Заметка
Доступ к этой странице требует авторизации. Вы можете попробовать войти в систему или изменить каталог.
Доступ к этой странице требует авторизации. Вы можете попробовать сменить директорию.
В этой статье описывается, как определить и диагностировать первопричину медленных запросов.
В этой статье раскрываются приведенные ниже темы.
- Как определить медленные запросы.
- Как определить медленно выполняющуюся процедуру вместе с ней. Определите медленный запрос среди списка запросов, относящихся к той же медленно выполняющейся хранимой процедуре.
Необходимые компоненты
Включите руководства по устранению неполадок, выполнив действия, описанные в руководствах по устранению неполадок.
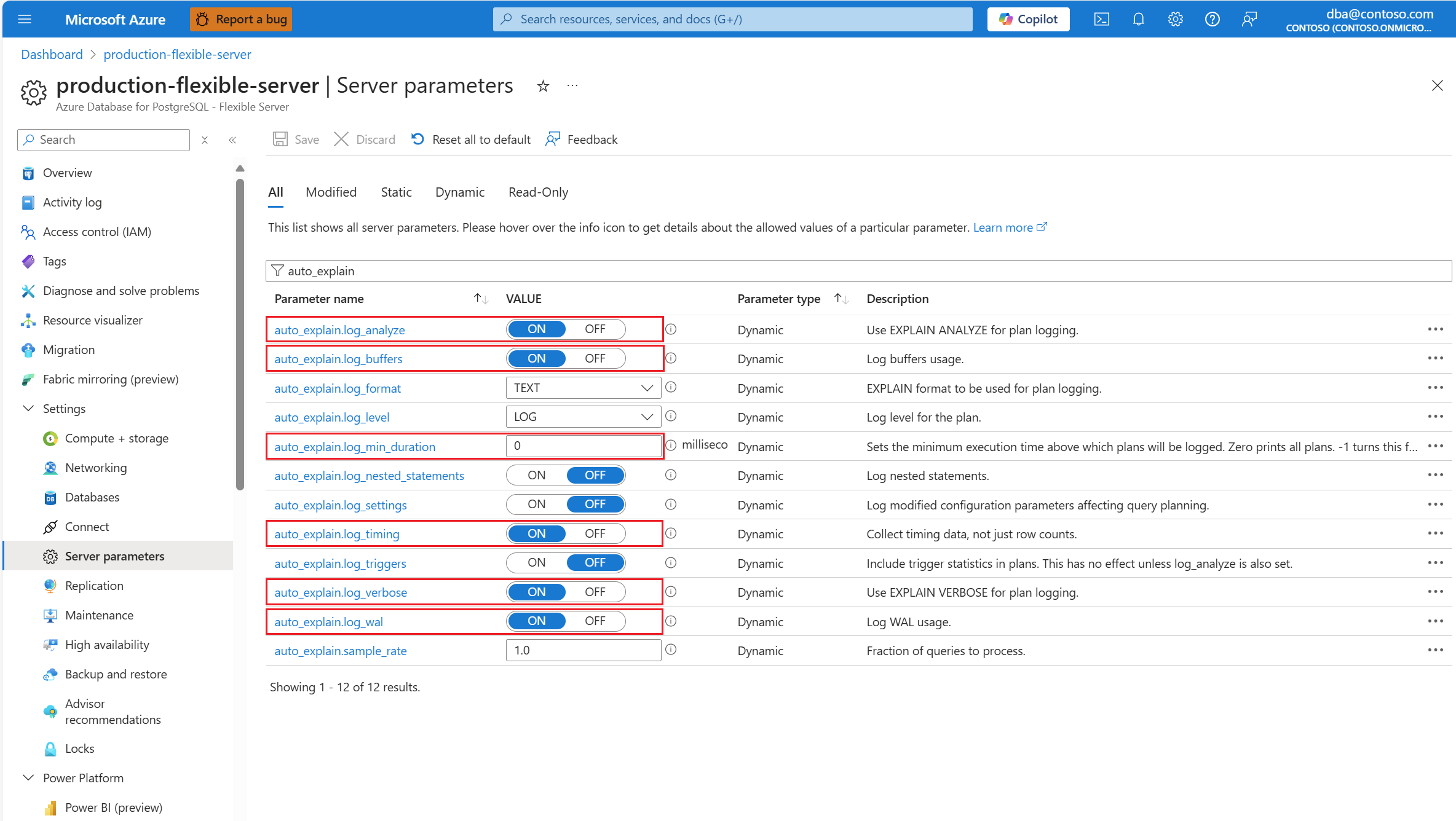
auto_explainНастройте расширение, указав список разрешений и загрузив расширение.auto_explainПосле настройки расширения измените следующие параметры сервера, которые управляют поведением расширения:-
auto_explain.log_analyzeизменено наON. -
auto_explain.log_buffersизменено наON. -
auto_explain.log_min_durationв соответствии с тем, что разумно в вашем сценарии. -
auto_explain.log_timingизменено наON. -
auto_explain.log_verboseизменено наON.
-

Примечание.
Если задано auto_explain.log_min_duration значение 0, расширение начинает ведение журнала всех запросов, выполняемых на сервере. Это может повлиять на производительность базы данных. Для определения значения, которое считается обрабатываемым медленно на сервере, необходимо провести тщательную проверку. Например, если все запросы выполняются менее чем за 30 секунд, и это приемлемо для приложения, рекомендуется обновить параметр до 30 000 миллисекунд. После этого будет регистрироваться любой запрос, который занимает более 30 секунд.
