Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Непрерывность бизнес-процессов в Базе данных Azure для PostgreSQL относится к механизмам, политикам и процедурам, которые позволяют бизнесу продолжать работать в условиях нарушения работы, особенно в своей вычислительной инфраструктуре. В большинстве случаев База данных Azure для PostgreSQL обрабатывает разрушительные события, которые могут произойти в облачной среде и поддерживать выполнение приложений и бизнес-процессов. Однако существуют некоторые события, которые не могут обрабатываться автоматически, например:
- Пользователь случайно удаляет или обновляет строку в таблице.
- Землетрясение приводит к сбою электроэнергии и временно отключает зону доступности или регион.
- Исправление базы данных необходимо для исправления ошибки или проблемы с безопасностью.
База данных Azure для PostgreSQL предоставляет возможности, которые защищают данные и минимизируют простой для критически важных баз во время запланированных и незапланированных событий простоя. На основе инфраструктуры Azure, которая обеспечивает надежную устойчивость и доступность, База данных Azure для PostgreSQL имеет функции непрерывности бизнес-процессов, обеспечивающие другую защиту от сбоев, решение требований к времени восстановления и снижение риска потери данных. При разработке приложений следует учитывать допустимость простоя — цель времени восстановления (RTO) и потери данных — цель точки восстановления (RPO). Например, для базы данных, критически важной для бизнеса, требуется более строгое время простоя, чем тестовая база данных.
В приведенной ниже таблице показаны функции, предоставляемые базой данных Azure для PostgreSQL.
| Функция | Описание | Рекомендации |
|---|---|---|
| Автоматическое резервное копирование | Гибкий экземпляр сервера Базы данных Azure для PostgreSQL автоматически выполняет ежедневные резервные копии файлов базы данных и постоянно создает резервные копии журналов транзакций. Резервные копии могут храниться от 7 до 35 дней. Вы можете восстановить сервер базы данных в любой момент времени в течение периода хранения резервных копий. RTO зависит от объема данных, подлежащих восстановлению, и времени, необходимого для выполнения восстановления журнала. Это может быть от нескольких минут до 12 часов. Для получения дополнительной информации см. Основные понятия — резервное копирование и восстановление. | Данные резервного копирования остаются в пределах региона. |
| Высокий уровень доступности с избыточностью в пределах зоны | Гибкий экземпляр сервера базы данных Azure для PostgreSQL можно развернуть с конфигурацией высокой доступности (High Availability, HA) с зональной избыточностью, где первичные и резервные серверы развертываются в двух разных зонах доступности в пределах одного региона. Эта конфигурация высокой доступности защищает ваши базы данных от сбоев на уровне зоны, а также помогает сократить время простоя приложений во время запланированных и незапланированных простоев. Данные с первичного сервера реплицируются на резервную реплику в синхронном режиме. В случае нарушения работы основного сервера происходит автоматическое переключение сервера на резервную реплику. Ожидается, что в большинстве случаев RTO (время восстановления) будет менее 120 секунд. Ожидается, что RPO будет нулевым (без потери данных). Дополнительные сведения см. в разделе "Основные понятия — высокий уровень доступности". | Поддерживается в вычислительных уровнях общего назначения и уровнях, оптимизированных по памяти. Доступно только в регионах, где доступно несколько зон. |
| Высокий уровень доступности в одной зоне | Гибкий экземпляр сервера Базы данных Azure для PostgreSQL можно развернуть с той же конфигурацией высокого уровня доступности зоны , где первичные и резервные серверы развертываются в той же зоне доступности в регионе. Эта конфигурация высокой доступности защищает ваши базы данных от сбоев на уровне узлов, а также помогает сократить время бездействия приложений во время запланированных и незапланированных простоев. Данные с первичного сервера реплицируются на резервную реплику в синхронном режиме. В случае нарушения работы основного сервера происходит автоматическое переключение сервера на резервную реплику. Обычно ожидается, что время восстановления (RTO) составит менее 120 секунд. Ожидается, что RPO будет нулевым (без потери данных). Дополнительные сведения см. в разделе [Основные понятия — высокий уровень доступности]/azure/надежность/надежность-postgresql-гибкий сервер. | Поддерживается в уровнях вычислительных мощностей общего назначения и оптимизированных для работы с памятью. |
| Управляемые диски премиум-класса | Файлы базы данных хранятся в очень прочном и надежном управляемом хранилище премиум-класса. Это обеспечивает избыточность данных с тремя копиями реплики, хранящимися в зоне доступности, с возможностью автоматического восстановления данных. Для получения дополнительной информации см. Документацию по управляемым дискам. | Данные хранятся в зоне доступности. |
