Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
В этой статье показано, как использовать рабочие нагрузки GPU NVIDIA с Azure Red Hat OpenShift.
Предпосылки
- Интерфейс командной строки OpenShift
- jq, moreutils и пакет gettext
- Azure Red Hat OpenShift 4.10
Если вам нужно установить кластер, см. руководство по созданию кластера Azure Red Hat OpenShift 4. кластеры должны быть версии 4.10.x или более поздней.
Замечание
По состоянию на 4.10 больше не требуется настраивать права для использования оператора NVIDIA. Это значительно упрощает настройку кластера для рабочих нагрузок GPU.
Линукс:
sudo dnf install jq moreutils gettext
macOS
brew install jq moreutils gettext
Запрос квоты GPU
По умолчанию все квоты GPU в Azure — 0. Вам потребуется войти в портал Azure и запросить квоту GPU. Из-за конкуренции для работников GPU может потребоваться подготовить кластер в регионе, где можно фактически зарезервировать GPU.
поддерживает следующие процессы работы с GPU:
- NC4as T4 v3
- NC6s v3
- NC8as T4 v3
- NC12s v3
- NC16as T4 v3
- NC24s v3
- NC24rs v3
- NC64as T4 v3
Следующие экземпляры также поддерживаются в дополнительных наборах компьютеров:
- Standard_ND96asr_v4
- NC24ads_A100_v4
- NC48ads_A100_v4
- NC96ads_A100_v4
- ND96amsr_A100_v4
Замечание
При запросе квоты помните, что Azure является ядром. Чтобы запросить один узел NC4as T4 версии 3, необходимо запросить квоту в группах 4. Если вы хотите запросить NC16as T4 версии 3, вам потребуется запросить квоту 16.
Войдите в портал Azure.
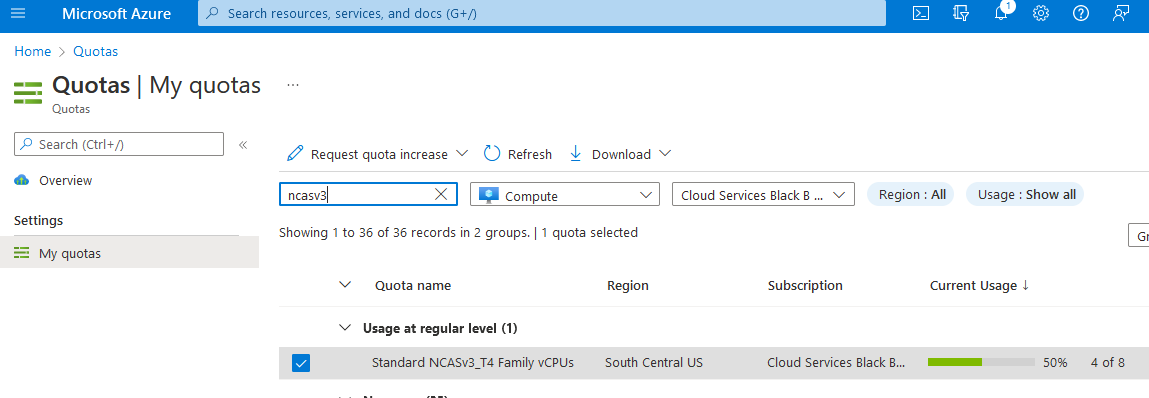
Введите квоты в поле поиска, а затем выберите "Вычисления".
В поле поиска введите NCAsv3_T4, установите флажок для региона, в который находится кластер, а затем выберите "Увеличить квоту запроса".
Настройка параметров квот.
Вход в кластер
Войдите в OpenShift с учетной записью пользователя с правами администратора кластера. В следующем примере используется учетная запись с именем Kubadmin:
oc login <apiserver> -u kubeadmin -p <kubeadminpass>
Секрет извлечения (условный)
Обновите секрет извлечения, чтобы убедиться, что вы можете установить операторы и подключиться к cloud.redhat.com.
Замечание
Пропустите этот шаг, если вы уже создали полный секрет извлечения с включенным cloud.redhat.com.
Войдите в cloud.redhat.com.
Перейдите по ссылке https://cloud.redhat.com/openshift/install/azure/aro-provisioned.