Определение медленного запроса
С помощью руководств по устранению неполадок и auto_explain расширений мы описываем сценарий с помощью примера.
У нас есть сценарий, в котором загрузка ЦП возрастает до 90 % и хочется определить причину пикового всплеска. Чтобы выполнить отладку сценария, выполните следующие действия.
Как только вы оповещены сценарием ЦП, в меню ресурсов затронутого экземпляра гибкого сервера Базы данных Azure для PostgreSQL в разделе "Мониторинг " выберите руководства по устранению неполадок.
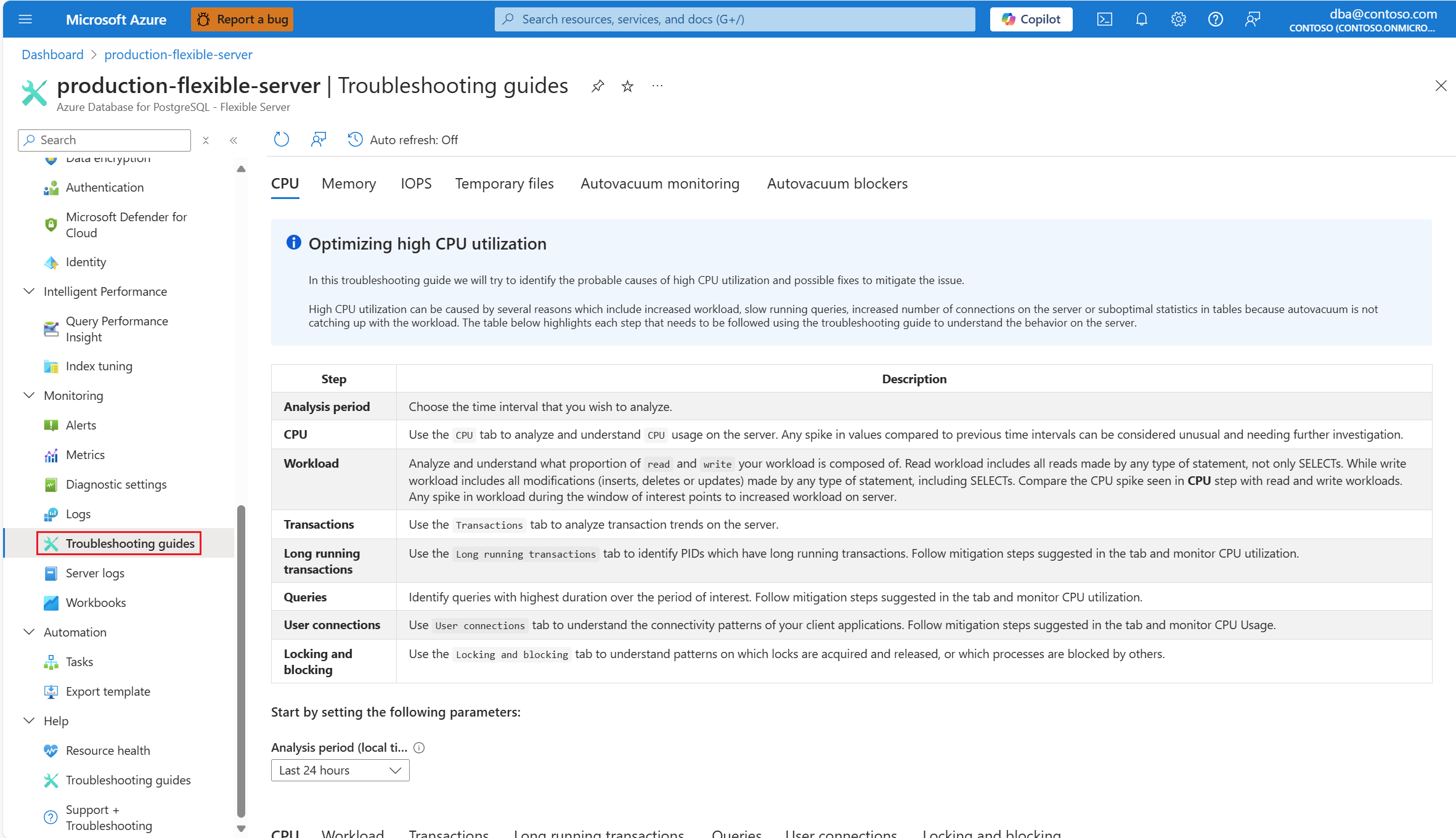
Выберите вкладку ЦП . Откроется руководство по устранению неполадок с оптимизацией использования ЦП.