| Резервное копирование с зональной избыточностью | Резервные копии экземпляров гибкого сервера Azure Database for PostgreSQL автоматически и безопасно хранятся в зонально-избыточном хранилище в пределах региона, если регион поддерживает зоны доступности. Во время сбоя на уровне зоны, где развернут сервер, и если сервер не настроен на резервирование зоны, вы по-прежнему можете восстановить базу данных с помощью последней точки восстановления в другой зоне. Для получения дополнительной информации см. Основные понятия — резервное копирование и восстановление. | Применимо только в регионах, где доступно несколько зон. |
| Георезервное резервное копирование | Резервные копии экземпляров гибкого сервера базы данных Azure для PostgreSQL копируются в удаленный регион. это помогает с мерами по восстановлению после сбоев в случае недоступности основной серверной области. | В настоящее время эта функция включена в выбранных регионах. Время восстановления (RTO) становится дольше, а допустимая потеря данных (RPO) выше в зависимости от размера данных для восстановления и объема необходимых операций по восстановлению. |
| Реплика для чтения | Реплики чтения между регионами могут быть развернуты для обеспечения защиты баз данных от региональных сбоев. Реплики чтения обновляются асинхронно с применением технологии физической репликации PostgreSQL и могут отставать от основной реплики. Для получения дополнительной информации см. раздел «Основные понятия — реплики для чтения». | Поддерживается на вычислительных уровнях общего назначения и уровнях, оптимизированных для работы с памятью. |
В таблице ниже сравниваются значения RTO и RPO в типичном сценарии рабочей нагрузки.
| Способность | Всплесковая производительность | Производственный SKU (оптимизация для общего назначения/памяти) |
|---|---|---|
| Восстановление на точку во времени из резервной копии | Любая точка восстановления в течение периода хранения Время восстановления (RTO) — варьируется RPO < 5 минут |
Любая точка восстановления в течение периода хранения Время восстановления (RTO) — варьируется RPO < 5 минут |
| Геовосстановление из геореплицированных резервных копий | RTO — значение варьируется RPO < 1 ч |
Время восстановления (RTO) — варьируется RPO < 1 ч |
| Реплики для чтения | Не применимо | RTO — минуты* RPO — обычно от 30 с до 5 минут* |
| Высокий уровень доступности | Не применимо | RTO < 120 с RPO = 0 |
Запланированные события простоя
Ниже приведены некоторые сценарии планового обслуживания. Эти события обычно приводят к простоям до нескольких минут без потери данных.
| Сценарий | Процесс |
|---|---|
| Масштабирование вычислений (инициированное пользователем) | Во время операции масштабирования вычислений активным контрольным точкам дают завершить работу, соединения с клиентами прерываются, все незафиксированные транзакции отменяются, хранилище безопасно отсоединяется, после чего происходит завершение работы. Новая гибкая база данных Azure для PostgreSQL с тем же именем сервера будет развернута с масштабируемой конфигурацией вычислительных ресурсов. Затем хранилище присоединяется к новому серверу, а база данных запускается, которая выполняет восстановление при необходимости, прежде чем принимать клиентские подключения. |
| Масштабирование хранилища (инициированное пользователем) | При инициировании операции масштабирования хранилища активные контрольные точки разрешены, клиентские подключения удаляются, а все незафиксированные транзакции отменяются. После этого сервер выключается. Хранилище масштабируется до желаемого размера и затем подключается к новому серверу. При необходимости перед приемом клиентских подключений выполняется восстановление. Обратите внимание, что уменьшение размера хранилища не поддерживается. |
| Развертывание нового программного обеспечения (инициированное Azure) | Внедрение новых функций или исправление ошибок автоматически происходит в рамках планового обслуживания службы, и вы можете запланировать, когда эти действия должны произойти. Для получения дополнительной информации посетите свой портал. |
| Небольшие обновления версий (инициируемые Azure) | База данных Azure для PostgreSQL автоматически устанавливает патчи на серверы баз данных до минорной версии, определенной Azure. Это происходит в рамках планового обслуживания службы. Сервер базы данных автоматически перезапускается с новой минорной версией. Дополнительные сведения см. в этой документации. Вы также можете проверить ваш портал. |
Когда экземпляр гибкого сервера Azure Database for PostgreSQL настроен с высокой доступностью, служба сначала выполняет масштабирование и операции обслуживания на резервном сервере. Дополнительные сведения см. в разделе [Основные понятия — высокий уровень доступности]/azure/надежность/надежность-postgresql-гибкий сервер.
