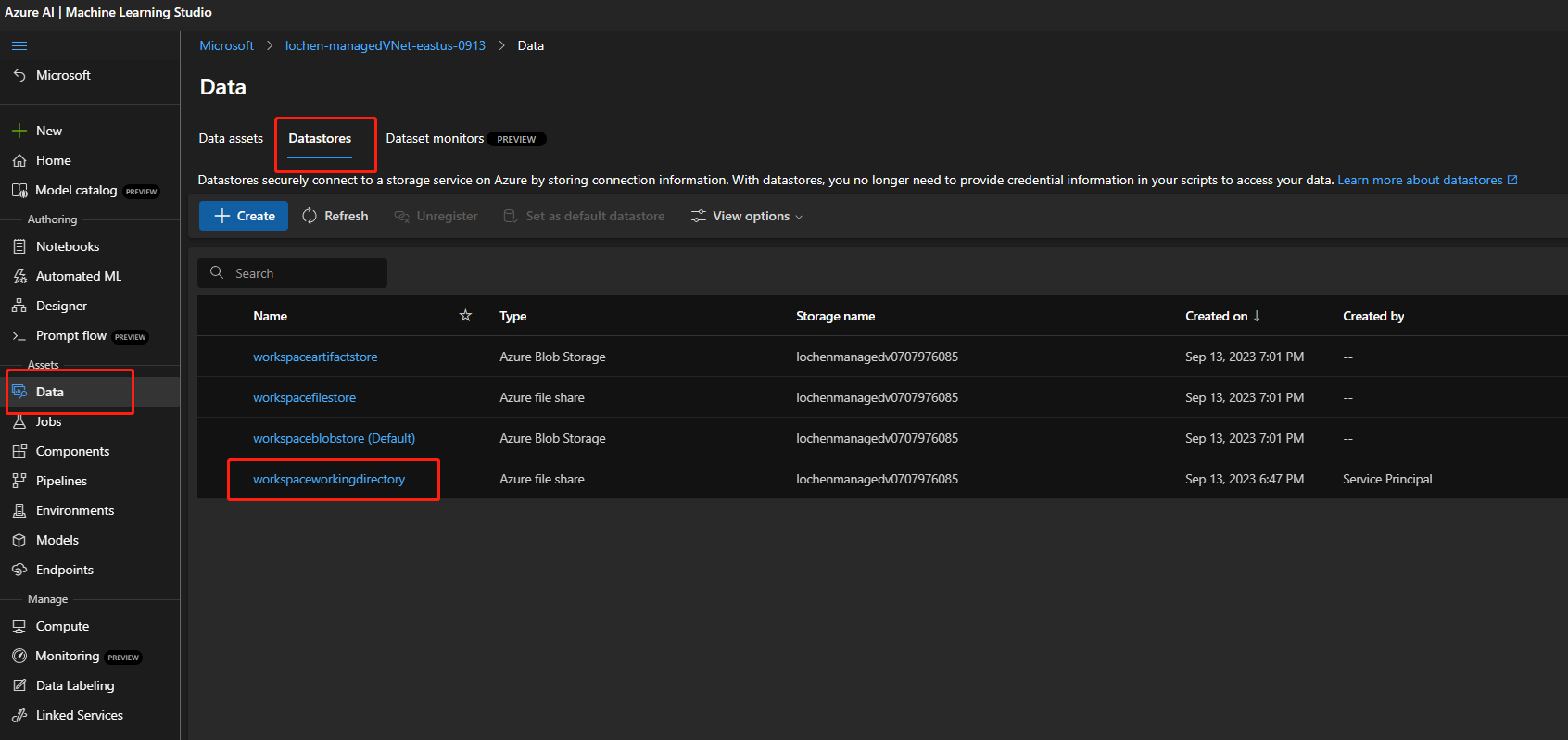
- Если вы не получили это хранилище данных, необходимо добавить его в рабочую область.
- Создайте общую папку с именем
code-391ff5ac-6576-460f-ba4d-7e03433c68b6. - Создайте хранилище данных с именем
workspaceworkingdirectory. См. статью "Создание хранилищ данных".