Выберите "Скачать секрет извлечения" и сохраните секрет извлечения как
pull-secret.txt.Это важно
Остальные шаги в этом разделе должны выполняться в том же рабочем каталоге, что
pull-secret.txtи .Экспорт существующего секрета извлечения.
oc get secret pull-secret -n openshift-config -o json | jq -r '.data.".dockerconfigjson"' | base64 --decode > export-pull.jsonОбъедините скачанный секрет извлечения с помощью секрета извлечения системы, чтобы добавить
cloud.redhat.com.jq -s '.[0] * .[1]' export-pull.json pull-secret.txt | tr -d "\n\r" > new-pull-secret.jsonОтправьте новый секретный файл.
oc set data secret/pull-secret -n openshift-config --from-file=.dockerconfigjson=new-pull-secret.jsonВозможно, потребуется ждать около 1 часа, чтобы все синхронизирулось с cloud.redhat.com.
Удаляет секреты.
rm pull-secret.txt export-pull.json new-pull-secret.json
Набор компьютеров GPU
использует Kubernetes MachineSet для создания наборов компьютеров. В приведенной ниже процедуре объясняется, как экспортировать первый набор компьютеров в кластере и использовать его в качестве шаблона для создания одного компьютера GPU.
Просмотр существующих наборов компьютеров.
Для простоты настройки в этом примере используется первый набор компьютеров для клонирования для создания нового набора компьютеров GPU.
MACHINESET=$(oc get machineset -n openshift-machine-api -o=jsonpath='{.items[0]}' | jq -r '[.metadata.name] | @tsv')Сохраните копию примера набора компьютеров.
oc get machineset -n openshift-machine-api $MACHINESET -o json > gpu_machineset.jsonИзмените
.metadata.nameполе на новое уникальное имя.jq '.metadata.name = "nvidia-worker-<region><az>"' gpu_machineset.json| sponge gpu_machineset.jsonУбедитесь, что
spec.replicasсоответствует требуемому количеству реплик для набора компьютеров.jq '.spec.replicas = 1' gpu_machineset.json| sponge gpu_machineset.jsonИзмените
.spec.selector.matchLabels.machine.openshift.io/cluster-api-machinesetполе, чтобы соответствовать полю.metadata.name.jq '.spec.selector.matchLabels."machine.openshift.io/cluster-api-machineset" = "nvidia-worker-<region><az>"' gpu_machineset.json| sponge gpu_machineset.jsonИзмените значение, соответствующее
.spec.template.metadata.labels.machine.openshift.io/cluster-api-machineset.metadata.nameполю.jq '.spec.template.metadata.labels."machine.openshift.io/cluster-api-machineset" = "nvidia-worker-<region><az>"' gpu_machineset.json| sponge gpu_machineset.jsonИзмените
spec.template.spec.providerSpec.value.vmSizeнужный тип экземпляра GPU из Azure.Компьютер, используемый в этом примере, Standard_NC4as_T4_v3.
jq '.spec.template.spec.providerSpec.value.vmSize = "Standard_NC4as_T4_v3"' gpu_machineset.json | sponge gpu_machineset.jsonИзмените
spec.template.spec.providerSpec.value.zoneсоответствие требуемой зоны из Azure.jq '.spec.template.spec.providerSpec.value.zone = "1"' gpu_machineset.json | sponge gpu_machineset.json.statusУдалите раздел yaml-файла.jq 'del(.status)' gpu_machineset.json | sponge gpu_machineset.jsonПроверьте другие данные в yaml-файле.
Убедитесь, что задан правильный номер SKU
В зависимости от образа, используемого для набора компьютеров, оба значения image.skuimage.version должны быть заданы соответствующим образом. Это гарантирует, будет ли использоваться виртуальная машина поколения 1 или 2 для Hyper-V. Подробнее см. здесь.
Пример:
При использовании Standard_NC4as_T4_v3поддерживаются обе версии. Как упоминалось в поддержке компонентов. В этом случае никаких изменений не требуется.
При использовании Standard_NC24ads_A100_v4поддерживается только виртуальная машина поколения 2.
В этом случае image.sku значение должно соответствовать эквивалентной v2 версии образа, соответствующего исходному файлу image.skuкластера. В этом примере будет значение v410-v2.