Уменьшение продолжительности незапланированного простоя
Незапланированные простои могут возникать в результате непредвиденных сбоев, таких как отказ основного оборудования, проблемы с сетью и ошибки программного обеспечения. Если сервер базы данных, настроенный для обеспечения высокой доступности, неожиданно выходит из строя, то активируется резервная реплика, и клиенты могут возобновить свои операции. Если не настроена высокая доступность (HA), то при неудачной попытке перезапуска автоматически создается новый сервер базы данных. Хотя незапланированное время простоя невозможно избежать, База данных Azure для PostgreSQL помогает снизить время простоя, автоматически выполняя операции восстановления без вмешательства человека.
Хотя мы постоянно стремимся обеспечить высокий уровень доступности, иногда возникает сбой базы данных Azure для PostgreSQL, что приводит к недоступности баз данных и таким образом влияет на приложение. Когда наш мониторинг служб обнаруживает проблемы, которые вызывают распространенные ошибки подключения, сбои или проблемы с производительностью, служба автоматически объявляет о сбое, чтобы держать вас в курсе.
Сбой в работе службы
В случае сбоя гибкого экземпляра сервера Базы данных Azure для PostgreSQL можно просмотреть дополнительные сведения о сбое в следующих местах:
- Баннер портала Azure: Если ваша подписка будет затронута, в уведомлениях портала Azure появится предупреждение об ошибке службы.
- Справка и поддержка или Поддержка и устранение неполадок: При создании запроса из Справка и поддержка или Поддержка и устранение неполадок, будут сведения о любых проблемах, влияющих на ваши ресурсы. Выберите "Просмотреть сведения о сбое" для получения дополнительных сведений и сводки о влиянии. На странице "Новый запрос на поддержку" также будет оповещение.
