Примеры конвейеров и наборов данных для конструктора Машинного обучения Azure
Используйте встроенные примеры в конструкторе Машинного обучения Azure, чтобы быстро приступить к созданию собственных конвейеров машинного обучения. Репозиторий GitHub конструктора Машинного обучения Azure содержит подробную документацию, которая поможет вам разобраться в ряде самых распространенных сценариев машинного обучения.
Необходимые компоненты
- Подписка Azure. Если у вас еще нет подписки Azure, создайте бесплатную учетную запись.
- Рабочая область Машинного обучения Azure
Важно!
Если вы не видите графические элементы, упомянутые в этом документе, такие как кнопки в студии или конструкторе, возможно, у вас нет соответствующих разрешений для рабочей области. Обратитесь к администратору подписки Azure, чтобы убедиться, что вам предоставлен правильный уровень доступа. Дополнительные сведения см. в статье Управление доступом к рабочей области Машинного обучения Azure.
Использование примеров конвейеров
Конструктор сохраняет копию примеров конвейеров в рабочей области студии. Вы можете изменить конвейер, адаптировав его к своим потребностям, и сохранить его как собственный. Используйте эти примеры в качестве отправной точки для быстрого запуска проектов.
Вот как использовать пример для конструктора:
Войдите на сайт ml.azure.com и выберите рабочую область, с которой хотите работать.
Выберите Конструктор.
Выберите пример конвейера в разделе Новый конвейер.
Выберите Show more samples (Показать другие примеры), чтобы получить полный список примеров.
Чтобы запустить конвейер, сначала задайте целевой объект вычислений по умолчанию, для которого нужно запустить этот конвейер.
В области Параметры справа от холста щелкните Выберите целевой объект вычислений.
В появившемся диалоговом окне выберите существующий целевой объект вычислений или создайте новый. Выберите Сохранить.
Выберите элемент Отправить в верхней части холста, чтобы отправить задание конвейера.
Время выполнения задания зависит от примера конвейера и параметров вычислений. В параметрах вычислений по умолчанию минимальный размер узла равен 0. Это означает, что конструктор должен выделить ресурсы после простоя. Последующие выполнения задания конвейера займут меньше времени, так как ресурсы вычислений уже будут выделены. Кроме того, конструктор использует кэшированные результаты для каждого компонента, чтобы повысить эффективность.
После выполнения конвейера его можно проверить, а также просмотреть выходные данные для каждого компонента, чтобы получить дополнительные сведения. Чтобы просмотреть выходные данные компонентов:
- На холсте щелкните правой кнопкой мыши компонент, выходные данные которого вы хотите просмотреть.
- Выберите Визуализировать.
Используйте примеры в качестве отправных точек для ряда распространенных сценариев машинного обучения.
Регрессия
Ознакомьтесь с этими встроенными примерами регрессии.
| Пример заголовка | Description |
|---|---|
| Регрессия — прогнозирование цен на автомобили (базовый вариант) | Прогнозирование цен на автомобиль с помощью линейной регрессии. |
| Регрессия — прогнозирование цен на автомобили (расширенный вариант) | Прогнозирование цен на автомобили с помощью леса принятия решений и регрессивных деревьев принятия решений. Сравните модели, чтобы найти оптимальный алгоритм. |
Классификация
Ознакомьтесь с этими встроенными примерами классификации. Дополнительные сведения о примерах можно получить, открыв в конструкторе сам пример и просмотрев комментарии к компонентам.
| Пример заголовка | Description |
|---|---|
| Двоичная классификация с выбором компонентов: прогнозирование дохода | Прогнозирование дохода как высокого или низкого с помощью двуклассового увеличивающегося дерева принятия решений. Для выбора компонентов используется корреляция Пирсона. |
| Двоичная классификация с помощью пользовательского скрипта Python: прогнозирование кредитных рисков | Классификация кредитных заявок как высоко- или низкорисковых. Для взвешивания данных используется компонент "Выполнение скриптов Python". |
| Двоичная классификация: прогнозирование отношений с клиентами | Прогнозирование оттока клиентов с помощью двуклассовых увеличивающихся деревьев принятия решений. Для выборки смещенных данных используется SMOTE. |
| Классификация текста — набор данных SP 500 из Википедии | Классификация типов компании из статей Википедии с помощью многоклассовой логистической регрессии. |
| Многоклассовая классификация — распознавание букв | Создание ансамблей двоичных классификаторов для классификации записанных букв. |
Компьютерное зрение
Ознакомьтесь с этими встроенными примерами компьютерного зрения. Дополнительные сведения о примерах можно получить, открыв в конструкторе сам пример и просмотрев комментарии к компонентам.