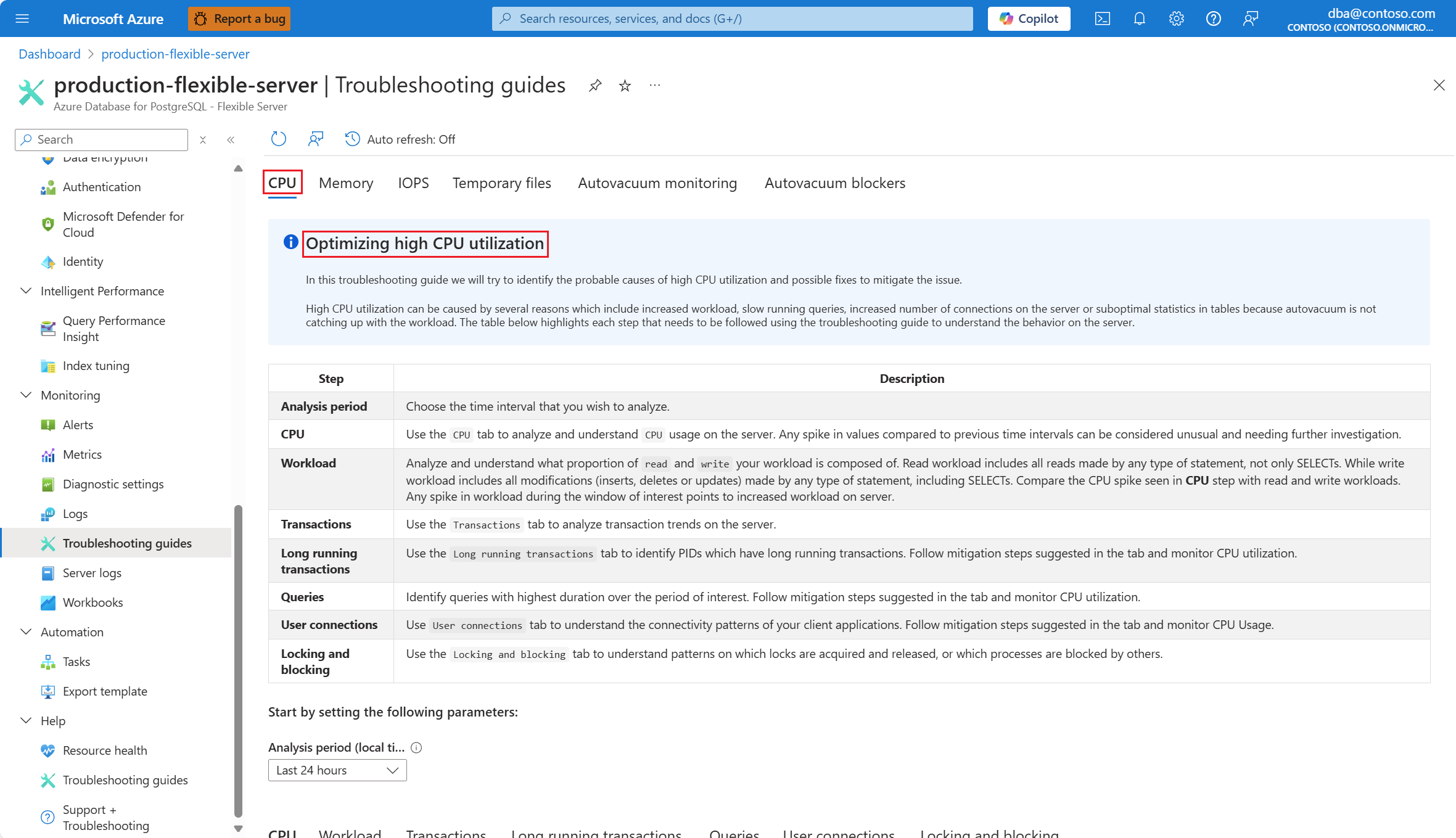
В раскрывающемся списке "Анализ" (локальное время) выберите диапазон времени, на котором нужно сосредоточить анализ.
Вкладка " Запросы". В нем показаны сведения обо всех запросах, запущенных в интервале, в котором было видно 90 % использования ЦП. Из моментального снимка он выглядит как запрос с самым медленным средним временем выполнения в течение интервала времени около 2,6 минут, и запрос выполнялся 22 раза в течение интервала. Этот запрос, скорее всего, является причиной пиков ЦП.
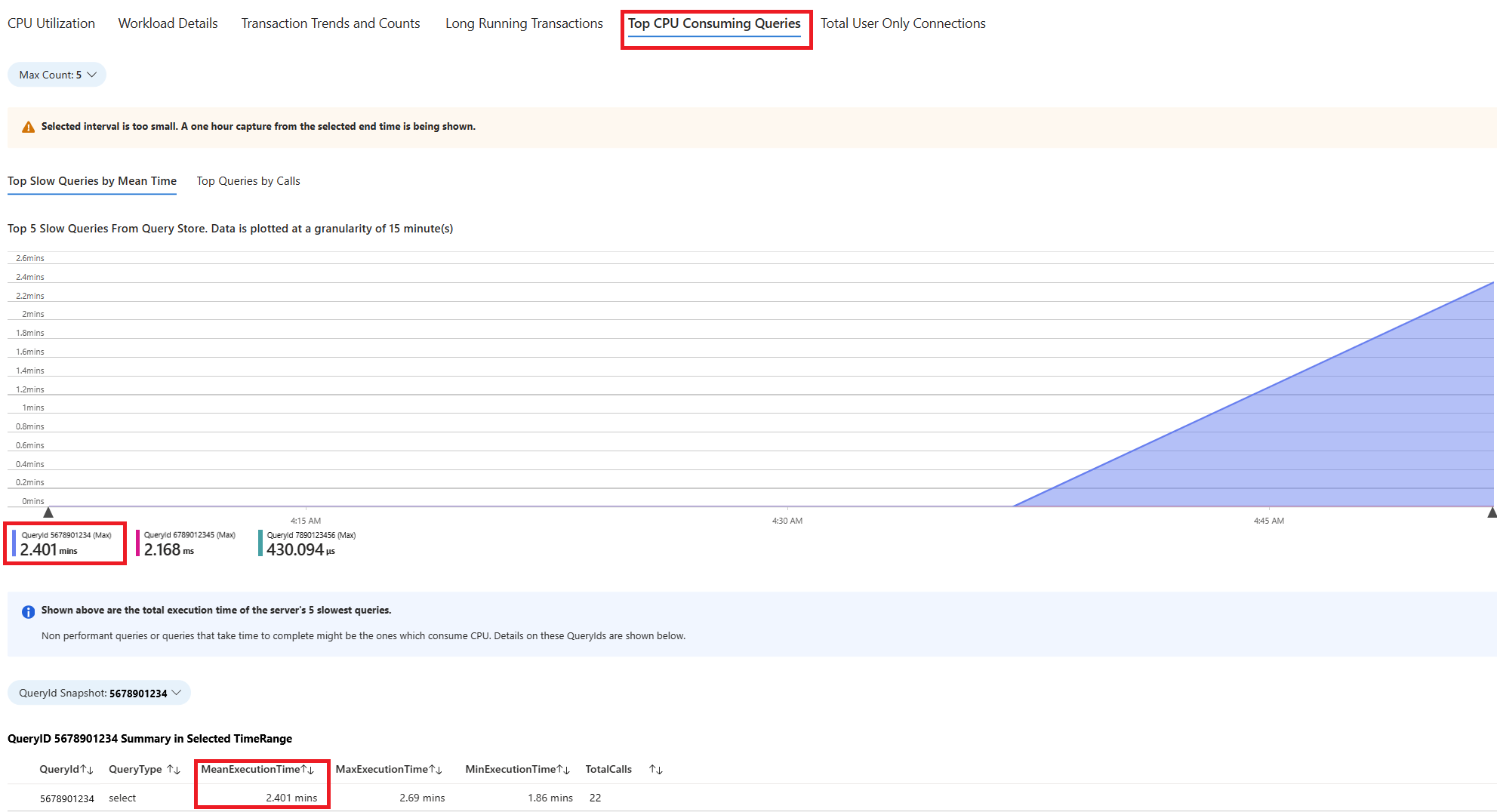
Чтобы получить фактический текст запроса, подключитесь к
azure_sysбазе данных и выполните следующий запрос.