- Создайте общую папку с именем
- Если у вас есть
workspaceworkingdirectoryхранилище данных, но его тип неfileshareявляетсяblob, создайте новую рабочую область. Используйте хранилище, которое не включает иерархические пространства имен для Azure Data Lake Storage 2-го поколения в качестве учетной записи хранения по умолчанию рабочей области. Дополнительные сведения см. в статье "Создание рабочей области".
- Если вы не получили это хранилище данных, необходимо добавить его в рабочую область.

Поток отсутствует

Существуют возможные причины для этой проблемы:
Если общедоступный доступ к учетной записи хранения отключен, необходимо обеспечить доступ путем добавления IP-адреса в брандмауэр хранилища или включения доступа через виртуальную сеть с частной конечной точкой, подключенной к учетной записи хранения.
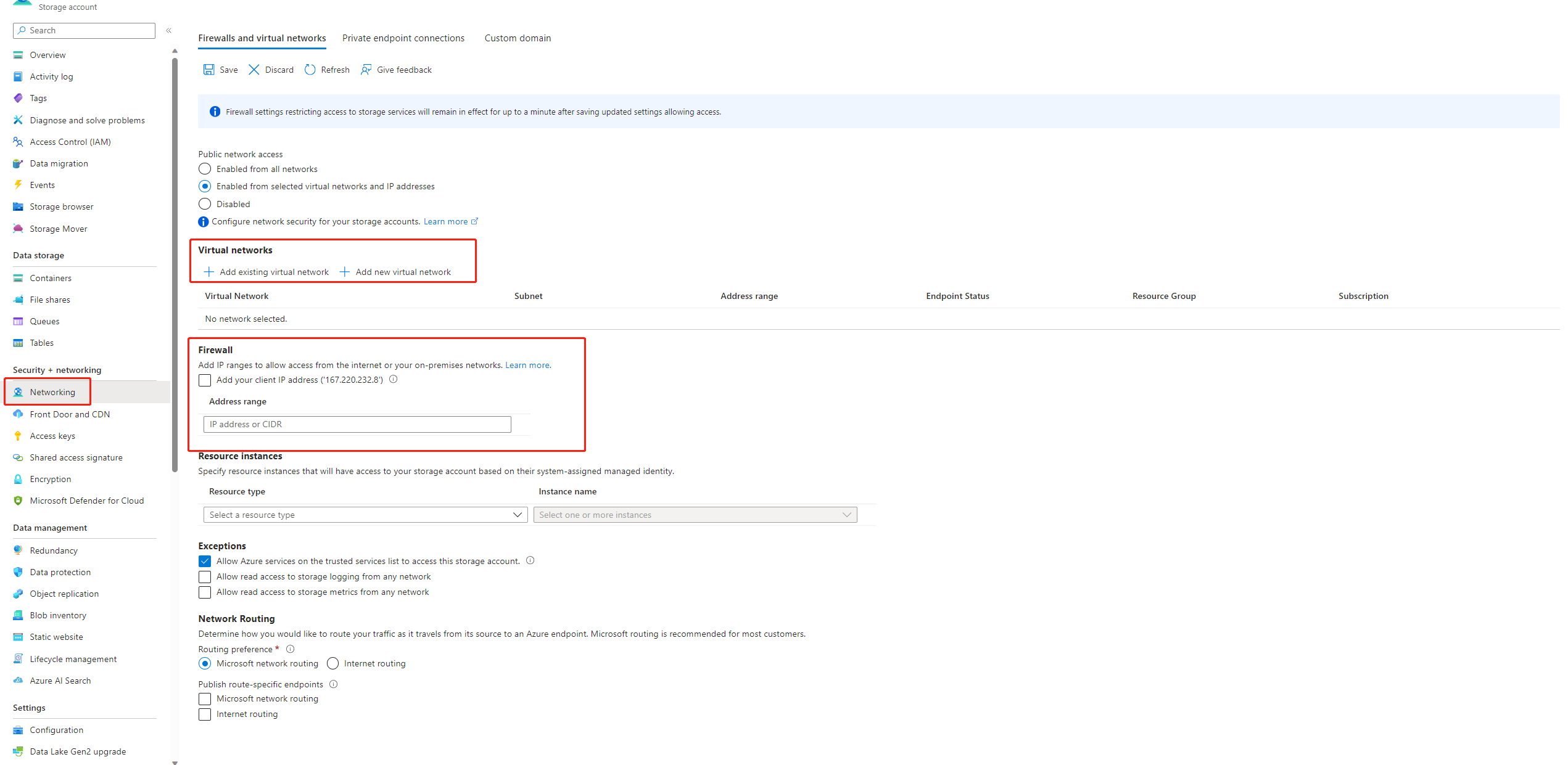
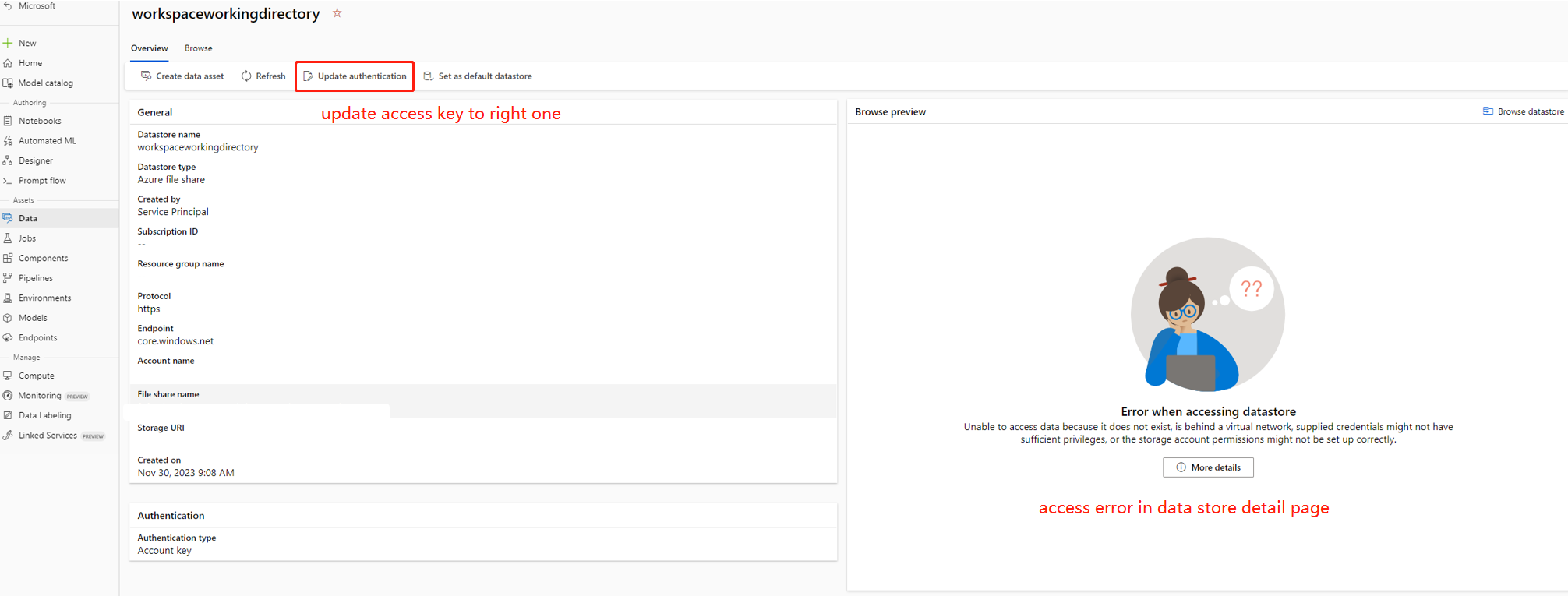
В некоторых случаях ключ учетной записи в хранилище данных не синхронизируется с учетной записью хранения, вы можете попытаться обновить ключ учетной записи на странице сведений о хранилище данных, чтобы устранить эту проблему.