| Пример заголовка | Description |
|---|---|
| Классификация изображений с помощью DenseNet | Используйте компоненты компьютерного зрения для создания модели классификации изображений на основе PyTorch DenseNet. |
Рекомендатель
Ознакомьтесь с этими встроенными примерами системы рекомендаций. Дополнительные сведения о примерах можно получить, открыв в конструкторе сам пример и просмотрев комментарии к компонентам.
| Пример заголовка | Description |
|---|---|
| Расширенная рекомендация — прогнозирование рейтинга ресторана | Создайте рекомендуемую подсистему ресторана на основе пользовательских функций и оценок. |
| Рекомендация — твиты по рейтингу фильмов | Создание системы для рекомендации фильмов на основе параметров и рейтинга фильмов и пользователей. |
Utility
Узнайте больше о примерах, демонстрирующих возможности служебных программ и функций машинного обучения. Дополнительные сведения о примерах можно получить, открыв в конструкторе сам пример и просмотрев комментарии к компонентам.
| Пример заголовка | Description |
|---|---|
| Двоичная классификация с использованием модели Vowpal Wabbit — прогнозирование дохода совершеннолетних лиц | Vowpal Wabbit — это система машинного обучения, которая расширяет границы машинного обучения с помощью таких методов, как онлайн-обучение, хэширование, общее сокращение, сокращение, обучение поиску, активное и интерактивное обучение. В этом примере показано, как использовать модель Vowpal Wabbit для построения модели двоичной классификации. |
| Использование пользовательского скрипта R — прогнозирование задержки рейсов | Используйте настраиваемый скрипт R, чтобы предсказать, составляет ли задержка запланированного пассажирского рейса более 15 минут. |
| Перекрестная проверка для двоичной классификации — прогнозирование дохода совершеннолетних лиц | Использование перекрестной проверки для создания двоичных классификаторов доходов совершеннолетних лиц. |
| Значение функции перестановки | Использование важности признака перестановки для вычисления оценки важности с точки зрения тестового набора данных. |
| Параметры настройки для двоичной классификации — прогнозирование дохода совершеннолетних лиц | Использование гиперпараметров модели настройки для поиска оптимальных гиперпараметров создания двоичного классификатора. |
Наборы данных
При создании конвейера в конструкторе Машинного обучения Azure по умолчанию в него добавляется ряд примеров наборов данных. Эти примеры наборов данных используются в примерах конвейеров на домашней странице конструктора.
Примеры наборов данных доступны в категории Наборы данных-Примеры. Вы можете найти его в палитре компонентов слева от холста в конструкторе. Любой из этих наборов данных можно использовать в собственном конвейере, перетащив его на холст.