Это можно найти с помощью следующей команды:
az vm image list --architecture x64 -o table --all --offer aro4 --publisher azureopenshift
Filtered output:
SKU VERSION
------- ---------------
v410-v2 410.84.20220125
aro_410 410.84.20220125
Если кластер был создан с использованием базового образа aro_410SKU, а то же значение хранится в наборе компьютеров, произойдет сбой со следующей ошибкой:
failure sending request for machine myworkernode: cannot create vm: compute.VirtualMachinesClient#CreateOrUpdate: Failure sending request: StatusCode=400 -- Original Error: Code="BadRequest" Message="The selected VM size 'Standard_NC24ads_A100_v4' cannot boot Hypervisor Generation '1'.
Создание набора компьютеров GPU
Чтобы создать новый компьютер GPU, выполните следующие действия. Для подготовки нового компьютера GPU может потребоваться 10–15 минут. Если этот шаг завершается ошибкой, войдите в портал Azure и убедитесь, что проблемы с доступностью отсутствуют. Для этого перейдите к Виртуальные машины и найдите имя рабочей роли, созданное ранее, чтобы просмотреть состояние виртуальных машин.
Создайте набор компьютеров GPU.
oc create -f gpu_machineset.jsonВыполнение команды занимает несколько минут.
Проверьте набор компьютеров GPU.
Компьютеры должны развертываться. Состояние набора компьютера можно просмотреть со следующими командами:
oc get machineset -n openshift-machine-api oc get machine -n openshift-machine-apiПосле подготовки компьютеров (которые могут занять 5–15 минут), компьютеры будут отображаться как узлы в списке узлов:
oc get nodesВы увидите узел с
nvidia-worker-southcentralus1именем, созданным ранее.
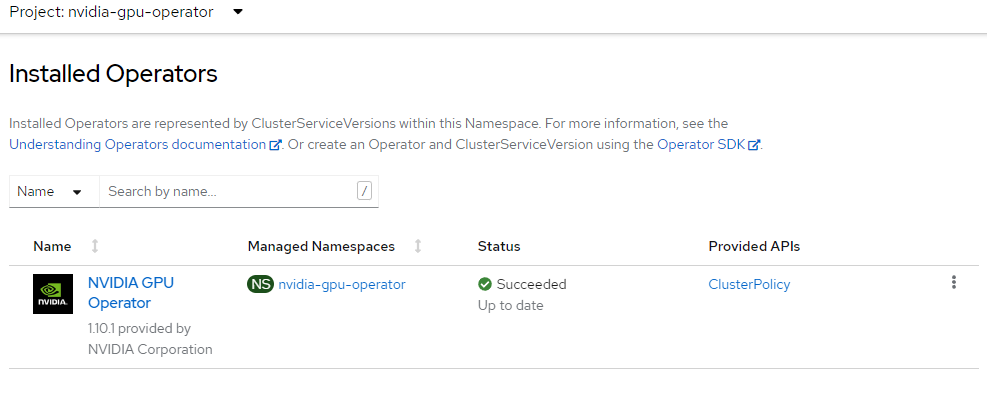
Установка оператора GPU NVIDIA
В этом разделе объясняется, как создать nvidia-gpu-operator пространство имен, настроить группу операторов и установить оператор NVIDIA GPU.
Создайте пространство имен NVIDIA.
cat <<EOF | oc apply -f - apiVersion: v1 kind: Namespace metadata: name: nvidia-gpu-operator EOFСоздание группы операторов.
cat <<EOF | oc apply -f - apiVersion: operators.coreos.com/v1 kind: OperatorGroup metadata: name: nvidia-gpu-operator-group namespace: nvidia-gpu-operator spec: targetNamespaces: - nvidia-gpu-operator EOFПолучите последний канал NVIDIA с помощью следующей команды:
CHANNEL=$(oc get packagemanifest gpu-operator-certified -n openshift-marketplace -o jsonpath='{.status.defaultChannel}')
Замечание
Если кластер был создан без предоставления секрета извлечения, кластер не будет включать примеры или операторы из Red Hat или сертифицированных партнеров. В результате появляется следующее сообщение об ошибке:
Ошибка с сервера (NotFound): packagemanifests.packages.operators.coreos.com "gpu-operator-certified" не найден.
Чтобы добавить секрет извлечения Red Hat в кластере Azure Red Hat OpenShift, следуйте инструкциям.