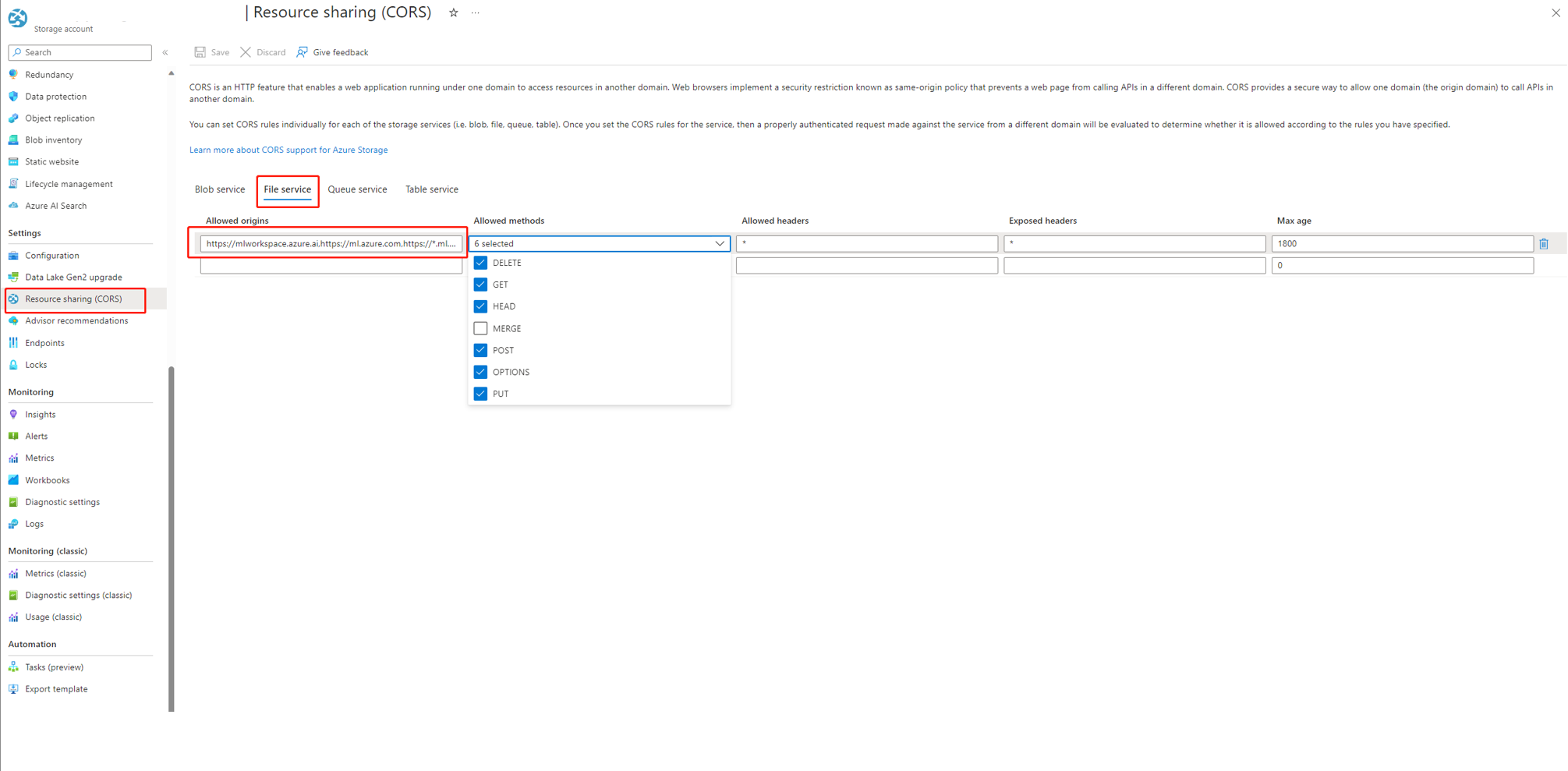
Если вы используете студию искусственного интеллекта, учетная запись хранения должна задать CORS, чтобы разрешить студии ИИ доступ к учетной записи хранения, в противном случае вы увидите отсутствие потока. Чтобы устранить эту проблему, можно добавить следующие параметры CORS в учетную запись хранения.