| Имя набора данных | Описание набора данных |
|---|---|
| набор данных Adult Census Income Binary Classification; | Подмножество данных из базы данных переписи 1994 года с информацией о работающих взрослых старше 16 лет с индексом скорректированного дохода > 100. Использование: классификация людей на основе демографических данных для прогнозирования, зарабатывает ли человек более 50 000 в год. Связанные исследования: Kohavi, R., Becker, B. (1996 г.). Репозиторий машинного обучения UCI. Ирвин, Калифорния: Калифорнийский Университет, школа информационных и компьютерных наук |
| Данные о ценах на автомобили (необработанные) | Информация об автомобилях по изготовителю и модели, включая цену, особенности, например, число цилиндров и MPG, а также оценки страховых рисков. Оценка риска изначально связывается с ценой автомобиля. Затем производится корректировка с учетом фактического риска. Актуарии именуют этот процесс symboling. Значение "+3" указывает, что автомобиль является опасным, а значение "-3" — что, вероятно, он безопасен. Использование: прогнозирование оценки рисков с учетом особенностей с помощью регрессионной или многомерной классификации. Связанное исследование: Schlimmer, J.C. (1987). Репозиторий машинного обучения UCI. Ирвин: Калифорнийский университет, школа информационных и компьютерных наук. |
| Общие метки стремления CRM | Метки с KDD Cup 2009 — конкурс прогнозистов, использующих программы взаимоотношения с клиентами (orange_small_train_appetency.labels). |
| Общие метки оттока CRM | Метки с KDD Cup 2009 — конкурс прогнозистов, использующих программы взаимоотношения с клиентами (orange_small_train_churn.labels). |
| Общий набор данных CRM | Эти данные взяты с KDD Cup 2009 — конкурса прогнозистов, использующих программы взаимоотношения с клиентами (orange_small_train.data.zip). Набор данных включает в себя сведения о 50 000 клиентов французской телекоммуникационной компании Orange. У каждого клиента есть 230 обезличенных характеристик, из которых 190 — числовые, а 40 — категорийные. Характеристики являются очень разреженными. |
| Общие метки увеличения суммы покупок CRM | Метки с KDD Cup 2009 — конкурс прогнозистов, использующих программы взаимоотношения с клиентами (orange_large_train_upselling.labels). |
| Данные о задержках рейсов | Данные о производительности пассажира, полученные из сбора данных TranStats Министерства транспорта США (по времени). Набор данных охватывает период времени с апреля по октябрь 2013 г. Перед отправкой в конструктор набор данных был обработан следующим образом: - Набор данных был отфильтрован, чтобы охватывать только 70 самых загруженных аэропортов в континентальной части США - Отмененные рейсы были помечены как отложенные более чем на 15 минут - Отфильтрованные рейсы были отфильтрованы — Были выбраны следующие столбцы: Year, Month, DayofMonth, DayOfWeek, Carrier, OriginAirportID, DestAirportID, CRSDepTime, DepDelay, DepDel15, CRSArrTime, ArrDelay, ArrDel15, Canceled |
| Набор данных German Credit Card UCI | Набор данных журнала регистрации статистики UCI (German Credit Card) (Statlog+German+Credit+Data) с использованием файла german.data. Набор данных классифицирует людей, описываемых набором атрибутов, как заемщиков с низким или высоким уровнем риска. Каждый пример представляет собой физическое лицо. Имеется 20 показателей, как числовых, так и категорийных, и двоичная метка (уровень кредитного риска). Записи с высоким уровнем риска имеют метку со значением 2, записи с низким уровнем риска имеют метку со значением 1. Стоимость ошибочной классификации низкого уровня риска как высокого — 1, а стоимость ошибочной классификации высокого уровня риска как низкого — 5. |
| Названия фильмов на сайте IMDB | Набор данных содержит сведения о фильмах, оцененных в твитах Twitter: идентификатор фильма IMDB, название и жанр фильма, год выхода. В наборе данных содержится 17 тыс. фильмов. Набор данных был представлен в документе S. Dooms, T. De Pessemier and L. Martens. MovieTweetings: a Movie Rating Dataset Collected From Twitter. Workshop on Crowdsourcing and Human Computation for Recommender Systems, CrowdRec at RecSys 2013." |