psql -h <server>.postgres.database.azure.com -U <user> -d azure_sys
SELECT query_sql_text
FROM query_store.query_texts_view
WHERE query_text_id = <query_id>;
- В приведенном примере запрос, который был найден медленным, был:
SELECT c_id, SUM(c_balance) AS total_balance
FROM customer
GROUP BY c_w_id, c_id
ORDER BY c_w_id;
Чтобы понять, какой именно план объяснения был сгенерирован, используйте журналы Azure Database для PostgreSQL. Каждый раз, когда запрос завершил выполнение в течение этого периода времени,
auto_explainрасширение должно записывать запись в журналах. В меню ресурсов в разделе "Мониторинг " выберите "Журналы".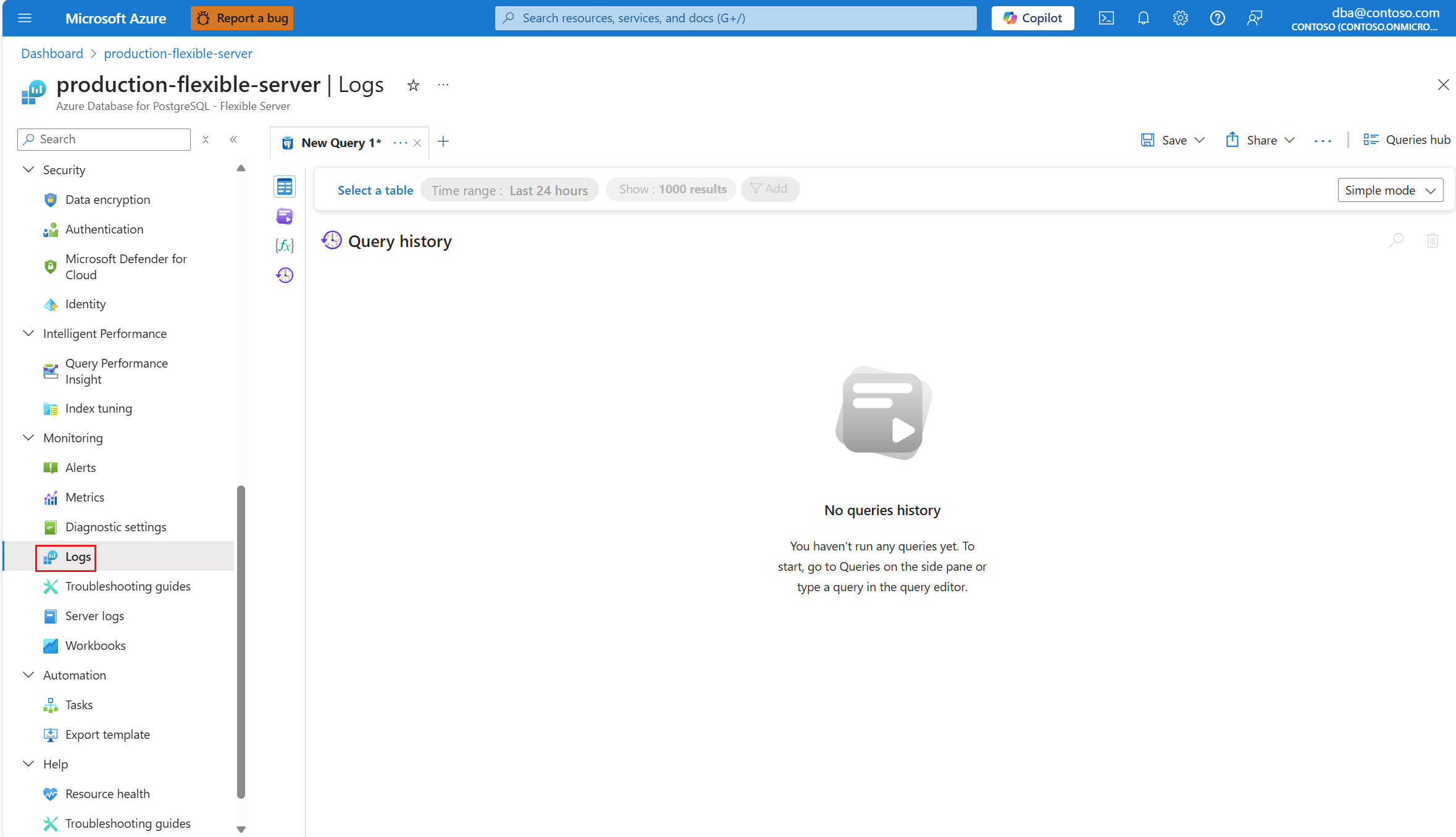
Выберите диапазон времени, в котором обнаружена загрузка ЦП 90 %.