- Перейдите на страницу учетной записи хранения, выберите
Resource sharing (CORS)в разделеsettingsи выберите вкладкуFile service. - Допустимые источники:
https://mlworkspace.azure.ai,https://ml.azure.com,https://*.ml.azure.com,https://ai.azure.com,https://*.ai.azure.com,https://mlworkspacecanary.azure.ai,https://mlworkspace.azureml-test.net - Разрешенные методы:
DELETE, GET, HEAD, POST, OPTIONS, PUT
- Перейдите на страницу учетной записи хранения, выберите



Проблемы, связанные с сеансом вычислений
Сбой выполнения из-за ошибки "Отсутствует модуль с именем XXX"
Этот тип ошибки, связанной с вычислительным сеансом, не хватает необходимых пакетов. Если вы используете среду по умолчанию, убедитесь, что образ сеанса вычислений использует последнюю версию. Если вы используете пользовательский базовый образ, убедитесь, что установлены все необходимые пакеты в контексте Docker. Дополнительные сведения см. в разделе "Настройка базового образа для сеанса вычислений".
Где найти бессерверный экземпляр, используемый сеансом вычислений?
Вы можете просмотреть бессерверный экземпляр, используемый сеансом вычислений на вкладке списка сеансов вычислений на странице вычислений. Узнайте больше об управлении бессерверным экземпляром.
Сбои сеанса вычислений с использованием пользовательского базового образа
Сбой запуска сеанса вычислений с использованием requirements.txt или пользовательского базового образа
Поддержка сеанса вычислений для использования requirements.txt или пользовательского базового образа для flow.dag.yaml настройки образа. Мы рекомендуем использовать для распространенных случаев, которые будут использоваться requirements.txt pip install -r requirements.txt для установки пакетов. Если у вас больше зависимостей, чем пакеты Python, необходимо выполнить настройку базового образа , чтобы создать новую базу образа на основе потока запроса. Затем используйте его в flow.dag.yaml. Узнайте больше , как указать базовый образ в сеансе вычислений.
- Вы не можете использовать произвольный базовый образ для создания сеанса вычислений, необходимо использовать базовый образ, предоставляемый потоком запроса.
- Не закрепляйте версию
promptflowиpromptflow-toolsвrequirements.txt, так как мы уже включили их в базовый образ. Использование старойpromptflowверсии иpromptflow-toolsможет привести к непредвиденному поведению.
Проблемы, связанные с выполнением потока
Как найти необработанные входные и выходные данные в средстве LLM для дальнейшего изучения?
В потоке запросов на странице потока с успешной страницей выполнения и выполнения подробных сведений можно найти необработанные входные и выходные данные средства LLM в разделе выходных данных. Нажмите кнопку, чтобы просмотреть полные выходные view full output данные.

Trace Раздел содержит каждый запрос и ответ на средство LLM. Вы можете проверить необработанное сообщение, отправленное модели LLM, и необработанный ответ модели LLM.

Как исправить ошибку 409 из Azure OpenAI?
Вы можете столкнуться с ошибкой 409 из Azure OpenAI, это означает, что вы достигли предела скорости Azure OpenAI. Вы можете проверить сообщение об ошибке в выходном разделе узла LLM. Дополнительные сведения об ограничении скорости OpenAI в Azure.

Определение узла, который потребляет больше всего времени
Проверьте журналы сеансов вычислений.
Попробуйте найти следующий формат журнала предупреждений:
{node_name} выполняется в течение {длительности} секунд.
Например:
Случай 1. Узел скрипта Python выполняется в течение длительного времени.

В этом случае можно найти, что
PythonScriptNodeработает в течение длительного времени (почти 300 секунд). Затем можно проверить сведения о узле, чтобы узнать, что такое проблема.Случай 2. Узел LLM выполняется в течение длительного времени.

В этом случае, если вы найдете сообщение
request canceledв журналах, это может быть связано с тем, что вызов API OpenAI занимает слишком много времени и превышает ограничение времени ожидания.Время ожидания API OpenAI может быть вызвано проблемой сети или сложным запросом, требующим больше времени обработки. Дополнительные сведения см. в разделе "Время ожидания API OpenAI".
Подождите несколько секунд и повторите запрос. Обычно это действие устраняет любые проблемы с сетью.
Если повторная попытка не работает, проверьте, используете ли вы длинную модель контекста, например
gpt-4-32k, и задайте для него большое значениеmax_tokens. Если это так, поведение ожидается, так как запрос может создать длинный ответ, который занимает больше верхнего порогового значения интерактивного режима. В этой ситуации рекомендуется попробоватьBulk test, так как этот режим не имеет параметра времени ожидания.