| Рейтинг фильма | Набор данных является расширенной версией набора данных Movie Tweeting. Набор данных содержит 170 тыс. оценок фильмов, извлеченных из хорошо структурированных твитов в Twitter. Каждый экземпляр представляет собой твит и является кортежем: идентификатор пользователя, идентификатор фильма IMDB, оценка, метка времени, число добавлений в избранное для твита и число ретвитов. Набор данных предоставлен A. Said, S. Dooms, B. Loni и D. Tikk для Recommender Systems Challenge 2014. |
| Набор погодных данных | Результаты ежечасных наземных наблюдений за погодой от NOAA (объединенные данные от 04.2013 г. до 10.2013 г.). Данные представляют собой наблюдения за погодой, осуществленные с метеорологических станций аэропортов, которые охватывают период времени с апреля по октябрь 2013 г. Перед отправкой в конструктор набор данных был обработан следующим образом: - Идентификаторы метеостанции были сопоставлены с соответствующими идентификаторами аэропорта - Метеостанции, не связанные с 70 самыми загруженными аэропортами, были отфильтрованы — Столбец "Дата" разделен на отдельные столбцы "Год", "Месяц" и "День" — Были выбраны следующие столбцы: AirportID, Year, Month, Day, Time, TimeZone, SkyCondition, Видимость, WeatherType, DryBulbFarenheit, DryBulbCelsius, WetBulbFarenheit, WetBulbCelsius, DewPointFarenheit, DewPointCelsius, RelativeHumidity, WindSpeed, WindDirection, ValueForWindCharacter, StationPressure, PressureTendency, PressureChange, SeaLevelPressure, RecordType, HourlyPrecip, Altimeter |
| набор данных Wikipedia SP 500 | Данные взяты из Википедии (https://www.wikipedia.org/) и основаны на статьях о каждой из компаний, включенной в фондовый индекс S&P 500. Они сохранены в формате XML. Перед отправкой в конструктор набор данных был обработан следующим образом: — Извлечение текстового содержимого для каждой конкретной компании — удаление форматирования вики-сайта — удаление небуквенно-цифровых символов — Преобразование всего текста в строчные регистры — Добавлены известные категории компаний Обратите внимание, что удалось найти статьи не для всех компаний, поэтому число записей меньше, чем 500. |
| Данные об услугах ресторанов | Набор метаданных о ресторанах и их услугах, например о типе пищи, стиле ресторанов и местоположении. Использование: этот набор данных в комбинации с другими двумя наборами данных о ресторанах применяется для обучения и тестирования системы рекомендаций. Связанные исследования: Баче, К. и Личман, М. (2013). Репозиторий машинного обучения UCI. Ирвин: Калифорнийский университет, школа информационных и компьютерных наук. |
| Оценки ресторанов | Содержит оценки, данные ресторанам пользователями по шкале от 0 до 2. Использование: этот набор данных в комбинации с другими двумя наборами данных о ресторанах применяется для обучения и тестирования системы рекомендаций. Связанные исследования: Баче, К. и Личман, М. (2013). Репозиторий машинного обучения UCI. Ирвин: Калифорнийский университет, школа информационных и компьютерных наук. |
| Данные о клиентах ресторанов | Набор метаданных о клиентах, включая демографические сведения и предпочтения. Использование: этот набор данных в комбинации с другими двумя наборами данных о ресторанах применяется для обучения и тестирования системы рекомендаций. Связанные исследования: Баче, К. и Личман, М. (2013). UCI Машинное обучение репозиторий Irvine, CA: Университет Калифорнии, школа информационной и компьютерной науки. |
Очистка ресурсов
Важно!
Созданные ресурсы можно использовать в качестве необходимых компонентов для других учебников и статей с практическими рекомендациями по Машинному обучению Azure.
Удаление всех ресурсов
Если вы не планируете использовать созданные ресурсы, удалите всю группу ресурсов, чтобы с вас не взималась плата.
На портале Azure слева выберите Группы ресурсов.
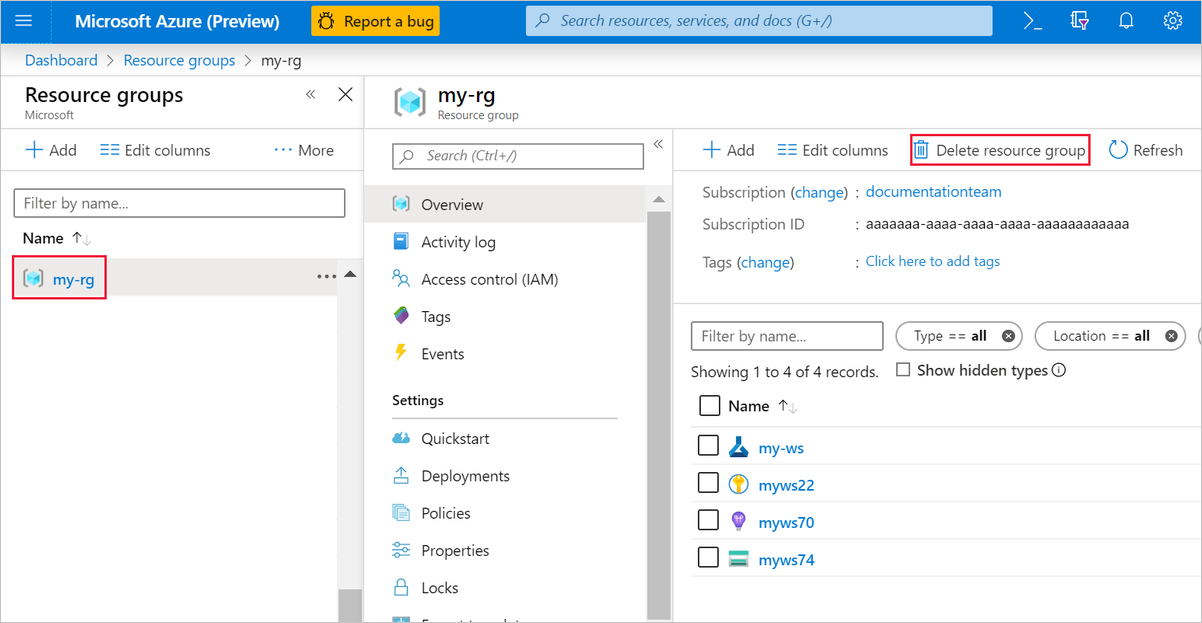
В списке выберите созданную группу ресурсов.