Получите последний пакет NVIDIA с помощью следующей команды:
PACKAGE=$(oc get packagemanifests/gpu-operator-certified -n openshift-marketplace -ojson | jq -r '.status.channels[] | select(.name == "'$CHANNEL'") | .currentCSV')Создание подписки.
envsubst <<EOF | oc apply -f - apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: gpu-operator-certified namespace: nvidia-gpu-operator spec: channel: "$CHANNEL" installPlanApproval: Automatic name: gpu-operator-certified source: certified-operators sourceNamespace: openshift-marketplace startingCSV: "$PACKAGE" EOFДождитесь завершения установки оператора.
Не продолжайте работу, пока не убедились, что оператор завершил установку. Кроме того, убедитесь, что ваша рабочая роль GPU подключена к сети.
Установка оператора обнаружения компонентов узла
Оператор обнаружения функций узла обнаружит GPU на узлах и соответствующим образом помечает узлы, чтобы их можно было нацелить на рабочие нагрузки.
В этом примере оператор NFD устанавливается в openshift-ndf пространство имен и создает "подписку", которая является конфигурацией для NFD.
Официальная документация по установке оператора обнаружения компонентов узла.
NamespaceНастройка.cat <<EOF | oc apply -f - apiVersion: v1 kind: Namespace metadata: name: openshift-nfd EOFСоздайте
OperatorGroup.cat <<EOF | oc apply -f - apiVersion: operators.coreos.com/v1 kind: OperatorGroup metadata: generateName: openshift-nfd- name: openshift-nfd namespace: openshift-nfd EOFСоздайте
Subscription.cat <<EOF | oc apply -f - apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: nfd namespace: openshift-nfd spec: channel: "stable" installPlanApproval: Automatic name: nfd source: redhat-operators sourceNamespace: openshift-marketplace EOFДождитесь завершения установки обнаружения компонентов узла.
Вы можете войти в консоль OpenShift, чтобы просмотреть операторы или просто ждать несколько минут. Сбой ожидания установки оператора приведет к ошибке на следующем шаге.
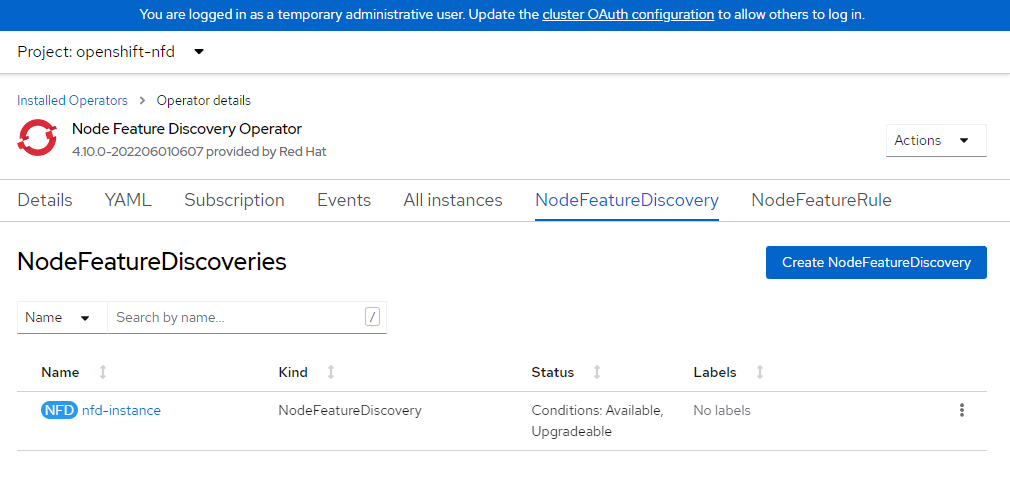
Создание экземпляра NFD.
