Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Служба "Управляемый экземпляр Azure для Apache Cassandra" позволяет автоматизировать операции развертывания и масштабирования для управляемых решений Apache Cassandra с открытым кодом для центров обработки данных. Эта функция ускоряет гибридные сценарии и помогает сократить текущее обслуживание.
В этом кратком руководстве показано, как с помощью портала Azure создать полностью управляемый кластер Apache Spark в виртуальной сети Azure управляемого экземпляра Azure для кластера Apache Cassandra. Вы создаете кластер Spark в Azure Databricks. Позже вы можете создавать или присоединять записные книжки к кластеру, считывать данные из разных источников данных и анализировать аналитические сведения.
Дополнительные сведения см. в статье "Развертывание Azure Databricks" в виртуальной сети Azure (внедрение виртуальной сети).
Необходимые компоненты
Если у вас нет подписки Azure, создайте бесплатную учетную запись, прежде чем приступить к работе.
Создание кластера Azure Databricks.
Выполните следующие действия, чтобы создать кластер Azure Databricks в виртуальной сети с управляемым экземпляром Azure для Apache Cassandra:
Войдите на портал Azure.
На левой панели найдите группы ресурсов. Перейдите в группу ресурсов, содержащую виртуальную сеть, где развернут управляемый экземпляр базы данных.
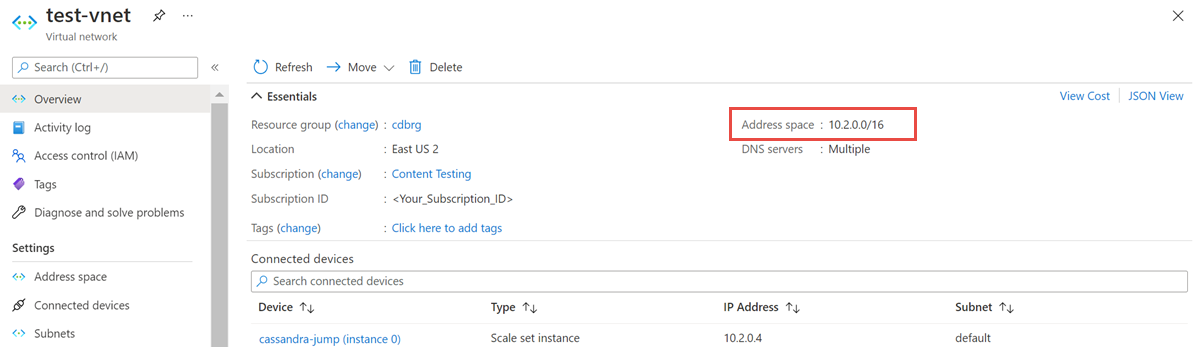
Откройте ресурс виртуальной сети и запишите адресное пространство.
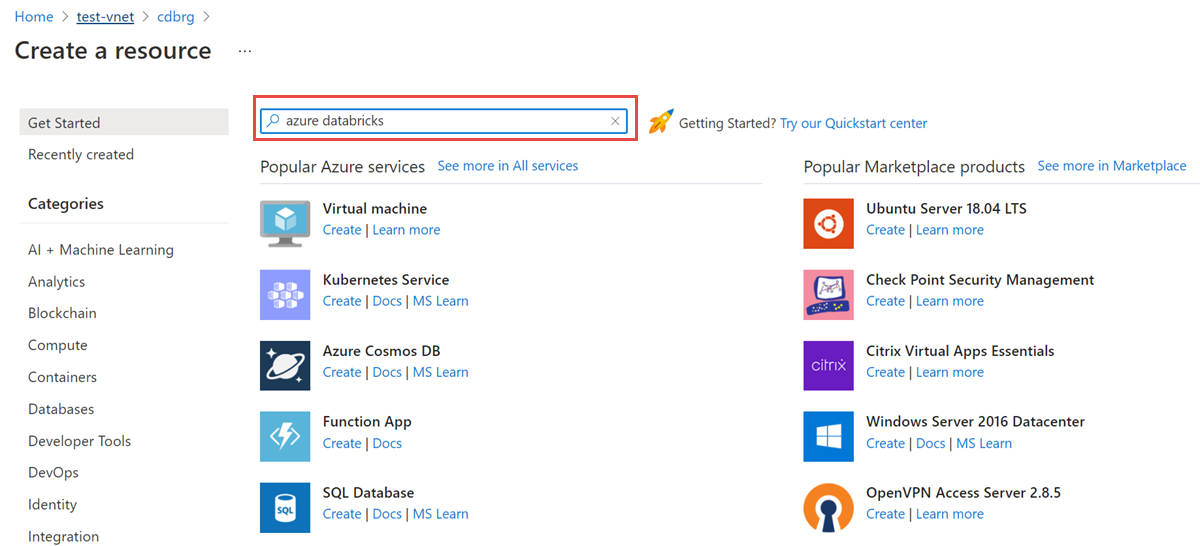
В группе ресурсов выберите Добавить и найдите Azure Databricks в поле поиска.