Выберите команду Удалить группу ресурсов.
При удалении группы ресурсов будут также удалены все ресурсы, созданные в конструкторе.
Удаление отдельных ресурсов
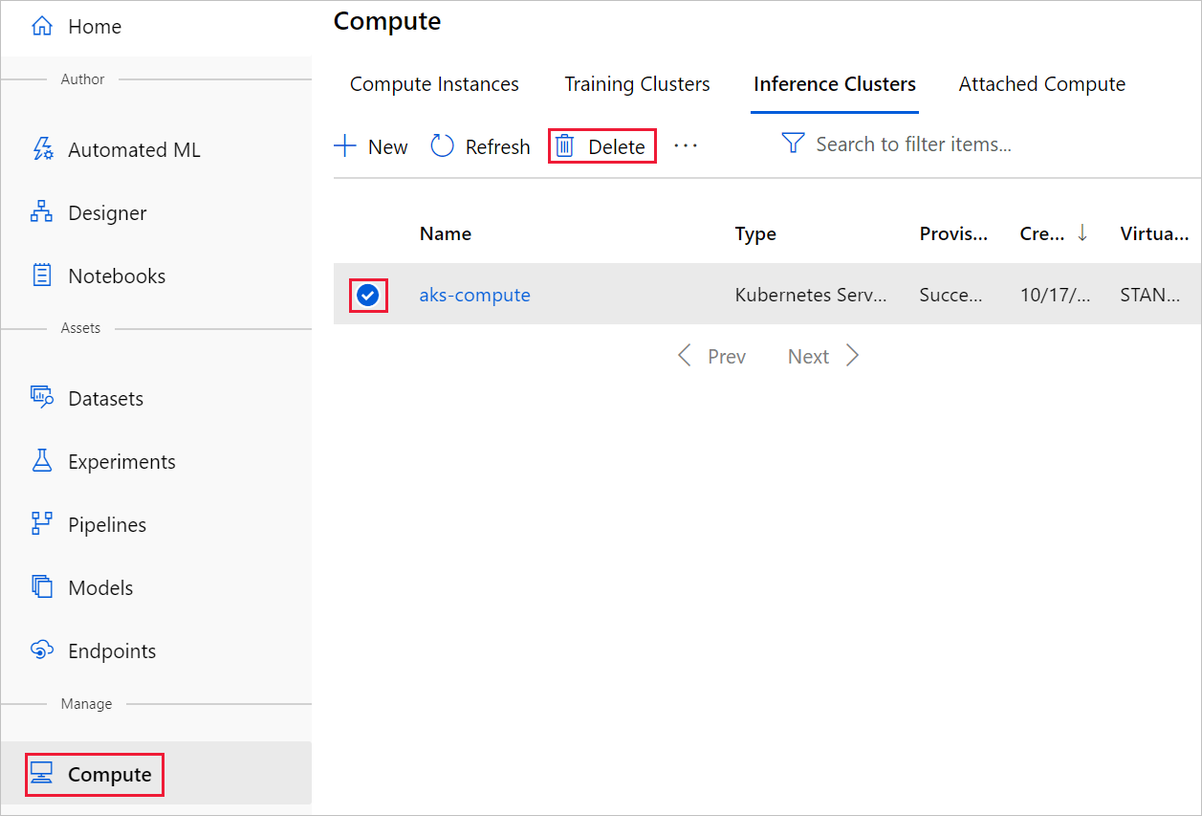
В конструкторе, в котором вы создали эксперимент, удалите отдельные ресурсы, выбрав их и нажав кнопку Удалить.