Если вы не можете найти ничего в журналах, чтобы указать, что это конкретная проблема с узлом:
- Обратитесь в группу потоков запроса (promptflow-eng) с журналами. Мы пытаемся определить первопричину.


Проблемы, связанные с развертыванием потока
Отсутствие авторизации для выполнения действия "Microsoft.MachineLearningService/workspaces/datastores/read"
Если поток содержит средство поиска индекса, после развертывания потока конечная точка должна получить доступ к хранилищу данных рабочей области для чтения yaml-файла MLIndex или папки FAISS, содержащей блоки и внедрения. Таким образом, необходимо вручную предоставить удостоверению конечной точки разрешение на это.
Вы можете предоставить удостоверение конечной точки AzureML Специалист по обработке и анализу данных в области рабочей области или пользовательскую роль, содержащую действие MachineLearningService/workspace/datastore/reader.
Проблема времени ожидания вышестоящего запроса при использовании конечной точки
При использовании интерфейса командной строки или пакета SDK для развертывания потока может возникнуть ошибка времени ожидания. По умолчанию request_timeout_ms значение равно 5000. Можно указать не более 5 минут, что составляет 300 000 мс. Ниже показано, как указать время ожидания запроса в yaml-файле развертывания. Дополнительные сведения см . в схеме развертывания.
request_settings:
request_timeout_ms: 300000
Ошибка проверки подлинности в API OpenAI
При повторном создании ключа Azure OpenAI и обновлении подключения, используемого в потоке запросов, могут возникнуть ошибки, такие как "Неавторизованный". Маркер доступа отсутствует, недопустим, аудитория некорректна или истекла". При вызове существующей конечной точки, созданной до повторного создания ключа.
Это связано с тем, что подключения, используемые в конечных точках или развертываниях, не будут автоматически обновляться. Любое изменение ключа или секретов в развертываниях должно выполняться вручную, что позволяет избежать влияния на развертывание в сети из-за непреднамеренной автономной операции.
- Если конечная точка была развернута в пользовательском интерфейсе студии, можно просто развернуть поток в существующую конечную точку с помощью того же имени развертывания.
- Если конечная точка была развернута с помощью пакета SDK или CLI, необходимо внести некоторые изменения в определение развертывания, например добавить фиктивную переменную среды, а затем использовать
az ml online-deployment updateдля обновления развертывания.
Проблемы с уязвимостью при развертывании потоков запросов
Для уязвимостей, связанных с средой выполнения потоков запросов, ниже приведены подходы, которые могут помочь в устранении неполадок.
- Обновите пакеты зависимостей в requirements.txt в папке потока.
- Если вы используете настроенный базовый образ для потока, необходимо обновить среду выполнения потока запроса до последней версии и перестроить базовый образ, а затем повторно развернуть поток.
Для любых других уязвимостей управляемых сетевых развертываний Машинное обучение Azure исправляет проблемы ежемесячно.
"Ошибка MissingDriverProgram" или "Не удалось найти программу драйвера в запросе"
Если вы развернете поток и столкнулись со следующей ошибкой, это может быть связано с средой развертывания.
'error':
{
'code': 'BadRequest',
'message': 'The request is invalid.',
'details':
{'code': 'MissingDriverProgram',
'message': 'Could not find driver program in the request.',
'details': [],
'additionalInfo': []
}
}
Could not find driver program in the request
Эта ошибка устранена двумя способами.
(Рекомендуется) Вы можете найти URI образа контейнера на странице сведений о пользовательской среде и задать его в качестве базового образа потока в файле flow.dag.yaml. При развертывании потока в пользовательском интерфейсе вы просто выбираете среду use current flow definition, а серверная служба создаст настраиваемую среду на основе этого базового образа и
requirement.txtдля развертывания. Дополнительные сведения о среде, указанной в определении потока.