Выберите "Создать", чтобы создать учетную запись Azure Databricks.
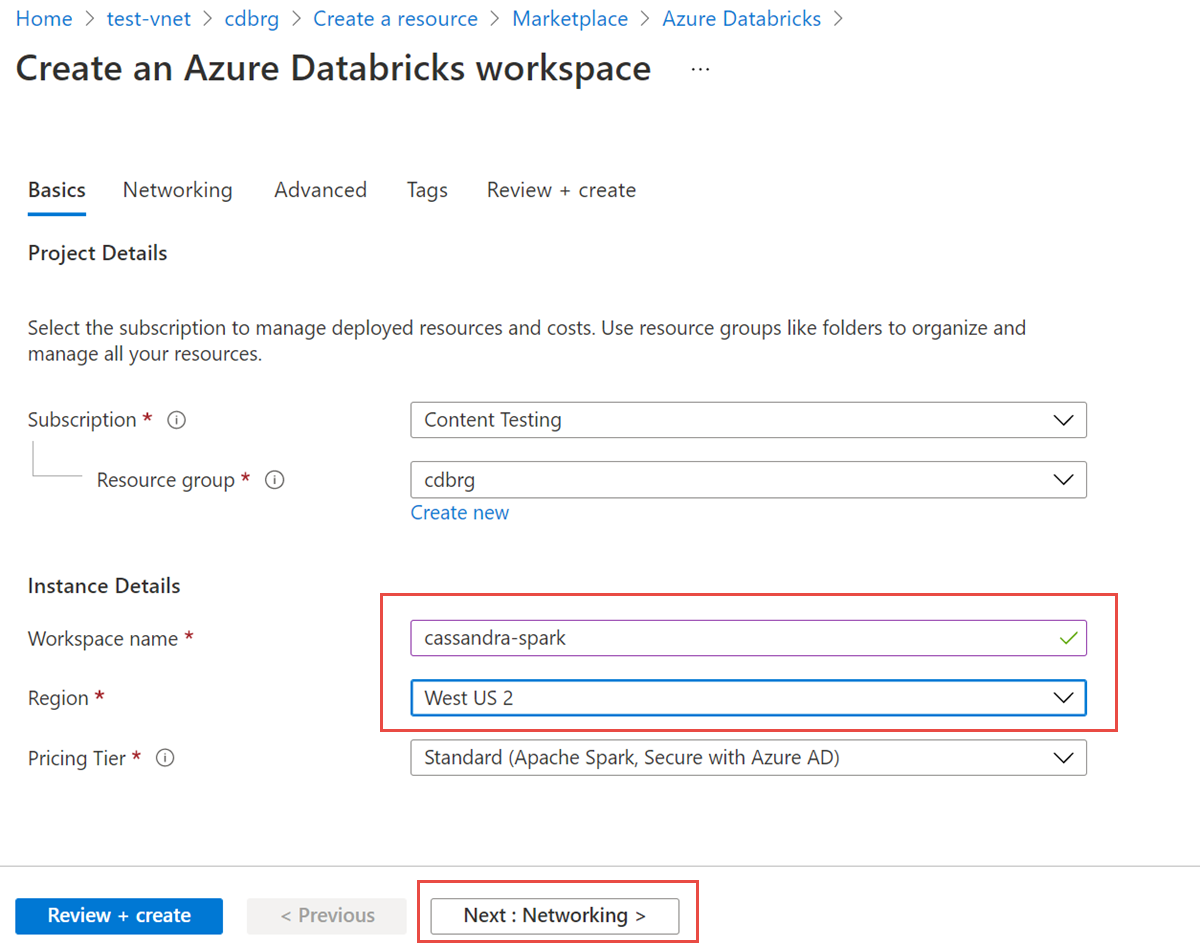
Введите следующие значения:
- Имя рабочей области. Укажите имя рабочей области Azure Databricks.