cat <<EOF | oc apply -f - kind: NodeFeatureDiscovery apiVersion: nfd.openshift.io/v1 metadata: name: nfd-instance namespace: openshift-nfd spec: customConfig: configData: | # - name: "more.kernel.features" # matchOn: # - loadedKMod: ["example_kmod3"] # - name: "more.features.by.nodename" # value: customValue # matchOn: # - nodename: ["special-.*-node-.*"] operand: image: >- registry.redhat.io/openshift4/ose-node-feature-discovery@sha256:07658ef3df4b264b02396e67af813a52ba416b47ab6e1d2d08025a350ccd2b7b servicePort: 12000 workerConfig: configData: | core: # labelWhiteList: # noPublish: false sleepInterval: 60s # sources: [all] # klog: # addDirHeader: false # alsologtostderr: false # logBacktraceAt: # logtostderr: true # skipHeaders: false # stderrthreshold: 2 # v: 0 # vmodule: ## NOTE: the following options are not dynamically run-time ## configurable and require a nfd-worker restart to take effect ## after being changed # logDir: # logFile: # logFileMaxSize: 1800 # skipLogHeaders: false sources: # cpu: # cpuid: ## NOTE: attributeWhitelist has priority over attributeBlacklist # attributeBlacklist: # - "BMI1" # - "BMI2" # - "CLMUL" # - "CMOV" # - "CX16" # - "ERMS" # - "F16C" # - "HTT" # - "LZCNT" # - "MMX" # - "MMXEXT" # - "NX" # - "POPCNT" # - "RDRAND" # - "RDSEED" # - "RDTSCP" # - "SGX" # - "SSE" # - "SSE2" # - "SSE3" # - "SSE4.1" # - "SSE4.2" # - "SSSE3" # attributeWhitelist: # kernel: # kconfigFile: "/path/to/kconfig" # configOpts: # - "NO_HZ" # - "X86" # - "DMI" pci: deviceClassWhitelist: - "0200" - "03" - "12" deviceLabelFields: # - "class" - "vendor" # - "device" # - "subsystem_vendor" # - "subsystem_device" # usb: # deviceClassWhitelist: # - "0e" # - "ef" # - "fe" # - "ff" # deviceLabelFields: # - "class" # - "vendor" # - "device" # custom: # - name: "my.kernel.feature" # matchOn: # - loadedKMod: ["example_kmod1", "example_kmod2"] # - name: "my.pci.feature" # matchOn: # - pciId: # class: ["0200"] # vendor: ["15b3"] # device: ["1014", "1017"] # - pciId : # vendor: ["8086"] # device: ["1000", "1100"] # - name: "my.usb.feature" # matchOn: # - usbId: # class: ["ff"] # vendor: ["03e7"] # device: ["2485"] # - usbId: # class: ["fe"] # vendor: ["1a6e"] # device: ["089a"] # - name: "my.combined.feature" # matchOn: # - pciId: # vendor: ["15b3"] # device: ["1014", "1017"] # loadedKMod : ["vendor_kmod1", "vendor_kmod2"] EOFУбедитесь, что NFD готов.
Состояние этого оператора должно отображаться как доступное.
Применение конфигурации кластера NVIDIA
В этом разделе объясняется, как применить конфигурацию кластера NVIDIA. Ознакомьтесь с документацией NVIDIA по настройке, если у вас есть собственные частные репозитории или определенные параметры. Для завершения этого процесса может потребоваться несколько минут.
Применение конфигурации кластера.
cat <<EOF | oc apply -f - apiVersion: nvidia.com/v1 kind: ClusterPolicy metadata: name: gpu-cluster-policy spec: migManager: enabled: true operator: defaultRuntime: crio initContainer: {} runtimeClass: nvidia deployGFD: true dcgm: enabled: true gfd: {} dcgmExporter: config: name: '' driver: licensingConfig: nlsEnabled: false configMapName: '' certConfig: name: '' kernelModuleConfig: name: '' repoConfig: configMapName: '' virtualTopology: config: '' enabled: true use_ocp_driver_toolkit: true devicePlugin: {} mig: strategy: single validator: plugin: env: - name: WITH_WORKLOAD value: 'true' nodeStatusExporter: enabled: true daemonsets: {} toolkit: enabled: true EOFПроверьте политику кластера.
Войдите в консоль OpenShift и перейдите к операторам. Убедитесь, что вы находитесь в
nvidia-gpu-operatorпространстве имен. Это должно сказатьState: Ready once everything is complete.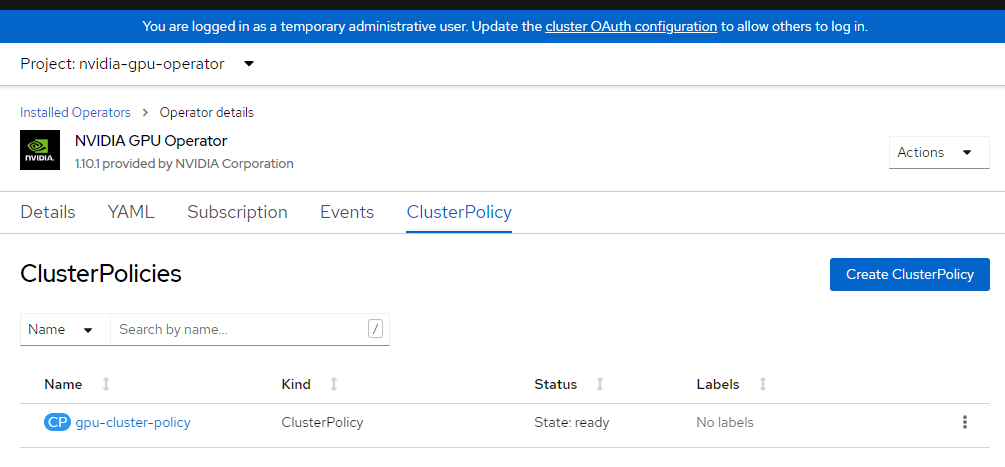
Проверка GPU
Для полной установки и самостоятельного определения компьютеров может потребоваться некоторое время для оператора NVIDIA и NFD. Выполните следующие команды, чтобы убедиться, что все выполняется должным образом:
Убедитесь, что NFD может видеть ваши GPU.