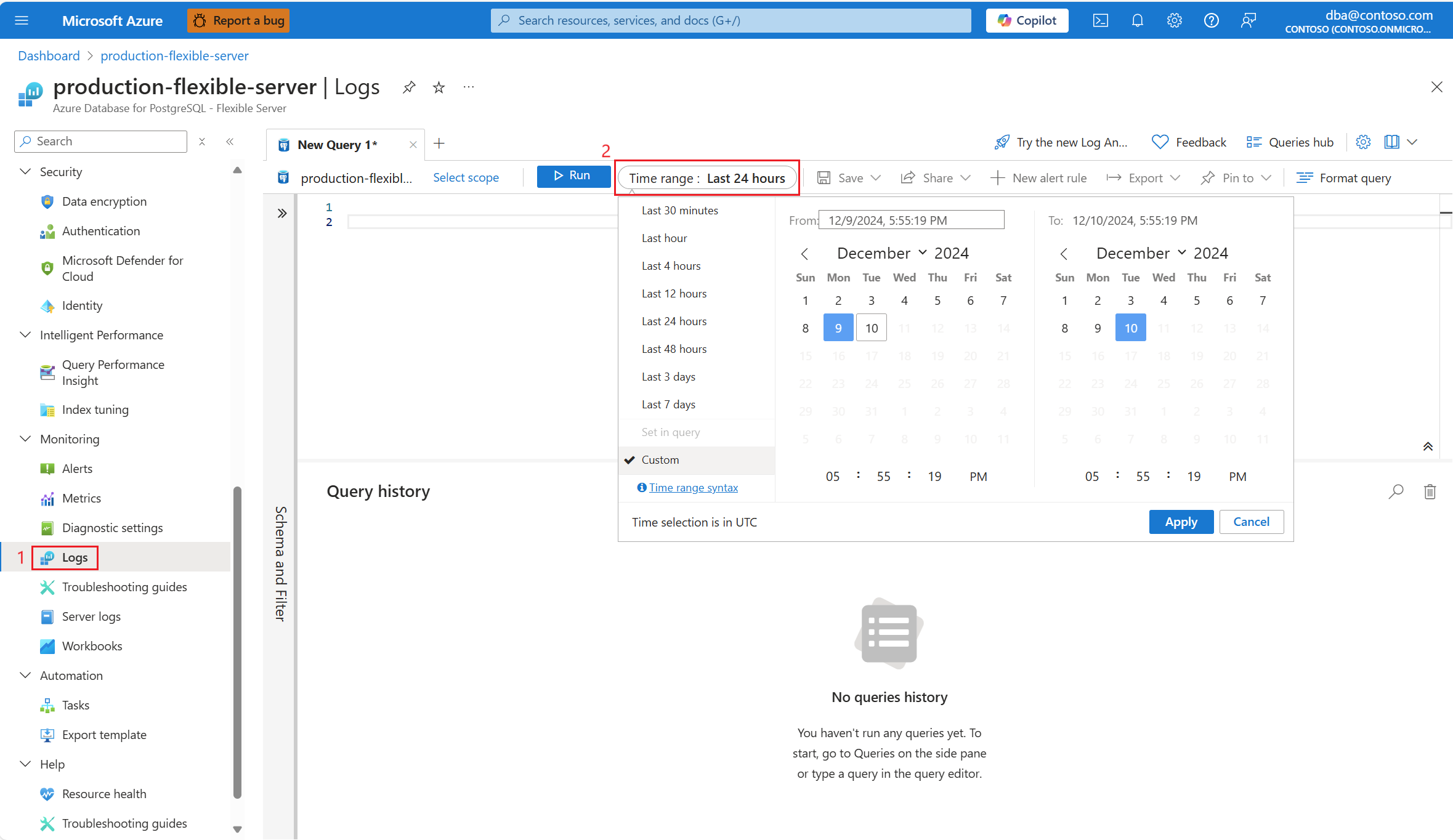
Выполните следующий запрос, чтобы получить выходные данные EXPLAIN ANALYZE для определенного запроса.