- Регион. Обязательно выберите тот же регион, что и виртуальная сеть.
- Ценовая категория: выбор категории "Стандартный", "Премиум" или "Пробная версия". Дополнительные сведения об этих уровнях см. на странице цен Azure Databricks.
Выберите вкладку "Сеть" и введите следующие сведения:
- Разверните рабочую область Azure Databricks в виртуальной сети (виртуальная сеть): нажмите кнопку "Да".
- Виртуальная сеть: в раскрывающемся списке выберите виртуальную сеть, в которой существует управляемый экземпляр.
- Имя общедоступной подсети: введите имя общедоступной подсети.
- Диапазон CIDR общедоступной подсети: введите диапазон IP-адресов для общедоступной подсети.
- Имя частной подсети: введите имя частной подсети.
- Диапазон CIDR частной подсети: введите диапазон IP-адресов для частной подсети.
Чтобы избежать конфликтов диапазонов, убедитесь, что выбраны более высокие диапазоны. При необходимости используйте калькулятор визуальной подсети , чтобы разделить диапазоны.
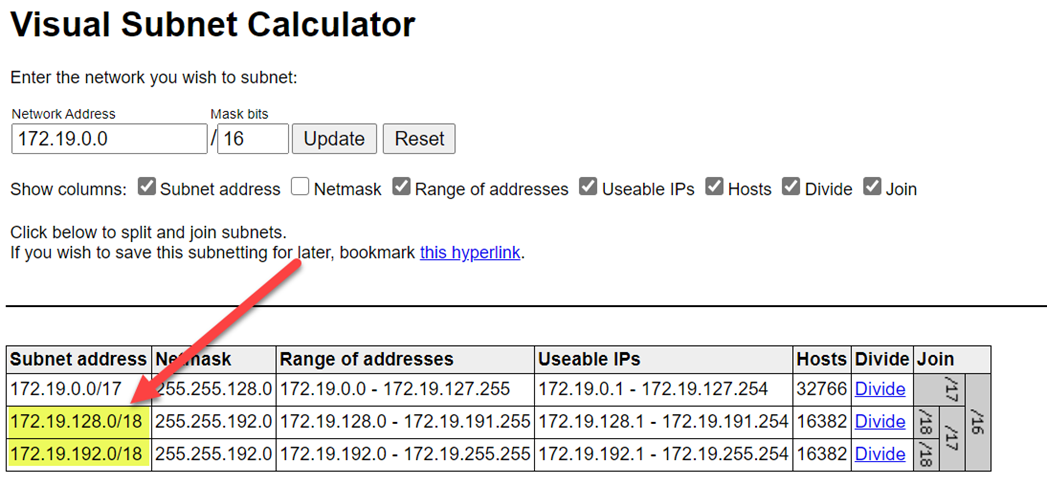
На следующем снимку экрана показаны примеры сведений о сети.
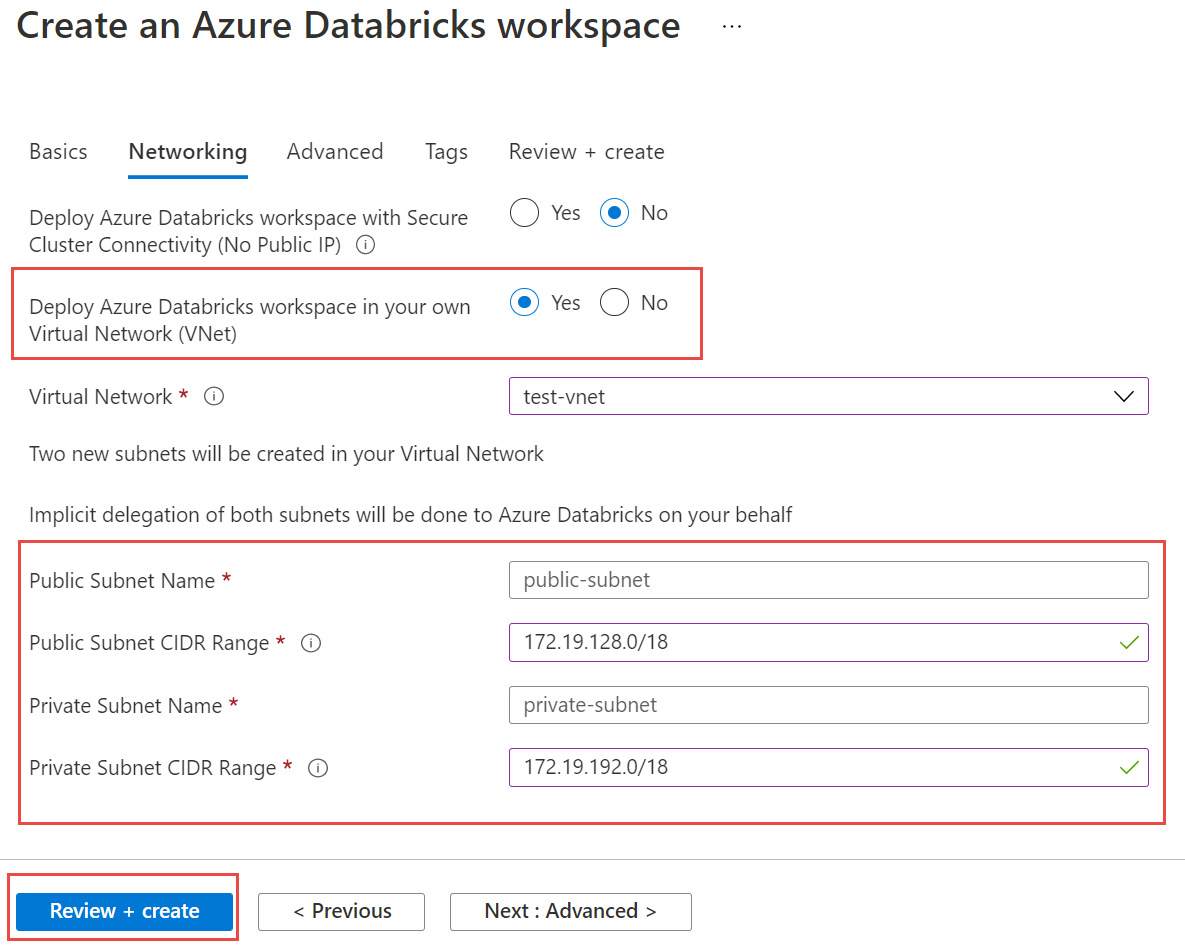
Выберите "Просмотр и создание", а затем нажмите кнопку "Создать ", чтобы развернуть рабочую область.
Откройте рабочую область после создания рабочей области.
Вы будете перенаправлены на портал Azure Databricks. На портале выберите Создать кластер.
На панели "Создать кластер " примите значения по умолчанию для всех полей, отличных от следующих полей:
- Имя кластера: введите имя кластера.