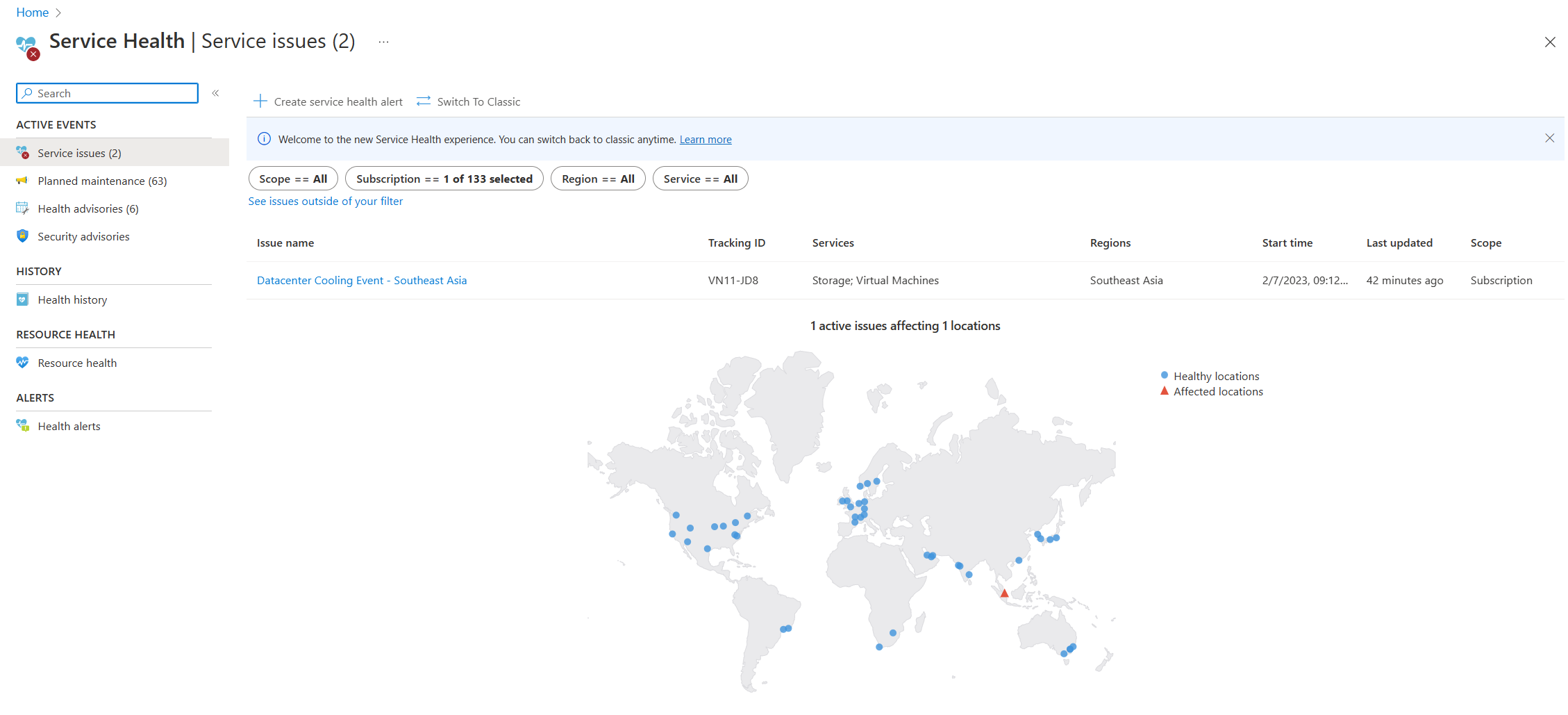
- Справка службы: На странице состояния службы в портале Azure содержится информация о глобальном состоянии центров обработки данных Azure. Найдите "состояние службы" в строке поиска в портале Azure, а затем просмотрите проблемы службы в категории "Активные события". Вы также можете просмотреть работоспособность отдельных ресурсов на странице работоспособности ресурсов любого ресурса в меню справки. На следующем снимке экрана показан пример страницы «Работоспособность службы», содержащей сведения об активной проблеме со службой в Юго-Восточной Азии.
- Уведомление по электронной почте: если вы настроили оповещения, уведомление по электронной почте будет поступать, когда сбой службы влияет на подписку и ресурс. Сообщения электронной почты поступают из "azure-noreply@microsoft.com". Текст сообщения начинается с "Оповещение журнала действий ... было вызвано проблемой с подпиской Azure на услугу...". Дополнительные сведения об оповещениях о работоспособности служб см. в статье «Получение оповещений журнала действий о уведомлениях службы Azure с помощью портала Azure».
Это важно
Как подразумевает имя, временные пространства таблиц в PostgreSQL используются для временных объектов, а также для других внутренних операций базы данных, таких как сортировка. Поэтому мы не рекомендуем создавать объекты схемы пользователей во временном табличном пространстве, так как мы не гарантируем сохранность таких объектов после перезапуска сервера, отказа высокой доступности и т. д.
Незапланированный простой: сценарии сбоев и восстановление службы
Ниже приведены некоторые сценарии незапланированного сбоя и процесс восстановления.