AzureDiagnostics
| where Category contains 'PostgreSQLLogs'
| where Message contains "<snippet of SQL text identified or name of any of the tables referenced in the query>"
| project TimeGenerated, Message
В столбце сообщений хранится план выполнения, как показано в этом выходных данных:
2024-11-10 19:56:46 UTC-6525a8e7.2e3d-LOG: duration: 150692.864 ms plan:
Query Text: SELECT c_id, SUM(c_balance) AS total_balance
FROM customer
GROUP BY c_w_id,c_id
order by c_w_id;
GroupAggregate (cost=1906820.83..2131820.83 rows=10000000 width=40) (actual time=70930.833..129231.950 rows=10000000 loops=1)
Output: c_id, sum(c_balance), c_w_id
Group Key: customer.c_w_id, customer.c_id
Buffers: shared hit=44639 read=355362, temp read=77521 written=77701
-> Sort (cost=1906820.83..1931820.83 rows=10000000 width=13) (actual time=70930.821..81898.430 rows=10000000 loops=1)
Output: c_id, c_w_id, c_balance
Sort Key: customer.c_w_id, customer.c_id
Sort Method: external merge Disk: 225104kB
Buffers: shared hit=44639 read=355362, temp read=77521 written=77701
-> Seq Scan on public.customer (cost=0.00..500001.00 rows=10000000 width=13) (actual time=0.021..22997.697 rows=10000000 loops=1)
Output: c_id, c_w_id, c_balance
Запрос выполнялся около 2,5 минут, как показано в руководстве по устранению неполадок. Значение duration 150692,864 мс из выходных данных плана выполнения подтверждает его. Используйте выходные данные EXPLAIN ANALYZE для дальнейшего устранения неполадок и настройки запроса.
Примечание.
Обратите внимание, что запрос выполнялся 22 раза в течение интервала, а отображаемые журналы содержат такие записи, захваченные в течение интервала.
Определение медленно выполняющегося запроса в хранимой процедуре
С помощью руководств по устранению неполадок и auto_explain расширения мы объясним сценарий с помощью примера.
У нас есть сценарий, в котором загрузка ЦП возрастает до 90 % и хочется определить причину пикового всплеска. Чтобы выполнить отладку сценария, выполните следующие действия.
Как только вы оповещены сценарием ЦП, в меню ресурсов затронутого экземпляра гибкого сервера Базы данных Azure для PostgreSQL в разделе "Мониторинг " выберите руководства по устранению неполадок.
Выберите вкладку ЦП . Откроется руководство по устранению неполадок с оптимизацией использования ЦП.
В раскрывающемся списке "Анализ" (локальное время) выберите диапазон времени, на котором нужно сосредоточить анализ.
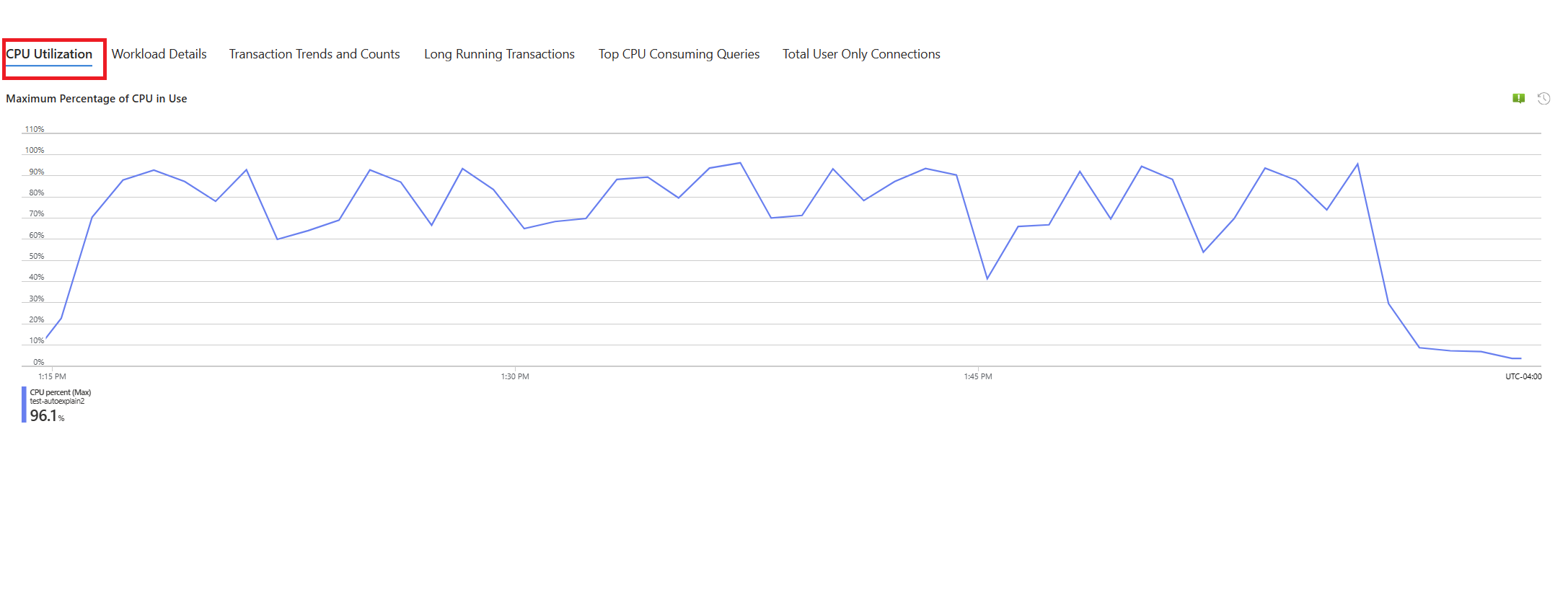
Вкладка " Запросы". В нем показаны сведения обо всех запросах, запущенных в интервале, в котором было видно 90 % использования ЦП. Из моментального снимка он выглядит как запрос с самым медленным средним временем выполнения в течение интервала времени около 2,6 минут, и запрос выполнялся 22 раза в течение интервала. Этот запрос, скорее всего, является причиной пиков ЦП.