oc describe node | egrep 'Roles|pci-10de' | grep -v masterРезультат должен выглядеть аналогично следующему:
Roles: worker feature.node.kubernetes.io/pci-10de.present=trueПроверьте метки узлов.
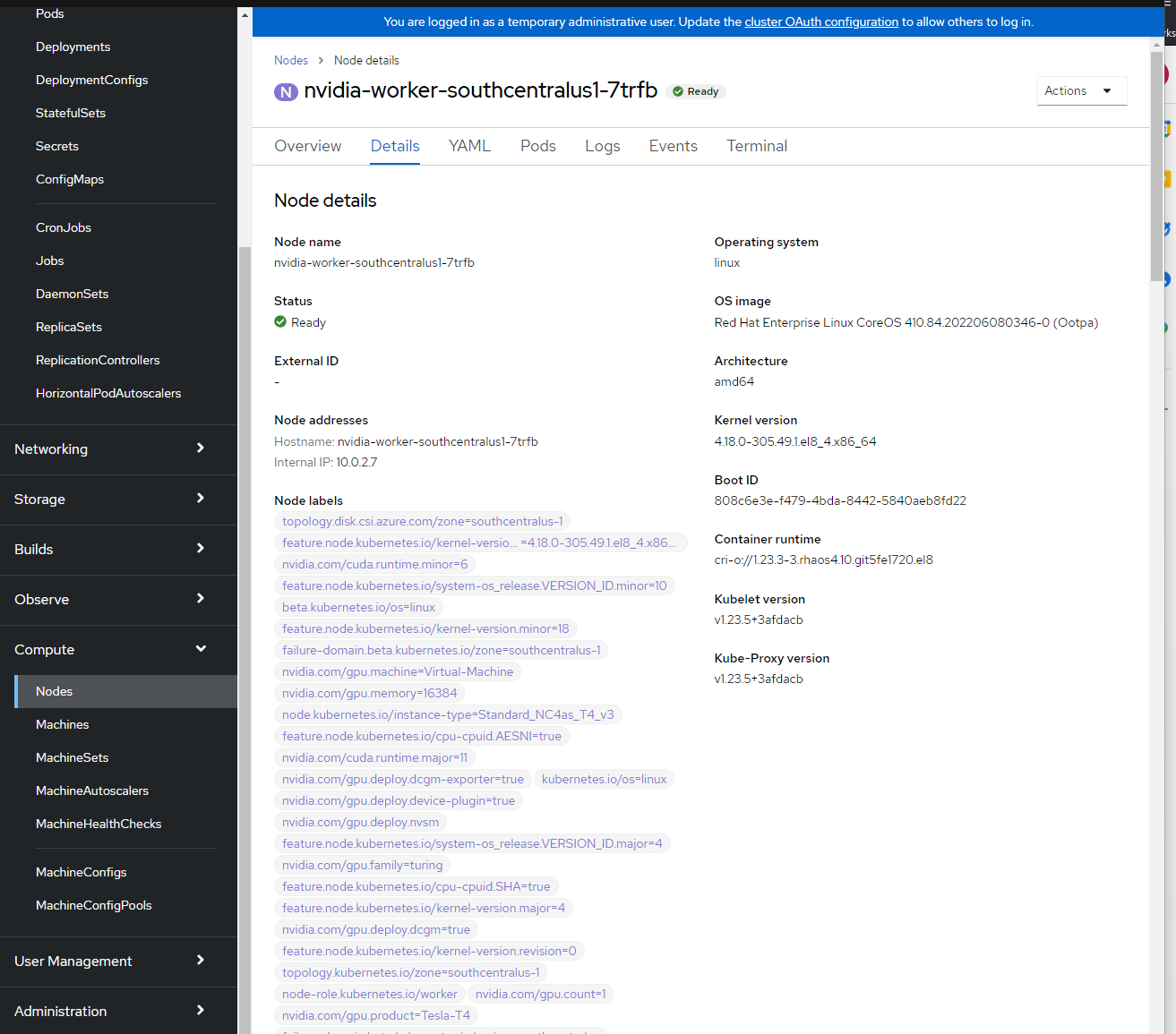
Метки узлов можно просмотреть, выполнив вход в консоль OpenShift —> Compute -> Nodes -> nvidia-worker-southcentralus1-. Вы должны увидеть несколько меток GPU NVIDIA и устройство pci-10de выше.