Созданный вами целевой объект вычислений автоматически масштабируется до нуля узлов, когда он не используется. Это действие предпринимается для снижения расходов. Чтобы удалить целевой объект вычислений, сделайте следующее:
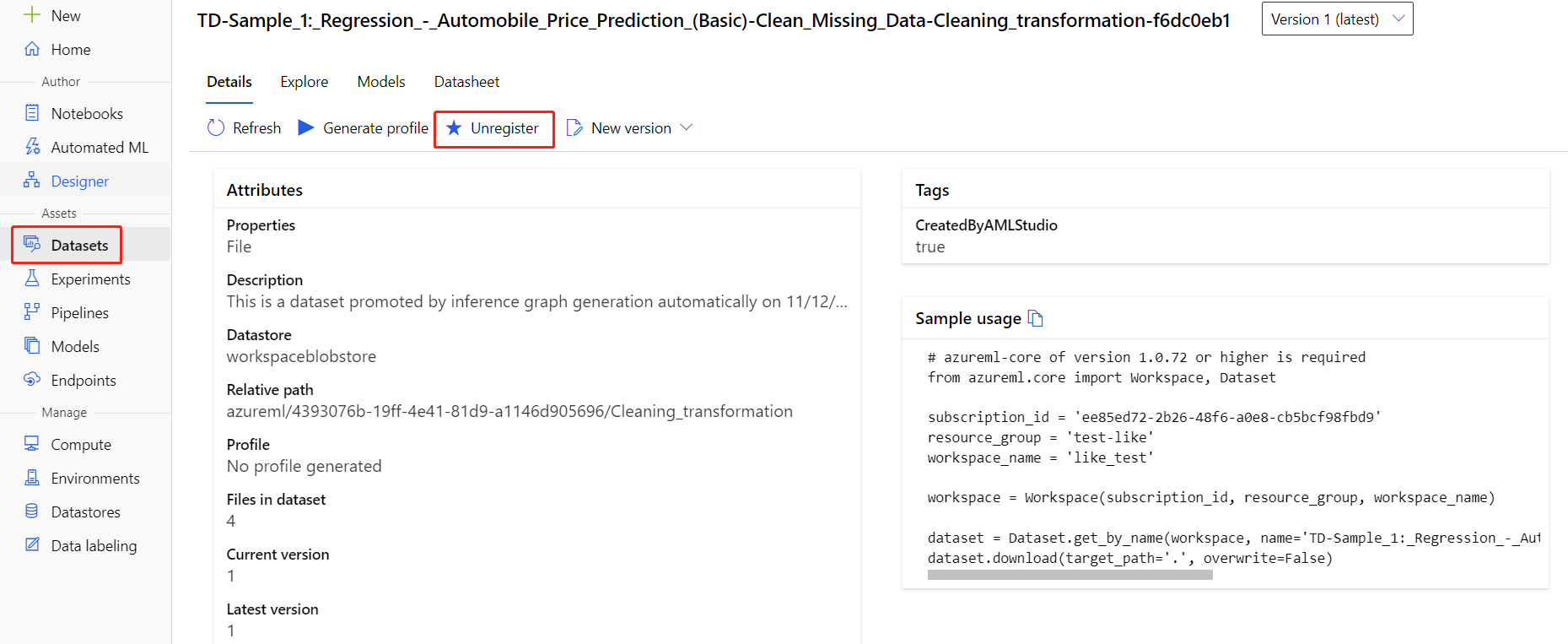
Вы можете отменить регистрацию наборов данных в рабочей области. Для этого выберите каждый набор данных и щелкните Отменить регистрацию.
Чтобы удалить набор данных, перейдите к учетной записи хранения на портале Azure или в приложении "Обозреватель службы хранилища Azure", а затем вручную удалите эти ресурсы.
Следующие шаги
Основы прогнозной аналитики и машинного обучения с помощью учебника. Прогнозирование цены на автомобили с помощью конструктора