Настройка производительности и обслуживание баз данных в База данных Azure для MySQL — гибкий сервер с помощью sys_schema
Схема performance_schema MySQL, которая стала впервые доступна в MySQL 5.5, предоставляет способ инструментирования многих важных ресурсов серверов, таких как выделение памяти, хранимые программы, блокировка метаданных и т. д. Однако performance_schema содержит более 80 таблиц. Для получения необходимой информации часто требуется объединение таблиц в performance_schema, а также таблицы из information_schema. В performance_schema и information_schema sys_schema предоставляется мощная коллекция пользовательских представлений в базе данных только для чтения и полностью включена в База данных Azure для MySQL гибкий сервер версии 5.7.
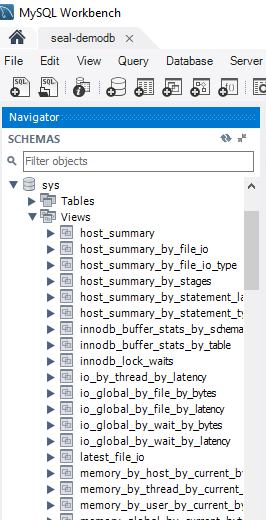
В sys_schema есть 52 представления, каждое из которых имеет один из следующих префиксов:
- Host_summary или IO. Задержки, связанные с операциями ввода и вывода.
- InnoDB. Состояние и блокировки буфера InnoDB.
- Memory. Использование памяти узлом и пользователями.
- Schema. Информация, связанная со схемой, такая как автоматическое увеличение, индексы и т. д.
- Statement. Информация об инструкциях SQL. Это может быть инструкция, выполнение которой привело к полному сканированию таблицы или длительному времени запроса.
- User. Потребляемые ресурсы, сгруппированные по пользователям. Примерами являются операции ввода-вывода файлов, подключения и память.
- Wait. События ожидания, сгруппированные по узлу или пользователю.
Теперь рассмотрим некоторые общие шаблоны использования sys_schema. Для начала мы сгруппируем шаблоны использования в две категории: настройка производительности и обслуживание базы данных.
Настройка производительности
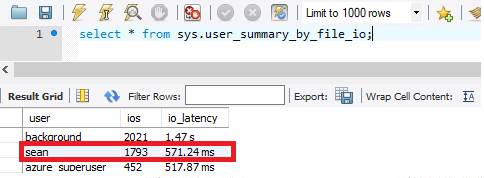
sys.user_summary_by_file_io
Операции ввода-вывода являются наиболее ресурсоемкими операциями в базе данных. Мы можем узнать среднюю задержку операций ввода-вывода, запросив представление sys.user_summary_by_file_io. При использовании подготовленного хранилища по умолчанию размером 125 ГБ задержка ввода-вывода составляет около 15 секунд.
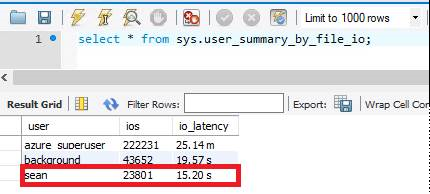
Так как База данных Azure для MySQL гибкий сервер масштабирует операции ввода-вывода в отношении хранилища, после увеличения подготовленного хранилища до 1 ТБ задержка ввода-вывода уменьшается до 571 мс.
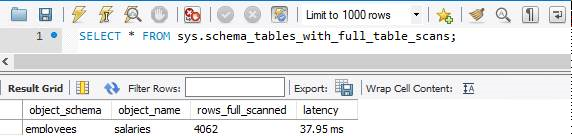
sys.schema_tables_with_full_table_scans
Несмотря на тщательное планирование, многие запросы могут по-прежнему привести к сканированию всей таблицы. Дополнительные сведения о типах индексов и их оптимизации см. в этой статье: производительность запросов профиля в База данных Azure для MySQL — гибкий сервер с помощью EXPLAIN. Полное сканирование таблиц является ресурсоемким и снижает производительность вашей базы данных. Самый быстрый способ поиска таблиц с полным сканированием — запросить представление sys.schema_tables_with_full_table_scans.
sys.user_summary_by_statement_type
Чтобы устранить проблемы с производительностью базы данных, это может оказаться полезным для выявления событий, происходящих внутри базы данных, и использование sys.user_summary_by_statement_type представления может просто сделать это.