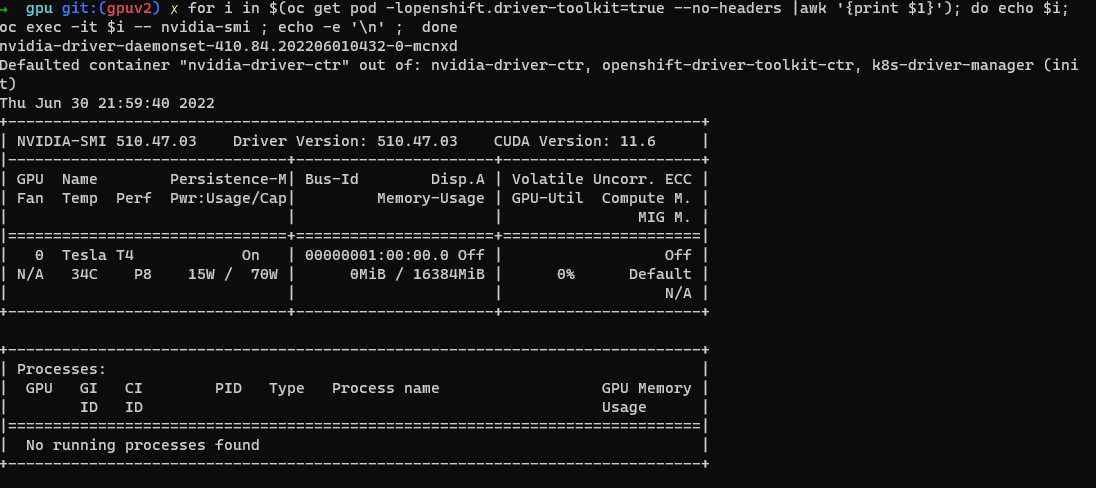
Проверка средства NVIDIA SMI.
oc project nvidia-gpu-operator for i in $(oc get pod -lopenshift.driver-toolkit=true --no-headers |awk '{print $1}'); do echo $i; oc exec -it $i -- nvidia-smi ; echo -e '\n' ; doneВы увидите выходные данные, показывающие графические процессоры, доступные на узле, например на этом примере снимка экрана. (Зависит от типа рабочей роли GPU)
Создание pod для выполнения рабочей нагрузки GPU
oc project nvidia-gpu-operator cat <<EOF | oc apply -f - apiVersion: v1 kind: Pod metadata: name: cuda-vector-add spec: restartPolicy: OnFailure containers: - name: cuda-vector-add image: "quay.io/giantswarm/nvidia-gpu-demo:latest" resources: limits: nvidia.com/gpu: 1 nodeSelector: nvidia.com/gpu.present: true EOFПросмотр журналов.
oc logs cuda-vector-add --tail=-1
Замечание
Если возникает ошибка Error from server (BadRequest): container "cuda-vector-add" in pod "cuda-vector-add" is waiting to start: ContainerCreating, попробуйте выполнить oc delete pod cuda-vector-add и повторно запустить инструкцию создания выше.
Выходные данные должны быть похожи на следующие (в зависимости от GPU):
[Vector addition of 5000 elements]
Copy input data from the host memory to the CUDA device
CUDA kernel launch with 196 blocks of 256 threads
Copy output data from the CUDA device to the host memory
Test PASSED
Done
При успешном выполнении модуль pod можно удалить:
oc delete pod cuda-vector-add