- Версия среды выполнения Databricks: рекомендуется выбрать среду выполнения Azure Databricks версии 7.5 или более поздней для поддержки Spark 3.x.

Разверните дополнительные параметры и добавьте следующую конфигурацию. Обязательно замените IP-адреса и учетные данные узла.
spark.cassandra.connection.host <node1 IP>,<node 2 IP>, <node IP> spark.cassandra.auth.password cassandra spark.cassandra.connection.port 9042 spark.cassandra.auth.username cassandra spark.cassandra.connection.ssl.enabled trueДобавьте библиотеку соединителей Apache Spark Cassandra в кластер для подключения к собственным конечным точкам, а также к конечным точкам Cassandra в Azure Cosmos DB. В вашем кластере выберите Библиотеки>Установить новый>Maven, и затем добавьте
com.datastax.spark:spark-cassandra-connector-assembly_2.12:3.0.0в поле Maven Координаты.
Нажмите Установить.
Очистка ресурсов
Если вы не собираетесь продолжать использовать этот кластер управляемых экземпляров, выполните следующие действия, чтобы удалить его:
- На портале Azure в меню слева выберите Группы ресурсов.
- В списке выберите группу ресурсов, созданную для этого краткого руководства.
- В области Обзор на странице группы ресурсов выберите Удалить группу ресурсов.
- На следующей панели введите имя группы ресурсов, чтобы удалить, и нажмите кнопку "Удалить".
Следующий шаг
Из этого краткого руководства вы узнали, как создать полностью управляемый кластер Apache Spark в виртуальной сети управляемого экземпляра Azure для кластера Apache Cassandra. Далее вы узнаете, как управлять ресурсами кластера и центра обработки данных.