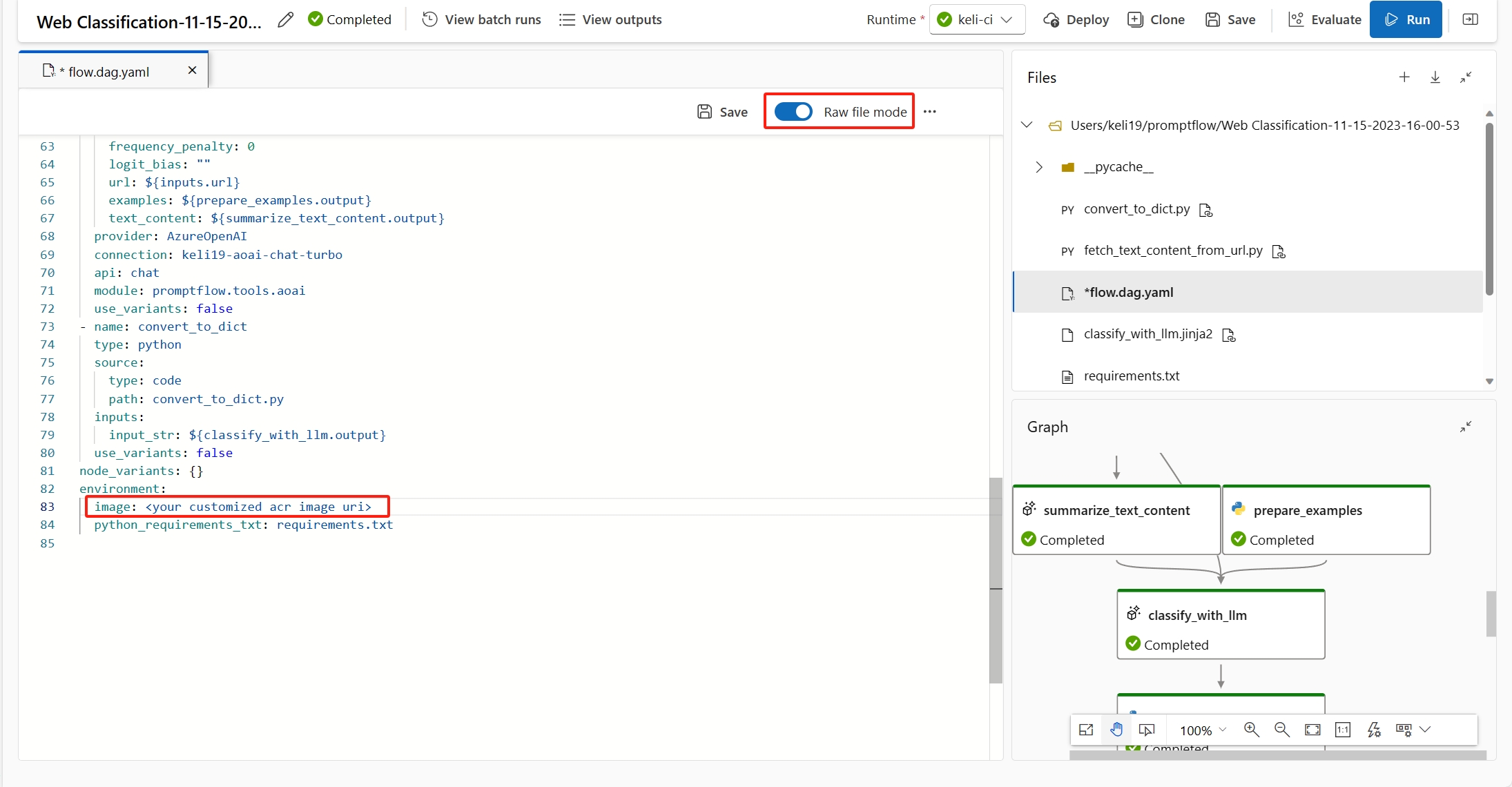
Эту ошибку можно исправить, добавив
inference_configв определение пользовательской среды.Ниже приведен пример настраиваемого определения среды.


$schema: https://azuremlschemas.azureedge.net/latest/environment.schema.json
name: pf-customized-test
build:
path: ./image_build
dockerfile_path: Dockerfile
description: promptflow customized runtime
inference_config:
liveness_route:
port: 8080
path: /health
readiness_route:
port: 8080
path: /health
scoring_route:
port: 8080
path: /score
Слишком долгое время ответа модели
Иногда вы можете заметить, что развертывание занимает слишком много времени для реагирования. Существует несколько потенциальных факторов для этого.