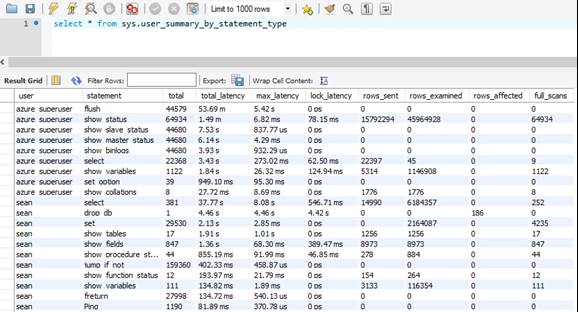
В этом примере База данных Azure для MySQL гибкий сервер провел 53 минуты очистки журнала медленных запросов 44579 раз. Это занимает много времени и требует множества операций ввода-вывода. Вы можете уменьшить эту активность, отключив журнал медленных запросов либо уменьшив частоту внесения в него записей на портале Azure.
Обслуживание базы данных
sys.innodb_buffer_stats_by_table
[!ВАЖНО]
Запрос этого представления может повлиять на производительность. Устранение неполадок следует запланировать на нерабочее время.
Буферный пул InnoDB находится в памяти и является основным механизмом кэширования между СУБД и хранилищем. Размер буферного пула InnoDB привязан к уровню производительности и не может быть изменен, если не выбран другой номер SKU продукта. Как и с памятью в операционной системе, старые страницы выгружаются, чтобы освободить место для новых данных. Чтобы узнать, какие таблицы используют больше всего памяти буферного пула InnoDB, можно запросить представление sys.innodb_buffer_stats_by_table.
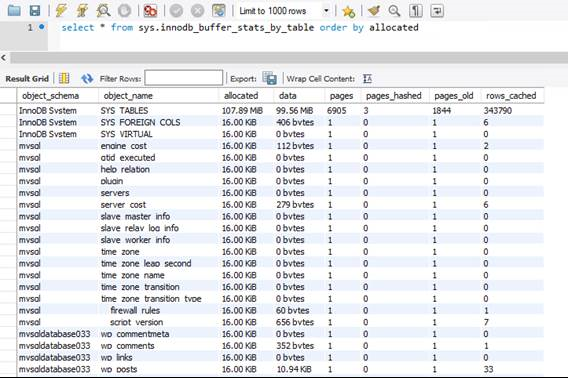
На рисунке выше видно, что, за исключением системных таблиц и представлений, каждая таблица базы данных mysqldatabase033, которая размещает один из сайтов WordPress, занимает 16 КБ или 1 страницу данных в памяти.
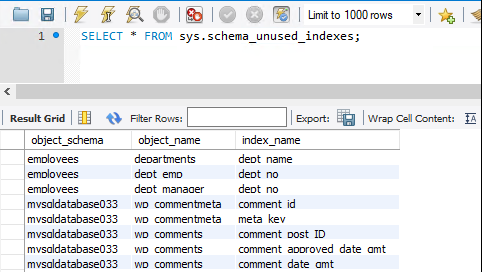
Sys.schema_unused_indexes & sys.schema_redundant_indexes
Индексы являются эффективным инструментом повышения производительности чтения, однако они влекут дополнительные затраты, связанные с операциями вставки и хранением. sys.schema_unused_indexes и sys.schema_redundant_indexes предоставляют сведения об неиспользуемых или повторяющихся индексах.

Заключение
Таким образом, sys_schema является мощным инструментом, который подходит и для настройки производительности, и для обслуживания базы данных. Не забудьте воспользоваться этой функцией в экземпляре гибкого сервера База данных Azure для MySQL.