| Сценарий |
Процесс восстановления [Серверы настроены без избыточности между зонами высокого уровня доступности] |
Процесс восстановления [Серверы, настроенные с зонально-избыточным HA] |
|---|---|---|
| Сбой сервера базы данных | Если сервер базы данных не работает, Azure попытается перезапустить сервер базы данных. Если это не удастся, сервер базы данных будет перезапущен на другом физическом узле. Время восстановления (RTO) зависит от различных факторов, включая действие во время сбоя, например большую транзакцию, и объем восстановления, который необходимо выполнить во время запуска сервера базы данных. Приложения, использующие базы данных PostgreSQL, должны быть разработаны таким образом, чтобы они выявляли прерванные подключения и завершившиеся сбоем транзакции и пытались восстановить или повторить их. |
Если обнаруживается сбой сервера базы данных, сервер переключается на резервный сервер, что сокращает время простоя. Для получения дополнительной информации см. страницу [концепции HA]/azure/надежность/надежность-postgresql-гибкий-сервер. Ожидается, что RTO составит 60–120 с без потери данных. |
| Сбой хранилища | Приложения не видят никакого влияния на любые проблемы, связанные с хранилищем, такие как сбой диска или повреждение физического блока. Поскольку данные хранятся в трех копиях, копия данных обслуживается уцелевшим хранилищем. Поврежденный блок данных автоматически восстанавливается, и автоматически создается новая копия данных. | Для любых редких и невосстановимых ошибок, таких как недоступность всего хранилища, происходит автоматическое переключение экземпляра гибкого сервера Azure Database for PostgreSQL на резервную реплику для уменьшения времени простоя. Дополнительные сведения см. на странице [концепции высокой доступности]/azure/reliability/reliability-postgresql-flexible-server. |
| Логические ошибки/ошибки пользователя | Чтобы исправить ошибки пользователя, такие как случайно отброшенные таблицы или неправильно обновленные данные, необходимо выполнить восстановление на определенный момент времени (PITR). При выполнении операции восстановления вы указываете настраиваемую точку восстановления, то есть время непосредственно перед возникновением ошибки. Если нужно восстановить лишь часть баз данных или отдельные таблицы, а не все базы данных на сервере базы данных, можно восстановить сервер баз данных в новый экземпляр, экспортировать из него эти таблицы с помощью команды pg_dump, а затем использовать команду pg_restore, чтобы восстановить эти таблицы в основную базу данных. |
Эти ошибки пользователя не защищены высокой доступностью, так как все изменения реплицируются в резервную реплику синхронно. Для того чтобы восстановиться после таких ошибок, необходимо выполнить восстановление на определенный момент времени. |
| Сбой зоны доступности | Для восстановления после сбоя на уровне зоны вы можете выполнить восстановление на определенный момент времени, используя резервную копию и выбрав настраиваемую точку восстановления с самым последним временем для восстановления последних данных. Новый гибкий сервер Azure Database для PostgreSQL развертывается в другой неподвержённой зоне. Время, необходимое для восстановления, зависит от предыдущей резервной копии и объема восстанавливаемых журналов транзакций. | Гибкий сервер базы данных Azure для PostgreSQL автоматически переключается на резервный сервер в течение 60-120 секунд без потери данных. Дополнительные сведения см. на странице [основные понятия высокого уровня доступности]/azure/надежность/надежность-postgresql-гибкий сервер. |
| Сбой региона | Если на сервере настроено геоизбыточное резервное копирование, можно выполнить геовосстановление в парном регионе. Новый сервер будет подготовлен и восстановлен до последней доступной информации, которая была скопирована в этот регион. Можно также использовать кросс-региональные реплики чтения. В случае сбоя региона можно выполнить операцию аварийного восстановления, повышая реплику для чтения до автономного сервера для чтения и записи. Ожидается, что RPO составляет до 5 минут (возможна потеря данных), за исключением случаев серьезного регионального сбоя, когда RPO может быть близок к задержке репликации во время сбоя. |
Тот же процесс. |
Настройка базы данных после восстановления из регионального сбоя
- Если для восстановления после сбоя используется геовосстановление или геореплика, необходимо убедиться, что подключение к новому серверу настроено правильно, чтобы нормальная функция приложения была возобновлена. Вы можете выполнять задачи после восстановления.
- Если вы ранее настроили параметр диагностики на исходном сервере, убедитесь, что он установлен на целевом сервере, если это необходимо, как описано в разделе "Настройка и доступ к журналам" в Базе данных Azure для PostgreSQL.
- Настройте оповещения телеметрии, чтобы убедиться, что существующие параметры правила генерации оповещений обновлены и соответствуют новому серверу. Дополнительные сведения о правилах генерации оповещений см. на портале Azure для настройки оповещений о метриках для Базы данных Azure для PostgreSQL.
Это важно
Удаленные серверы можно восстановить. Если вы удалите сервер, вы можете следовать нашим рекомендациям по восстановлению удаленной базы данных Azure для восстановления. Используйте блокировку ресурсов Azure, чтобы предотвратить случайное удаление вашего сервера.