- Модель, используемая в потоке, недостаточно мощна (например, используйте GPT 3.5 вместо text-ada)
- Запрос индекса не оптимизирован и занимает слишком много времени
- Поток имеет много шагов для обработки
Рекомендуется оптимизировать конечную точку с приведенными выше рекомендациями, чтобы повысить производительность модели.
Не удалось получить схему развертывания
После развертывания конечной точки и хотите проверить ее на вкладке "Тест" на странице сведений о конечной точке, если на вкладке "Тест" отображается схема развертывания", можно попробовать следующие два метода, чтобы устранить эту проблему:

- Убедитесь, что вы предоставили правильное разрешение для удостоверения конечной точки. Узнайте больше о том, как предоставить разрешение для удостоверения конечной точки.
- Это может быть связано с тем, что вы запустили поток в старой среде выполнения версии, а затем развернули поток, развертывание использовало среду выполнения, которая была в старой версии, а также. Чтобы обновить среду выполнения, выполните обновление среды выполнения в пользовательском интерфейсе и повторно запустите поток в последней среде выполнения, а затем снова разверните поток.
Доступ запрещен для перечисления секрета рабочей области
Если вы столкнулись с ошибкой, например "Доступ отказано в списке секретов рабочей области", проверьте, предоставили ли вам правильное разрешение на удостоверение конечной точки. Узнайте больше о том, как предоставить разрешение для удостоверения конечной точки.
Проблемы с проверкой подлинности и удостоверениями
Разделы справки использовать хранилище данных без учетных данных в потоке запросов?
Изменение типа проверки подлинности хранилища данных на None
Вы можете следовать проверке подлинности данных на основе удостоверений , чтобы сделать хранилище данных менее учетными данными.
Необходимо изменить тип проверки подлинности хранилища данных на None, который соответствует meid_token проверке подлинности. Вы можете внести изменения на страницу сведений о хранилище данных или cli/SDK: https://github.com/Azure/azureml-examples/tree/main/cli/resources/datastore

Для хранилища данных на основе BLOB-объектов можно изменить тип проверки подлинности, а также включить MSI рабочей области для доступа к учетной записи хранения.

Для хранилища данных на основе общей папки можно изменить только тип проверки подлинности.

Предоставление разрешения на удостоверение пользователя или управляемое удостоверение
Чтобы использовать хранилище данных без учетных данных в потоке запросов, необходимо предоставить достаточно разрешений для удостоверения пользователя или управляемого удостоверения для доступа к хранилищу данных.
- Убедитесь, что у управляемого удостоверения
Storage Blob Data Contributor, назначаемого системой рабочей области, иStorage File Data Privileged Contributorв учетной записи хранения, по крайней мере требуется разрешение на чтение и запись (лучше также включить удаление). - Если вы используете удостоверение пользователя по умолчанию в потоке запросов, необходимо убедиться, что удостоверение пользователя имеет следующую роль в учетной записи хранения:
Storage Blob Data Contributorв учетной записи хранения по крайней мере требуется разрешение на чтение и запись (лучше также включить удаление).Storage File Data Privileged Contributorв учетной записи хранения по крайней мере требуется разрешение на чтение и запись (лучше также включить удаление).
- Если вы используете управляемое удостоверение, назначаемое пользователем, необходимо убедиться, что управляемое удостоверение имеет следующую роль в учетной записи хранения:
Storage Blob Data Contributorв учетной записи хранения по крайней мере требуется разрешение на чтение и запись (лучше также включить удаление).Storage File Data Privileged Contributorв учетной записи хранения по крайней мере требуется разрешение на чтение и запись (лучше также включить удаление).- Между тем необходимо назначить роль удостоверения
Storage Blob Data Readпользователя учетной записи хранения по крайней мере, если вы хотите использовать поток запросов для разработки и тестирования.
- Если вы по-прежнему не можете просматривать страницу сведений о потоке потока потоков и при первом использовании потока запроса раньше 2024-01-01, необходимо предоставить MSI рабочей области как
Storage Table Data Contributorучетной записи хранения, связанной с рабочей областью.
Обратная связь
Ожидается в ближайшее время: в течение 2024 года мы постепенно откажемся от GitHub Issues как механизма обратной связи для контента и заменим его новой системой обратной связи. Дополнительные сведения см. в разделе https://aka.ms/ContentUserFeedback.
Отправить и просмотреть отзыв по