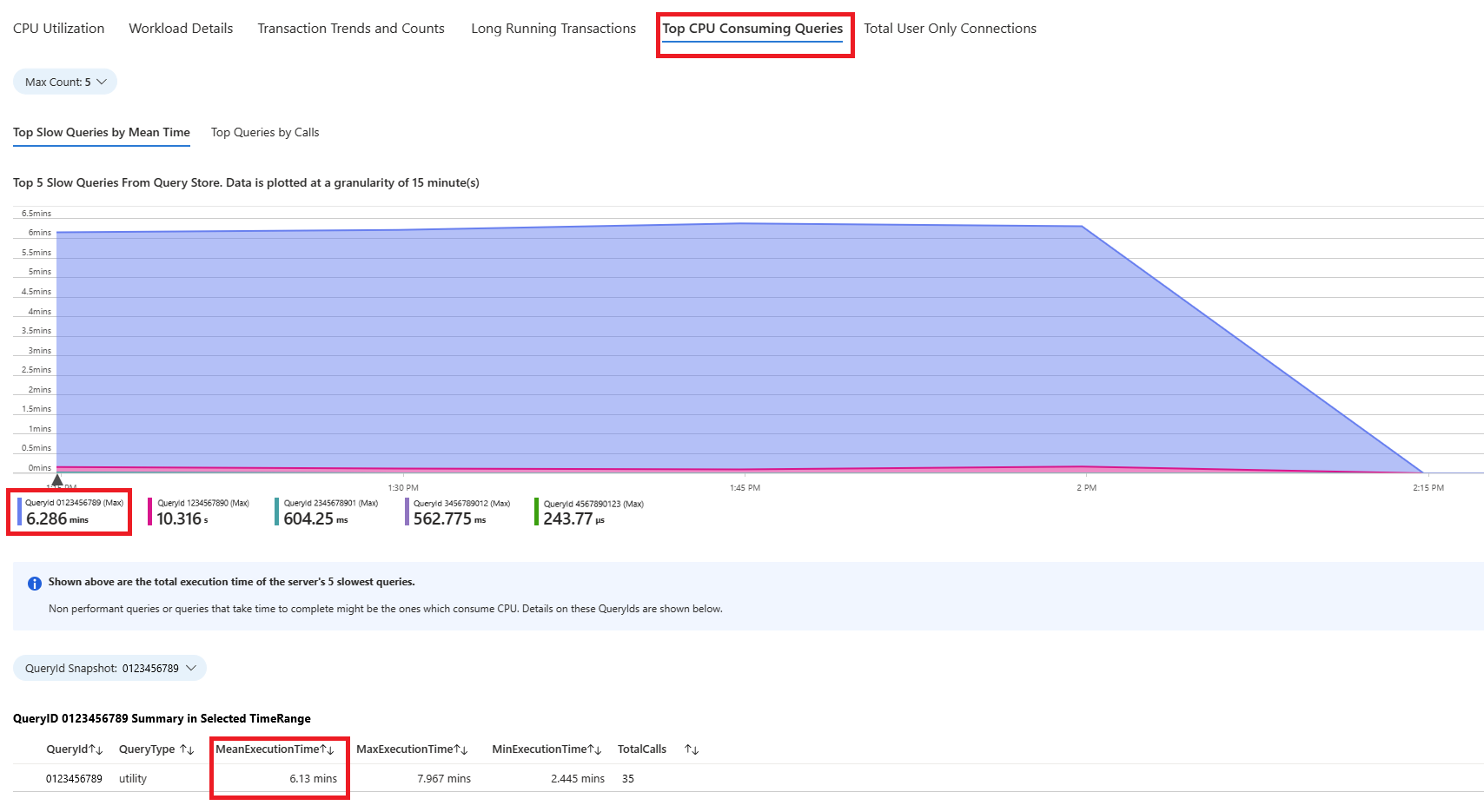
Подключитесь к базе данных azure_sys и выполните запрос, чтобы получить фактический текст запроса с помощью приведенного ниже скрипта.


psql -h <server>.postgres.database.azure.com -U <user> -d azure_sys
SELECT query_sql_text
FROM query_store.query_texts_view
WHERE query_text_id = <query_id>;
- В приведенном примере запрос, который был найден медленным, был хранимой процедурой:
call autoexplain_test ();
- Чтобы понять, какой именно план объяснения был сгенерирован, используйте журналы Azure Database для PostgreSQL. Каждый раз, когда запрос завершил выполнение в течение этого периода времени,
auto_explainрасширение должно записывать запись в журналах. В меню ресурсов в разделе "Мониторинг " выберите "Журналы". Затем в диапазоне времени выберите окно времени, в котором нужно сосредоточить анализ.

- Выполните следующий запрос, чтобы получить данные анализа определенного запроса.
AzureDiagnostics
| where Category contains 'PostgreSQLLogs'
| where Message contains "<snippet of SQL text identified or name of any of the tables referenced in the query>"
| project TimeGenerated, Message
Процедура содержит несколько запросов, которые выделены ниже. Объяснение анализа выходных данных каждого запроса, используемого в хранимой процедуре, регистрируется для дальнейшего анализа и устранения неполадок. Время выполнения зарегистрированных запросов можно использовать для определения самых медленных запросов, входящих в хранимую процедуру.
2024-11-10 17:52:45 UTC-6526d7f0.7f67-LOG: duration: 38459.176 ms plan:
Query Text: insert into customer_balance SELECT c_id, SUM(c_balance) AS total_balance FROM customer GROUP BY c_w_id,c_id order by c_w_id
Insert on public.customer_balance (cost=1906820.83..2231820.83 rows=0 width=0) (actual time=38459.173..38459.174 rows=0 loops=1)Buffers: shared hit=10108203 read=454055 dirtied=54058, temp read=77521 written=77701 WAL: records=10000000 fpi=1 bytes=640002197
-> Subquery Scan on "*SELECT*" (cost=1906820.83..2231820.83 rows=10000000 width=36) (actual time=20415.738..29514.742 rows=10000000 loops=1)
Output: "*SELECT*".c_id, "*SELECT*".total_balance Buffers: shared hit=1 read=400000, temp read=77521 written=77701
-> GroupAggregate (cost=1906820.83..2131820.83 rows=10000000 width=40) (actual time=20415.737..28574.266 rows=10000000 loops=1)
Output: customer.c_id, sum(customer.c_balance), customer.c_w_id Group Key: customer.c_w_id, customer.c_id Buffers: shared hit=1 read=400000, temp read=77521 written=77701
-> Sort (cost=1906820.83..1931820.83 rows=10000000 width=13) (actual time=20415.723..22023.515 rows=10000000 loops=1)
Output: customer.c_id, customer.c_w_id, customer.c_balance Sort Key: customer.c_w_id, customer.c_id Sort Method: external merge Disk: 225104kB Buffers: shared hit=1 read=400000, temp read=77521 written=77701
-> Seq Scan on public.customer (cost=0.00..500001.00 rows=10000000 width=13) (actual time=0.310..15061.471 rows=10000000 loops=1) Output: customer.c_id, customer.c_w_id, customer.c_balance Buffers: shared hit=1 read=400000
2024-11-10 17:52:07 UTC-6526d7f0.7f67-LOG: duration: 61939.529 ms plan:
Query Text: delete from customer_balance
Delete on public.customer_balance (cost=0.00..799173.51 rows=0 width=0) (actual time=61939.525..61939.526 rows=0 loops=1) Buffers: shared hit=50027707 read=620942 dirtied=295462 written=71785 WAL: records=50026565 fpi=34 bytes=2711252160
-> Seq Scan on public.customer_balance (cost=0.00..799173.51 rows=15052451 width=6) (actual time=3185.519..35234.061 rows=50000000 loops=1)
Output: ctid Buffers: shared hit=27707 read=620942 dirtied=26565 written=71785 WAL: records=26565 fpi=34 bytes=11252160
2024-11-10 17:51:05 UTC-6526d7f0.7f67-LOG: duration: 10387.322 ms plan:
Query Text: select max(c_id) from customer
Finalize Aggregate (cost=180185.84..180185.85 rows=1 width=4) (actual time=10387.220..10387.319 rows=1 loops=1) Output: max(c_id) Buffers: shared hit=37148 read=1204 written=69
-> Gather (cost=180185.63..180185.84 rows=2 width=4) (actual time=10387.214..10387.314 rows=1 loops=1)
Output: (PARTIAL max(c_id)) Workers Planned: 2 Workers Launched: 0 Buffers: shared hit=37148 read=1204 written=69
-> Partial Aggregate (cost=179185.63..179185.64 rows=1 width=4) (actual time=10387.012..10387.013 rows=1 loops=1) Output: PARTIAL max(c_id) Buffers: shared hit=37148 read=1204 written=69
-> Parallel Index Only Scan using customer_i1 on public.customer (cost=0.43..168768.96 rows=4166667 width=4) (actual time=0.446..7676.356 rows=10000000 loops=1)
Output: c_w_id, c_d_id, c_id Heap Fetches: 24 Buffers: shared hit=37148 read=1204 written=69
Примечание.
В демонстрационных целях показаны выходные данные EXPLAIN ANALYZE только нескольких запросов, используемых в процедуре. Идея состоит в том, чтобы собрать выходные данные EXPLAIN ANALYZE всех запросов из журналов и определить самые медленные из них и попытаться настроить их.
Связанный контент
- Устранение неполадок с высокой загрузкой ЦП в Базе данных Azure для PostgreSQL.
- Устранение неполадок с высоким использованием IOPS в Azure Database для PostgreSQL.
- Устранение неполадок с высокой загрузкой памяти в Базе данных Azure для PostgreSQL.
- Параметры сервера в Базе данных Azure для PostgreSQL.
- Настройка autovacuum в Базе данных Azure для PostgreSQL.